- The paper introduces LoPT, a novel framework that guarantees lossless parallel tokenization with consistency equivalent to sequential methods.
- It employs an overlapped chunk split coupled with a position-aware merge to achieve 5–6x faster tokenization for long-context inference.
- Empirical evaluations on diverse datasets show LoPT’s exact accuracy (1.0) and scalability compared to existing delimiter- and overlap-based methods.
LoPT: Lossless Parallel Tokenization Acceleration for Long Context Inference of LLM
Introduction and Motivation
The deployment of LLMs in long-context inference scenarios, such as multi-document analysis and agentic systems, imposes heavy computational burdens not only on model inference but also on the text preprocessing pipeline. Tokenization, the step where input text is converted into token IDs via an algorithmically defined vocabulary, is increasingly recognized as a latency bottleneck for extensive contexts (e.g., 64K+ tokens), yet remains under-optimized relative to architectural and operator-level advances. Existing parallel tokenization solutions, mainly delimiter-based and overlap-based chunk splitting, have achieved substantial throughput gains but suffer from inconsistency: merged token sequences can deviate from the standard sequential tokenizer, causing degradation in downstream model performance.
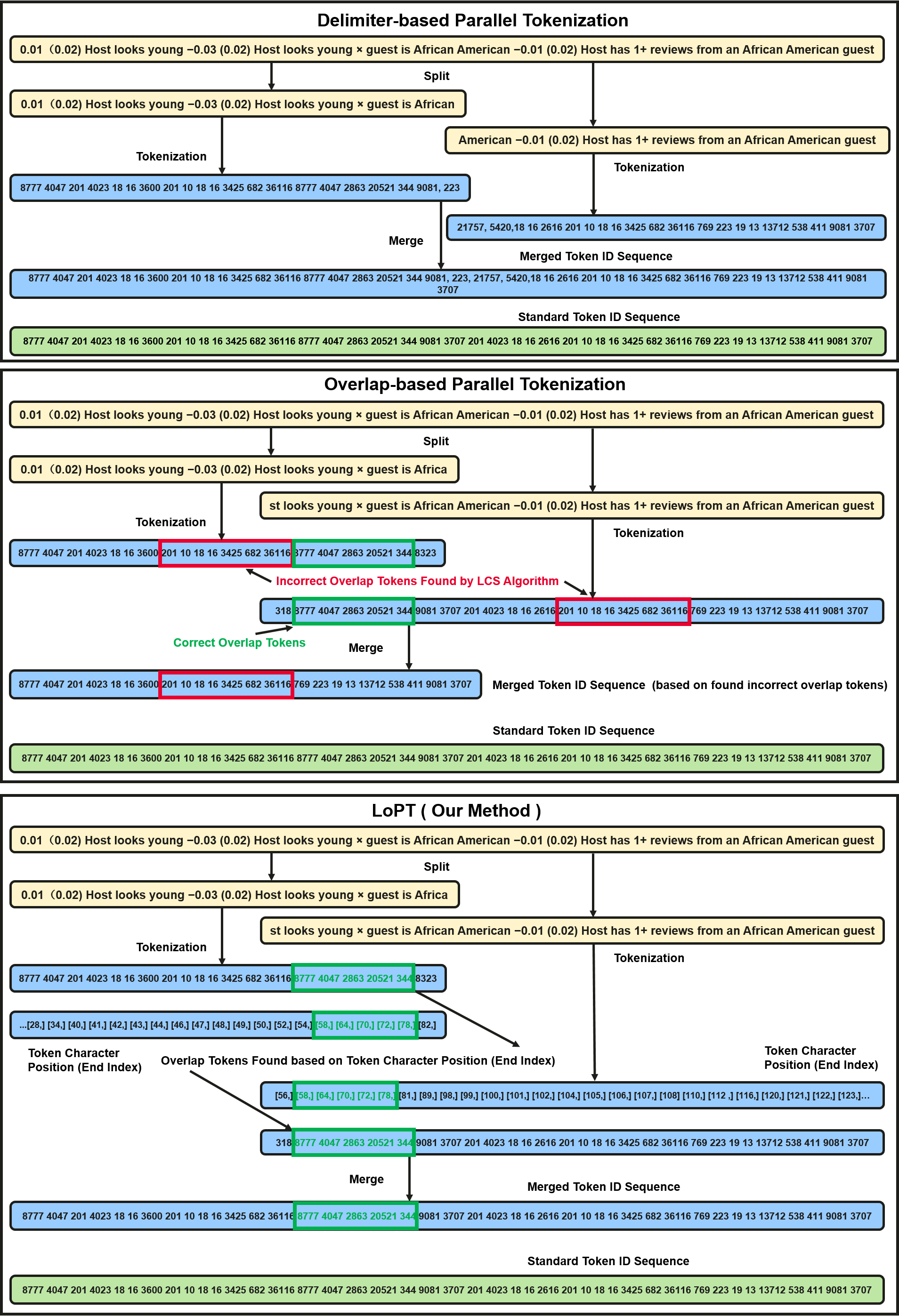
Figure 1: Error cases of previous chunk-based parallel tokenization (blue), standard tokenization (green), and the lossless behavior of LoPT.
