- The paper introduces ReaDe, a reasoning-based instruction interpreter that transforms ambiguous user inputs into detailed, generator-ready prompts for controllable video synthesis.
- The paper employs a two-stage training process combining supervised reasoning initialization and reinforcement learning to enhance prompt fidelity and cross-modal alignment.
- The paper demonstrates robust performance improvements across quantitative metrics and qualitative benchmarks, ensuring higher caption accuracy, motion smoothness, and consistency under diverse conditions.
Universal Reasoning-Based Instruction Interpretation for Controllable Video Generation
Motivation and Problem Statement
Recent developments in Diffusion Transformers (DiTs) have markedly improved the fidelity and temporal coherence of generated video content. Despite these advancements, fine-grained controllability remains suboptimal when bridging user intent and the explicit prompt representations required by generative models. Users typically issue concise, often ambiguous instructions, in stark contrast to the richly detailed prompts dominating model training datasets. This distributional mismatch impairs instruction fidelity and overall video quality, especially in multi-condition or reasoning-intensive settings. Existing prompt interpretation efforts either restrict themselves to textual modalities or demand large collections of condition-specific data, both of which fail to generalize under cross-modal constraints or reasoning-rich scenarios (Figure 1).
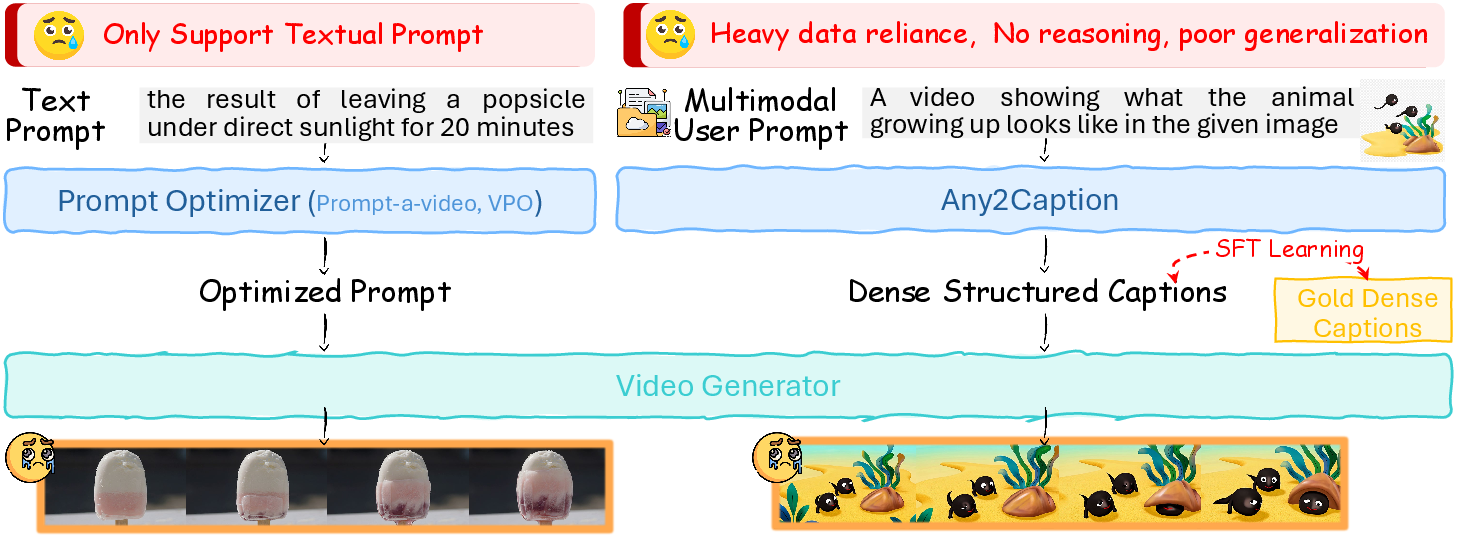
Figure 1: Text-only prompt optimizers and data-hungry multimodal methods (e.g., Any2Caption) remain brittle, performing poorly on reasoning-intensive and unseen instructions.
