UltraFlux: Data-Model Co-Design for High-quality Native 4K Text-to-Image Generation across Diverse Aspect Ratios
Abstract: Diffusion transformers have recently delivered strong text-to-image generation around 1K resolution, but we show that extending them to native 4K across diverse aspect ratios exposes a tightly coupled failure mode spanning positional encoding, VAE compression, and optimization. Tackling any of these factors in isolation leaves substantial quality on the table. We therefore take a data-model co-design view and introduce UltraFlux, a Flux-based DiT trained natively at 4K on MultiAspect-4K-1M, a 1M-image 4K corpus with controlled multi-AR coverage, bilingual captions, and rich VLM/IQA metadata for resolution- and AR-aware sampling. On the model side, UltraFlux couples (i) Resonance 2D RoPE with YaRN for training-window-, frequency-, and AR-aware positional encoding at 4K; (ii) a simple, non-adversarial VAE post-training scheme that improves 4K reconstruction fidelity; (iii) an SNR-Aware Huber Wavelet objective that rebalances gradients across timesteps and frequency bands; and (iv) a Stage-wise Aesthetic Curriculum Learning strategy that concentrates high-aesthetic supervision on high-noise steps governed by the model prior. Together, these components yield a stable, detail-preserving 4K DiT that generalizes across wide, square, and tall ARs. On the Aesthetic-Eval at 4096 benchmark and multi-AR 4K settings, UltraFlux consistently outperforms strong open-source baselines across fidelity, aesthetic, and alignment metrics, and-with a LLM prompt refiner-matches or surpasses the proprietary Seedream 4.0.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces UltraFlux, a system that turns text descriptions into very high‑quality, native 4K images (super sharp and detailed), no matter if the picture is wide, square, or tall. The key idea is to design the training data and the model together so they fit each other perfectly. This “co‑design” helps the model avoid common problems that happen when making huge images.
Key Objectives
The researchers set out to answer a few simple questions:
- How can we create a text‑to‑image model that makes true 4K pictures across many shapes (aspect ratios) without weird artifacts like stripes, blur, or drifting details?
- What kind of 4K dataset do we need so the model learns both high detail and good taste (aesthetics)?
- Which model changes help keep sharp details, place objects correctly, and balance training so the model learns well at 4K?
How They Did It
To tackle the problem, the team improved both the data and the model. Here’s the approach in everyday terms:
Building a better 4K dataset
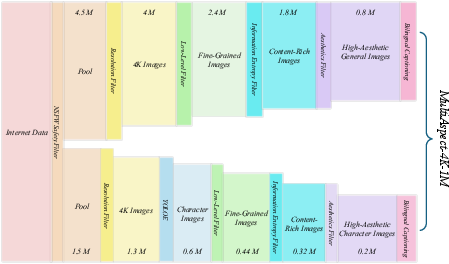
They created MultiAspect‑4K‑1M, a huge collection of about one million 4K images with:
- Lots of different aspect ratios (picture shapes), like wide, square, and tall, so the model doesn’t overfit to just one shape.
- Bilingual captions (English and Chinese), plus tags and quality scores, making it easier to pick the right training examples.
- A balanced mix of content, including people, landscapes, and objects, with careful safety and quality checks.
Think of this dataset as a well‑organized library with detailed labels so the model can learn from the right books at the right time.
Upgrading the image “compressor” (VAE)
Before training, images are compressed into smaller “codes” to make the process faster. A VAE is like a smart zip file: it shrinks images and later expands them back. At 4K, compression can lose tiny details (like hair strands or fabric texture). The team lightly retrained the VAE’s decoder to better recover fine details, without using complicated adversarial tricks. This kept images sharp while staying efficient.
Fixing “where things go” (positional encoding)
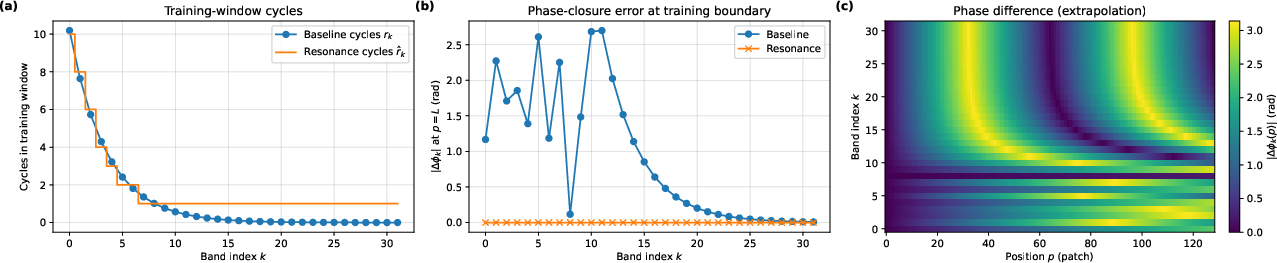
Models rely on a kind of “grid GPS” to understand where image patches are. At 4K, that GPS can get confused, especially for very wide or tall images, causing ghosting or striping. The team introduced Resonance 2D RoPE with YaRN:
- Resonance: tunes the position signals so they line up perfectly within the training window (like matching a wave to fit exactly inside a frame).
