C3Po: Cross-View Cross-Modality Correspondence by Pointmap Prediction
Abstract: Geometric models like DUSt3R have shown great advances in understanding the geometry of a scene from pairs of photos. However, they fail when the inputs are from vastly different viewpoints (e.g., aerial vs. ground) or modalities (e.g., photos vs. abstract drawings) compared to what was observed during training. This paper addresses a challenging version of this problem: predicting correspondences between ground-level photos and floor plans. Current datasets for joint photo--floor plan reasoning are limited, either lacking in varying modalities (VIGOR) or lacking in correspondences (WAFFLE). To address these limitations, we introduce a new dataset, C3, created by first reconstructing a number of scenes in 3D from Internet photo collections via structure-from-motion, then manually registering the reconstructions to floor plans gathered from the Internet, from which we can derive correspondence between images and floor plans. C3 contains 90K paired floor plans and photos across 597 scenes with 153M pixel-level correspondences and 85K camera poses. We find that state-of-the-art correspondence models struggle on this task. By training on our new data, we can improve on the best performing method by 34% in RMSE. We also identify open challenges in cross-modal geometric reasoning that our dataset aims to help address.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to match what you see in a ground-level photo (like a picture you take with your phone) to the right spot on a flat, top-down floor plan (like a museum map). That’s hard because:
- The views are very different (ground view vs. bird’s-eye view).
- The styles are very different (real photos vs. simple, line-drawing maps).
The authors create a big new dataset to train and test computer vision models on this exact challenge, and they build a method, called C3Po, that improves how well computers can find these matches.
What questions did the researchers ask?
Here are the main questions the paper explores:
- Can a computer find which point in a floor plan matches a point seen in a ground-level photo?
- Do today’s best matching methods (built for photo-to-photo) work when the inputs are so different (photo-to-plan)?
- If not, can training on a new, carefully built dataset make these methods work better?
How did they do the research?
First, they built a new dataset called C3 (Cross-View, Cross-Modality Correspondence). Then they trained and tested models on it.
Here’s how they made the dataset, in everyday terms:
- Finding floor plans: They collected thousands of real floor plan images (like church layouts, castles, temples) from Wikimedia Commons.
- Finding matching photos: They gathered lots of ground-level photos of the same places from big public photo sets (like MegaScenes and YFCC100M).
- Figuring out which photo points match which floor plan points:
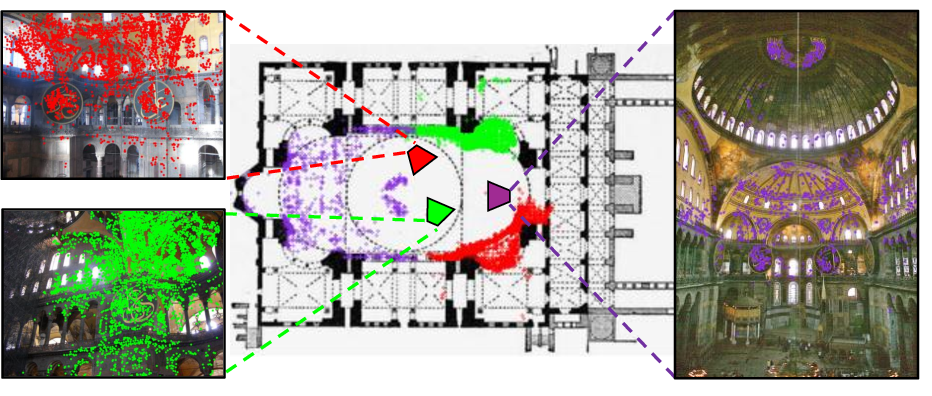
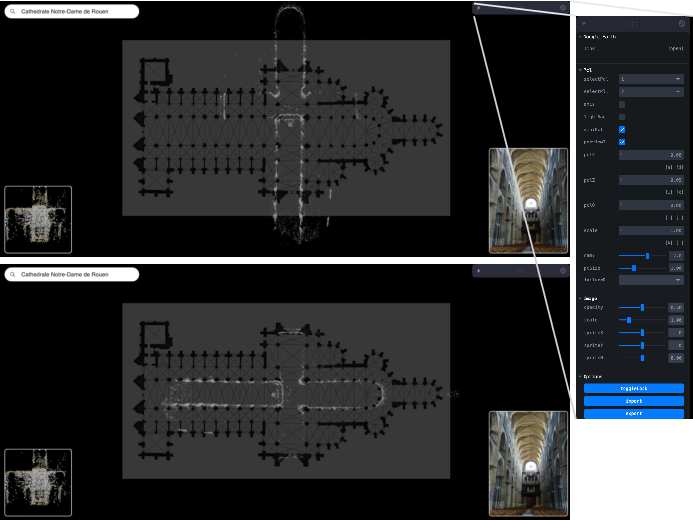
- They used a standard 3D reconstruction tool called COLMAP. Think of COLMAP as taking a bunch of overlapping photos and rebuilding a rough 3D “point cloud” of the place, plus the position of each camera (where each photo was taken).