The ReaDe Framework: Architecture and Training
ReaDe (Reason-then-Describe) constitutes a universal, model-agnostic instruction interpreter, designed to robustly translate user inputs—including textual and heterogeneous multimodal conditions (visual, pose, depth, camera, audio)—into detailed, generator-ready prompts suitable for state-of-the-art controllable video generation pipelines. The core paradigm leverages explicit stepwise reasoning, reminiscent of Chain-of-Thought strategies, to first decompose and clarify ambiguous user demands and subsequently synthesize compositional, richly annotated guidance.
The framework is realized atop a multimodal LLM backbone (Qwen2.5-Omni), augmented with specialized encoders to process non-standard conditions such as camera trajectories. Training proceeds in two stages:
- Supervised Reasoning Initialization: Instruction–reasoning–caption triples are curated, where reasoning annotations record the intermediate cognitive steps of intent extraction, multimodal alignment, and supplementary detail completion.
- Reinforcement Learning with Multi-Dimensional Reward Assignment: A reward function aggregates format adherence, coverage across explicit user requests, fidelity to condition-derived details, imaginative (yet plausible) supplementation, and internal consistency. This fine-grained signal is used to optimize the policy via GRPO (Group Relative Policy Optimization), yielding robust generalization across domains and input distributions.
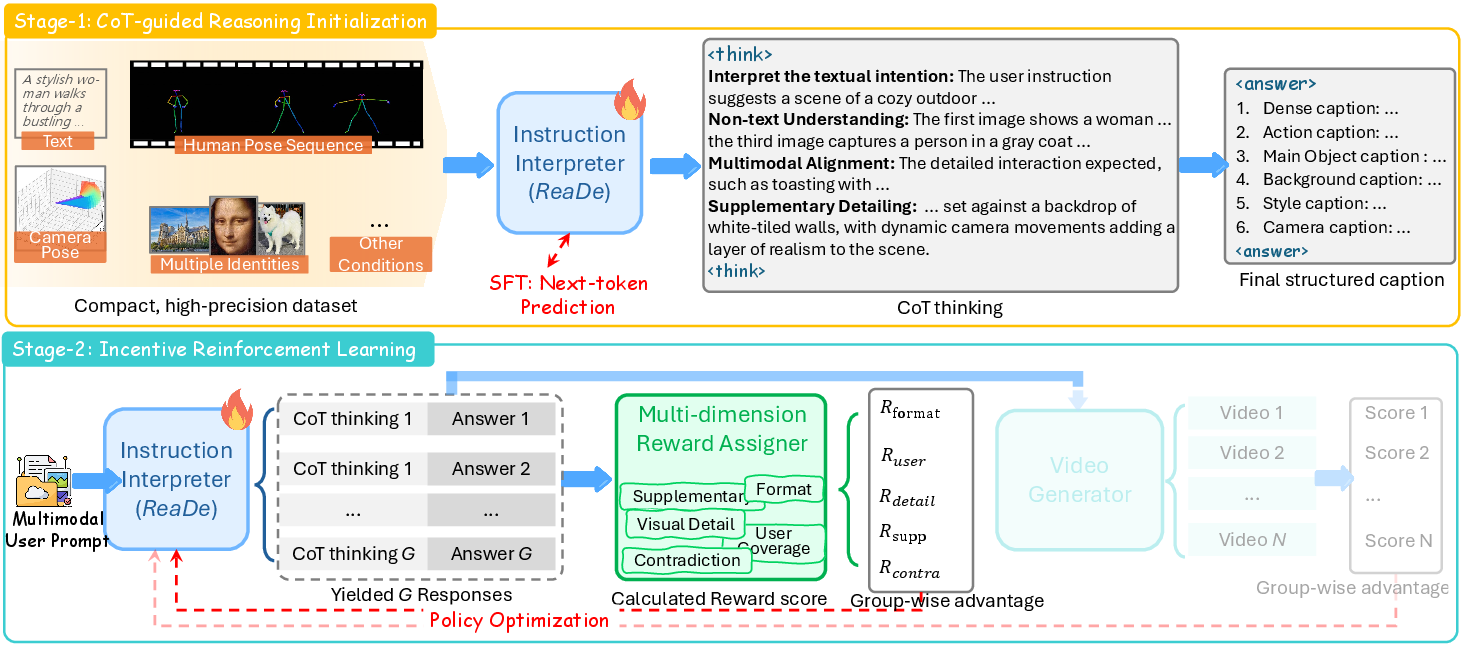
Figure 2: Overview of the training framework for the Instruction Interpreter (ReaDe). (1) CoT-guided reasoning initialization and (2) reinforcement learning using multi-dimensional reward assignment and video feedback.