- YaRN: adjusts those signals differently for low‑ and high‑frequency parts when the image size changes. Together, these keep the model’s “sense of place” stable across different sizes and shapes.
Teaching the model to care about the right details (training objective)
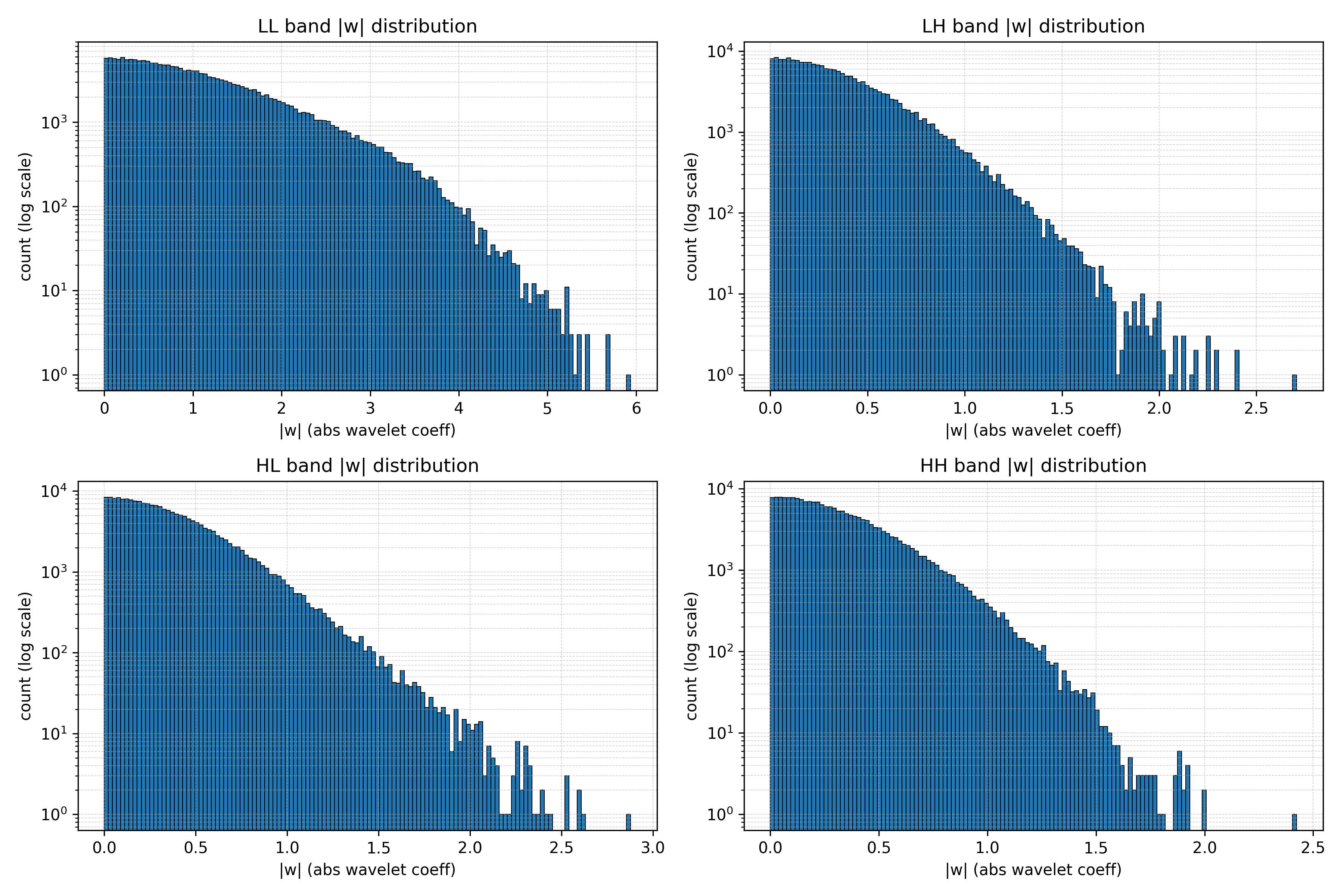
They used an SNR‑Aware Huber Wavelet objective:
- “Wavelet” splits the image into parts like bass vs. treble in music, so the model sees both big shapes (low frequency) and tiny details (high frequency).
- “Huber” is a gentle loss function that doesn’t over‑penalize big errors, helping preserve micro‑details.
- “SNR‑Aware” balances training across noise levels, so the model learns well at all stages. This combo helps the model keep edges sharp and textures crisp at 4K.
A smart training schedule for aesthetics
Stage‑wise Aesthetic Curriculum Learning (SACL) trains in two phases:
- Stage 1: Learn from the whole dataset to understand general 4K structure and content.
- Stage 2: Focus on the noisiest part of generation with only the most beautiful images (top 5% by aesthetic score). This is like practicing hard parts of a song more often, but with the best music sheets. It nudges the model toward nicer‑looking images exactly where it needs artistic guidance.
