Image Diffusion Models Exhibit Emergent Temporal Propagation in Videos
Abstract: Image diffusion models, though originally developed for image generation, implicitly capture rich semantic structures that enable various recognition and localization tasks beyond synthesis. In this work, we investigate their self-attention maps can be reinterpreted as semantic label propagation kernels, providing robust pixel-level correspondences between relevant image regions. Extending this mechanism across frames yields a temporal propagation kernel that enables zero-shot object tracking via segmentation in videos. We further demonstrate the effectiveness of test-time optimization strategies-DDIM inversion, textual inversion, and adaptive head weighting-in adapting diffusion features for robust and consistent label propagation. Building on these findings, we introduce DRIFT, a framework for object tracking in videos leveraging a pretrained image diffusion model with SAM-guided mask refinement, achieving state-of-the-art zero-shot performance on standard video object segmentation benchmarks.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper explores a surprising ability hidden inside image-generating AI called diffusion models. Even though these models are trained to make single images, the authors show they can also help follow an object across a video, frame by frame, without any extra training on videos. They turn the model’s “attention” maps into a tool that spreads labels over time, so a rough shape of an object in one frame becomes a clean, consistent object mask in later frames. They build a system called Drift that does this and set new zero-shot performance records on standard video object segmentation tests.
What questions does the paper ask?
- Can an image-only diffusion model (not trained on videos) naturally “carry” information across time and help track objects in videos?
- Are the model’s self-attention maps a good way to spread an object’s label (its mask) from one frame to the next?
- How can we tune or adapt the model at test time to make this label spreading more accurate and stable?
- Does this approach beat other zero-shot methods on popular video benchmarks?
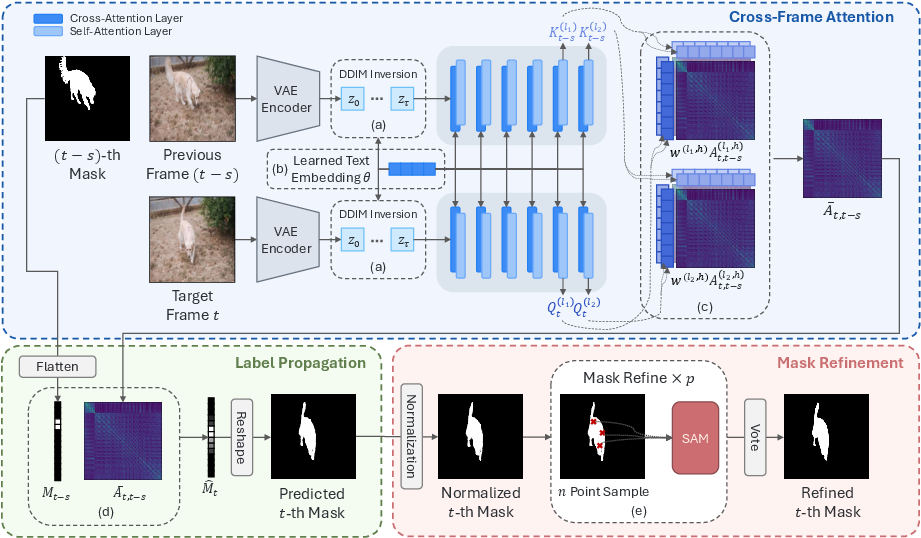
How did they do it? (Methods explained simply)
Think of a diffusion model like an artist who removes noise from a picture, step by step, to reveal a clear image. To do this well, it learns what parts of the image are related—like how all parts of a cat belong together. That “relatedness” is stored in attention maps.
- Attention maps: Imagine shining a spotlight from one pixel to others that look similar. Self-attention is the model’s way of saying, “If I’m looking here, which other places should I also care about?” The authors use these maps as a “propagation kernel,” like a set of rules for spreading an object’s label from known pixels to other similar pixels.
- From image to video: Instead of only linking pixels within one image, they link pixels across consecutive frames. That lets a cat mask in frame 1 spread into frame 2 and so on, creating temporally consistent tracking.
