- The paper introduces a novel QMAE architecture that combines quantum state embedding, learnable mask tokens, and a two-qubit entangling ansatz to reconstruct masked images.
- The paper demonstrates superior performance with a quantum state fidelity of 0.734 and improved reconstruction metrics on the MNIST dataset compared to standard QAE models.
- The paper employs a fidelity-based loss via a SWAP test that enables stable joint optimization of encoder/decoder parameters and mask tokens, ensuring robust feature recovery.
Quantum Masked Autoencoders: Architecture and Empirical Analysis
Overview of Classical and Quantum Autoencoder Paradigms
Autoencoders are efficient feature learners that project high-dimensional data into a compressed latent space and attempt to reconstruct the original data with minimal information loss. Classical masked autoencoders (MAEs) are designed to infer features even with missing portions of input by leveraging learnable mask tokens for reconstruction. The quantum autoencoder (QAE) paradigm extends these concepts by operating on quantum data through variational quantum circuits (VQCs), exploiting superposition and entanglement for potential gains in efficiency and representational power.
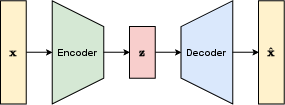
Figure 1: Classical autoencoder architecture, showing the data flow between encoder, latent space, and decoder.

Figure 2: Quantum autoencoder architecture, illustrating the analogous encoder–latent–decoder flow using quantum states and VQCs.
Quantum autoencoders have demonstrated the ability to compress and reconstruct data such as images using fewer parameters compared to classical approaches. However, direct application of classical MAE concepts to quantum circuits encounters obstacles, including limitations in state preparation and mid-circuit measurements inherent to quantum processing.
Proposed Architecture: Quantum Masked Autoencoder (QMAE)
The Quantum Masked Autoencoder (QMAE) introduces several innovations necessary to realize masked reconstruction in the quantum setting:
- Quantum State Embedding: Images, inherently classical, are amplitude embedded into quantum states of size 2n, requiring n qubits per sample vector, and normalized as necessary.
- Encoder/Decoder Ansatz: Both the encoder U(θ) and decoder U†(θ) are implemented using strongly entangling two-qubit interaction circuits following the Wang et al. ansatz, parameterized to entangle feature patches robustly.
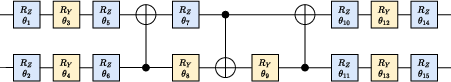
Figure 3: The two-qubit entangling circuit used for image compression in the encoder/decoder ansatz, comprising 18 gates with 15 trainable parameters per pair.
- Learnable Mask Token: Masked image patches are replaced with learnable tokens prior to amplitude embedding. These tokens are trainable parameters that aim to generate content in the masked regions relevant to the surrounding context, mitigating the need for mid-circuit interventions.
- Fidelity-based Loss with SWAP Test: Similarity between the reconstructed and original states is evaluated using a SWAP test—an ancilla qubit captures the fidelity measure ⟨σZ⟩=∣⟨ϕ∣ψ⟩∣2—which is minimized as the primary loss.
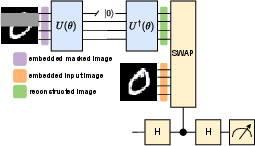
Figure 4: QMAE architectural diagram, detailing input masking, amplitude embedding, encoder/decoder operations, and fidelity measurement via SWAP test.
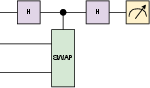
Figure 5: SWAP test circuit for fidelity measurement between two quantum states embedded on separate qubit wires.
The training protocol jointly optimizes the encoder/decoder parameters and the mask tokens by minimizing 1−⟨σZ⟩, typically using Adam or other gradient-based optimizers.
Experimental Evaluation and Comparative Results
All empirical analysis is performed using the MNIST dataset, where 16×16 grayscale images are amplitude embedded into quantum states, requiring 8 qubits. Reconstructions are evaluated both visually and quantitatively using quantum and classical metrics.
Reconstruction Quality: QMAE reconstructions consistently outperform those of QAE in terms of fidelity and perceptual similarity, especially in masked scenarios (e.g., 25% mask). QAE models fail to generate meaningful content in masked regions, whereas QMAE leverages learned tokens to fill in plausible features.

Figure 6: Visual comparison—QMAE (row 1) and QAE (row 2) reconstructions under 25% mask, with original images in row 3.
Masking levels were varied systematically; below 25% mask, QMAE maintains high fidelity, while reconstruction quality degrades at 50%, indicating architectural limits.

