TFCDiff: Robust ECG Denoising via Time-Frequency Complementary Diffusion
Abstract: Ambulatory electrocardiogram (ECG) readings are prone to mixed noise from physical activities, including baseline wander (BW), muscle artifact (MA), and electrode motion artifact (EM). Developing a method to remove such complex noise and reconstruct high-fidelity signals is clinically valuable for diagnostic accuracy. However, denoising of multi-beat ECG segments remains understudied and poses technical challenges. To address this, we propose Time-Frequency Complementary Diffusion (TFCDiff), a novel approach that operates in the Discrete Cosine Transform (DCT) domain and uses the DCT coefficients of noisy signals as conditioning input. To refine waveform details, we incorporate Temporal Feature Enhancement Mechanism (TFEM) to reinforce temporal representations and preserve key physiological information. Comparative experiments on a synthesized dataset demonstrate that TFCDiff achieves state-of-the-art performance across five evaluation metrics. Furthermore, TFCDiff shows superior generalization on the unseen SimEMG Database, outperforming all benchmark models. Notably, TFCDiff processes raw 10-second sequences and maintains robustness under flexible random mixed noise (fRMN), enabling plug-and-play deployment in wearable ECG monitors for high-motion scenarios. Source code is available at https://github.com/Miroircivil/TFCDiff.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to clean noisy heart signals (ECGs) called TFCDiff. It’s designed to work well even when someone is moving a lot, like during sports, when ECGs often get messy from different kinds of noise (like body movement or muscle activity). The goal is to remove that noise and keep the important heartbeat shapes accurate, so doctors and wearable devices can trust the results.
What were the main questions?
The authors focused on simple but important questions:
- How can we remove strong, mixed noise from longer ECG recordings (about 10 seconds) without breaking the shape of the heartbeats?
- Can we build a method that works not just on fake (simulated) noise, but also on real-life noisy ECGs it hasn’t seen before?
- Can we make the method efficient enough for wearable devices?
How did they try to solve it?
Think of an ECG like a song recorded in a noisy room. You want to keep the melody (the heartbeat) and remove the background noise (movement, muscles, loose electrodes). TFCDiff does this in three big steps.
1) Work in the “frequency world” instead of the “time world”
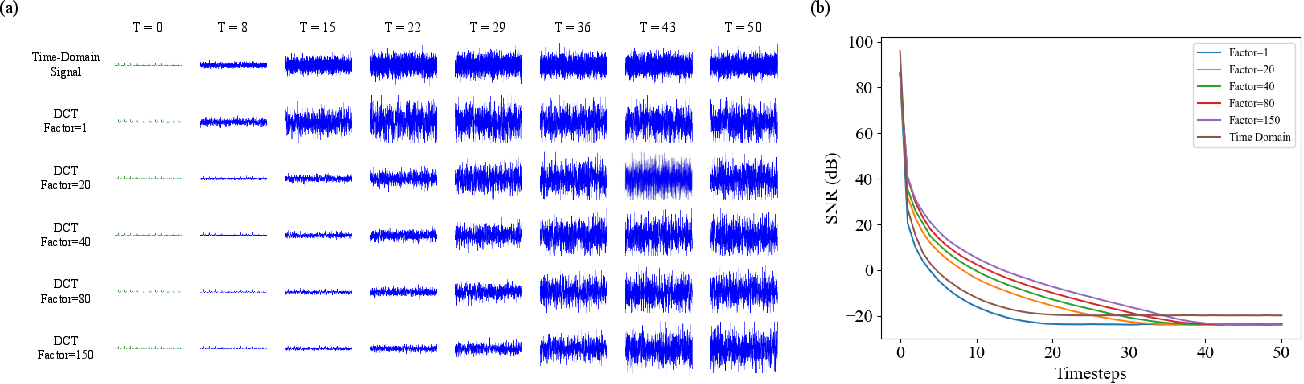
- An ECG is a wavy line over time. The authors convert it using the Discrete Cosine Transform (DCT), which turns the signal into a set of “frequencies,” a bit like turning a song into notes.
- Why do this? Important ECG details mostly live in lower frequencies (about 0.5–50 Hz). By keeping only those and trimming away the unhelpful high frequencies, the model runs faster and focuses on what matters.