This work introduces LoPT, a framework for lossless parallel tokenization specifically optimized for high-throughput, long-context scenarios. The LoPT pipeline comprises three key modules—overlapped chunk split, parallel tokenization with position metadata, and position-aware merging—which collectively ensure perfectly accurate tokenization results with acceleration competitive with delimiter-based approaches.
Background and Limitations of Existing Methods
Classical tokenization algorithms (BPE, WordPiece, etc.) have been engineered to support fast CPU- and GPU-side implementations (HuggingFace Tokenizers, TikToken, cuDF, BlockBPE), leveraging techniques such as trie-based longest-match search and multi-threading for generalized acceleration. However, these solutions either struggle under extreme sequence lengths or do not reduce per-sample latency in critical inference pipelines.
Chunk-based parallelization is the prevailing solution for scaling to longer contexts, implemented either by delimiter-driven splitting (fast but low accuracy) or overlaps (higher accuracy, but merging often fails with repeated sequences and incurs substantial computational overhead). The key limitation of existing overlap-based approaches is reliance on token ID matching for merge, which cannot guarantee correct correspondence at chunk boundaries—especially for subword tokenizers with nontrivial context dependencies.
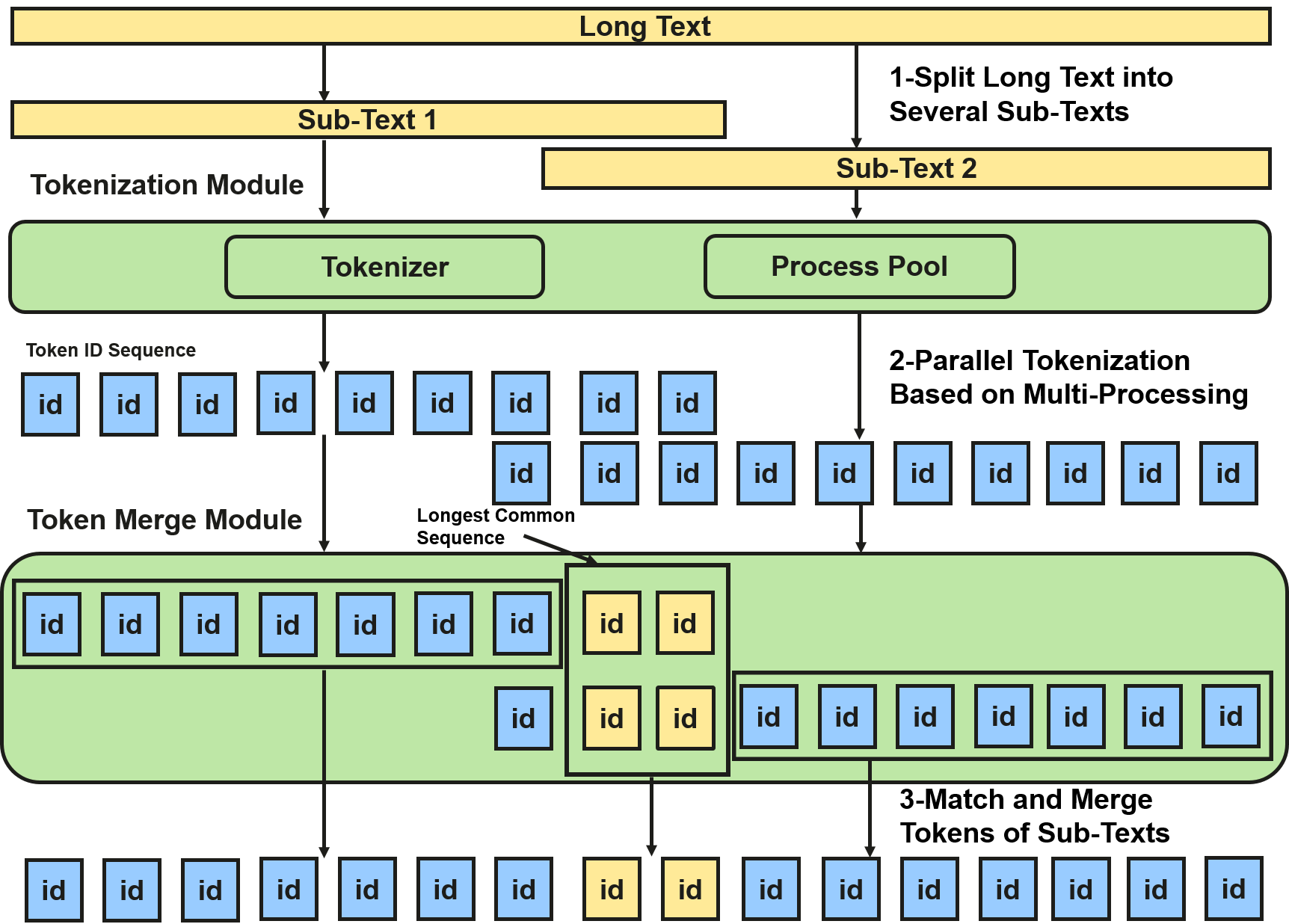