Core Methodological Innovations
Reason-then-Describe Reasoning: The dataset formalizes multi-step reasoning: textual intent extraction, non-textual condition parsing, cross-modal alignment, and context-driven supplementation. Each step is supported by gold-standard dense captions, ensuring unbiased, principled annotation.
Multi-Aspect Reward Modeling: Beyond format checking, the reward assigner includes user-side intent coverage, effective leveraging of condition-specific details, and imagination-guided enrichment, with additional constraints on contradiction avoidance for longer prompts.
Generalization and Modality-Agnostic Capability: Unlike existing approaches that are either text-centric or rely on direct SFT (Supervised Fine-Tuning) and memorization, ReaDe is explicitly optimized to reason—demonstrating strong transfer even in domains unseen during training (Figure 3).
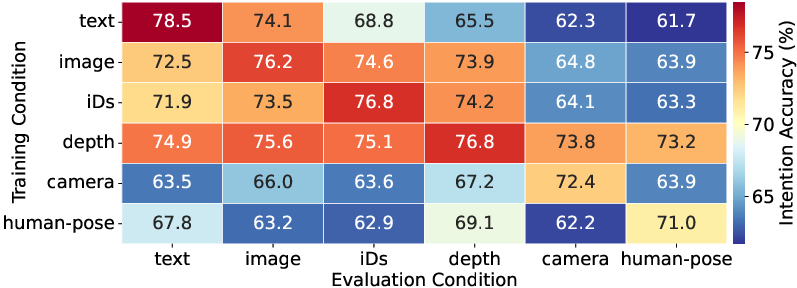
Figure 3: Generalization capability of ReaDe. Intention accuracy under various training–evaluation condition pairs highlights robust cross-condition transfer.
Experimental Evaluation
Extensive benchmarking includes single-condition (identities, camera, depth, human pose) and multi-condition compositional control, employing both quantitative metrics (CLIP-T, DINO-I, PAcc., RotErr, MAE, aesthetic and smoothness scores) and qualitative visualizations.
Key findings:
- Accuracy and Fidelity Superiority: The ReaDe interpreter consistently surpasses prior SFT and prompt interpretation baselines (e.g., Any2Caption), yielding higher caption accuracy and alignment scores across all condition types.
- Robust Multi-Condition Reasoning: Under compositional control, ReaDe maintains superior performance in reconciling conflicting or interacting signals (Table 1, Table 2). Gains are especially pronounced in Camera+Depth+IDs composition, where naive approaches falter.
- Ablation Results: Multi-aspect rewards (user, detail, supp, contra) each contribute to overall gains in reasoning quality and output coherence. The two-stage learning (CoT + RL) is necessary for stabilizing and maximizing learning efficiency.
- Prompt Optimization on Benchmarks: On VBench, ReaDe (SFT+GRPO) matches or outperforms state-of-the-art prompt optimizers across most axes (subject/background consistency, motion smoothness, multiple object coverage, appearance/style, and scene quality).

Figure 4: Illustration of prompt optimization for raw prompts. CogVideoX generation results highlight improved image/video fidelity with ReaDe-interpreted prompts.