- Next, a person lined up this 3D point cloud with the floor plan by shifting, rotating, and scaling it in 2D (like fitting a puzzle piece onto a map).
- Once aligned, any 3D point seen in a photo can be “projected” onto the floor plan, giving pairs of matching points: one in the photo, one on the plan. This creates millions of accurate “correspondences” without drawing them all by hand.
What is a “point cloud”? It’s a set of many dots in 3D space that outline the shape of a place, like a sparse 3D sketch made from photos.
What is a “correspondence”? It’s a pair of points—one in the photo and one on the floor plan—that refer to the same real-world spot (for example, the center of a doorway).
How did they build their method (C3Po)?
- They started with a modern model called DUSt3R, which predicts a “pointmap.” A pointmap links each pixel in a photo to a 3D point in space.
- They trained (fine-tuned) DUSt3R on the new C3 dataset so it could handle photos and floor plans together.
- To turn DUSt3R’s 3D output into a floor-plan point, they used an “orthographic projection,” which you can think of as dropping the “height” and looking straight down—just like a map.
What did they find?
They built a large, high-quality dataset:
- 597 scenes (places) with 648 unique floor plans
- About 85,000 ground-level photos
- Around 90,000 floor plan–photo pairs
- 153 million pixel-level correspondences
- A known camera pose (where the photo was taken) for each photo
They tested many top methods (SuperGlue, LoFTR, DINOv2, DIFT, RoMa, DUSt3R, MASt3R). These methods are great at photo-to-photo matching, but they struggled when matching photos to floor plans. Errors were often large because the viewpoint and the visual style are so different.
After training on C3, their adapted method (C3Po) improved the error by 34% (lower RMSE) compared to the best baseline.
What does “RMSE” mean? It’s a way to measure average error—smaller is better. Imagine measuring how far each predicted point is from the correct point on the floor plan; RMSE summarizes these distances.
They also looked at:
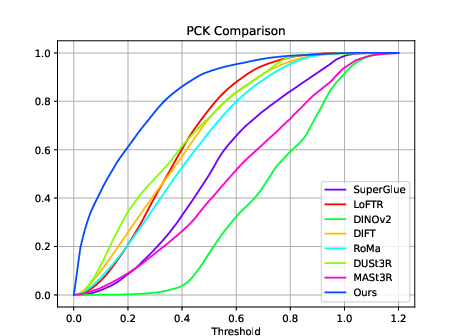
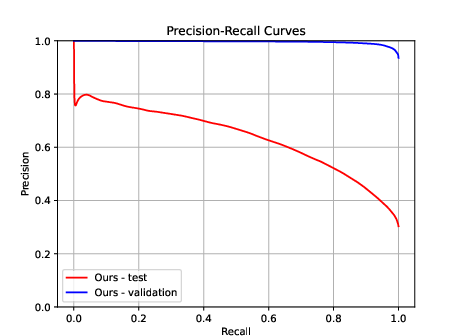
- PCK (Percentage of Correct Keypoints): what fraction of points land “close enough” to the right place (higher is better).