Figure 2: Parallel tokenization workflow of existing methods, showing tokenization of split chunks and subsequent merging.
Methodology and Theoretical Guarantee
Framework Overview
LoPT’s architecture consists of:
- Text Split Module: The input string is segmented into chunks with pre-defined length and overlap; the overlaps ensure that context-sensitive tokens can be matched across boundaries.
- Parallel Tokenization Module: Each chunk is tokenized independently and in parallel, with the tokenizer outputting both token IDs and the corresponding character-level positions within the chunk.
- Position-Aware Merge Module: Token sequences from adjacent chunks are merged based on character position alignment, guaranteeing that only tokens with identical positions in the original text are matched.
Dynamic chunk length adjustment is invoked during merge if adequate overlap cannot be established, doubling the chunk size and rerunning split/tokenization/merge phases as necessary until losslessness conditions are met.
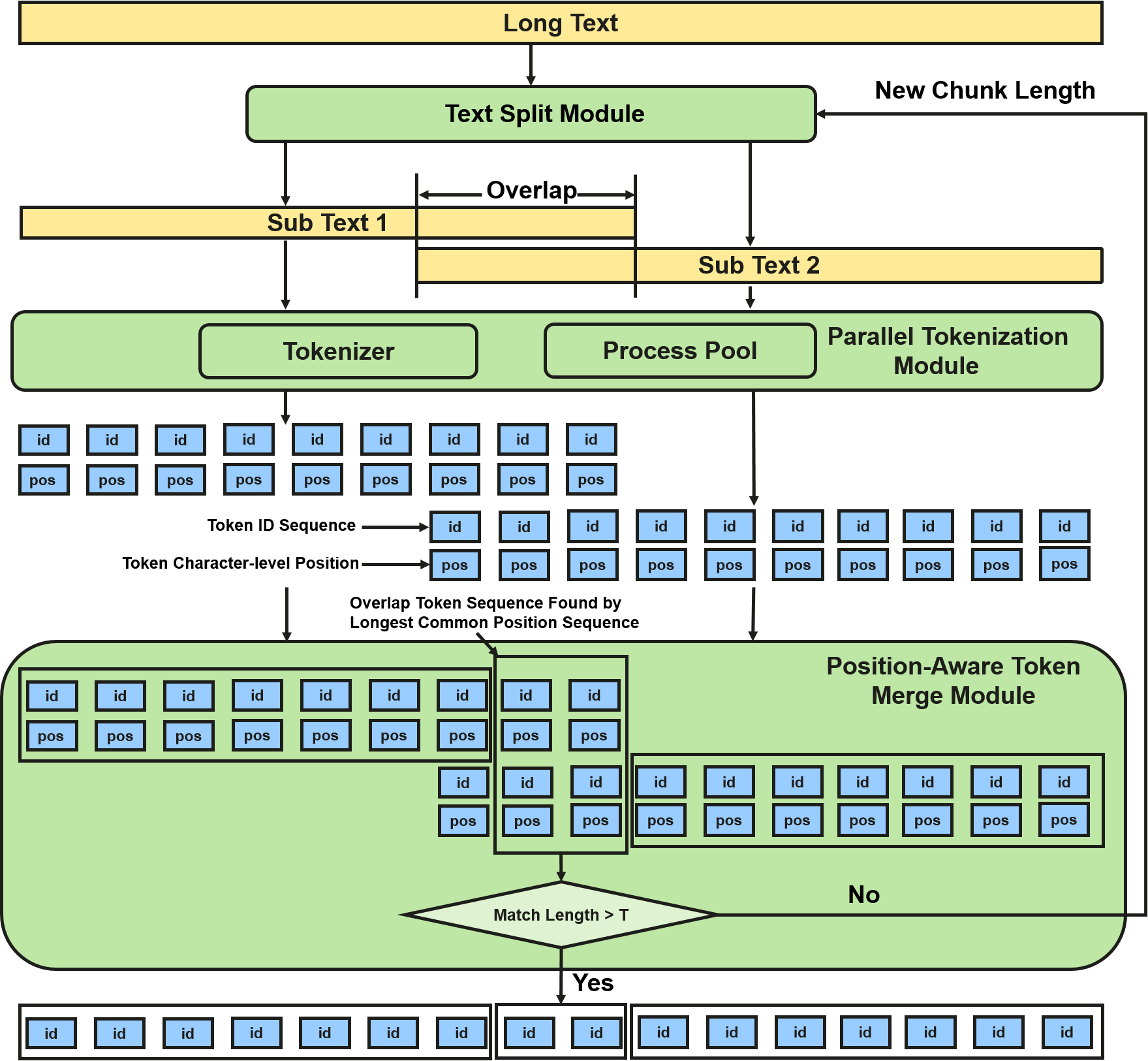
Figure 3: LoPT system pipeline; green denotes the novel modules involving chunk overlap and position-aware merge.
Lossless Merge and Algorithmic Guarantees
LoPT’s merge operation proceeds via identification of an overlap token sequence between two adjacent chunks whose character positions map to precisely the same range in the original input string. This criterion ensures