Illustrator's Depth: Monocular Layer Index Prediction for Image Decomposition
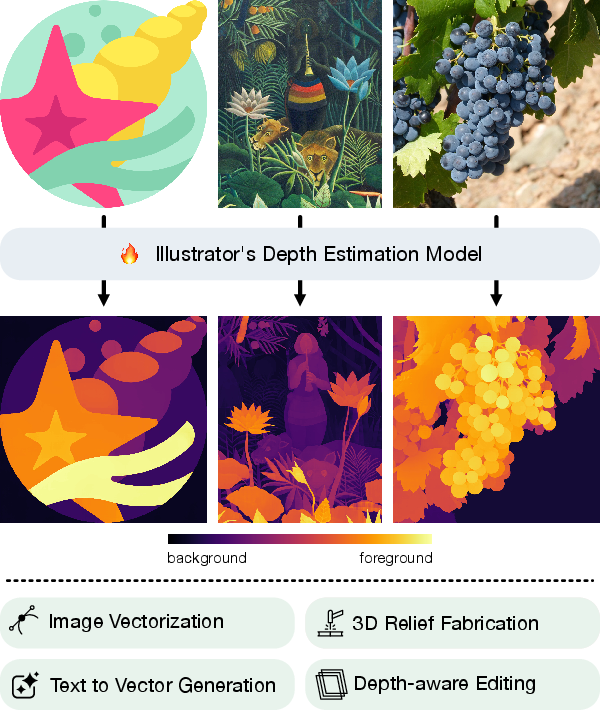
Abstract: We introduce Illustrator's Depth, a novel definition of depth that addresses a key challenge in digital content creation: decomposing flat images into editable, ordered layers. Inspired by an artist's compositional process, illustrator's depth infers a layer index to each pixel, forming an interpretable image decomposition through a discrete, globally consistent ordering of elements optimized for editability. We also propose and train a neural network using a curated dataset of layered vector graphics to predict layering directly from raster inputs. Our layer index inference unlocks a range of powerful downstream applications. In particular, it significantly outperforms state-of-the-art baselines for image vectorization while also enabling high-fidelity text-to-vector-graphics generation, automatic 3D relief generation from 2D images, and intuitive depth-aware editing. By reframing depth from a physical quantity to a creative abstraction, illustrator's depth prediction offers a new foundation for editable image decomposition.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to understand “depth” in pictures called Illustrator’s Depth. Instead of measuring how far things are in the real world (like a camera or a 3D scanner would), Illustrator’s Depth guesses how an artist would stack parts of a picture into layers, like stickers placed one on top of another. This helps turn flat images into editable layers, making it much easier to edit, move, recolor, or reuse parts of the image.
Key Objectives
The authors set out to answer three simple questions:
- How can we predict the order of layers in a picture from just one image (no 3D or extra views)?
- Can this “layer order” be learned in a way that matches how artists actually work?
- If we can do that, does it make real tasks—like vectorizing images, generating editable graphics from text, or making 3D reliefs—work better?
How They Did It (Methods, in Everyday Terms)
Think of building an illustration like making a paper collage:
- The background is the bottom sheet.
- Objects (like a tree, a cat, a shadow) are layered on top.
- Even flat things with no “real” depth (like printed patterns or painted shadows) still have a place in the stack.
The paper teaches a computer to predict this stack for every pixel in an image.
Here’s the approach, step by step:
- What “Illustrator’s Depth” means:
- For each pixel in the image, the model predicts a layer index (1, 2, 3, …). Lower numbers are “behind,” higher numbers are “in front.”
- It’s not measuring physical distance. It’s capturing how an artist would stack parts so the image is easy to edit.
- Building training data from vector graphics:
- Vector graphics (SVGs) already have layers and shapes.
- The team collected many well-structured SVG illustrations where the stacking order makes sense (background to foreground).
- They cleaned this dataset (for example, merging consecutive layers that were the exact same color, and removing confusing cases).
- Then they turned each SVG into:
- a normal image (what you see), and
- a “layer map” image that secretly encodes each pixel’s layer number using special color codes the computer can read back. You can think of this like giving every layer a unique barcode encoded as a color.