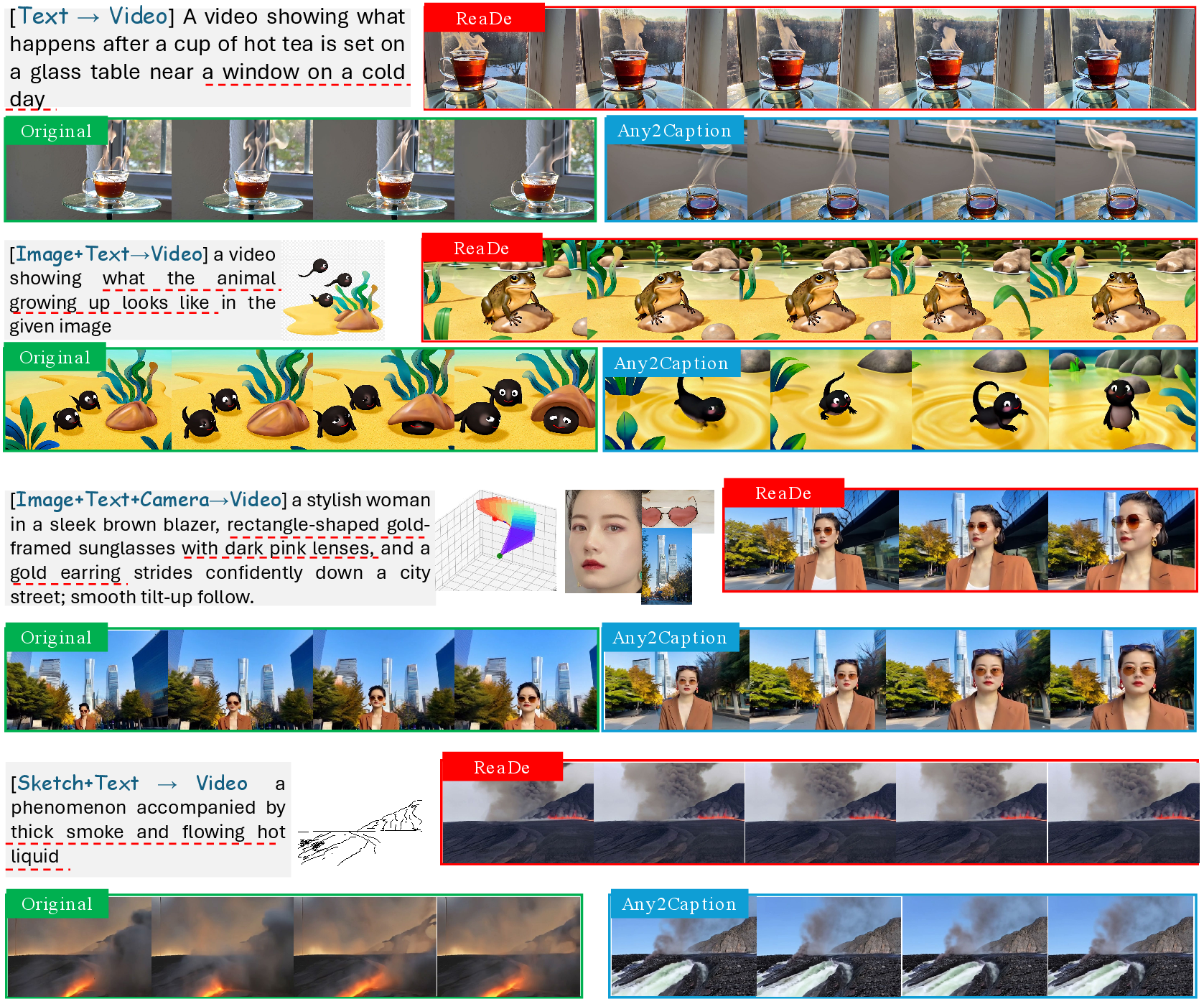
Figure 5: Qualitative comparison of the generation quality across original prompts, Any2Caption-interpreted, and ReaDe-interpreted. Kling1.6, FullDiT, and SketchVideo generations demonstrate ReaDe’s enhanced reasoning and coherence.