Main Findings and Why They Matter
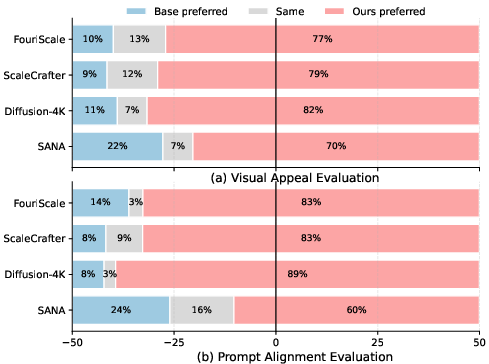
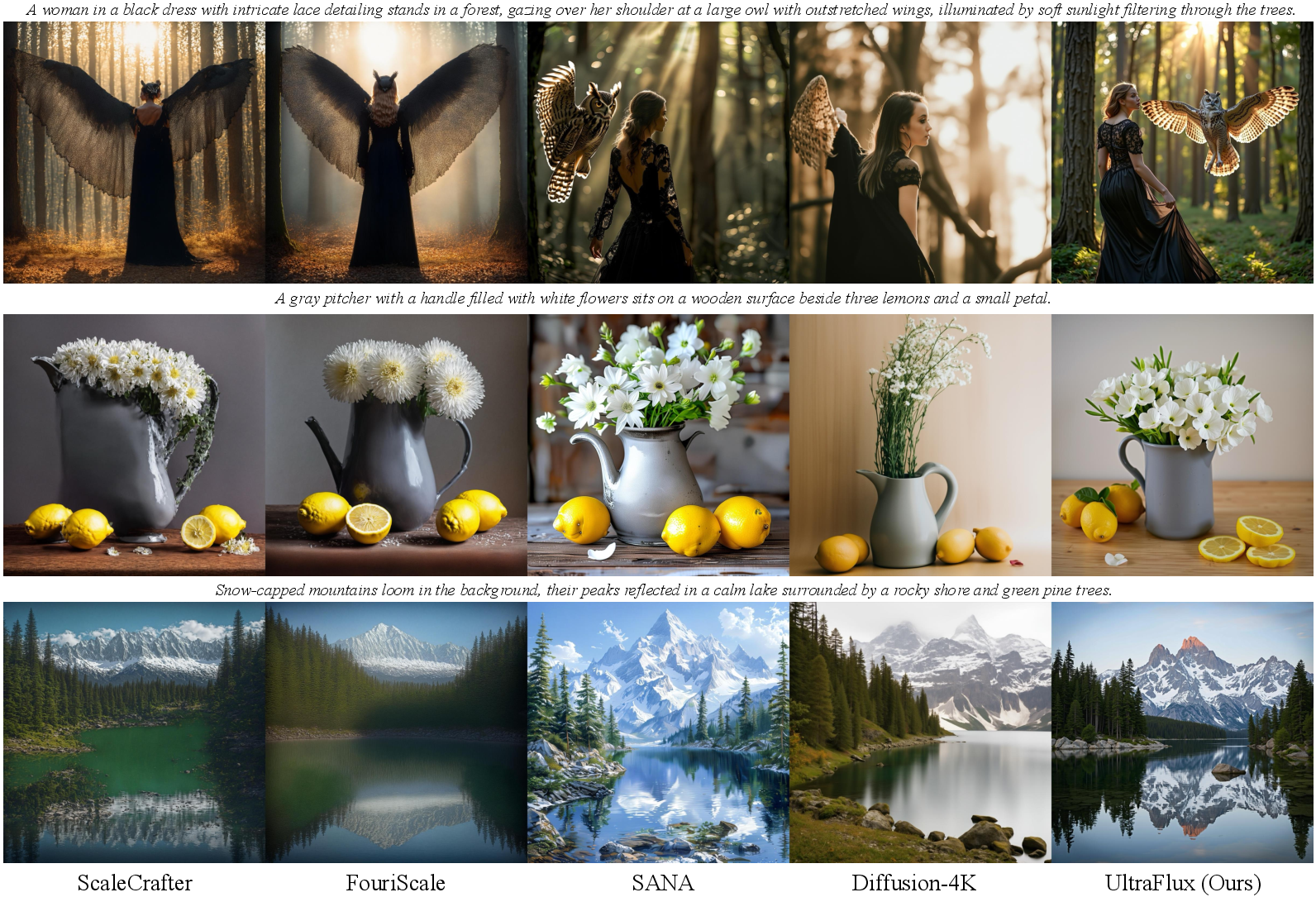
UltraFlux consistently beats other open‑source 4K systems on:
- Fidelity: images look real and detailed.
- Aesthetics: images are more pleasing and stylish.
- Alignment: pictures match the text descriptions better.
It also handles multiple aspect ratios reliably (wide, square, tall), which many models struggle with at 4K. When combined with a strong “prompt refiner” (an AI that rewrites your text to be clearer), UltraFlux matches or even surpasses a leading closed‑source system in several measures. This shows that careful data‑model co‑design can reach top‑tier quality without relying on secret, proprietary methods.
Implications and Impact
UltraFlux shows a clear path for building future high‑resolution text‑to‑image systems:
- Co‑designing data and models leads to stable, beautiful 4K results across many picture shapes.
- Simple, smart tweaks (better positional encoding, a tuned VAE, and a balanced training objective) can solve big problems at large resolutions.