- Training the model:
- They used a neural network that already understands shapes and occlusions from the real world (pretrained on depth tasks), then retrained it to learn this new kind of “artist-friendly depth.”
- Important detail: The network doesn’t need the exact layer numbers to match the original; what matters most is the correct order (which is in front of which). So they trained it to care about the correct ordering, not the exact digits.
- The model outputs a smooth “depth-like” value per pixel, which can be turned into clean, discrete layers by simple steps like grouping values into bins.
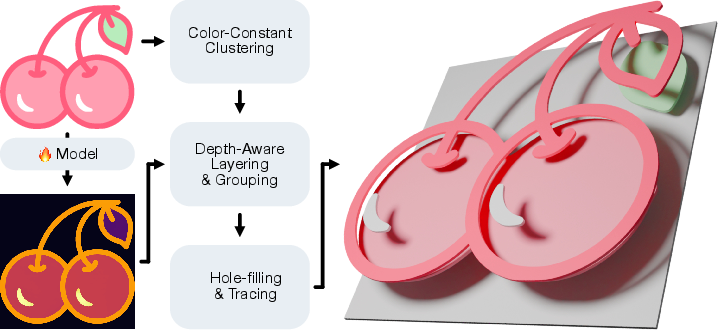
- Post-processing for different tasks:
- For raster editing: they can simply “threshold” the depth map to split foreground and background (or several layers).
- For vectorization: they group pixels with similar colors and similar predicted depths into neat, editable vector layers.
Key idea: Instead of physical depth (how far things are in meters), the model learns creative depth (how an illustrator would stack the parts).
Main Findings and Why They Matter
- It predicts layers better than normal depth models:
- Regular “monocular depth” models (which estimate real-world distances from a single image) do great on photos of 3D scenes—but they’re confused by flat art elements like printed shadows, logos on shirts, or paintings. Those models try to ignore flat patterns.
- Illustrator’s Depth does the opposite: it produces clean, piecewise-flat regions and a consistent layer order, even for flat art and patterns. It gets the “which is on top” story right much more often.
- Stronger vectorization (turning images into SVGs):
- Plugging this layer prediction into a standard vectorization pipeline creates SVGs with:
- more accurate layer order,
- fewer, cleaner paths,
- and a closer visual match to the original.
- This makes the result far more editable and practical for designers.
- Plugging this layer prediction into a standard vectorization pipeline creates SVGs with:
- Text-to-vector gets an upgrade:
- Today’s text-to-image models can make beautiful pictures, but the output is a single flat image.
- With Illustrator’s Depth plus vectorization, those images can be automatically converted into layered, editable vector graphics—so you can move parts around, change colors, and edit shapes just like an artist.
- 3D relief from a single image:
- Treating the predicted depth as “height,” you can raise pixels into 3D to make bas-relief sculptures.
- This works on paintings and illustrations without any manual depth labeling, making it useful for tactile art or decorative fabrication.
- Depth-aware editing:
- The predicted layer map lets you separate the foreground from the background with a slider, or split an image into several stacked layers for smart cutouts, inpainting, or compositing.
- It reduces the guesswork compared to pure segmentation tools because the layers have a clear, global order.
Implications and Potential Impact
- For creators and designers: Faster, cleaner, and more intuitive editing. You get ready-to-edit layers from a single image, without manually tracing or sorting shapes.
- For vector graphics: More reliable automatic vectorization, with correct stacking and fewer messy artifacts—ideal for illustration, branding, and print.
- For generative workflows: Turn text-generated images into truly editable vector artworks, bridging the gap between AI images and professional design tools.
- For accessibility and fabrication: Automatic 3D reliefs could help convert artworks into tactile objects and speed up 3D decorative design.
- Big picture: The paper reframes “depth” from a physical measurement to a creative tool, opening the door to smarter, more “artist-aware” image editing and generation systems.
In short, Illustrator’s Depth teaches computers to think like artists about layers. That simple shift—from measuring meters to predicting stack order—unlocks better vectorization, easier editing, improved generative design, and even new 3D uses from plain 2D images.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and opportunities for future research that are either missing, uncertain, or left unexplored in the paper.
