- The paper demonstrates that LLM assistants improved human forecasting accuracy by up to 43% compared to control conditions.
- It employed a controlled experiment with 991 participants across diverse forecasting tasks using superforecasting and biased LLM assistants.
- The findings imply that AI-assisted forecasting boosts decision-making in complex domains and challenges conventional views on skill-related AI benefits.
"AI-Augmented Predictions: LLM Assistants Improve Human Forecasting Accuracy" Essay
Introduction
The paper "AI-Augmented Predictions: LLM Assistants Improve Human Forecasting Accuracy" explores the effect that LLMs have on human judgment in forecasting tasks. With the continuous development of LLMs such as GPT models, there is a growing interest in their ability to enhance human cognitive tasks, especially in complex domains like economic and geopolitical forecasting. This study aims to test whether LLM augmentation—via AI assistants—can substantially improve human performance in forecasting future events.
Study Design and Methodology
The research employed a controlled experimental setup with 991 participants interacting with one of three different LLM conditions: a superforecasting LLM assistant, a biased LLM assistant, and a control group using a simpler DaVinci-003 model. Participants were tasked with forecasting real-world future events including financial, geopolitical, and other quantitative predictions. The accuracy of these forecasts formed the central dependent variable for evaluation.
Participants in the experimental groups could interact freely with their assigned LLMs, engaging in dialogues that ranged from seeking direct forecasts to receiving feedback on their initial predictions. The impact of LLM augmentation was measured through the accuracy of their forecasts, calculated as the deviation from the true values of the forecasted questions. Preregistered analyses compared the mean forecasting accuracy across different conditions using statistical tests such as ANOVA and regression analysis.
Figure 1: Treatment interface.
Results
The study found that both LLM assistants significantly improved forecasting accuracy over the control group, exhibiting a 23% enhancement in forecasting performance. Notably, this improvement was consistent across both the superforecasting and biased LLM assistants, suggesting that the accurate guidance in forecasting is not purely dependent on the model's intrinsic accuracy.
This suggests potential synergies between human forecasters and LLMs, wherein even a biased assistant can provide beneficial support when used interactively. However, exploratory analyses revealed a pronounced discrepancy in one specific forecasting item. Without this outlier, the superforecasting assistant showed a 43% increase in accuracy over controls, while the biased assistant showed a 28% increase.
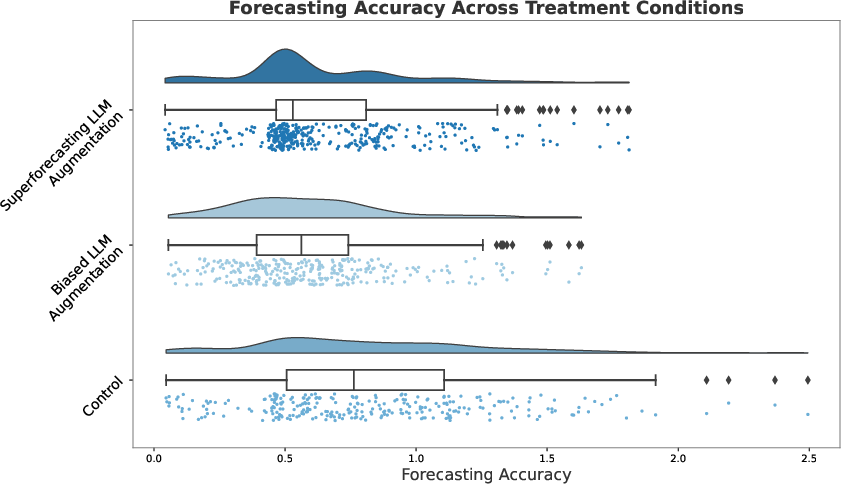
Figure 2: Raincloud plot of forecasting accuracy by condition.
The analysis also explored whether LLM augmentation disproportionately benefits low-skill forecasters, a hypothesis not consistently supported by the data. This prompted further investigation into the role of varying forecasting question difficulty, where no consistent differential impact was found across question difficulties.
Discussion
The implications of this research are twofold. Practically, the use of LLMs in decision-heavy environments such as law, business, and policy could enhance productivity and decision accuracy. Theoretically, the findings challenge the commonly held belief that AI benefits disproportionately accrue to less skilled individuals, at least within the forecasting domain.
Importantly, the study highlights the potential of LLMs to assist in tasks beyond their conventional benchmark usage, allowing for strategic human-machine collaborations. The model's ability to foster improved performance, even with biased assistance, questions the narrowly defined narrative of LLM utility and prompts reevaluation of how AI might be integrated into human frameworks to maximize collective output.
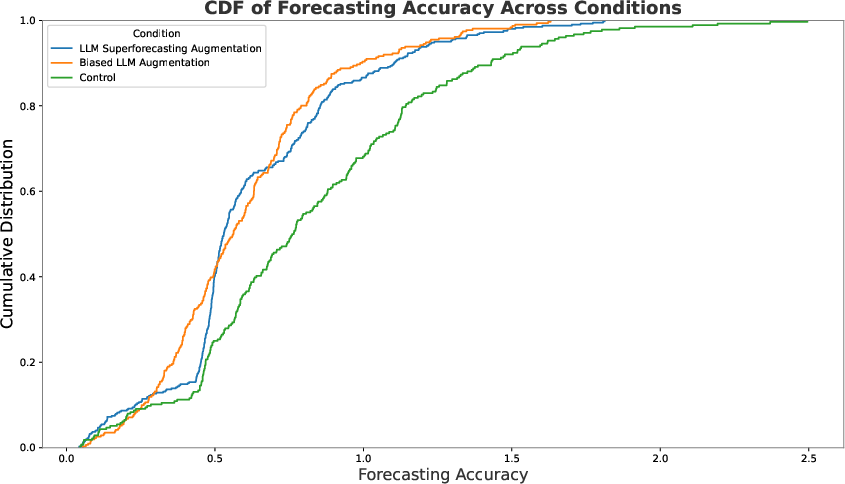
Figure 3: CDF of forecasting accuracy by condition.
Conclusion
This paper substantiates the proposition that LLMs augment human forecasting capabilities effectively across diverse tasks. The positive impact is prevalent even with a seemingly less reliable biased assistant, marking this a pivotal step in understanding how AI might serve broader functions in aiding human cognition. Future inquiries should focus on dissecting the nuanced interplay between human and AI reasoning, to discern optimal conditions for AI deployment across varied cognitive domains.