- The large, well‑labeled dataset makes training and evaluation more transparent and controllable.
For creators, designers, and researchers, this means sharper posters, art, and photography‑like images directly from text—no need to generate a smaller picture and then upscale it. For the research community, it offers reusable ideas for scaling models to even higher resolutions or adapting them to video and editing tasks while keeping quality high.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of unresolved issues and open directions that future work could address.
- Dataset release and licensing: The paper does not state whether MultiAspect-4K-1M will be released, under what license, or how copyright/usage rights were verified for 1M high-res images. Clarify release status, licensing, and provenance to enable reproducibility and ethical use.
- Captioning and translation quality: Bilingual captions are generated using Gemini-2.5-Flash and translated by Hunyuan-MT-7B, but there is no quantitative evaluation of caption accuracy (English and Chinese), consistency, or potential translation artifacts. Provide human or benchmark-based assessments and error analyses.
- Biases from VLM-driven filtering: Using Q-Align and ArtiMuse to curate “quality” and “aesthetics” may introduce stylistic and cultural biases. Quantify demographic, geographic, and stylistic diversity and analyze how VLM-based scoring shifts the dataset distribution.
- Human-centric augmentation precision/recall: The YOLOE open-vocabulary detection pipeline is used to flag “character” images, but its false positives/negatives, cross-domain robustness, and impact on training are not reported. Evaluate detector performance, label noise, and ablate the augmentation path.
- AR coverage extremes: While several ARs are tested, ultra-extreme aspect ratios (e.g., 1:6, 4:1, 9:32) and nonstandard grids are not evaluated. Stress-test AR generalization beyond the reported set and quantify failure modes.
- 8K and beyond: The approach targets native 4K; scalability to 8K/12K and to arbitrarily sized token grids remains untested. Establish scaling behavior, stability, and quality at higher resolutions.
- Efficiency and throughput: Inference/training costs for UltraFlux are not reported (wall-clock per 4K image, GPU memory, token grid sizes, attention cost). Provide detailed throughput benchmarks vs. Sana, Diffusion-4K, and F8/F16 VAE baselines.
- F16 VAE trade-offs: Reconstruction quality is improved via post-training, but quantitative metrics (PSNR/SSIM/LPIPS), failure cases (color shifts, small-text legibility), and cross-domain generalization of the F16 decoder are absent. Report standardized reconstruction metrics and ablate wavelet/perceptual loss contributions.
- One-level wavelet design: The SNR-Aware Huber Wavelet objective uses a one-level DWT; multi-level wavelets, alternative bases (e.g., steerable pyramids), or learned transforms are unexplored. Compare wavelet levels/bases and quantify impacts on high-frequency fidelity and stability.
- Loss hyperparameters and sensitivity: The objective depends on c(t), γ, β, α, and the Min-SNR weight. Sensitivity analyses, principled selection, and robustness across schedules/backbones are missing. Provide sweeps, stability plots, and generalization across tasks.
- Flow path choices: Only straight-path flow matching is considered. Explore alternative FM paths, variance-preserving schedules, or EDM-style setups and compare optimization stability and final quality at 4K.
- Resonance 2D RoPE theory and limits: The integer-cycle snapping and YaRN ramp are motivated empirically; formal analysis of phase behavior, aliasing reduction, and cross-attention interactions is absent. Provide theoretical grounding, sensitivity to α/β, and limits under extreme AR/resolution jumps.
- Generalization to other backbones: UltraFlux is built on Flux; applicability to U-Nets (e.g., SDXL), PixArt-Σ, and other DiTs remains unvalidated. Demonstrate portability and component-wise benefits across architectures.
- Text rendering and small-detail evaluation: Readability of fine text, micro-patterns, and signage—key indicators at 4K—are not evaluated. Include OCR/text fidelity tests and high-frequency benchmarks (e.g., micro-structure charts).
- Prompt languages and alignment: Despite bilingual data, Chinese prompt alignment and performance are not reported. Evaluate cross-lingual prompt adherence, failure modes, and differences between languages.
- Diversity vs. aesthetics: SACL’s Stage 2 trains on the top-5% ArtiMuse images at high-noise timesteps. Quantify diversity preservation, mode collapse risk, and aesthetic-style bias introduced by this curriculum.
- Safety and harmful content: Beyond NSFW filtering at data curation, model safety, bias, and harmful content generation are not assessed. Conduct safety audits, controllability tests, and bias evaluations across demographics.
- Human evaluations: Preferences are judged by Gemini-2.5-Flash; no human-subject studies are presented. Run IRB-approved human evaluations to validate aesthetic and alignment gains and compare against LMM judges.
- Benchmark coverage and FID validity: FID at 4K can be unreliable due to domain shifts; reliance on Aesthetic-Eval@4096 and VLM-based metrics may not generalize. Include diverse benchmarks, task-specific metrics (e.g., photorealism, compositionality), and robustness tests.
- Data-model sampling strategies: The paper mentions AR-/resolution-aware sampling enabled by metadata but does not detail sampling policies or curricula beyond SACL. Provide explicit sampling strategies, policies, and ablate their effects.