- Dataset coverage and bias: The model is trained and evaluated primarily on MMSVG-Illustration; it is unclear how well it generalizes to broader SVG semantics (masks, clips, filters, gradients, blend modes), non-vector artwork, mixed-media compositions, and diverse illustration styles not represented in MMSVG.
- Ambiguity in “artist-intent” layering: The paper mitigates label ambiguity by merging same-color consecutive layers and excluding overlapping same-color cases, but does not model or quantify the inherent multiplicity of valid layerings. A multi-annotator, probabilistic, or distributional ground-truth for layer order remains unaddressed.
- Handling transparency and blend modes: Real-world illustrations often use alpha blending, soft shadows, glows, and non-linear composite operators. How to jointly infer global layer order together with layer opacities and blend modes is not addressed.
- Gradient fills and complex path effects: The ground-truth rasterization encodes layer indices via per-layer false colors, but the handling of gradients, pattern fills, strokes with variable width, filters, and path effects (e.g., SVG filters) is unspecified and likely unsupported.
- Color-space correctness in depth encoding: The base-256 encoding strategy for depth in RGB assumes linear, lossless color rasterization; the impact of sRGB gamma, color management, compression, and antialiasing on accurate index recovery is not analyzed.
- Estimating the number of layers (N): The network outputs continuous values later discretized by binning or clustering, but there is no principled method to infer or control the optimal number of layers for a given image or task (trade-off between editability and fidelity).
- Discrete, piecewise-constant layer enforcement: The model predicts continuous “depth” without explicit constraints to produce piecewise-constant regions per layer. Structured losses (e.g., ordinal regression, ranking with transitivity constraints, CRFs) or architectural changes to enforce discrete layering are not explored.
- Occlusion and amodal layer inference: The approach assigns indices only to visible pixels; inferring amodal illustrator’s depth (including occluded extents of elements) is not studied.
- Object-level grouping and hierarchy: Layer indices are per-pixel; mechanisms to group pixels into objects, hierarchies, and nested stacks (e.g., sublayers within groups) that match design workflows are not proposed.
- Robustness to visual illusions and flat printed content: While examples show progress on flat patterns and prints, there is no systematic analysis of failure cases (e.g., trompe-l’oeil, complex textures, shading gradients, overlapping patterns) or guidance on domain-dependent behavior.
- Cross-dataset, cross-domain evaluation: Quantitative evaluation uses a small subset (100 images) and is largely confined to MMSVG. Broader tests on varied datasets (e.g., clipart libraries, design corpora, natural images, scans) and ablations across domains are missing.
- Editability-centric evaluation: The metrics focus on pixel-wise order accuracy and reconstruction fidelity; user studies and task-based metrics (time-to-edit, number of layer adjustments, error rates during typical editing tasks) are needed to validate practical editability benefits.
- Baseline comparability and tuning: The paper reports large gaps versus LLM-based or optimization baselines; the fairness and thoroughness of hyperparameter tuning, resolution settings, and pipeline adaptations for these baselines are not detailed.
- Post-processing choices and reliability: The paper mentions binning and color clustering to derive discrete layers but does not systematically compare these strategies, analyze sensitivity to thresholds, or propose learning-based quantization for robust, automatic discretization.
- Topological correctness and hole handling: The pipeline uses inpainting to fill holes and bridge gaps prior to vectorization, but the impact on topology (e.g., correctly preserving negative space, holes, and cutouts) and potential shape distortions is not quantified.
- Path quality and vector compactness: While path counts are measured, there is no analysis of curve quality (Bezier control point efficiency, smoothness, anchor count) or downstream editability (e.g., ease of retouching curves, path simplification) beyond mere count.
- Temporal consistency for video: Extending illustrator’s depth to video (consistent layer ordering across frames) is not explored; this is essential for animation and video editing workflows.
- Uncertainty estimation and interactive control: The model does not expose confidence maps, uncertainty quantification, or interactive controls to resolve ambiguous regions, which could assist designers during layer refinement.
- Combining semantics with depth: Integrating panoptic/instance semantics with illustrator’s depth to produce semantically meaningful, ordered layers (e.g., grouping all parts of a character) is left unexplored.
