- The paper introduces TorchQuantumDistributed, a PyTorch-based framework that enables distributed and differentiable quantum statevector simulation by sharding qubits across accelerators.
- It leverages optimized tensor reshaping, dimension grouping, and broadcasted matrix multiplication to efficiently apply quantum gates while maintaining gradient flow.
- It addresses quantum measurement noise using exact and reparameterized sampling methods and demonstrates strong scaling up to 1024 GPUs on high-qubit QML circuits.
Scalable Differentiable Quantum Statevector Simulation with TorchQuantumDistributed
Scalable quantum circuit simulation is essential for advancing Quantum Machine Learning (QML) and assessing quantum advantage in near-term and fault-tolerant regimes. Existing frameworks—Qiskit, Cirq, Pennylane, TorchQuantum—provide flexible Python APIs and increasingly integrate with hardware accelerators, but all either lack distributed statevector simulation capability or are limited to specific hardware ecosystems (e.g., CUDA-centric backends). This bottleneck restricts feasibility for high-qubit-count models that may exhibit quantum advantage over classical analogs, especially in QML workloads where differentiability is paramount (Asadi et al., 2024, Bergholm et al., 2018).
TorchQuantumDistributed (tqd) addresses these deficiencies by introducing a PyTorch-based, accelerator-agnostic, extensible library for differentiable distributed simulation. Critically, tqd supports sharding the quantum statevector across multiple accelerators, enabling simulations at higher qubit counts than with previous approaches, while retaining the modularity and automatic differentiation strengths of PyTorch [paszke2019pytorch].
Design and Implementation
TorchQuantumDistributed design principles are anchored in PyTorch's computational graph abstraction, providing both object-oriented and functional APIs. Gate definitions are centralized and programmatically generate both stateless functional and stateful module forms, minimizing code complexity.
Key implementation characteristics include:
Incorporating Quantum Measurement Noise
Quantum measurement is inherently stochastic (shot noise). tqd implements two methods to model this:
- Exact Sampling: Non-differentiable multinomial sampling, suitable for inference. When the global probability vector is sharded, tqd uses statistical properties of the multinomial to enable hierarchical distributed sampling with a single initial communication phase.
- Approximate Sampling via Reparameterization Trick: In the high-shot regime, the outcome distribution approximates a multivariate Gaussian. tqd leverages this for differentiable training runs, maintaining gradient flow by mapping samples through matrix factorization of the covariance (Householder transformation) [kingma2014auto-encoding].
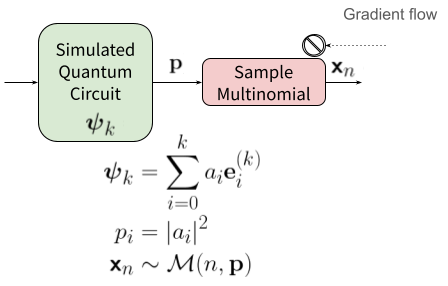
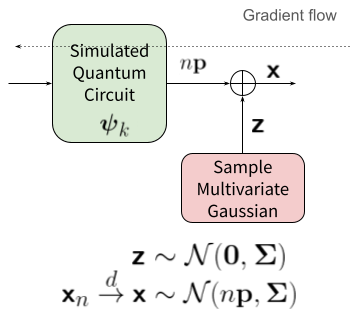
Figure 2: Left—exact sampling interrupts gradient flow. Right—approximate sampling via reparameterization maintains differentiability for training.
Computational Efficiency and Memory Optimization
Utilizing the invertible property of quantum unitary operations, tqd supports gradient computation by recomputing intermediate activations during backpropagation, significantly reducing memory consumption. The backward path reconstructs earlier layer activations from outputs using unitary conjugates, avoiding large activation storage.
Profiling and Scalability
Benchmark experiments executed on a multi-node HPC cluster with AMD MI250X accelerators validate tqd's scaling efficiency for a common QML ansatz—ladder-structured circuits comprising entangling CNOT and Pauli Y rotations. Tests involve both "strong" and "weak" scaling, up to 1024 GPUs and problems ranging from 18 to 28 qubits.