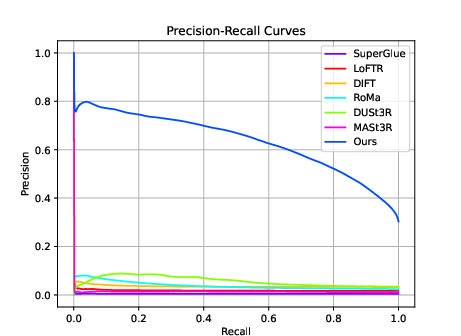
- Precision–Recall: how reliable the model’s confident matches are across different confidence levels.
C3Po scored better on these too.
They identified two big remaining challenges:
- Minimal context photos: Close-ups (like just a door or a painting) give too few clues about where you are on the plan.
- Symmetry: Some buildings (like churches or temples) have repeated, mirror-like structures, making multiple positions look equally plausible from a single photo.
Why does this matter?
This research helps computers connect what we see from the ground to what’s drawn on a map. That can:
- Help robots or AR navigation systems figure out where they are using just a floor plan and a few photos.
- Improve 3D reconstruction of places when photos don’t overlap much, by using the floor plan to tie everything together.
- Enable new tasks, like:
- Finding exactly where a photo was taken on a floor plan (camera localization).
- Generating images from floor plans.
- Reconstructing floor plans from photos.
In short, the dataset and method push computer vision toward understanding spaces the way people do: linking real-world views to simplified maps. It’s a step toward smarter navigation, better mapping, and more reliable 3D scene understanding.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to be actionable for future work.
- Ground-truth validation: The correspondences and camera poses rely on SfM plus manual point-cloud-to-plan alignment; the paper does not quantify annotation accuracy, inter-annotator agreement, or alignment uncertainty. Establish rigorous QA (e.g., repeat-alignments, consensus metrics, uncertainty labels) and measure how label noise affects model training and evaluation.
- Transform model adequacy: Alignment is restricted to 2D similarity transforms (translation/rotation/scale) in plan coordinates, assuming an orthographic plan and negligible non-linear distortions. Investigate whether homographies or non-rigid warps are needed for plans with distortions, perspective, or hand-drawn inaccuracies, and quantify downstream impacts.
- Orthographic projection assumption: C3Po drops the y coordinate ((x, y, z) → (x, z)) to project to the plan, assuming “up” is orthogonal to the plan. Evaluate cases where this assumption fails (multi-level spaces, mezzanines, sloped terrain, non-horizontal floors) and design a principled mapping from 3D to plan coordinates (e.g., learned plan-plane estimation, floor-aware projection).
- Sparse-to-dense supervision gap: “Pixel-level correspondences” are derived from sparse reconstructed points projected to 2D. Assess how sparsity biases training (toward textured, well-lit regions), and develop densification strategies (e.g., MVS depth, synthetic renderings from BIM/CAD, semi-supervised pseudo-labeling) to obtain more uniform coverage.
- Baseline fairness and adaptation: Only DUSt3R is fine-tuned on C3, while other baselines are used off-the-shelf. Conduct controlled fine-tuning/adaptation of LoFTR, RoMa, DIFT, MASt3R, and feature-based methods on C3 to ensure equitable comparison and reveal which architectural choices best transfer to cross-modal matching.
- Failure mode quantification: The paper qualitatively reports two failure categories (“minimal context” and “structural symmetry”) but does not quantify their prevalence or severity. Create per-scene and per-pair difficulty labels, measure error distributions across category bins, and establish targeted benchmarks for ambiguity-aware correspondence.
- Ambiguity-aware prediction: Current models output point estimates; they do not express multi-modal correspondences under symmetry or limited context. Develop uncertainty- or distributional predictions (e.g., diffusion-based, mixture density networks, conformal sets) and design metrics (e.g., coverage vs. set size) to evaluate ambiguity handling.