- Domain-adaptive strategies: The method initializes from physical MDE priors; when cues in photos contradict illustrative ordering (e.g., printed textures), a principled way to adapt or switch priors per domain remains open.
- Relief generation mapping: The 2D-to-3D relief conversion uses depth-as-elevation directly; there is no study on perceptual or fabrication-aware height mappings (e.g., non-linear scalings, smoothing, ridges) or on controlling relief design objectives (tactility, printability).
- Scalability and efficiency: Inference “takes seconds,” but scalability to very high-resolution images, memory constraints, GPU/CPU latency, and tiling strategies (with seam handling) are not addressed.
- End-to-end text-to-layered-SVG generation: The pipeline relies on raster synthesis (e.g., Flux) followed by vectorization; an end-to-end model that directly generates editable, layered SVGs from text (with controllable layer structure) remains an open direction.
- Hierarchical layering and multi-resolution: The notion of single global ordering does not capture nested or hierarchical depth; hierarchical indices or multi-scale layering (coarse-to-fine) could better reflect real design workflows but are not studied.
- Failure case taxonomy and diagnostics: The paper references supplementary material for failures but does not provide a systematic taxonomy, diagnostic tools, or benchmarks to quantify typical error modes and guide improvements.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed today using the paper’s model, dataset curation, and evaluation protocol.
- Layer-aware vectorization for creative software — Sectors: software, graphics, design
- Description: Integrate illustrator’s depth into vectorization to output edit-ready, depth-ordered SVGs with fewer paths and correct stacking (foreground/background, outlines over fills).
- Potential tools/products/workflows: Plugins for Adobe Illustrator, Inkscape, Figma; batch server for agencies; pipeline: image → depth map → color clustering → per-layer potrace → ordered SVG.
- Assumptions/dependencies: Best on illustration-like inputs; GPU or cloud inference recommended; quality depends on color clustering and inpainting steps.
- Batch conversion for stock and brand asset libraries — Sectors: media, marketing, DAM (digital asset management)
- Description: Automatically convert raster submissions into layered vectors to improve searchability, editability (e.g., recolor by layer), and downstream reuse.
- Potential tools/products/workflows: Backend microservice for Shutterstock/Adobe Stock/enterprise DAMs; automated QA using the paper’s “ordering consistency” metric.
- Assumptions/dependencies: Input diversity; licensing/usage rights; service-level GPU scaling.
- Text-to-vector graphics pipelines — Sectors: generative AI, advertising, marketing
- Description: Use high-quality text-to-image models (e.g., Flux) followed by illustrator’s depth vectorization to produce complex, editable SVGs from prompts.
- Potential tools/products/workflows: Prompt → T2I → depth map → vectorization → layered SVG delivery; integration with SD/Flux APIs in creative suites.
- Assumptions/dependencies: T2I must produce vector-style images (flat colors/clean edges); legal use of generative outputs; GPU inference for throughput.
- Depth-aware raster editing and compositing — Sectors: software, photography, social media tools
- Description: Add a “layer-threshold” slider to split images into foreground/background (or N bins) for selection, masking, inpainting, and parallax effects.
- Potential tools/products/workflows: Photoshop/GIMP/Krita plugins; mobile apps that generate masks from the depth map for selective edits; batch matting for marketing creatives.
- Assumptions/dependencies: Illustrator’s depth encodes editorial ordering, not physical depth; user guidance may be needed for ambiguous cases.
- Automatic bas-relief and tactile graphics from 2D images — Sectors: accessibility, education, manufacturing
- Description: Convert depth maps to height fields for 3D printing/CNC milling of tactile diagrams, museum replicas, and embossed signage.
- Potential tools/products/workflows: Image → illustrator’s depth → smoothed elevation → mesh → slicer/CAM; classroom tools to produce tactile textbooks.
- Assumptions/dependencies: Illustrator’s depth ≠ metric depth; requires height scaling, smoothing, and fabrication constraints (minimum feature sizes, safety, durability).
- Crafting and plotter cutting separation — Sectors: maker tools, print-on-demand, e-commerce
- Description: Produce cut-ready color layers for Cricut/Silhouette/laser cutters; automatically separate stickers, decals, and heat-transfer vinyl layers.