- Why not just compare features directly? A common trick is cosine similarity (comparing feature vectors like measuring angle closeness). The paper shows this can be noisy and scatter attention to irrelevant places. In contrast, self-attention uses learned projections and multiple “heads” that each focus on different meaningful patterns, producing cleaner, sharper matches across frames.
To make the propagation even better, they add three simple test-time tweaks:
- DDIM inversion: Adds “smart” noise aligned with the model’s understanding, so the features keep the object’s meaning across diffusion steps. Think of it as nudging the inputs into the model’s comfort zone.
- Textual inversion: Learns custom text tokens for the specific object in the first frame. These tokens don’t describe the object like “cat”—they act like fine-tuning knobs that shape attention maps to propagate the given mask more precisely.
- Adaptive head weighting: Attention has many heads; some are more helpful than others. They learn weights so the most useful heads contribute more to the final propagation map.
Finally, they refine the masks using SAM (Segment Anything Model). They treat the propagated mask as a soft “map” of where the object likely is, sample a few point prompts from it, ask SAM to produce candidate masks, and pick the best one. This sharpens edges and improves details.
Main findings and why they matter
- Self-attention > cosine similarity: Using self-attention for cross-frame propagation gives much more accurate and stable masks than raw feature similarity, especially over time.
- Test-time tuning helps a lot:
- DDIM inversion makes performance more stable across diffusion steps and improves peak accuracy.
- Textual inversion with the propagation loss beats using empty prompts, class names, or captions; it’s better to learn tokens tailored for propagation, not for naming the object.
- Adaptive head weighting gives consistent, if modest, gains by emphasizing the most informative attention heads.
- State-of-the-art zero-shot performance: Their Drift framework (with SAM for refinement) outperforms strong baselines like STC, DINO, and DIFT without training on video segmentation. It also beats methods that rely on large image segmentation training (like SegGPT and SAM-PT) on short video benchmarks and stays robust on long videos, where others struggle.
- Comparable to fully supervised models: Despite no video training, Drift’s results approach those of methods trained on labeled video data, showing strong generalization.
These results matter because they reveal hidden “temporal thinking” in image diffusion models and show we can repurpose them for video tasks without expensive training data.
What’s the impact? (Implications)
- Less training data needed: You can track objects in videos using an image diffusion model and a first-frame mask—no special video training required. This could lower the cost and speed up building practical tools for video editing, analysis, and robotics.
- New use for generative models: The paper shows that models made for generation also learn useful structure for understanding and tracking, hinting at broader applications beyond making images.
- Better foundations for video AI: With simple test-time tweaks, we can unlock temporal coherence from image models, suggesting future systems can be lighter, more flexible, and easier to adapt.
- A path to robust zero-shot video segmentation: Drift demonstrates that combining smart attention-based propagation with refinement tools like SAM can deliver strong performance in real-world video tasks.
In short, the paper discovers and harnesses an “emergent” skill in image diffusion models—temporal label propagation—turning them into capable zero-shot object trackers in videos.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what remains missing, uncertain, or unexplored in the paper and suggest concrete directions for future research:
- Formal theory for “emergent temporal propagation”
- Provide a principled explanation of why self-attention trained solely on static images yields reliable cross-frame correspondences in videos.
- Characterize the conditions (e.g., appearance changes, motion magnitude, occlusions) under which this emergent property holds or fails, and derive bounds or guarantees on propagation accuracy.
- Architectural generalization
- Test whether the phenomenon and the Drift pipeline transfer across diffusion architectures (UNet vs. DiT), model scales (e.g., SD v1.5, SDXL), and training corpora, and quantify sensitivity to architecture-specific attention patterns.
- Computational efficiency and scalability
- Report and optimize runtime/memory for extracting multi-layer, multi-head attention, DDIM inversion per frame, textual inversion, and SAM refinement.
- Assess real-time feasibility at common video resolutions and long sequences; propose approximations (e.g., layer/head pruning, low-rank attention) that preserve performance while reducing cost.
- Robustness in challenging video conditions
- Systematically evaluate failures under fast motion, severe occlusions, large scale changes, non-rigid deformations, camera shake, lighting changes, motion blur, and complex backgrounds.