Architecture and Modality Integration
The multimodal encoding strategy supports text, image, video, pose, depth, and camera conditions, processed through specialized encoders and fused via Qwen-LLM; the output is a deeply interpreted prompt well-aligned with downstream video generator expectations (Figure 6).
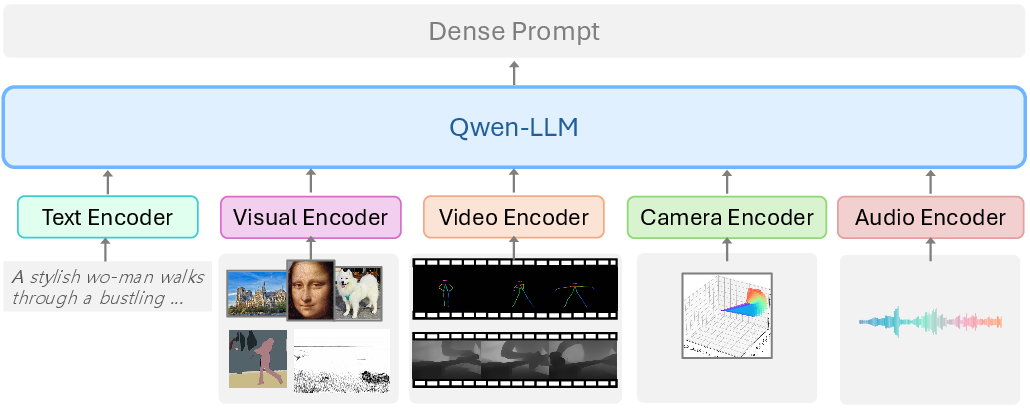
Figure 6: The multimodal encoding framework integrates diverse user-supplied conditions into deeply reasoned dense prompts for downstream video generators.
Reward Model Validation and Comparative Consistency
Reward evaluation stability is validated against GPT-4o, with negligible variance and strong alignment in scores (Figures 7, 8), supporting reliable optimization during RL training.
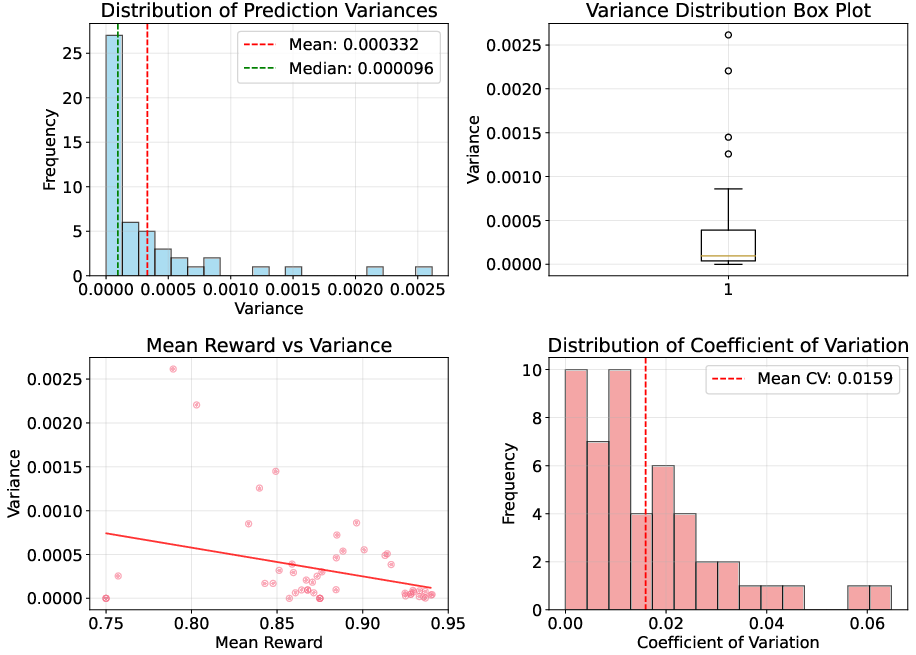
Figure 7: The reward score of consistency analysis for Qwen3-30B model, demonstrating low score variance and reliable evaluation.