Figure 7: QMAE outputs at 12.5%, 25%, and 50% masking, illustrating the fidelity–mask-size trade-off.
Metric Evaluation: Averaged over 10,000 test samples, QMAE achieves quantum state fidelity of 0.734 compared to 0.600 for QAE. Classical cosine similarity and SSIM corroborate QMAE’s superior reconstruction (CS: 0.843 vs. 0.799; SSIM: 0.446 vs. 0.445).
Training Dynamics: QMAE loss converges rapidly and stably to ∼0.25, contrasting with the unstable and elevated loss of QAE, which fluctuates between 0.2 and 0.8.
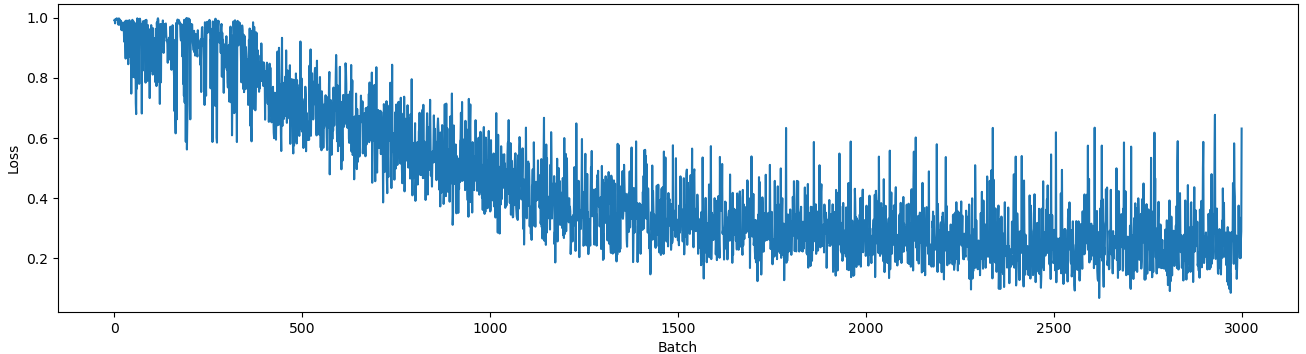
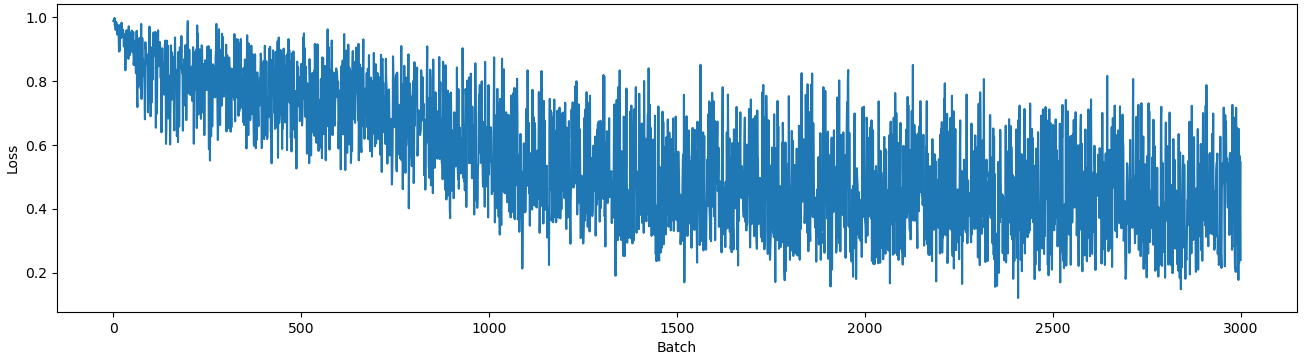
Figure 8: QMAE training loss curve showing robust convergence; QAE training loss is more volatile and achieves poorer minima.
Classifier Accuracy: Images reconstructed by QMAE, when classified by a trained ResNet18, yield 65.06% accuracy versus 52.20% for QAE outputs, substantiating the claim that QMAE reconstructions restore more discriminative features.
Implications and Future Directions
QMAE demonstrates that quantum machine learning models can surpass classical counterparts in masked feature learning, achieving high-fidelity reconstruction with trainable mask tokens exclusively in quantum state space. The approach is significant for domains where training data is incomplete or partially observable, including quantum anomaly detection, quantum-enhanced vision, and robust quantum data compression.
From a theoretical perspective, QMAE opens avenues for investigating the entanglement capacity and generalization behavior of quantum neural models in incomplete data scenarios. Practically, the architecture suggests a path forward for hybrid classical–quantum pipelines, where quantum preprocessing can supply robust interpolations to classical classifiers.
Continued research may address scalability to higher-resolution datasets, the optimal design of mask token insertion and parameterization, and generalization of QMAEs across non-image modalities—potentially fostering resilient, adaptive quantum models with undiminished information recovery under aggressive masking.
Conclusion
Quantum Masked Autoencoders (QMAE) substantively advance feature learning in the quantum domain, enabling principled reconstruction of masked data using quantum circuits. The empirical superiority over quantum autoencoders in fidelity, similarity, and downstream classification establishes QMAE as a compelling approach for quantum-enhanced vision and robust quantum data encoding. The framework invites further inquiry into architectural scalability and cross-modal applications in quantum machine learning (2511.17372).