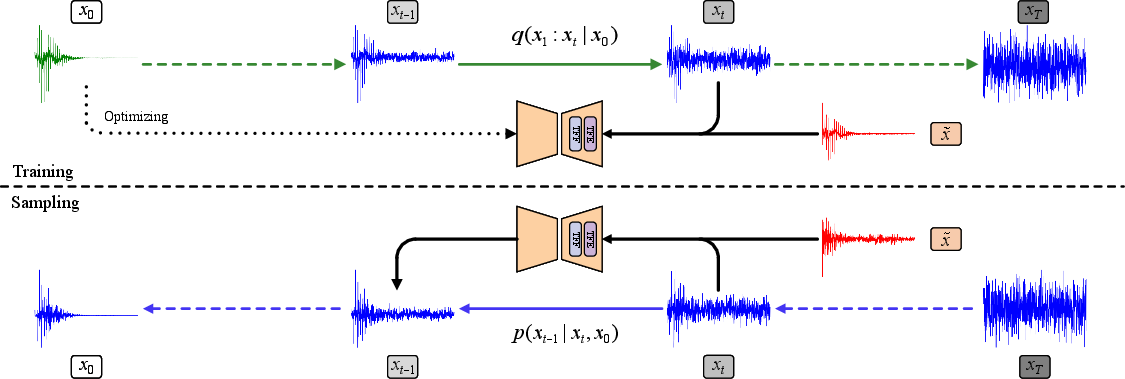
2) Use a “diffusion model” to clean the signal step by step
- Diffusion models are like un-blurring a photo by carefully removing noise in small steps.
- Training: the model learns how noise gets added to clean ECGs (forward process), so it can learn to remove it later.
- Cleaning (sampling): starting from random noise, the model repeatedly “denoises” the signal, guided by the actual noisy ECG you want to fix. This helps it reconstruct a clean version that matches the real heartbeat.
- The model uses the noisy ECG as a hint (a “condition”) so it doesn’t make up shapes but follows what’s in the data.
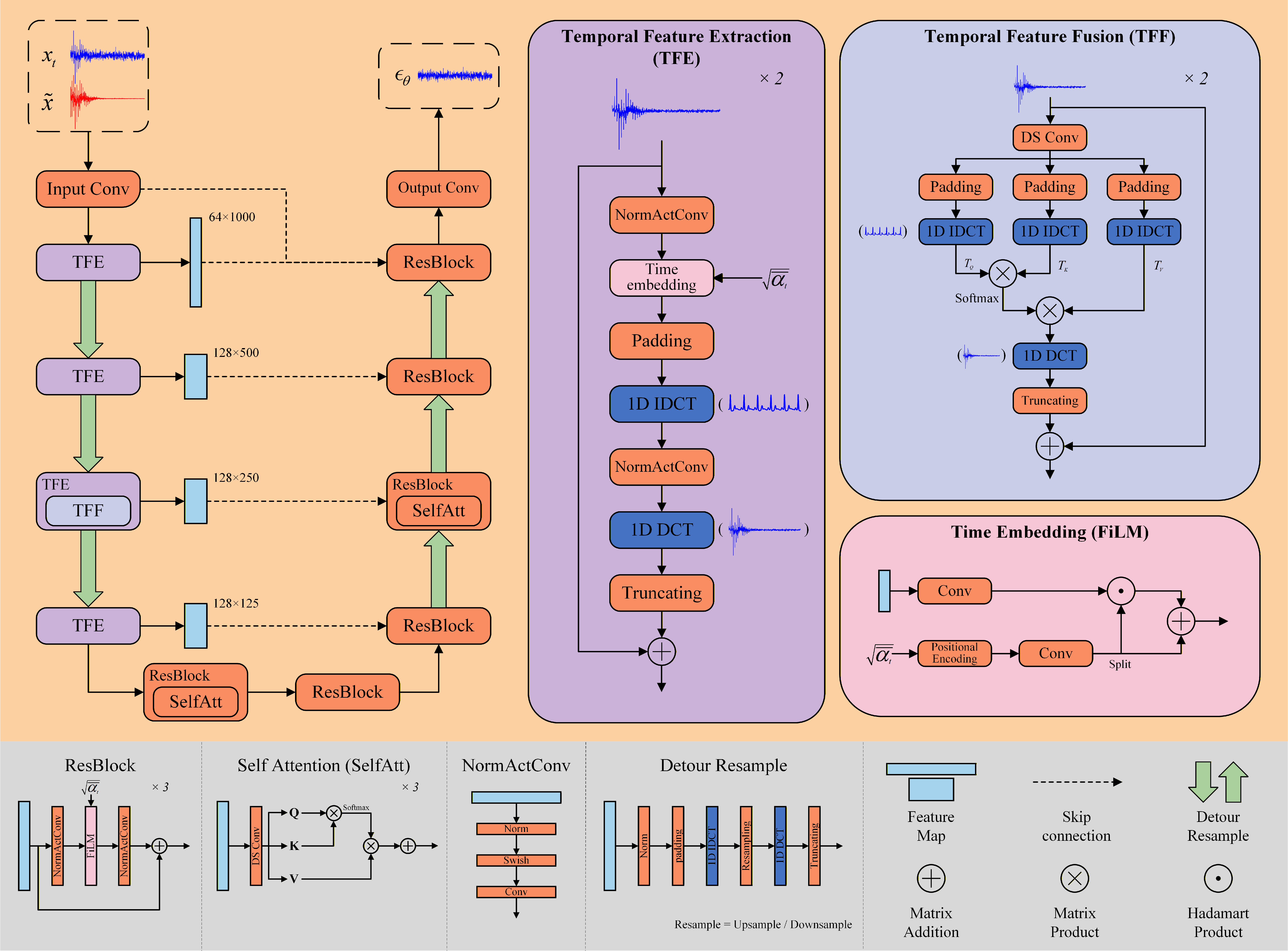
3) Keep the heartbeat shape sharp with TFEM
- Because working in the frequency world can blur time details (like the sharp peaks of a heartbeat), they designed a helper called TFEM (Temporal Feature Enhancement Mechanism).