- Long/complex prompts and constraints: The robustness to long, compositional, or constraint-heavy prompts (e.g., spatial layouts, counts) is not explored. Evaluate compositionality, object count fidelity, and constraint satisfaction.
- Editing and downstream tasks: UltraFlux is presented for T2I synthesis only; editing, inpainting, outpainting, and region conditioning are not tested. Assess whether the components (Resonance RoPE, SNR-HW, SACL) benefit editing tasks.
- Comparison to cascade upscalers: The claimed advantages over upscaling pipelines are qualitative; no controlled comparisons (quality vs. compute) against cascaded SR systems are provided. Run matched experiments to isolate native-4K gains.
- Reproducibility details: Training schedules are partially ambiguous (e.g., corrupted “500K data … 10K steps” text), and compute/optimizer settings are incomplete. Release exact recipes, seeds, configs, and logs for reproducibility.
- RL or preference optimization: Seedream benefits from large-scale RL post-training; UltraFlux uses stage-wise SFT only. Investigate integrating RLHF/preference optimization with SNR-HW and SACL, and quantify gains vs. cost.
- Token compression and attention strategies: Interaction between positional encoding and token compression/windowed attention at 4K is not deeply analyzed. Study attention windowing, memory locality, and RoPE behavior under compression.
- Domain generalization: Performance across artistic styles, medical imagery, scientific plots, and low-illumination/night scenes remains untested. Add domain-specific evaluations and identify domains needing tailored data or objectives.
- Failure mode cataloging: The paper notes reductions in ghosting/striping but does not catalog residual artifacts, their frequency, or mitigation strategies. Provide systematic error analyses and diagnostic tools.
Practical Applications
Overview
Based on the paper’s data–model co-design for native 4K multi–aspect ratio (AR) text-to-image generation (UltraFlux and the MultiAspect-4K-1M dataset), the following are practical, real-world applications spanning industry, academia, policy, and daily life. Each item lists sectors, what it enables, potential tools/workflows, and key assumptions/dependencies.
Immediate Applications
- 4K multi-AR content generation for media, ads, and gaming
- Sectors: media/entertainment, advertising, gaming, e-commerce
- What: Native 4K assets across ARs (1:1, 16:9, 9:16, 2.39:1) for banners, thumbnails, DOOH signage, hero images, cinematic stills, and in-game concept art without upscaler artifacts
- Tools/workflows: UltraFlux inference API; Adobe Photoshop/After Effects plugins; batch generation with LLM prompt refiner; CMS integration for AR-specific variants
- Assumptions/dependencies: Access to GPUs for 4K inference; rights/safety controls on prompts/outputs; availability of UltraFlux weights and permissive license
- Vertical/Horizontal social content at scale
- Sectors: social media, creator economy, marketing
- What: Rapid generation of 9:16 reels covers, 1:1 posts, and 16:9 thumbnails with faithful compositions per AR
- Tools/workflows: Social schedulers auto-calling UltraFlux with AR-specific prompts/crops; prompt refinement templates; seed management for campaign consistency
- Assumptions/dependencies: Latency targets acceptable for campaign pipelines; brand safety filtering
- Print and packaging design
- Sectors: print, retail, product design
- What: High-frequency detail for posters, billboards, catalogs, and packaging layouts; less reliance on post upscaling/restoration
- Tools/workflows: Integration with prepress (CMYK conversion, color proofing); export presets per print size/AR
- Assumptions/dependencies: Color management and gamut mapping; legal/IP clearance; printer-specific proofing
- Game/VFX concept art and matte painting
- Sectors: VFX, gaming, film
- What: Panoramic backgrounds (e.g., 2.39:1), high-detail textures and plates at 4K with improved positional stability across ARs
- Tools/workflows: Unreal/Unity pipeline add-ons; bridge to texture libraries; seed-locked iterations for art direction
- Assumptions/dependencies: Style consistency controls (e.g., LoRA, ControlNet, reference conditioning); GPU compute for 4K
- Responsive web and app hero imagery
- Sectors: software/web design, e-commerce
- What: AR-specific hero assets generated natively to avoid destructive crops, improving layout fidelity
- Tools/workflows: Design systems (Figma/Sketch plugins) that request per-breakpoint assets from UltraFlux
- Assumptions/dependencies: CDN/storage for multiple AR variants; governance for AI-generated imagery
- E-commerce product and fashion visuals
- Sectors: retail, fashion, marketplaces
- What: Lookbooks, product reveal shots, and lifestyle imagery in multiple ARs with preserved fine details
- Tools/workflows: Product CMS integration; prompt libraries per category; batch runs with QA gates
- Assumptions/dependencies: Risk of misrepresentation; need for human-in-the-loop approval and disclosure policies
- Upgrading existing VAEs without GANs
- Sectors: software, ML infrastructure
- What: Apply the non-adversarial, data-efficient VAE post-training recipe to boost high-resolution reconstruction for F16 VAEs in other T2I systems
- Tools/workflows: “VAE post-train kit” using wavelet + perceptual + L2 losses; curated high-detail subset selection via flatness/entropy