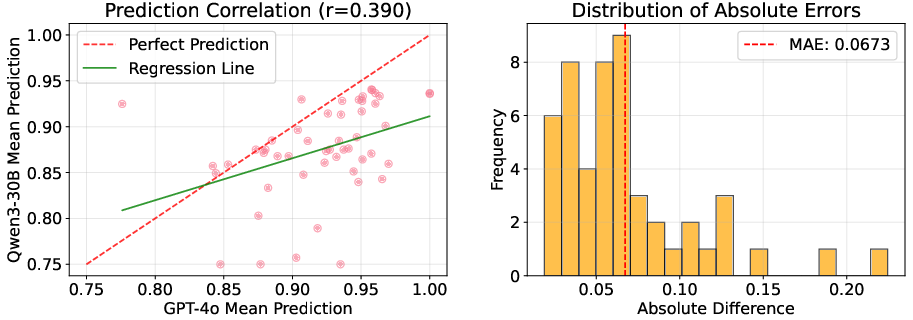
Figure 8: Comparison between Qwen3-30B and GPT-4o predictions, showing close agreement and low mean absolute error.
Qualitative and Case Study Results
Empirical case studies—across condition-controlled and reason-intensive generation tasks—determine that ReaDe yields more detailed, semantically faithful, and temporally coherent video outputs. Notably, generator feedback-driven joint optimization affords further improvement in visual quality and prompt adherence. For multimodal scenarios, the capability to unify text, image, audio, and auxiliary control signals yields stable gains in downstream synthesis.

Figure 9: Comparison of videos generated from original, ReaDe-generated, and further optimized prompts, using CogVideoX feedback.

Figure 10: Joint optimization with downstream model feedback further enhances video generated quality and alignment.
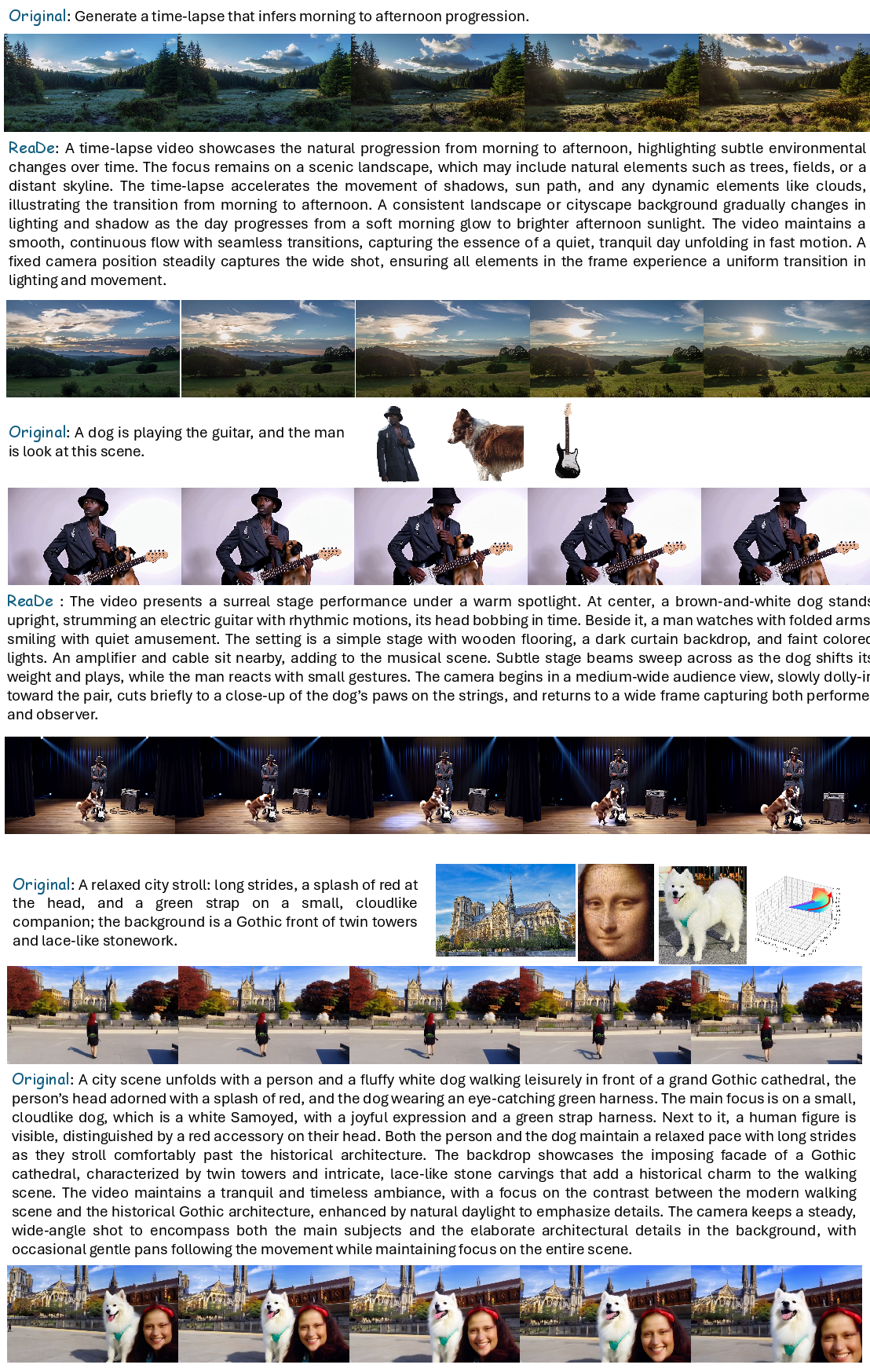
Figure 11: Kling1.6 and FullDiT comparisons, showing ReaDe’s improvements under identity, pose, depth, and camera controls.