- TFEM flips features back and forth between frequency and time views, then fuses them. Imagine looking at the signal both as notes (frequency) and as the original waveform (time) to make sure important details (like the QRS peak) are preserved.
To make the method stable and realistic:
- They adjust how quickly noise is added/removed in the frequency world (using a scaled signal-to-noise ratio) so high-frequency details aren’t wiped out too soon.
- They carefully scale the DCT numbers so the model trains smoothly.
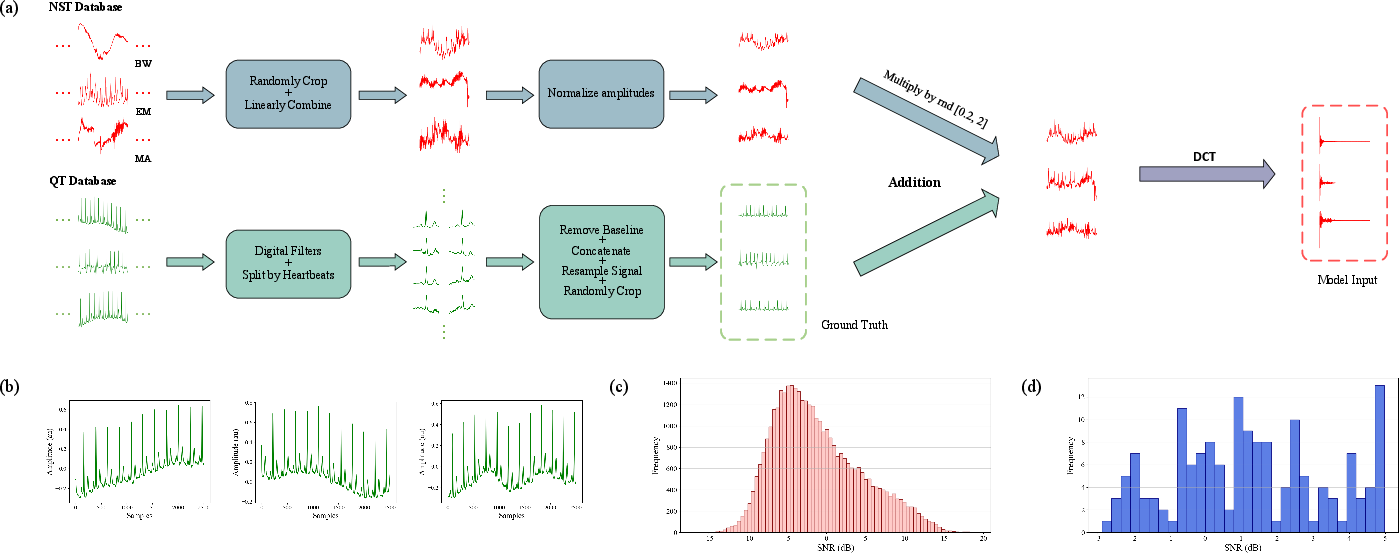
- They train on “flexible random mixed noise” (fRMN): instead of adding one type of noise at a time, they mix several (baseline wander, muscle noise, electrode motion) with random strengths—closer to real life.