- Assumptions/dependencies: Access to a few hundred thousand detail-rich images; compatible VAE architecture
- Improved diffusion training objectives and curricula
- Sectors: ML research/engineering (vision/foundation models)
- What: Adopt SNR-Aware Huber Wavelet loss and Stage-wise Aesthetic Curriculum Learning (SACL) to enhance detail preservation and aesthetics in new or ongoing model training
- Tools/workflows: Drop-in PyTorch modules for wavelet transforms and Pseudo-Huber penalties; loader that restricts Stage-2 to high-noise steps with top-k aesthetic data
- Assumptions/dependencies: Hyperparameter tuning; performance depends on curated aesthetic scoring and noise schedule
- More robust positional encoding for cross-res/AR tasks
- Sectors: software, vision research (segmentation, detection, generative models)
- What: Integrate Resonance 2D RoPE with YaRN to stabilize transformers under large changes in resolution and AR
- Tools/workflows: Open-source RoPE library update; ablations in detection/segmentation backbones using multi-scale training
- Assumptions/dependencies: Implementation correctness and benchmarking; may require per-architecture tuning
- Data curation and audit templates for high-res T2I
- Sectors: policy/compliance, data engineering, academia
- What: Use MultiAspect-4K-1M-style metadata (Q-Align, ArtiMuse, flatness/entropy, bilingual captions) as a template for dataset audits and stratified sampling
- Tools/workflows: Data cards with AR coverage histograms; AR/aesthetic-aware samplers; quality dashboards
- Assumptions/dependencies: Availability and licensing of scorers (Q-Align, ArtiMuse); compute to score large corpora; dataset release/permissions
- Localization and cross-lingual prompt evaluation
- Sectors: education, international product teams, research
- What: Bilingual captions enable cross-lingual prompt testing (English/Chinese) for generative systems and curricula
- Tools/workflows: Prompt libraries mirrored across languages; CLIP-based cross-language alignment checks
- Assumptions/dependencies: Translation quality; cultural considerations for aesthetics and content
- Cost and energy reductions via F16 latents
- Sectors: platform providers, sustainability teams
- What: Smaller latent grids reduce inference time/energy per 4K image, improving throughput and cost
- Tools/workflows: Monitoring dashboards tracking energy per image; autoscaling policies adapted to lower latency
- Assumptions/dependencies: Acceptable quality trade-offs vs. F8; access to efficient kernels and memory plans
- Daily creative uses
- Sectors: daily life, creator economy
- What: Personalized 4K wallpapers, posters, photobooks, and channel branding in the desired AR
- Tools/workflows: Consumer apps integrating UltraFlux with safety filters and simple prompt templates
- Assumptions/dependencies: Device constraints; print color calibration; terms of use and disclosure
Long-Term Applications
- Native 8K and ultra-wide/ultra-tall generation
- Sectors: media, film, signage, premium print
- What: Extend Resonance 2D RoPE, SNR-aware losses, and VAE approach to 8K+ for cinema posters, large-format prints, and UHD signage
- Tools/workflows: Memory-efficient attention, checkpointing/activation recompute, multi-node training
- Assumptions/dependencies: Significant compute and memory; new 8K-capable datasets with balanced AR coverage
- High-resolution video generation with AR control
- Sectors: entertainment, advertising, social platforms
- What: Temporal extensions of UltraFlux for 4K video with consistent composition across ARs (e.g., auto-versioning vertical/horizontal spots)
- Tools/workflows: Video diffusion with temporal positional encoding; wavelet-temporal objectives; Stage-wise aesthetic curricula per timestep schedule
- Assumptions/dependencies: Large curated 4K video datasets; temporal coherence training; higher compute budgets
- AR/VR and 3D asset pipelines
- Sectors: XR, gaming, simulation
- What: Generate 4K skyboxes, environment maps, and textures; condition T2I on scene/layout for NeRF/mesh pipelines
- Tools/workflows: Multi-view/360° consistency modules; integration with material/UV workflows; panoramic AR-aware encodings
- Assumptions/dependencies: Multi-view datasets and constraints; geometry-aware training objectives
- Domain-specialized 4K generation (scientific, medical, geospatial)
- Sectors: healthcare, earth observation, industrial inspection
- What: Adapt methods to produce high-fidelity, domain-specific imagery for education and simulation (not diagnosis)
- Tools/workflows: Domain corpora with expert labels; AR-aware dataset curation and safety protocols
- Assumptions/dependencies: Strict compliance and ethics; domain data availability; strong guardrails to avoid misuse
- Robotics and sim-to-real
- Sectors: robotics, autonomous systems
- What: High-res synthetic environments and textures to improve perception model pretraining and rare-case simulation
- Tools/workflows: Procedural scene generation with aspect-aware layouts; curriculum that targets difficult noise regimes for texture detail
- Assumptions/dependencies: Physics/lighting realism; domain randomization alignment with downstream tasks
- Layout- and brand-aware automatic design systems
- Sectors: marketing, publishing, retail
- What: Generate AR-specific, on-brand compositions that respect layout constraints (text-safe regions, logo placement)