- Develop mechanisms (e.g., occlusion-aware gating, motion priors, re-identification cues) to recover identity after long occlusions and reappearances.
- Dependence on initial-mask quality
- Quantify sensitivity to imperfect first-frame masks (noisy, partial, coarse box, scribbles).
- Explore weaker first-frame supervision (points/boxes) and automatic initialization, including recovery from suboptimal seeds.
- Multi-object interaction and identity management
- Analyze failure modes in crowded scenes, overlaps, and object-object occlusions; measure identity switches and cross-object confusion.
- Introduce explicit identity memory or instance-aware constraints to maintain consistent per-object propagation over time.
- Long-horizon stability and drift accumulation
- Study error accumulation over very long sequences (beyond the reported benchmarks), including strategies for dynamic reference-frame selection, forgetting, and propagation re-anchoring to mitigate drift.
- Hyperparameter sensitivity and tuning
- Provide comprehensive sensitivity analyses for key choices (top-k sparsification, spatial radius r, number of reference frames S, diffusion timestep τ, SAM point count n and candidate count p).
- Design adaptive strategies to set these parameters per-video or per-frame.
- Test-time optimization design and overhead
- Quantify the optimization time budget, convergence behavior, and trade-offs of textual inversion and head-weight learning.
- Investigate alternative objectives (e.g., cycle-consistency across multiple frames, contrastive separation from distractors) to reduce overfitting to the initial frame and improve generalization.
- Dynamic vs. static head weighting
- Explore frame-wise or object-wise adaptive head weights instead of a single static set per video, and study head specialization and pruning for efficiency and robustness.
- Interpretability of learned text tokens
- Characterize what mask-specific textual embeddings actually encode (they do not cluster with semantic class tokens) and whether they transfer across videos or objects with similar appearance/motion.
- Cross-attention’s role and combinations
- Systematically compare and combine cross-attention (text-conditioned) with self-attention kernels for propagation, including CLIP-guided prompts or learned visual tokens, and study when each contributes most.
- Integration with SAM and alternative refinement modules
- Analyze failure modes of SAM refinement when prior masks are imprecise; compare against alternative refinement methods (e.g., lightweight boundary refinement heads, CRFs) that do not require large supervised models.
- Investigate end-to-end differentiable refinement to reduce reliance on heuristic point sampling.
- Domain transfer and modality robustness
- Validate the approach on diverse domains (egocentric/robotics, medical, thermal/infrared, low-light, compressed videos) and examine whether emergent temporal propagation persists under domain shifts.
- Reference-frame aggregation strategy
- Replace uniform aggregation over references with learned or adaptive weighting based on temporal distance, confidence, or motion cues; evaluate diminishing returns as references become older.
- Diverse evaluation metrics and tasks
- Complement segmentation metrics with tracking-focused measures (e.g., identity F1, ID switches) and point tracking benchmarks to directly quantify temporal correspondence quality.
- Extend to related tasks (video editing consistency, correspondence/flow estimation) to test the generality of the propagation kernel.
- Handling thin structures and small objects
- Examine the impact of attention sparsification and spatial masks on fine structures; propose multi-scale attention or super-resolution propagation for small/thin targets.
- Resolution and resizing effects
- Detail how frames are preprocessed/resized before attention extraction; analyze resolution mismatches between latent space and pixel space and their impact on fine boundary alignment.
- Reliability under different noise schedules
- Beyond DDIM inversion, evaluate alternate inversion schemes and controlled noise schedules; study whether per-frame inversion consistency matters and how it impacts temporal stability.
- Partial supervision or lightweight training
- Explore whether modest fine-tuning (e.g., on a small video set, or synthetic data) can further stabilize propagation without sacrificing zero-shot generalization, and identify minimal supervision thresholds that yield substantial gains.
Practical Applications
Overview
Below are actionable applications that can be derived from the paper’s findings, methods, and innovations—primarily the use of self-attention in pretrained image diffusion models as a temporal label propagation kernel, the test-time optimization techniques (DDIM inversion, textual inversion, adaptive head weighting), and the Drift framework with SAM-guided refinement.