- They average several cleaned outputs (like taking multiple photos and averaging) to get a more reliable final ECG.
What did they find?
Across many tests, TFCDiff:
- Beat other popular methods (classic filters, neural networks, and other diffusion models) on five common quality measures. In short, it made ECGs cleaner and closer to the true signal.
- Worked well on long, 10-second recordings—not just on short, one-beat snippets—making it more practical.
- Generalized better to a separate, real dataset (SimEMG) with genuine muscle noise it never saw during training. This means it’s more likely to work on real-world data from wearables.
- Stayed strong even when noise types and strengths were mixed randomly, which is what happens in everyday movement.
Why is that important? Clean ECGs lead to better diagnosis and safer decision-making, especially during exercise or daily activities.
Why does this matter?
- For patients and athletes: Wearable heart monitors could give more accurate readings while you walk, run, or exercise—times when current devices often struggle.
- For doctors: Cleaner signals improve the chance of catching heart problems early and correctly.
- For devices: The method is efficient (thanks to trimming unneeded frequencies) and robust, which makes it easier to plug into real products.
In short, TFCDiff is a step toward reliable, real-world ECG cleaning: it understands both the “notes” (frequency) and the “melody” (time shape) of the heartbeat, and uses a careful, step-by-step denoising process to bring out the true signal even in messy, high-motion situations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research:
- Real-world clinical validation: The study reports signal-level metrics only; it does not evaluate downstream diagnostic performance (e.g., beat delineation, QRS detection accuracy, ST-segment measurements, arrhythmia classification) or clinician-centered assessments of morphological fidelity.
- Runtime, latency, and energy use on wearables: No measurements of inference time, sampling latency across T=50 steps, impact of k-generation averaging, memory footprint, or power consumption are provided, despite claims of plug-and-play deployment in wearable devices.
- Streaming/online denoising: The method is evaluated on isolated 10-second segments; boundary continuity, overlap–add strategies, and performance in continuous streaming scenarios remain unaddressed.
- Multilead ECG applicability: The model is evaluated on single-lead segments; how to extend TFCDiff to 12-lead ECG and exploit inter-lead correlations for improved denoising is not explored.
- Sampling-rate robustness: Training/testing are normalized to 360 Hz (with SimEMG downsampled). The impact of varying sampling rates (e.g., 250, 500, 1000 Hz) and resampling artifacts on TFCDiff’s performance is not characterized.
- Fixed DCT truncation at 50 Hz: The choice to retain only sub-50 Hz content may suppress clinically relevant high-frequency components (e.g., fragmented QRS, late potentials, pacemaker spikes) and ignores powerline interference at 50/60 Hz. Methods for adaptive or patient/device-specific truncation thresholds are absent.
- Noise realism and coverage: The flexible random mixed noise (fRMN) uses NSTDB BW/MA/EM with uniform random weights, which may not reflect true ambulatory noise distributions (e.g., nonstationary bursts, electrode dropouts, cable microphonics, respiration harmonics, powerline hum). A data-driven calibration of mixture ratios and inclusion of additional real-world noise sources is missing.
- Reliance on synthetic paired data: Training depends on synthesized clean–noisy pairs; strategies for unsupervised/self-supervised learning from unpaired real recordings (where clean ground truth is unavailable) are not investigated.
- Ground-truth preprocessing bias: The piecewise baseline wander removal using expert annotations may introduce artifacts and relies on annotations not available in practice. Its effect on learned signal priors and model bias is not quantified or validated against standard clinical baseline-removal methods.
- Hyperparameter sensitivity and ablations: Key design choices (SNR scaling factor c=150, percentile τ=1.75 for the scaling bound η, number of retained DCT coefficients, number of diffusion steps T, k in model-k averaging) are chosen empirically without systematic ablation or robustness analysis.
- Frequency-aware diffusion scheduling: The SNR scaling is global; per-frequency or band-specific schedules, adaptive noise injection, or frequency-weighted losses that reflect ECG spectral characteristics are not explored.