- Tools/workflows: Conditioning on layout masks/constraints; LLM-guided prompt and compliance checks
- Assumptions/dependencies: Additional control signals (segmentation/masks); brand asset libraries and approval loops
- Regulatory benchmarking and procurement standards for high-res generative AI
- Sectors: policy, standards bodies, enterprise governance
- What: Define 4K AR-aware benchmarks (alignment, aesthetics, IQA) and dataset audit requirements using the paper’s metadata template
- Tools/workflows: Evaluation suites with HPS, Q-Align, MUSIQ, AR distribution reporting; procurement checklists (AR coverage, safety)
- Assumptions/dependencies: Multi-stakeholder adoption; openness of benchmark datasets and metrics
- On-prem/edge 4K deployment
- Sectors: media/retail (stores), creative studios, privacy-sensitive verticals
- What: Quantized and pruned UltraFlux variants, using F16 latents to fit edge servers or private clusters
- Tools/workflows: Model compression pipelines; low-latency schedulers; A/B quality gates for compressed models
- Assumptions/dependencies: Accuracy/quality retention with quantization; hardware-specific kernels
- Multimodal agents and co-pilots for creative direction
- Sectors: software, media, education
- What: Agents using LLM prompt refinement + UltraFlux to ideate, iterate, and version AR-specific assets collaboratively
- Tools/workflows: Chain-of-thought prompt planners; human-in-the-loop review; asset management integration
- Assumptions/dependencies: Cost control per iteration; policy for disclosure and provenance
- Training-data marketplaces and ethical curation services for high-res AI
- Sectors: data platforms, legal/compliance
- What: Services offering AR-balanced, high-aesthetic, bilingual-captioned 4K datasets with metadata, auditability, and opt-out management
- Tools/workflows: Scoring services (Q-Align, ArtiMuse), deduplication, NSFW safety, licensing workflows
- Assumptions/dependencies: Clear rights management and compensation models; standardized data cards
Notes on feasibility and dependencies common across applications:
- Compute: 4K generation remains GPU-intensive; F16 VAE helps but planning for VRAM and latency is needed.
- Data and licensing: Availability and licensing of MultiAspect-4K-1M, captions (Gemini/Hunyuan-MT), and scorers (Q-Align/ArtiMuse) can constrain adoption.
- Safety/IP: Strong safety filters, watermarking, and human oversight are needed to meet brand and regulatory requirements.
- Generalization: While results are strong on natural images, domain transfer (e.g., medical, scientific) requires new data and careful validation.
- Ecosystem integration: Maximum value arises when UltraFlux is paired with prompt refiners, control modules (e.g., masks, reference images), and production asset pipelines.
Glossary
- Aesthetic-Eval@4096: A benchmark for evaluating 4K text-to-image models on aesthetics and alignment. "On the Aesthetic-Eval@4096 benchmark and multi-AR 4K settings, UltraFlux consistently outperforms strong open-source baselines across fidelity, aesthetic, and alignment metrics"
- ArtiMuse: An MLLM-based image aesthetics evaluator providing numeric scores and explanations. "for aesthetics we use ArtiMuse, a recent MLLM-based image aesthetics evaluator that provides numeric scores together with reasoned, expert-style explanations"
- Aspect Ratio (AR): The proportional relationship between an image’s width and height. "extending these systems to native 4K while supporting a broad spectrum of aspect ratios (ARs)"
- CLIP Score: A text-image similarity metric derived from the CLIP model. "CLIP Score~\cite{zhang2024long}"
- Diffusion transformers (DiTs): Transformer-based generative models that perform diffusion for image synthesis. "Diffusion transformers (DiTs)~\cite{peebles2023scalable,batifol2025flux,esser2024scaling,chen2024pixart,xie2024sana} have recently pushed text-to-image generation to impressive quality around 1K resolution"
- Discrete Wavelet Transform (DWT): A multi-scale transform that decomposes signals into frequency sub-bands. "letting denote a one-level orthonormal DWT (sub-bands concatenated along channels)"
- F16 VAE: A VAE variant with 16× spatial downsampling for efficient high-resolution latents. "we instead adopt an VAE"
- F8 VAE: A VAE variant with 8× spatial downsampling producing larger latent grids. "The Flux backbone uses an VAE (height/width downsampling by $8$)"
- FID: Fréchet Inception Distance, a distributional metric of image realism. "using FID~\cite{heusel2017gans}"
- Flow matching: A training framework where models learn velocity fields along interpolation paths. "a drop-in replacement for standard flow-matching losses"
- FouriScale: A training-free high-resolution method using Fourier-domain guidance. "FouriScale approaches ultra-high resolution from the frequency view via Fourier-domain low-pass guidance and dilated convolutions"
- Global–local fusion: A decoder design combining global context with local detail in generation. "Decoder-side approaches based on global–local fusion or tiled diffusion improve size flexibility"
- HiDiffusion: A high-resolution adaptation technique using resolution-aware U-Nets and windowed attention. "HiDiffusion diagnoses duplication and quadratic self-attention costs at high resolutions and introduces a resolution-aware U-Net and windowed attention to improve quality and speed"