- Potential tools/products/workflows: Web or desktop utility: upload image → get per-color ordered SVG layers with weeding borders.
- Assumptions/dependencies: Reliant on solid color regions and clean boundaries; manual tweaks for fine details.
- Comics/manga and illustration relayering — Sectors: publishing, localization
- Description: Separate line art, fills, highlights, and shadows into coherent stacks for rapid recoloring, translation, and reformatting.
- Potential tools/products/workflows: Batch relayering tool for studios; rules that enforce “strokes above fills” as in the training data.
- Assumptions/dependencies: Strongest when artwork resembles the curated SVG domain; special handling for screen tones/halftones.
- UI/icon cleanup and conversion — Sectors: software, UX, design systems
- Description: Convert legacy raster UI elements into structured, minimal-layer vectors for design system standardization and responsive scaling.
- Potential tools/products/workflows: Design ops pipeline that ingests PNGs/SVG raster exports and outputs cleaned SVGs with named layers.
- Assumptions/dependencies: Works best on flat/sharp iconography; may need manual merging/renaming conventions.
- Cultural heritage analysis and education — Sectors: museums, art history, edtech
- Description: Offer interactive explorations of artworks by peeling back layers showing compositional structure; printable layered didactics.
- Potential tools/products/workflows: Museum kiosks and classroom apps that visualize layer order; export to tactile reliefs.
- Assumptions/dependencies: Generalizes to many paintings but can fail on highly textured/impasto works; curatorial review advised.
- Metrics and datasets for academic benchmarking — Sectors: academia, ML research
- Description: Adopt the paper’s depth-ordering consistency metric and curated SVG→depth pairs for evaluating layer inference and amodal reasoning.
- Potential tools/products/workflows: Open-source benchmarks; challenge tasks on layer ordering; cross-comparison with panoptic/amodal baselines.
- Assumptions/dependencies: Community uptake; careful train/val/test splits and reporting standards.
- Web and mobile asset optimization — Sectors: web performance, mobile apps
- Description: Replace raster illustrations with compact layered SVGs to reduce bandwidth while enabling targeted color/theme changes at runtime.
- Potential tools/products/workflows: Build pipeline that auto-vectorizes marketing/UI art and injects layer-level CSS variables.
- Assumptions/dependencies: Input suitability; CDN/browser SVG rendering performance; design tokens alignment.
- Everyday personalization apps — Sectors: consumer apps, education
- Description: Turn kids’ drawings or photos into layered stickers, wall art, and relief keepsakes with simple one-click workflows.
- Potential tools/products/workflows: Mobile apps: capture → layerize → choose material/process → order print/cut/3D print.
- Assumptions/dependencies: On-device or cloud inference; parental consent, safety and material choices.
Long-Term Applications
The following applications are promising but require further research, scaling, or standardization (e.g., training for natural imagery, temporal consistency, physical-depth alignment).
- Video layer-index prediction for animation and VFX — Sectors: film, games, motion design
- Description: Temporally consistent per-frame layer maps to enable automatic parallax, cutout animation, and depth-aware transitions.
- Potential tools/products/workflows: Video model with temporal losses; per-shot relayering and auto-rigging of 2D assets.
- Assumptions/dependencies: Needs sequence training, temporal consistency, and handling of motion blur and occlusion cycles.
- AR compositing and occlusion for 2D assets — Sectors: AR/VR, retail, marketing
- Description: Use illustrator’s depth for realistic occlusion and layered interactions in AR scenes with 2D graphics or posters.
- Potential tools/products/workflows: AR SDK that reads layer order to composite virtual props behind/in front of printed elements.
- Assumptions/dependencies: Illustrator’s depth differs from physical depth; hybrid methods must reconcile both to avoid visual artifacts.
- Vector-native generative models conditioned on layer order — Sectors: generative AI, design
- Description: Train T2V models to produce SVGs with explicit, globally ordered layers (learned from illustrator’s depth supervision).
- Potential tools/products/workflows: Diffusion models outputting parametric paths and stack order; “layer-aware” SDS or vector transformers.