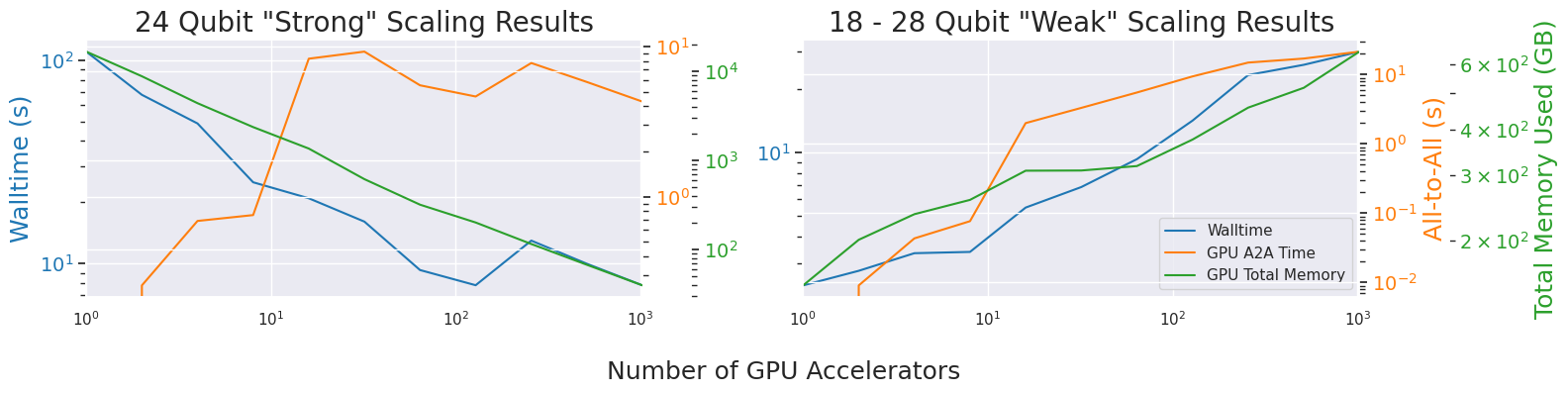
Figure 3: Strong and weak scaling for tqd simulation across 1–1024 accelerators on 18–28 qubit circuits; profiling walltime, NCCL communication, and GPU memory.
Key findings:
- Walltime decreases with increased accelerators at near-theoretical rates, indicating robust scaling, with communication and memory costs remaining manageable up to 24 qubits and 1024 GPUs.
- tqd enables higher-qubit-count simulation with differentiable workflows unattainable with non-distributed frameworks.
- Favorable power-law trends for compute overhead and communication suggest practical usability at substantial circuit sizes.
Implications and Future Directions
The tqd framework substantially enhances the capabilities for studying large-scale, learnable quantum circuits under realistic hardware constraints. Enabling both differentiable simulation and distributed statevector management unlocks progress for QML model research, quantum-inspired ML, and performance profiling relevant to real quantum hardware.
Theoretical implications center on tractable exploration of quantum advantage boundaries and algorithmic development for hybrid quantum-classical systems. Practically, tqd may catalyze new research in QML pipelines, inform optimal circuit compilation, and support benchmarking for both simulator and device backends.
Future work includes profiling peak memory/network I/O, integrating circuit-cutting and knitting methods to further mitigate communication overhead, and refining support for heterogeneous and emergent accelerator architectures.
Conclusion
TorchQuantumDistributed advances scalable, hardware-agnostic, differentiable quantum circuit simulation via distributed statevector handling, modular extensibility, and efficient handling of quantum measurement noise. Profiling demonstrates favorable scaling in high-qubit count QML ansatze across large accelerator clusters. These contributions position tqd as a practical and theoretically meaningful tool for quantum ML research and development (2511.19291).