- HPSv3: A human preference scoring metric for generative images. "using FID~\cite{heusel2017gans}, HPSv3~\cite{ma2025hpsv3widespectrumhumanpreference}"
- LLM: A model trained on large text corpora, here used to refine prompts. "and—with a LLM prompt refiner—matches or surpasses the proprietary Seedream~4.0"
- Large Multimodal Model (LMM): A model that processes both images and text jointly. "for quality we adopt Q-Align, a large multimodal model (LMM)-based visual scorer"
- Latent-space super-resolution: A method to upsample and sharpen details in latent representations. "Latent-space super-resolution and self-cascade schemes sharpen details beyond the original training resolution"
- Linear-attention DiT: A DiT variant with linear-time attention for scalability. "Sana (32 VAE with linear-attention DiT) make 40964096 synthesis computationally feasible"
- Min-SNR: A weighting strategy emphasizing mid-range noise timesteps during training. "echoing Min-SNR analyses that show inefficient use of intermediate timesteps"
- MUSIQ: A metric assessing perceptual image quality. "MUSIQ~\cite{MUSIQ}"
- Native 4K: Training and generating directly at 4096×4096 resolution without upscaling. "we show that extending them to native 4K across diverse aspect ratios exposes a tightly coupled failure mode"
- NTK factor: A scaling term applied to positional frequencies inspired by Neural Tangent Kernel analysis. "The official Flux backbone employs a fixed per-axis rotary spectrum with an optional global NTK factor"
- NTK-style scaling strategies: Techniques to adjust positional encodings for sequence length extrapolation. "existing RoPE interpolation and NTK-style scaling strategies are primarily developed for 1D sequence length extrapolation"
- Open-vocabulary detector: A detector that recognizes arbitrary textual categories without fixed label sets. "a promptable open-vocabulary detector"
- PickScore: A learned preference metric for images conditioned on prompts. "PickScore~\cite{Kirstain2023PickaPicAO}"
- PixArt-: An efficient DiT backbone that uses token-compression attention. "PixArt- (token-compression attention)"
- Prompt refiner: A model that rewrites or enhances prompts to improve generation. "UltraFlux w. Prompt Refiner (Ours) with a GPT-4O front-end"
- Pseudo-Huber penalty: A smooth robust loss that transitions between L2 and L1 behavior. "For robustness we use the Pseudo-Huber penalty $\rho_{c}(r)=c^{2}\!\big(\sqrt{1+(r/c)^{2}-1\big)$"
- Q-Align: A VLM-based scorer providing IQA-related quality judgments. "for quality we adopt Q-Align, a large multimodal model (LMM)-based visual scorer"
- Resonance 2D RoPE: A 2D rotary positional encoding adjusted to complete integer cycles on the training window. "We then snap to the nearest nonzero integer ... Resonance 2D RoPE"
- RoPE: Rotary Positional Embeddings used to encode positions via complex rotations. "following the standard RoPE formulation \cite{su2024roformer}"
- SACL (Stage-wise Aesthetic Curriculum Learning): A two-stage training scheme focusing high-aesthetic data on high-noise steps. "a Stage-wise Aesthetic Curriculum Learning (SACL) scheme that concentrates high-aesthetic supervision on high-noise steps"
- Sana: A native-4K DiT model with linear attention and strong compression. "Sana~\cite{xie2024sana}"
- Seedream 4.0: A closed-source native 4K multi-AR text-to-image system. "Seedream 4.0~\cite{seedream2025seedream}"
- Self-Cascade Diffusion: A method integrating low-res generation into high-res denoising for rapid adaptation. "Self-Cascade Diffusion integrates low-resolution generation into the high-resolution denoising process"
- Signal-to-Noise Ratio (SNR): The ratio measuring signal strength relative to noise in training timesteps. "Here under the straight FM path"
- SNR-Aware Huber Wavelet objective: A robust, frequency- and timestep-aware training loss for 4K latents. "an SNR-Aware Huber Wavelet objective that rebalances gradients across timesteps and frequency bands"
- Stage-wise SFT: Supervised fine-tuning organized in stages. "our full pipeline relies solely on stage-wise SFT"
- Tiled diffusion: Generating images by processing tiles with mechanisms to ensure global coherence. "global–local fusion or tiled diffusion improve size flexibility"
- Token-compression attention: An attention mechanism that reduces token count for efficiency. "PixArt- (token-compression attention)"
- T2I (Text-to-image): Generative modeling that creates images conditioned on textual prompts. "This section reviews approaches to scaling text-to-image diffusion models to high-resolution T2I"
- U-Net: A convolutional encoder–decoder architecture used in diffusion backbones. "introduces a resolution-aware U-Net"
- VAE (Variational Autoencoder): A latent-variable model used to compress and reconstruct images. "VAE compression"
- VLM (Vision-LLM): A model jointly trained on images and text, used for scoring and metadata. "VLM-based quality and aesthetic scores"
- Windowed attention: An attention mechanism restricted to local windows to reduce cost. "and windowed attention to improve quality and speed"
- YaRN: A RoPE extrapolation scheme that scales positional frequencies band-wise. "Inspired by the YaRN scheme for length extrapolation of 1D RoPE"
- YOLOE: A promptable open-vocabulary object detector for human-centric augmentation. "YOLOE~\cite{wang2025yoloerealtimeseeing}, a promptable open-vocabulary detector"
Collections
Sign up for free to add this paper to one or more collections.