- Assumptions/dependencies: Large, high-quality paired datasets; robust differentiable vector renderers; compute and IP considerations.
- Standards for “illustrator’s depth” metadata — Sectors: policy, web standards, print/PDF
- Description: Propose a standard channel/attribute for layer index in SVG/PDF for interoperability across tools and pipelines.
- Potential tools/products/workflows: W3C SVG extension; PDF/UA updates; export/import APIs in major editors.
- Assumptions/dependencies: Consensus in standards bodies; backward compatibility; accessibility and security review.
- Robust natural-image decomposition — Sectors: photography, creative editing
- Description: Extend training to natural photos to obtain edit-friendly layer stacks (e.g., background, subject, shadows, reflections).
- Potential tools/products/workflows: Mixed-domain datasets with amodal/ordering supervision; joint training with panoptic/semantic cues.
- Assumptions/dependencies: More data and labels; reasoning about transparency, specularities, complex textures.
- Manufacturing pipelines (minting, embossing, packaging) — Sectors: industrial design, packaging, minting
- Description: Convert 2D brand marks and commemorative art into manufacturable reliefs/toolpaths with automated stratification.
- Potential tools/products/workflows: CAM integrations that translate layer order into multi-depth milling/emboss dies.
- Assumptions/dependencies: Mechanical constraints (draft angles, minimum radii); relief-to-toolpath optimization; QA.
- Accessibility-at-scale for tactile textbooks and maps — Sectors: education, public policy
- Description: Semi-automated production of tactile STEM diagrams and maps with consistent symbol hierarchies across curricula.
- Potential tools/products/workflows: District-level services; teacher dashboards to convert visuals; Braille/tactile standards mapping.
- Assumptions/dependencies: Alignment with standards (e.g., BANA/ICEB); human QA; funding and procurement pathways.
- Asset provenance and manipulation forensics — Sectors: trust & safety, compliance
- Description: Analyze layer-order signatures to detect AI generation or composite manipulations in advertising or political content.
- Potential tools/products/workflows: Forensic tools that compare layer order statistics to known priors; integrate with C2PA metadata.
- Assumptions/dependencies: Further research to establish discriminative power; risk of adversarial attacks.
- Smart, responsive creative automation — Sectors: ad-tech, localization
- Description: Auto-adapt layered graphics to formats, languages, or themes by re-stacking, re-coloring, or substituting layers programmatically.
- Potential tools/products/workflows: Creative optimization engines that treat layers as variables; A/B testing by layer variants.
- Assumptions/dependencies: Reliable, semantically meaningful layer grouping; governance around brand safety.
- Education and HCI research on compositional reasoning — Sectors: academia, edtech, HCI
- Description: Study how layer order affects human editability, comprehension, and creative flow; develop curricula for visual composition.
- Potential tools/products/workflows: User studies, classroom modules showing “how artists would layer this” with interactive toggles.
- Assumptions/dependencies: IRB/user research; cross-cultural and domain variability.
- Bandwidth-aware, progressive delivery of layered art — Sectors: web, mobile
- Description: Stream base layers first, refine with foreground details later; enable low-latency previews and progressive enhancement.
- Potential tools/products/workflows: Layer-prioritized SVG streaming; client-side reflow and interaction per layer.
- Assumptions/dependencies: Browser/runtime support for partial rendering; caching/CDN strategies.
- Cross-modal 2D→3D asset bootstrapping — Sectors: games, simulation
- Description: Use illustrator’s depth as a pseudo-elevation prior to scaffold 3D proxies for quick block-outs and parallax scenes.
- Potential tools/products/workflows: DCC add-ons that extrude/offset per layer with material presets; quick previz workflows.
- Assumptions/dependencies: Physical plausibility limits; requires artist oversight to resolve ambiguities.
Notes on core assumptions across applications
- Domain fit: The model excels on illustrations, vector-like renders, and many paintings; complex photoreal scenes, transparency, and fine textures may need retraining or hybrid methods.
- Initialization and data: Performance relies on Depth Pro/DINO-v2 priors and curated, consistently layered SVG data.
- Compute: Real-time or batch use typically requires GPU; mobile/on-device deployment demands optimized models.