- Architecture component effectiveness: The contribution of TFEM (TFE/TFF), detour resample strategy, and attention placements lacks quantitative ablation; decoder-side TFEM was said to show no benefit but is not documented with results.
- Extreme noise/artifact robustness: Performance under more severe conditions (e.g., λ > 2, clipping, saturation, missing samples, abrupt electrode motion) is not reported; SimEMG evaluation excludes segments with SNR ≥ 5 dB, leaving performance in moderate-noise regimes unclear.
- Baseline comparisons breadth: Only one diffusion baseline (DesCod) is included; comparisons to accelerated samplers (DDIM/ODE/consistency/rectified flow), latent diffusion, GAN-based denoisers, wavelet-domain models, or recent audio/time-series diffusion methods are absent.
- Device/domain calibration: The scaling bound η is estimated from the training data; procedures for on-the-fly calibration to new devices/patient populations with different amplitude distributions are not provided.
- Uncertainty quantification and failure detection: While ensemble averaging (model-k) is used, there is no mechanism to quantify uncertainty, detect unreliable outputs, or flag potentially degraded reconstructions for clinician review.
- Impact on derived metrics: Effects of denoising on heart-rate variability, QT interval measurement, and other clinical biomarkers are not assessed.
- Multimodal conditioning: The model conditions only on the noisy ECG; leveraging auxiliary sensors (e.g., IMU/accelerometer/PPG) to inform motion/noise removal is not explored.
- Pathology-stratified performance: Generalization across specific pathologies (e.g., AF, ischemia, conduction abnormalities), heart-rate variability extremes, and rhythm transitions is not stratified or analyzed.
- Continuous deployment and drift: Strategies for handling electrode aging, calibration drift, and long-term device variability (domain adaptation, continual learning) are not addressed.
Glossary
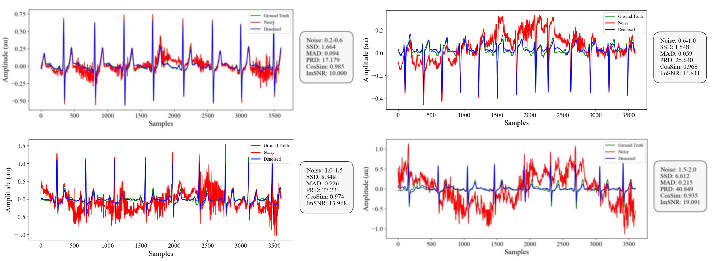
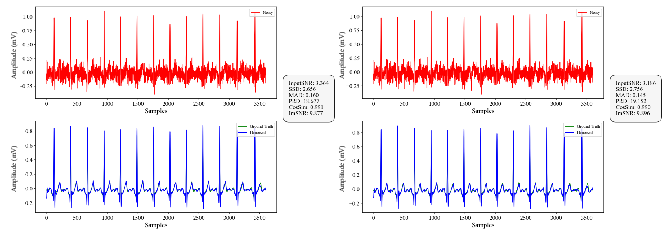
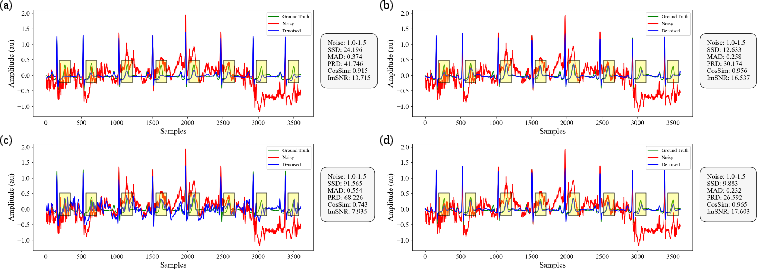
- Absolute Maximum Distance (MAD): A distortion metric measuring the maximum absolute difference between corresponding points in two signals; example: "Sum of the Square of the Distances (SSD), Absolute Maximum Distance (MAD) and Percentage Root-Mean-Square Difference (PRD) are distance-based metrics"
- Autoregressive model: A generative modeling approach where current outputs depend on previous outputs; example: "Buchholz et al. applied an autoregressive model in the Fourier domain to tackle image super-resolution tasks \cite{bib35}."
- Bandpass filter: A digital filter that passes frequencies within a certain range and attenuates frequencies outside that range; example: "we first apply digital filters including a bandpass filter and a median filter to remove impulsive artifacts."
