- The paper introduces Reward-Guided Speculative Decoding (RSD) to combine draft and target models using reward evaluations for efficient LLM reasoning.
- It employs a threshold-based mixture strategy that reduces computational cost by up to 4.4x while boosting accuracy by 3.5 points on reasoning benchmarks.
- Experimental results on tasks like MATH500 demonstrate the approach's scalability and robustness in managing resource-intensive inference scenarios.
Reward-Guided Speculative Decoding for Efficient LLM Reasoning
Introduction
The paper introduces Reward-Guided Speculative Decoding (RSD), a framework that enhances efficiency in LLM inference by combining a draft model and a target model with a focus on reward signals. This approach contrasts with standard speculative decoding (SD), which relies on strict token matching, often leading to computational inefficiency when tokens are mismatched. RSD employs a reward model to evaluate draft outputs and decide whether the target model should be invoked, optimizing the trade-off between computational cost and output quality. Extensive evaluations demonstrate that RSD provides significant efficiency gains over traditional methods, achieving up to 4.4x fewer FLOPs while improving accuracy by up to 3.5 points on reasoning benchmarks.
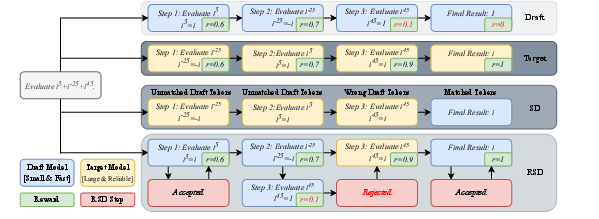
Figure 1: Reward-Guided Speculative Decoding (RSD) improves efficiency by refining draft outputs based on reward signals.
Methodology
RSD integrates a lightweight draft model with a more capable target model, prioritizing high-reward outputs through a controlled bias. Unlike traditional SD methods that enforce strict unbiasedness, RSD employs a reward model to adaptively select high-value draft outputs.
The process begins with a draft model generating candidate steps, which are evaluated using a reward function. If a step's reward score is sufficiently high, it is accepted to continue the reasoning trajectory. Otherwise, the target model is invoked to refine the outputs. This method allows for greater flexibility in exploring diverse completions, reducing the overhead typically associated with strict token matching.
The paper also presents a theoretical framework for RSD, demonstrating that a threshold-based mixture strategy achieves an optimal balance between efficiency and performance. The mixture distribution PRSD balances contributions from both models, guided by a dynamically adjusted weighting function.
RSD Algorithm
The RSD algorithm involves the following steps:
- Draft Step Generation: The draft model generates a candidate step given the prompt and previous outputs.
- Reward Computation: The reward function evaluates the quality of this candidate step.
- Adaptive Acceptance: If the candidate's reward score meets a predefined criterion, the step is accepted. Otherwise, the target model generates a substitute step.
- Iteration: This process iterates until an end-of-sequence (EOS) token is generated or the maximum sequence length is reached.
Technical Implementation
The weighting function ω(r) determines the contribution of the draft model within the mixture distribution. Several variants of ω(r) are proposed, including constant, binary, clipping, sigmoidal, and logistic transformations. A key insight is that the optimal weighting function maximizes the reward by selectively using outputs of the draft model for high-reward regions, while the target model serves as a fallback for low-quality outputs.
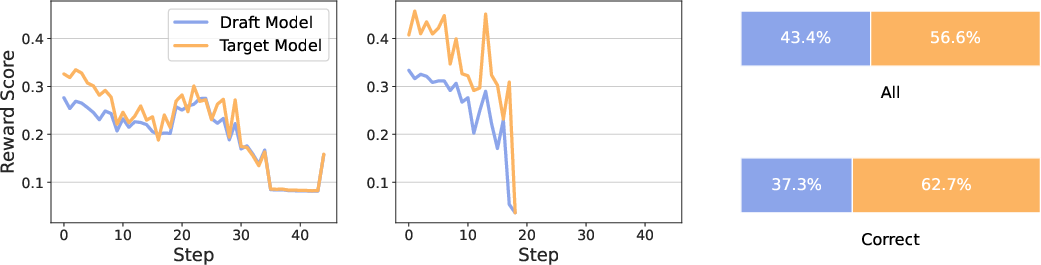
Figure 2: Comparison of reward scores and winning rates between draft and target models within the RSD framework.
RSD outperforms traditional speculative decoding and Best-of-N techniques across multiple reasoning benchmarks such as MATH500 and Olympiad-level tasks. The framework not only improves reasoning accuracy but also significantly reduces computational costs. The approach demonstrates versatility across different model configurations, showcasing robustness and scalability.
Efficiency Gains
Experimental results highlight that RSD with a 7B draft model and a 72B target model achieves higher accuracy than a 72B target model alone, with a computational cost reduction of up to 4.4x, demonstrating the efficiency and practicality of RSD in real-world applications.
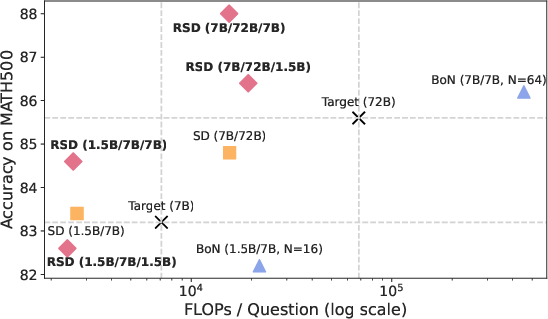
Figure 3: Flops vs. accuracy on MATH500, illustrating RSD's superior efficiency and performance.
Conclusion
Reward-Guided Speculative Decoding presents a promising advancement in LLM inference, offering a scalable solution that balances computational efficiency with reasoning accuracy. This framework is well-suited for resource-intensive scenarios, providing substantial performance improvements while minimizing overhead. Future work may explore the integration of more sophisticated reward models and the extension of RSD to other complex tasks and domains.