- Legal/ethical: Generative pipelines must respect IP/provenance; accessibility deployments need standards compliance and human QA.
- Physical vs illustrator’s depth: The predicted order is editorial (useful for editing) and not a physically metric depth map; workflows that assume true geometry must adapt or fuse with MDE.
Glossary
- Alpha channel: An additional image channel that encodes per-pixel opacity for compositing and consistency. "atlas-based video methods that unwrap scenes into a few textures with an alpha channel for temporal consistency~\cite{lopes_learned_2019,law_image_2025}."
- Amodal segmentation: Segmentation that predicts masks including occluded parts of objects, beyond visible regions. "Amodal instance and amodal-panoptic formulations extend masks to occluded regions (for countable âthingâ categories, typically), while âstuffâ categories remain modal;"
- Atlas-based video methods: Techniques that unwrap scenes into texture atlases (2D maps) to maintain temporal consistency across frames. "atlas-based video methods that unwrap scenes into a few textures with an alpha channel for temporal consistency~\cite{lopes_learned_2019,law_image_2025}."
- Bas-relief: A shallow sculptural technique where shapes slightly protrude from a flat background. "Bas-relief, a shallow form of this technique, is widely applied, from coinage to architectural ornament~\cite{zhang_computer-assisted_2019}."
- Bézier control points: Parameters controlling the shape of Bézier curves used to represent smooth vector paths. "their training often compounds all the steps of the vectorization process (including Bézier control points), resulting in frequent reconstruction failures on complex inputs."
- Cosine learning rate schedule: A training policy where the learning rate varies following a cosine curve over epochs. "Training is done for 40 epochs on 8 Nvidia\textsuperscript{\textregistered!} A100 GPUs, with a cosine learning rate schedule, a max learning rate of , and a batch size of 8."
- Depth ordering consistency: A metric that measures how well the relative depth order between pairs of pixels is preserved. "The resulting depth ordering consistency metric (abbreviated as Order in Tabs.~\ref{tab:mde_comp}-\ref{tab:svg_depth}) measures the percentage of correctly ordered pixel pairs, providing a complementary measure of global depth consistency."
- Depth Pro: A state-of-the-art monocular depth estimation model used as a strong geometric prior. "Depth Pro~\cite{bochkovskii_depth_2025}, built on Dino-v2~\cite{oquab_dinov2_2024} and equipped with a multi-scale encoder, provides a robust feature extractor..."
- Depth Anything-v2: A monocular depth estimation baseline model for predicting physical depth from single images. "We compare our approach with two state-of-the-art monocular depth estimation (MDE) methods, Depth Pro~\cite{bochkovskii_depth_2025} and Depth Anything-v2~\cite{yang_depth_2024}."
- DINO-v2: A self-supervised vision transformer backbone providing rich feature representations for downstream tasks. "we follow~\cite{bochkovskii_depth_2025} by emplying two distinct learning rates for the encoder (DINO-v2 \cite{oquab_dinov2_2024}) and the CNN-based decoder."
- Disocclusions: Regions that become visible in a new view because previously occluding geometry no longer blocks them. "These abstractions excel at detecting disocclusions and synthesizing new views..."
- Flux: A text-to-image diffusion model used to generate high-quality raster images for subsequent vectorization. "By augmenting text-to-image diffusion models like Flux~\cite{labs_flux1_2025} with illustratorâs depth, generated images can be automatically transformed into editable vector graphics."
- Fronto-parallel planes: Planes parallel to the image plane, commonly used in layered scene representations for view synthesis. "Multiplane Images approximate scenes by many fronto-parallel planes for novel-view rendering~\cite{zhou_stereomag_2018,mildenhall_llff_2019}."
- Inpainting: The process of filling or synthesizing content in masked regions of images. "Paired with any inpainting model such as~\cite{rombach_high-resolution_2022}, our method can produce overlapping layers..."
- Layered Depth Images: Representations that store multiple depth samples per ray to model occlusions for view synthesis. "Layered Depth Images store multiple depth samples per ray to model occlusions~\cite{shade_ldi_1998,dhamo2019peeking}..."