- Baseline wander (BW): Low-frequency drift in ECG baseline caused by respiration or movement; example: "including baseline wander (BW), muscle artifact (MA), and electrode motion artifact (EM)"
- Clamp operation: A numeric stabilization step that restricts values within bounds during sampling; example: "for DeScoD, the \verb|clamp| operation must be enabled in sampling process, otherwise the generation process collapses due to unbounded outputs."
- Conditional diffusion model: A generative model that denoises data conditioned on observed inputs; example: "we propose TFCDiff, a conditional diffusion model defined in the frequency domain that trains and performs inference on raw 10-second sequences."
- Cosine Similarity (CosSim): A similarity metric based on the cosine of the angle between two vectors; example: "Cosine Similarity (CosSim) assesses similarity by computing the cosine of the angle between two vectors."
- Depthwise separable convolution: A factorized convolution splitting spatial (depthwise) and channel mixing (pointwise) operations; example: "Depthwise separable convolution is used to encode the feature map into , , ."
- Denoising Autoencoders (DAEs): Neural networks trained to reconstruct clean inputs from noisy versions; example: "Denoising Autoencoders (DAEs) have also been notably applied, with variants such as Fully Convolutional Network (FCN-DAE) \cite{bib13}, Convolutional Block Attention Module (CBAM-DAE) \cite{bib14}, and Attention-based Convolutional (ACDAE) \cite{bib15}."
- Detour resample strategy: A resampling method that switches to time domain to avoid aliasing when up/downsampling frequency-domain features; example: "To alleviate the problem, we introduce a detour resample strategy."
- Discrete Cosine Transform (DCT): A real-valued transform providing energy compaction for signals; example: "we propose Time-Frequency Complementary Diffusion (TFCDiff), a novel approach that operates in the Discrete Cosine Transform (DCT) domain"
- Discrete Fourier Transform (DFT): A transform converting time-domain signals into complex-valued frequency components; example: "The Discrete Cosine Transform (DCT), a variant of the Discrete Fourier Transform (DFT), produces real-valued frequency coefficients by extending a real input signal to an even function \cite{bib36}."
- Dual-path diffusion process: A diffusion strategy that separates different noise sources into distinct paths; example: "Building on this, \cite{bib19} introduced a dual-path diffusion process that separates ECG noise diffusion from Gaussian noise diffusion"
- Electrode motion artifact (EM): Noise caused by movements of ECG electrodes; example: "including baseline wander (BW), muscle artifact (MA), and electrode motion artifact (EM)"
- Electromyographic (EMG) noise: Muscle activity noise contaminating ECG signals; example: "baseline wander (BW), muscle artifact (MA) also known as electromyographic (EMG) noise, and electrode motion artifact (EM)."
- Entropy-Consistent Scaling: A scaling method ensuring stable diffusion by using bounds derived from DC components; example: "Inspired by the Entropy-Consistent Scaling approach \cite{bib30}, we decompose the DCT coefficients into a direct current (DC) component and an alternating current (AC) component."
- Evidence lower bound (ELBO): A variational objective minimized to align the model with the data distribution; example: "we minimize the variational evidence lower bound (ELBO) of -log p({x}_{0}|\tilde{x})."
- Feature-wise Linear Modulation (FiLM): A conditioning mechanism applying learned per-feature scaling and shifting; example: "Regarding time embedding, we employ feature-wise linear modulation (FiLM) with affine transformation \cite{bib43}."
- Flexible random mixed noise (fRMN): A noise synthesis strategy that randomly weights multiple noise types; example: "we adopt a flexible random mixed noise (fRMN) strategy in our synthesized dataset, which assigns random weights to different noise types to enhance diversity."
- Flow matching: A training paradigm that matches model flows to target distributions; example: "Additionally, \cite{bib27} introduced flow matching for building arbitrary distributions."
- Frequency resolution: The spacing between adjacent frequency bins in a transform domain; example: "Assuming a sampling frequency of , the frequency resolution is "
- Group Normalization: A normalization technique normalizing over groups of channels; example: "The fundamental building block of the network is a residual block comprising Group Normalization, Swish activation, and 1D convolution."
- Hermite interpolation: A smooth interpolation method using derivatives to ensure continuity; example: "we concatenate the corrected segments and apply Hermite interpolation at the junctions to ensure smooth transitions, resulting in clean ECG signals."