- Multi-image reasoning: The method matches single photos to a plan and does not leverage multiple views from the same scene to resolve ambiguity. Explore joint inference across sets of images (temporal aggregation, graph matching over camera trajectories, bundle-adjusted correspondences) to reduce uncertainty.
- Floor plan semantics: The approach treats floor plans as raw images and does not exploit semantic symbols (walls, doors, domes, labels, axes). Investigate plan parsing (symbol detection, topology graphs), text understanding, and scene graph alignment to improve geometric reasoning and disambiguation.
- Cross-modality scope: The dataset and method focus on floor plans vs. ground-level photos. Evaluate generalization to other modalities (satellite/aerial orthophotos, elevations/sections, CAD/BIM, sketches), and study cross-domain adaptation strategies and universal encoders for structured 2D representations.
- Multi-floor buildings and components: Composite/ambiguous plans and smaller components are discarded, and only two largest components per scene are aligned. Extend alignment to all components, annotate floor-level associations, and benchmark correspondences across multi-story and composite plans.
- Plan orientation and scale normalization: Many plans have unknown or inconsistent orientation/scale. Propose automatic plan normalization (estimating canonical axes, scale calibration from known dimensions) and examine how normalization improves correspondence accuracy and cross-scene transfer.
- Camera-to-plan pose benchmark: Although camera poses and plan alignments exist, the paper does not evaluate camera localization relative to the plan. Establish a standardized camera-to-plan pose task, metrics (position/orientation error), and baselines leveraging correspondences and plan topology.
- Robustness to plan quality and style: Plans sourced from Wikimedia vary in style (hand-drawn, schematic, scanned PDFs), cleanliness, and fidelity. Quantify performance across plan styles, introduce style augmentation/normalization, and measure model sensitivity to plan artifacts (noise, skew, compression).
- Geographic and scene-type biases: Wikimedia/MegaScenes/YFCC sourcing likely introduces geographic and scene-type skew (e.g., iconic landmarks, religious buildings). Audit dataset composition, report diversity metrics (region, building type), and study domain imbalance and its effect on generalization.
- Impact of YFCC geo-tag noise: Supplementing photos via YFCC within 50 m may introduce incorrect or irrelevant images. Quantify geo-tag reliability and its effect on reconstruction/labels; incorporate location filtering/verification (e.g., visual place recognition, metadata cross-checking).
- Losses and training ablations: The paper does not ablate key design choices (encoder splitting, plan augmentations, projection axis choice, loss components). Perform systematic ablations to identify which choices drive gains and to inform reproducible training protocols.
- Evaluation metrics: RMSE/PCK/PR are computed in normalized plan coordinates and may not reflect structural/topological alignment quality. Introduce structure-aware metrics (e.g., wall/door-level IoU, topological correctness, plan graph alignment distance) and scene-level success criteria.
- Runtime and deployment constraints: Training uses 8×A6000 over 3 days; inference efficiency and memory footprint are not reported. Benchmark throughput/latency, study model compression/distillation, and assess feasibility for robotics or mobile deployment.
- Integration with SLAM/SfM: The paper motivates SfM usage but does not evaluate how predicted correspondences improve SfM/SLAM (merging disjoint components, stabilizing reconstruction). Create pipelines and metrics for reconstruction improvement from plan-conditioned correspondences.
- Automated point-cloud-to-plan alignment: Manual alignment is a bottleneck. Explore automatic alignment (coarse-to-fine registration via plan parsing, learned aligners, weak supervision) and measure accuracy/efficiency trade-offs vs. manual alignment.
- Handling non-structural imagery: Many photos emphasize art, furniture, or close-ups lacking structural cues. Develop filters or detectors for “non-structural” content, or augment models with semantic priors to infer plausible structural correspondences under limited cues.