Immediate Applications
- Zero-shot video rotoscoping and compositing for post-production [sector: media/software]
- Tools/workflows: A plugin for After Effects/Premiere/DaVinci that takes a first-frame mask, runs Drift to propagate masks frame-by-frame, and uses SAM refinement for clean edges; batch processing for multiple shots.
- Assumptions/dependencies: Access to a pretrained text-to-image diffusion model (e.g., Stable Diffusion), SAM integration, GPU inference; an accurate first-frame mask; acceptable offline processing latency.
- Rapid dataset annotation via mask propagation [sector: academia/industry/software]
- Tools/workflows: “Auto-annotator” that propagates a single ground-truth mask through a video to bootstrap labels for training segmentation/tracking models; human-in-the-loop correction interface.
- Assumptions/dependencies: Initial high-quality mask; moderate scene dynamics; annotation QA; compute availability.
- Sports analytics and broadcast graphics [sector: media/sports analytics]
- Use cases: Tracking the ball or a player across frames to generate heatmaps, trajectories, or dynamic overlays; automatic lower-third compositing around tracked subjects.
- Assumptions/dependencies: Reliable initial localization (human or detector-driven), handling of occlusions and fast motion; latency constraints for near-real-time use.
- Surveillance and smart retail analytics (privacy-aware deployments) [sector: retail/security]
- Use cases: Track a specific person/product once identified in the first frame (e.g., loss prevention, item movement analysis); anonymization by blurring tracked subjects across frames.
- Assumptions/dependencies: Strong privacy and compliance controls; initial subject identification; careful monitoring of bias and misuse; potentially offline batch processing.
- Live streaming and creator tools for background removal/object highlighting [sector: consumer software/media]
- Tools/workflows: Desktop/mobile apps that let creators mark an object on frame 1 and auto-track for overlays, blur, or replacement; SAM refinement for cleaner boundaries.
- Assumptions/dependencies: First-frame mark-up; video resolution affects speed; CPU/GPU constraints on end-user devices.
- AR prototyping and teleoperation overlays [sector: robotics/AR]
- Use cases: One-shot tracking of target objects for overlay alignment in demos or teleoperation feeds where training data are scarce.
- Assumptions/dependencies: Not yet suitable for closed-loop control at high FPS; initial mask quality and moderate motion complexity.
- Scientific video analysis and microscopy/object tracking [sector: life sciences/academia]
- Use cases: Track cells, organisms, or instruments in lab videos using a first-frame segmentation (e.g., endoscopy tool tracking, microscopy time-lapse).
- Assumptions/dependencies: Domain shift from natural images may require careful mask initialization; validation for scientific rigor; offline analysis acceptable.
- Content moderation pipelines (privacy protection) [sector: policy/industry/software]
- Use cases: Once a face or sensitive object is identified, automatically propagate blurs or redactions across frames to ensure temporal consistency.
- Assumptions/dependencies: Face/object detectors to establish initial mask; policy oversight; audit logs for compliance.
- Video search and indexing [sector: software/media]
- Use cases: Generate per-frame object presence timelines; improve video retrieval with object tracks without training on video segmentation datasets.
- Assumptions/dependencies: Acceptable offline processing; storage for mask metadata; integration with MAM/DAM systems.
- Diffusion-attention diagnostics and teaching aids [sector: academia/education]
- Use cases: Classroom demos and research tooling to visualize multi-head self-attention, compare cosine vs. attention affinities, and study emergent temporal propagation from image-only training.
- Assumptions/dependencies: Open-source diffusion models; visualization interfaces.
Long-Term Applications
- Real-time, on-device tracking without video-specific training [sector: robotics/edge computing]
- Products/workflows: Edge-optimized Drift variants running on mobile/embedded GPUs for closed-loop tasks (e.g., pick-and-place with one-shot object masks).
- Assumptions/dependencies: Significant optimization (model distillation, attention caching, quantization); robust handling of fast motion, occlusion, and viewpoint changes.