that token boundaries and contexts are preserved exactly as in sequential tokenization. Whenever the required amount of overlap is not found, the chunk size is adaptively increased. The framework provides a theoretical proof of consistency: if every adjacent chunk pair yields a valid overlap sequence, the final merged output (T) is guaranteed to be identical to standard sequential tokenization (Tokenizer(S)).
The LoPT algorithm is formalized as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def LoPT_tokenize(text, tokenizer, chunk_len, overlap_len, proc_pool_size):
while True:
chunks = split_with_overlap(text, chunk_len, overlap_len)
tokens_positions = parallel_tokenize(chunks, tokenizer, proc_pool_size)
matches = []
for i in range(len(chunks) - 1):
l_idx, r_idx, n_overlap = match_positions(tokens_positions[i], tokens_positions[i + 1])
if n_overlap == 0:
chunk_len *= 2 # Increase chunk length and restart
break
matches.append((l_idx, r_idx, n_overlap))
else: # All matches successful
merged_tokens = []
for i, (l_idx, r_idx, n_overlap) in enumerate(matches):
if i == 0:
merged_tokens.extend(tokens_positions[0].tokens[:l_idx + n_overlap])
merged_tokens.extend(tokens_positions[i + 1].tokens[r_idx + n_overlap : matches[i + 1][0] + matches[i + 1][2] if i + 1 < len(matches) else None])
return merged_tokens |
This pseudo-code reflects the core process: split, parallel tokenize, position-based match and merge, and dynamic adjustment.