- Calibration and confidence: For PR curves, confidence calibration is not discussed. Implement and evaluate calibration (e.g., temperature scaling, reliability diagrams) for correspondence confidence to improve thresholding and downstream decision-making.
- Data release completeness: It is unclear whether alignment transforms, component IDs, plan metadata (style, scale), and uncertainty estimates will be released. Specify and include these artifacts to enable reproducible research and improved baselines.
- Proposed tasks left untested: The paper lists applications (image localization on plan, plan-conditioned image generation, image-to-plan generation) without benchmarks or baselines. Define task protocols, datasets splits, metrics, and initial baselines to catalyze progress.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can be built today using the C3 dataset and the C3Po approach (DUSt3R fine-tuned for photo–floor plan correspondences), acknowledging current accuracy and limitations.
- Photo-to-floor-plan localization service for public venues
- Sector: tourism, cultural heritage, education, facilities
- Description: A mobile app or kiosk that takes a visitor’s photo and places a marker on the venue’s floor plan, aiding wayfinding and tour guidance in museums, cathedrals, campuses, historic sites.
- Tools/products/workflows: “C3Po Correspondence API” for photo→plan pixel mapping; client-side AR overlay; backend mapping to canonical floor-plan coordinates; lightweight orthographic projection to convert 3D pointmaps to 2D plan coordinates.
- Assumptions/dependencies: Access to canonical floor plans (correct orientation, scale); enough contextual content in the photo (non-ambiguous landmarks); accuracy sufficient for coarse positioning (current errors still higher than classical matching tasks); privacy and licensing of venue imagery.
- SfM/photogrammetry pipeline augmentation for dataset registration
- Sector: software (photogrammetry), 3D mapping, digital heritage
- Description: Use photo–plan correspondences to register disjoint SfM components and improve alignment of reconstructions to canonical plan views, especially when image overlap is sparse.
- Tools/products/workflows: COLMAP plug-in or script that ingests C3Po correspondences; workflow to estimate similarity transforms (2D translation, rotation, scale) and merge components; export camera poses in plan coordinates.
- Assumptions/dependencies: Reliable floor-plan alignment procedure; availability of at least sparse structure from SfM; correspondences robust enough to constrain transforms; plan abstractions match the photographed structural geometry.
- Robotics pilot: map-based localization from sparse ground images
- Sector: robotics (service robots, inspection), logistics
- Description: In controlled environments (e.g., museums after hours, university buildings), robots can use a floor-plan prior plus a few onboard camera frames to localize approximately on the plan.
- Tools/products/workflows: ROS node wrapping C3Po’s correspondence prediction; fusion with odometry/IMU to stabilize poses; heuristic ambiguity resolution (e.g., temporal consistency, human-in-the-loop confirmation).
- Assumptions/dependencies: Floor plans available and accurate; sufficient visual cues; need for additional sensors to mitigate symmetry/minimal-context failures; acceptable localization accuracy for non-critical navigation.
- Academic benchmarking and training for cross-view, cross-modality correspondence
- Sector: academia (computer vision, robotics, graphics)
- Description: Use C3 for standardized evaluation of cross-view/cross-modality matching; train/fine-tune correspondence models and pointmap predictors; study structured failure modes (minimal context, symmetry).
- Tools/products/workflows: Public dataset and leaderboards; training recipes for split Siamese encoders; augmentation pipelines; error analysis toolkits (PCK, PR, RMSE).
- Assumptions/dependencies: Community adoption; reproducible baselines; compute resources (GPU) for training; clarity on licensing for redistribution.
- Curated digital tours and content indexing
- Sector: media/entertainment, cultural heritage
- Description: Align crowd-sourced images to floor plans to build guided tours, spatially indexed photo galleries, and exhibit-level content retrieval.
- Tools/products/workflows: Batch processing pipeline that maps photos to floor-plan coordinates; exhibit metadata linking; UI for browsing plan-linked media.
- Assumptions/dependencies: Plan–exhibit metadata availability; moderation of user-generated content; image licensing; acceptance of coarse localization errors.