- General-purpose video understanding foundation tools built from image diffusion priors [sector: software/academia]
- Use cases: Unsupervised/zero-shot temporal segmentation, point tracking, and motion reasoning—extending the propagation kernel beyond masks (attributes, styles, edits).
- Assumptions/dependencies: Further research on cross-frame attention stability, multi-object tracking, occlusion recovery, and long-horizon coherence.
- Professional-grade medical/industrial inspection systems [sector: healthcare/manufacturing]
- Use cases: Clinical-grade endoscopy tracking, instrument/defect tracking in industrial inspection without video-specific training.
- Assumptions/dependencies: Extensive validation studies, regulatory approval (e.g., FDA/CE), domain adaptation for imaging modalities; resilient performance under artifacts.
- Advanced video editing and generative workflows [sector: media/software]
- Use cases: Temporal consistency in video editing and generative effects—propagating masks, styles, and localized edits across frames with minimal user input.
- Assumptions/dependencies: Tight integration with video diffusion/editing stacks; user experience design for prompt/textual inversion management; scalability to 4K+.
- Privacy-preserving analytics and policy frameworks [sector: policy/industry]
- Use cases: Standardized pipelines that enforce anonymization by default (propagated blurs); auditability of zero-shot tracking; benchmarks for fairness and dataset bias in tracking without supervised video training.
- Assumptions/dependencies: Governance, legal review, and transparent reporting; bias and robustness audits across demographics and environments.
- Semi-automated labeling ecosystems [sector: academia/industry]
- Products/workflows: Integrated platforms where mask propagation drastically reduces manual labeling time; automatic quality metrics; iterative correction loops; provenance records.
- Assumptions/dependencies: Seamless UX for human correction; scalable compute; compatibility with existing data curation tools.
- Edge IoT analytics for logistics and smart infrastructure [sector: energy/logistics/smart cities]
- Use cases: Track assets or components in maintenance videos with minimal training; generate operational insights from long-form footage.
- Assumptions/dependencies: Model compression; power/latency constraints; robust performance in low-light and noisy environments.
- Educational and research curricula on emergent capabilities in foundation models [sector: education/academia]
- Use cases: Hands-on courses exploring self-attention as propagation kernels; reproducible benchmarks on zero-shot video tasks; interdisciplinary studies (vision + generative modeling).
- Assumptions/dependencies: Open datasets, standardized tooling for extracting attention maps from diffusion models; community maintenance.
- Cross-modal extensions (audio/vision; multimodal prompts) [sector: software/research]
- Use cases: Conditioning temporal propagation with multimodal cues (text/audio) for richer tracking (e.g., tracking an instrument guided by its sound).
- Assumptions/dependencies: Research on multimodal conditioning of attention; data availability; new APIs for cross-modal integration.
- Energy-efficient inference strategies and hardware co-design [sector: energy/hardware]
- Use cases: Co-design of attention-centric accelerators for propagation; scheduling techniques for long videos; carbon-aware batch processing.
- Assumptions/dependencies: Collaboration with hardware vendors; workload characterization; performance–energy trade-off studies.
Cross-Cutting Assumptions and Dependencies
- Initial mask availability: Most applications depend on a high-quality first-frame mask; practical systems may pair Drift with detectors/segmenters to auto-initialize.
- Access to model internals: Extraction of self-attention maps requires models with accessible architecture (e.g., open-source text-to-image diffusion UNets).
- Compute and latency: Test-time optimization (DDIM inversion, textual inversion, head weighting) introduces runtime overhead; immediate deployments favor offline/batch scenarios.
- Domain shift and robustness: Natural-image pretraining can limit performance in specialized domains (medical/microscopy/thermal); SAM refinements mitigate but do not replace domain adaptation.
- Ethical and legal considerations: Tracking has privacy and misuse risks; policy-compliant deployments need anonymization by default, audit trails, and fairness evaluations.
- Multi-object/long-horizon complexity: While Drift supports multi-object propagation, heavy occlusions, scene cuts, and extreme motion remain challenging; longer videos may require memory mechanisms or re-initialization strategies.