- LPIPS: Learned Perceptual Image Patch Similarity, a deep feature-based metric for perceptual image similarity. "Learned Perceptual Image Patch Similarity (LPIPS)~\cite{zhang_unreasonable_2018}."
- Mean Absolute Error (MAE): An error metric computing the average absolute difference between predicted and ground-truth values. "We then train the network using a Mean Absolute Error (MAE) loss on these normalized maps..."
- Mean Squared Error (MSE): An error metric computing the average squared difference between predictions and ground truth, emphasizing larger errors. "we first normalize all predicted depth maps... prior to computing Mean Squared Error (MSE) and Mean Absolute Error (MAE)."
- MiDaS: A family of scale-invariant monocular depth estimation methods; here, a reference for normalization design. "we adopt a scale-invariant normalization scheme similar to MiDaS~\cite{ranftl_towards_2020}."
- Monocular depth estimation (MDE): Predicting scene depth from a single RGB image using learned models. ".2em{Monocular depth estimation (MDE)}~Classical learning approaches for depth estimation from images..."
- Multiplane Images: Scene representations using a stack of fronto-parallel planes to render novel views efficiently. "Multiplane Images approximate scenes by many fronto-parallel planes for novel-view rendering~\cite{zhou_stereomag_2018,mildenhall_llff_2019}."
- Nano Banana: A generative pipeline/model used in multi-stage workflows for synthesizing vector-style illustrations. "a pipeline based on Nano Banana~\cite{google_gemini_2025} and illustrator's depth synthesizes a vector-graphics illustration..."
- OmniSVG: A data-driven, LLM-assisted approach for generating or interpreting SVG graphics. "OmniSVG~\cite{yang_omnisvg_2025}"
- Panoptic segmentation: A segmentation paradigm combining instance and semantic segmentation across all image regions. "compute panoptic segmentations~\cite{kirillov_panoptic_2019,ravi_sam_2025}"
- Potrace: A widely used algorithm to convert raster bitmaps into smooth vector paths. "vectorizing each layer with potrace~\cite{selinger_potrace_2003}."
- Rasterization: The process of converting vector graphics into pixel-based images for rendering or training. "We then rasterize this modified SVG; the resulting ``false color" image is converted back into a per-pixel integer depth map..."
- Scale-invariant normalization: Normalization of depth values (e.g., via median and MAD) to emphasize relative ordering over absolute scale. "we adopt a scale-invariant normalization scheme similar to MiDaS~\cite{ranftl_towards_2020}."
- Scikit-Image: A Python library for image processing used for operations like inpainting and hole filling. "inpaint layers to fill holes and bridge gaps (with, e.g., Scikit-Image~\cite{van2014scikit})"
- Score Distillation Sampling (SDS): An optimization technique that uses diffusion model gradients to produce structured outputs (e.g., vector graphics). "Score Distillation Sampling (SDS)~\cite{zhang_text--vector_2024, polaczek_neuralsvg_2025}"
- SSIM: Structural Similarity Index Measure, an image quality metric capturing luminance, contrast, and structure. "Structural Similarity Index Measure (SSIM)~\cite{zhou_wang_image_2004}"
- Starvector: An LLM-based method for vector graphics generation or reconstruction. "Starvector~\cite{rodriguez_starvector_2025}"
- SVG (Scalable Vector Graphics): An XML-based vector image format that supports layered paths and precise stacking order. "Scalable Vector Graphics (SVG) files are an ideal source for this data, as they are inherently composed of layered vector paths..."
- Tactile graphics: Graphics designed to be perceived by touch, often realized via raised reliefs. "tactile graphics creation"
- Triangulated surface: A mesh representation composed of triangles used to model 3D surfaces from 2D data. "build a triangulated surface by transforming each pixel into a vertex with 3D coordinates , and triangulating adjacent vertices."
- Vectorization: Converting raster images into vector forms (paths, layers) for scalable, editable graphics. "Image vectorization, which consists in converting raster images to vector graphics, is a particularly straightforward application of illustrator's depth."
- VTracer: A heuristic raster-to-vector tool used as a baseline and component in the proposed pipeline. "VTracer~\cite{pun_vtracer_2025}"
Collections
Sign up for free to add this paper to one or more collections.