- Facility analytics from photo streams
- Sector: facilities management, operations
- Description: Aggregate timestamped photos and camera poses to estimate visitor density by region, identify underused areas, and monitor signage effectiveness relative to floor plan layouts.
- Tools/products/workflows: Data pipeline for photo→plan mapping; heatmap visualization; BI dashboard integration.
- Assumptions/dependencies: Policies allowing analysis of photo streams; anonymization; sufficient coverage and representative sampling; plan fidelity to current layout.
Long-Term Applications
The following use cases require further research and engineering (e.g., handling symmetry, low-context images, domain generalization, tighter accuracy), as well as scaling and integration.
- Indoor AR navigation with robust cross-modal localization
- Sector: mobile/AR, retail, transportation hubs, healthcare
- Description: Real-time mapping of smartphone camera frames to floor plans for precise indoor wayfinding (airports, malls, hospitals), replacing QR codes or beacons.
- Tools/products/workflows: AR Wayfinding SDK combining C3Po-like correspondences with SLAM and inertial sensors; multi-floor disambiguation; semantic cue integration (doors, domes, signage).
- Assumptions/dependencies: Substantially lower localization error; robust handling of occlusions, lighting, crowd variability; high-quality, standardized floor plans; privacy and latency constraints.
- Emergency response localization (vision-to-plan)
- Sector: public safety, policy
- Description: Helmet or body-cam feeds mapped to floor plans to localize firefighters, paramedics, or police inside complex buildings in smoke/low light.
- Tools/products/workflows: Edge inference on ruggedized devices; fusion with thermal imagery and radio beacons; uncertainty-aware multi-hypothesis tracking; command center visualization.
- Assumptions/dependencies: Models trained for extreme conditions; strong ambiguity resolution; standardized, up-to-date building plans; secure data handling; policy frameworks for plan access (e.g., code requirements for digital plan availability).
- Construction/BIM progress tracking and QA
- Sector: construction, AEC (architecture, engineering, construction)
- Description: Map site photos to floor plans (and to as-built BIM) for progress audits, punch lists, and anomaly detection.
- Tools/products/workflows: BIM plug-in that aligns photo evidence to plan layers; change detection workflows; integration with CDE (Common Data Environment).
- Assumptions/dependencies: Plan–BIM synchronization; robustness to evolving layouts and occlusions; industry adoption of cross-modal QA workflows.
- Automated image-to-floor-plan generation and validation
- Sector: real estate, AEC, software
- Description: From a limited set of interior/exterior photos, generate or refine floor plans; perform plan validation against observed imagery.
- Tools/products/workflows: Generative models trained on C3-like correspondences; plan synthesis and constraint satisfaction (e.g., room adjacency); human-in-the-loop correction tools.
- Assumptions/dependencies: High-quality training data across building types; strong priors to resolve symmetry; compliance with property data privacy and licensing.
- Floor-plan–conditioned image and scene generation
- Sector: visualization, media, virtual staging
- Description: Generate photorealistic views of a scene from a given floor plan and virtual camera pose (e.g., marketing, simulation, virtual tours).
- Tools/products/workflows: Conditional generative models (diffusion/NeRF hybrids) seeded from plan geometry and camera pose; rendering pipelines for multi-view consistency.
- Assumptions/dependencies: Large-scale paired plan–photo data across domains; accurate camera-to-plan pose estimation; rendering fidelity and multi-view coherence.
- Digital twin alignment across modalities (satellite, ground, plans)
- Sector: smart cities, urban planning, infrastructure
- Description: Fuse aerial imagery, street-level photos, and floor plans into unified, queryable digital twins for planning, accessibility routing, and maintenance.
- Tools/products/workflows: Multi-modal correspondence stack; topology-aware graph linking of building interiors to exteriors; APIs for cross-layer queries.
- Assumptions/dependencies: Data standardization (plan formats, georeferencing); handling scale/orientation across modalities; governance and access controls.