Glossary
- Adaptive head weighting: A method that learns per-head weights to combine multi-head attention maps for better correspondence. Example: "adaptive head weighting"
- Aggregated self-attention: A combined attention map across layers/heads that emphasizes consistent semantic correspondences. Example: "Aggregated Self-attention"
- Argmax: An operation selecting the label with the highest score at each pixel. Example: "pixel-wise argmax"
- Binary cross-entropy (BCE): A loss function for binary classification or mask prediction tasks. Example: "binary cross-entropy"
- BLIP-2: A vision–LLM used here to generate object-specific captions for prompts. Example: "BLIP-2âgenerated object-specific captions"
- Boundary F-measure: A metric measuring boundary accuracy via the harmonic mean of boundary precision and recall. Example: "boundary F-measure"
- Cosine similarity: A feature-similarity measure using the cosine of the angle between vectors. Example: "Cosine Similarity"
- Cross-attention: Attention linking text and image tokens to highlight regions corresponding to textual prompts. Example: "cross-attention maps"
- Cross-frame attention map: An attention map that measures correspondences between different video frames for propagation. Example: "we compute a cross-frame attention map"
- Cross-frame label propagation kernel: An operator derived from attention that transports labels from one frame to another. Example: "repurposed as a cross-frame label propagation kernel"
- DDIM inversion: A technique that maps an image to its diffusion latent with model-predicted noise for semantic preservation. Example: "DDIM inversion"
- Diffusion models: Generative models that iteratively denoise noisy data to synthesize or analyze content. Example: "Diffusion models"
- Diffusion timesteps: Discrete steps controlling noise levels during diffusion denoising or inversion. Example: "Diffusion Timesteps"
- Drift: The proposed framework using diffusion features and SAM for zero-shot video object tracking via segmentation. Example: "we present Drift, a framework"
- Ground-truth (GT) mask: The reference segmentation mask provided for supervision or evaluation. Example: "GT mask"
- Intersection-over-Union (IoU): A region-overlap metric between predicted and ground-truth masks. Example: "IoU"
- Jaccard index: Another name for IoU, measuring the overlap between sets. Example: "Jaccard index"
- Label propagation: Spreading labels from known pixels/frames to others using learned affinities. Example: "label propagation"
- Latents: Internal latent representations used by diffusion processes. Example: "nearly noise-free latents"
- Logits: Pre-sigmoid/softmax scores from a model, used here to refine segmentation with SAM outputs. Example: "extract the logits associated with the selected SAM mask"
- Multi-head self-attention: Attention mechanism with multiple heads capturing diverse relations. Example: "multi-head self-attention"
- Query–key interactions: The dot-product similarity between query and key projections underlying attention. Example: "queryâkey interactions"
- Segment Anything Model (SAM): A foundation model producing masks from prompts (points/boxes), used for refinement. Example: "Segment Anything Model (SAM)"
- Self-attention: An attention mechanism relating different positions within the same feature map. Example: "self-attention maps"
- Semantic manifold: The structure of representations capturing semantic regularities learned by the model. Example: "modelâs learned semantic manifold"
- Softmax: A normalization turning scores into a probability distribution over options. Example: "softmax"
- Spatiotemporal attention: Attention across space and time to capture motion and appearance coherence in videos. Example: "spatiotemporal attention"
- Temporal label propagation: Extending label propagation across video frames to maintain consistency over time. Example: "Temporal Label Propagation via Self-Attention"
- Test-time optimization: Adaptation steps performed at inference to tailor the model to the instance/task. Example: "test-time optimization"
- Textual inversion: Learning new text embeddings (tokens) that steer diffusion features for a specific object. Example: "textual inversion"
- Top-k: A sparsification strategy keeping only the k highest scores to improve robustness. Example: "top-k scores"
- t-SNE: A dimensionality-reduction method for visualizing high-dimensional embeddings. Example: "t-SNE Embeddings"
- Video diffusion models: Diffusion models trained on videos with temporal modeling capability. Example: "Video diffusion models"
- Zero-shot: Performing a task without task-specific training data or supervision. Example: "zero-shot"
Collections
Sign up for free to add this paper to one or more collections.