Empirical Evaluation
Datasets and Implementation
LoPT is evaluated on LongBenchV2 (English, long texts), LEval (English, medium texts), and ClongEval (Chinese, long texts), covering diverse domains. Tokenizer implementations cover both BPE (Qwen3, DeepSeek-V3, Llama3.1, GPT-OSS-120B) and WordPiece (BERT Base models). LoPT uses HuggingFace’s fast tokenizer as its backend and C++ for optimized token merge, with Python orchestrating parallel execution.
Baselines
- Standard HuggingFace TokenizerFast (Single-threaded)
- Delimiter-Based Parallel Tokenizer: Splits on whitespace, comma, or period; direct concatenation of results.
- Overlap-Based Parallel Tokenizer (OpenLMLab and reimplemented variants)
- Sample-Level Multi-Process HuggingFace Tokenizer
Metrics
The benchmarks focus on per-input latency (ms) and accuracy of results (ratio matching sequential tokenizer).
Results
LoPT achieves exact accuracy (1.0) across all models/datasets, outperforming delimiter-based methods (accuracy ranging 0.24–0.99) and previous overlap-based implementations (accuracy up to 0.98 but lower throughput due to costly merges). LoPT typically attains 5–6x speedup compared to HuggingFace TokenizerFast with no loss of consistency. It maintains linear scaling in sequence length but with a significantly reduced slope, indicating much less sensitivity to longer input strings.
Analytical Insights and Scalability
Sequence Length
LoPT's acceleration advantage increases with longer input sequences; its linear scaling has a lower gradient versus HuggingFace TokenizerFast.
(Figure 4)
Figure 4: Tokenization time increases with sequence length; LoPT shows substantially lower growth rate.
Chunk Length and Process Pool Size
An optimal chunk length balances parallel efficiency and per-process workload. Chunk size should be set such that the number of chunks approximates the process pool size. Excessively small chunks cause process oversubscription and longer merge times; overly large chunks lead to underutilization of parallelism.
(Figure 5)
Figure 5: Tokenization time as a function of chunk length; performance minimum aligns with process pool utilization.
Process pool size further modulates throughput. While increasing the pool size improves tokenization speed, this effect plateaus when the number of chunks reaches the pool size. Empirically, optimal configurations are dependent on text length and available hardware resources.
(Figure 6)
Figure 6: Tokenization time as a function of process pool size; diminishing returns beyond the optimal pool size.
Batch Size and Device Impact
LoPT is less sensitive to CPU compute capabilities than HuggingFace TokenizerFast and demonstrates more consistent latency across different hardware profiles. Batch size scaling reveals that LoPT excels over sample-level multi-process approaches at small batch sizes, which are typical in long-context inference scenarios.
Practical Implications and Limitations
LoPT’s strict tokenization output consistency enables its direct adoption in LLM serving and production pipelines, alleviating a previously underappreciated bottleneck. Its design is agnostic to the underlying tokenizer architecture (BPE, WordPiece), supporting robust integration across model families. The implementation requires access to character-level token position metadata from the backend tokenizer—a feature available in well-engineered systems but possibly absent in legacy deployments. Deployment recommendation includes tuning chunk size and process pool size for specific hardware and input characteristics.
Potential limitations include increased memory consumption due to concurrent holding of chunk tokenization state, and for extremely high concurrency scenarios, process pool management overhead can become significant.
Conclusion
LoPT presents a robust solution to tokenization acceleration for long-context LLM inference, combining multi-process parallelism with position-aware merge to ensure output identicality and high throughput. The framework is theoretically guaranteed to be lossless, empirically attains exact accuracy across benchmarks, and offers substantial latency reductions scalable with input length and hardware. LoPT is positioned for immediate deployment in long-context serving frameworks and establishes a methodological foundation for further research in efficient, exact text preprocessing for LLM applications. Future developments may extend chunking strategies and broaden compatibility with newer tokenizer architectures.