- Security and operations: real-time incident localization on floor plans
- Sector: security, facilities operations
- Description: Map CCTV or mobile footage to floor plans to quickly localize incidents and dispatch responders.
- Tools/products/workflows: On-prem inference for privacy; integration with VMS (video management systems); uncertainty-aware alarms; audit trails.
- Assumptions/dependencies: Legal and ethical use of imagery; reliable performance under low light and occlusions; integration with existing security infrastructure.
- Insurance and risk assessment
- Sector: finance/insurance
- Description: Map claim photos to floor plans to validate damage location, assess risk exposure, and expedite claims.
- Tools/products/workflows: Claims ingestion pipeline; plan-linked evidence repository; automated consistency checks against declared property layouts.
- Assumptions/dependencies: Access to accurate floor plans; standardized policy workflows; model reliability across residential and commercial properties.
Cross-cutting assumptions and dependencies
- Data availability and quality: Canonical, up-to-date floor plans with consistent scale, orientation, and annotations; scene photos with sufficient contextual cues.
- Ambiguity and symmetry: Many buildings exhibit repeated patterns; methods may need distributional outputs or multi-hypothesis tracking to resolve.
- Domain generalization: Current training data skews toward public landmarks; models must be adapted to residential, commercial, and industrial settings.
- Accuracy expectations: Although C3Po improves RMSE by 34% over the best baseline, error remains higher than traditional correspondence tasks; critical applications need additional sensors and fusion.
- Standards and policy: Benefits grow with standardized digital plan formats and policies enabling secure plan access for safety-critical use cases.
- Compute and deployment: Training requires significant GPU resources; inference must be optimized for edge/mobile devices in real-time scenarios.
- Legal/privacy/licensing: Use of photos and floor plans must respect IP, privacy, and data protection regulations.
Glossary
- Bilinear interpolation: A resampling method that upsamples images by linearly interpolating in two dimensions. "upsample the features to full image resolution using bilinear interpolation"
- Bird's-eye view: An overhead viewpoint that looks down on a scene from above. "The interface displays a floor plan and a bird's-eye-view of a point cloud."
- Camera pose: The position and orientation of a camera in 3D space. "COLMAP estimates a 3D camera pose for each image"
- COLMAP: A popular structure-from-motion pipeline for reconstructing 3D scenes and estimating camera poses from images. "Given a set of images, COLMAP estimates a 3D camera pose for each image"
- Cosine similarity: A measure of similarity between feature vectors based on the cosine of the angle between them. "then compute pixel correspondence with cosine similarity."
- Cross-modal: Involving different data modalities (e.g., photos vs. floor plans). "cross-view, cross-modal correspondences"
- Cross-view: Involving different viewpoints (e.g., aerial vs. ground-level views). "Exacerbating this cross-view challenge is the fact that the modality is also different:"
- Dense matching: Estimating correspondences at (near) every pixel across images. "a combination of sparse, semi-dense, and dense matching algorithms:"
- DIFT: A method leveraging image diffusion to obtain correspondence features. "For LoFTR, DIFT, and RoMa, we can sample correspondences directly with pixel coordinates."
- DINOv2: A self-supervised vision model that produces robust visual features. "DINOv2 outputs patch-level features"
- Diffusion models: Generative models that learn data distributions via iterative noise addition and removal. "e.g., with diffusion models would be more appropriate in such cases."
- Disjoint components: Separate, unconnected parts of a reconstruction graph or point cloud. "For some scenes, COLMAP on MegaScenes photos results in disjoint components and very sparse reconstructions."
- DUSt3R: A model that predicts scene geometry and pointmaps from image pairs. "At its core, DUSt3R predicts a pointmap which creates a one-to-one mapping between 2D image pixels to 3D scene points, and we turn this pointmap prediction into a correspondence prediction."
- Euclidean distance: Straight-line distance used as an error metric between predicted and ground-truth points. "our distance metric is the Euclidean distance."