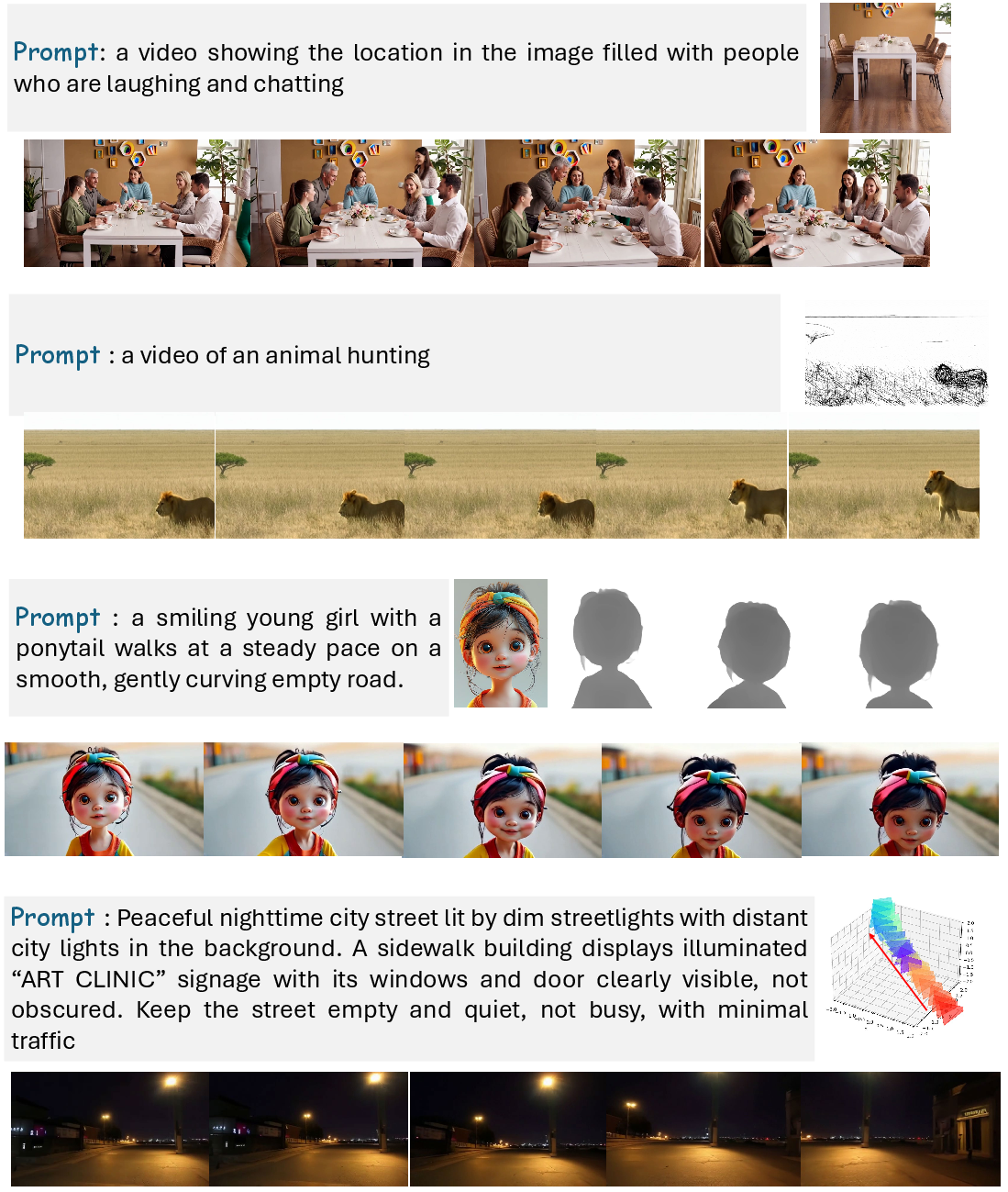
Figure 12: Condition-controlled video generation: ReaDe outputs detailed, multifaceted prompts resulting in coherent visual synthesis across Kling1.6, SketchVideo, and FullDiT.

Figure 13: Audio-text multimodal condition: ReaDe extracts and incorporates audio context, improving video realism and alignment.
Implications and Future Directions
From a practical standpoint, ReaDe advances controllable video generation pipelines by rationalizing the intent–prompt gap and providing dense, actionable guidance irrespective of input ambiguity or composition. The decoupled and generalizable reasoning paradigm further facilitates integration into diverse generators without the need for model-specific tailoring. Theoretically, the method demonstrates the value of explicit reasoning and differential reward modeling for cross-modal intent parsing, setting a template for multi-agent RL optimization in generative AI.
Potential future avenues include scaling to denser modalities (e.g., categorical attributes, activity graphs), extending to longer-horizon or open-ended narrative video synthesis, and incorporating human-in-the-loop alignment and safety-critical filters for controlled deployment.
Conclusion
ReaDe presents a universal, reasoning-based instruction interpreter for controllable video generation, establishing a robust solution to the input–prompt distribution shift and model controllability bottleneck. The framework leverages explicit stepwise multimodal reasoning and reward-driven policy optimization to yield highly faithful, semantically rich prompts compatible with modern video diffusion transformers. Experimental results across quantitative and qualitative benchmarks confirm consistent gains in fidelity, alignment, and generalization. Future work will address expanded modalities, longer-horizon reasoning, and real-world deployment challenges.
Reference: "A Reason-then-Describe Instruction Interpreter for Controllable Video Generation" (2511.20563)