- Exhaustive matching: A matching strategy that considers all possible image pairs. "we use exhaustive matching with default parameters."
- Feature extraction: Computing descriptive features from images to support matching and reconstruction. "We use default parameters for feature extraction and sparse reconstruction."
- Geometric augmentations: Data augmentation using geometric transforms like cropping and rotation. "geometric augmentations (cropping and rotation) on the floor plans."
- Geotagged: Images annotated with geographic coordinates. "Since YFCC100M photos are geotagged,"
- LoFTR: A detector-free transformer-based dense feature matching method. "For LoFTR, DIFT, and RoMa, we can sample correspondences directly with pixel coordinates."
- MASt3R: A 3D-grounded image matching network built on DUSt3R. "With MASt3R, we provide the input images in the same order as DUSt3R."
- Model merger: A COLMAP post-processing step to merge overlapping reconstructed components. "we run COLMAP's model merger on all pairs of reconstructed 3D components for each scene."
- Nearest neighbor interpolation: A simple resampling method that assigns each output pixel the value of the nearest input sample. "we perform nearest neighbor interpolation to create a dense correspondence map."
- Orthographic projection: A projection that maps 3D points to 2D by dropping one coordinate axis. "perform an orthographic projection "
- Patch-level features: Visual features computed per image patch rather than per pixel. "DINOv2 outputs patch-level features"
- PCK (Percent of Correct Keypoints): A metric measuring the fraction of keypoints predicted within a threshold of the ground truth. "The middle graph shows percent of correct keypoints (PCK)"
- Pixel correspondence: Matching pixels across images that represent the same real-world point. "Pixel correspondence, the process of finding matching points in different images that represent the same point in the real world, is a fundamental task in computer vision"
- Point cloud: A set of 3D points representing scene geometry. "Aligning these point clouds with the floor plan thus directly yields correspondences"
- Pointmap: A mapping from 2D image pixels to 3D scene points predicted by DUSt3R. "DUSt3R's pointmap representation maps each photo pixel to a 3D point at location in the floor plan's coordinate frame."
- Precision-Recall (PR) curves: Curves summarizing the trade-off between precision and recall across confidence thresholds. "The right graph displays Precision-Recall (PR) curves"
- Registration: Aligning one dataset to another via transformations (e.g., point clouds to floor plans). "then manually registering the reconstructions to floor plans"
- RMSE: Root Mean Square Error, a measure of average prediction error magnitude. "We can improve on the best performing method by 34\% in RMSE."
- RoMa: A robust dense feature matching method. "For LoFTR, DIFT, and RoMa, we can sample correspondences directly with pixel coordinates."
- Self-supervised features: Features learned without labeled data using self-supervised objectives. "Self-supervised feature representations like DINO~\citep{oquab2023dinov2} or DIFT~\citep{tang2023emergent} have been shown to allow for cross-modality correspondences."
- Siamese encoders: Two encoders with shared architecture (often weights) processing paired inputs. "we split the DUSt3R's Siamese encoders"
- Sparse reconstruction: A reconstruction capturing only a subset of points (e.g., keypoints) in the scene. "We use default parameters for feature extraction and sparse reconstruction."
- Structure-from-Motion (SfM): Reconstructing 3D structure and camera motion from multiple images. "challenging structure-from-motion (SfM) problems"
- SuperGlue: A graph neural network-based matcher that produces sparse correspondences. "Since SuperGlue produces sparse correspondences, we perform nearest neighbor interpolation"
- Vocabulary tree matching: An approximate image matching technique using a hierarchical visual vocabulary. "we instead use vocabulary tree matching with 40 nearest neighbors."
- Wilcoxon signed-rank test: A non-parametric statistical test for paired samples. "We perform the Wilcoxon signed-rank test, a non-parametric paired test, between our error and each baseline"
- YFCC100M: A large dataset of Flickr images used for multimedia research and augmentation. "For some scenes, we also collect additional photos from YFCC100M"
Collections
Sign up for free to add this paper to one or more collections.