- Hierarchical uniform sampling: A timestep sampling scheme improving generalization across noise levels; example: "Additionally, we adopt the hierarchical uniform sampling approach proposed in \cite{bib40}, which enables the noise predictor to generalize across continuous noise levels."
- Improved SNR (ImSNR): The gain in signal-to-noise ratio achieved by denoising; example: "Improved SNR (ImSNR) quantifies the enhancement in signal quality achieved through denoising."
- Infinite Impulse Response (IIR): A filter with feedback resulting in an infinite-duration impulse response; example: "Digital filters include Finite Impulse Response (FIR) and Infinite Impulse Response (IIR) filters, which contain no learnable parameters."
- Inverse DCT (IDCT): The transform that reconstructs a time-domain signal from its DCT coefficients; example: "The original time-domain signal is recovered using the inverse DCT (IDCT), implemented via the type-III DCT."
- Isotropic Gaussian noise: Gaussian noise with identical variance in all directions; example: "When , approximates isotropic Gaussian noise."
- Latent representation: The intermediate variable in diffusion representing the corrupted signal at step t; example: "where is the latent representation at step "
- Monte Carlo estimation: A statistical method using random sampling to estimate parameters; example: "From the DC components of this dataset, we compute the Monte Carlo estimation of the scaling bound , using percentile-based truncation to mitigate the impact of outliers:"
- Multi-head Self-attention (MHSA): An attention mechanism computing multiple attention heads for richer feature interactions; example: "substituted Multi-head Self-attention (MHSA) with a dynamic filter based on Fourier Transform for efficient high-resolution image recognition \cite{bib31}."
- Muscle artifact (MA): ECG noise due to muscle activity; example: "including baseline wander (BW), muscle artifact (MA), and electrode motion artifact (EM)"
- Noise predictor: The model component that estimates added noise during diffusion; example: "the noise predictor, conditioned on the noisy observation , learns to predict the added noise."
- Noise schedule: The timestep-dependent rule controlling noise addition/removal in diffusion; example: "The noise schedule governs the progression of noise addition during the forward diffusion process and noise removal during the reverse process."
- Ordinary Differential Equation (ODE): A continuous-time formulation used to speed up diffusion sampling; example: "To address the issue of slow generation, \cite{bib26} reformulated the sampling process as a deterministic ordinary differential equation (ODE), reducing sampling steps from thousands \cite{bib23} to just 10-20."
- Percentage Root-Mean-Square Difference (PRD): A percentage error metric based on RMS differences; example: "Sum of the Square of the Distances (SSD), Absolute Maximum Distance (MAD) and Percentage Root-Mean-Square Difference (PRD) are distance-based metrics"
- Quadratic variance-preserving noise schedule: A specific schedule shaping noise variance quadratically across timesteps; example: "We initially define a quadratic variance-preserving noise schedule based on a total of timesteps and boundary values , "
- Random mixed noise (RMN): A synthetic noise scheme combining multiple types uniformly; example: "TCDAE introduced a random mixed noise (RMN) strategy, which randomly selected one or more noise types and combined them with uniform weights to mimic real-world noise conditions."
- Residual block: A neural network module with skip connections enabling stable, deeper models; example: "The fundamental building block of the network is a residual block comprising Group Normalization, Swish activation, and 1D convolution."
- Signal-to-noise ratio (SNR): The ratio of signal power to noise power; example: "Given this schedule, the signal-to-noise ratio (SNR) of the latent signal at timestep is computed as:"
- Sinusoidal positional embeddings: Fixed-frequency encodings used to represent positions or scalars like noise levels; example: "The noise level is first encoded by sinusoidal positional embeddings \cite{bib44}"
- Skip connections: Direct links between non-adjacent layers to preserve information across scales; example: "Skip connections further bridge corresponding encoder and decoder layers at multiple scales to recover information lost during downsampling."
- SNR scaling factor: A multiplier applied to the SNR schedule to modulate noise dynamics; example: "we introduce an SNR scaling factor to modulate the noise progression in diffusion."
- Strided convolutions: Convolutions using strides to downsample or upsample signals; example: "then upsampled or downsampled using strided convolutions or interpolation"
- Sum of the Square of the Distances (SSD): A squared-error metric for signal distortion; example: "Sum of the Square of the Distances (SSD), Absolute Maximum Distance (MAD) and Percentage Root-Mean-Square Difference (PRD) are distance-based metrics"
- Swish activation: A smooth activation function defined as x·sigmoid(x); example: "The fundamental building block of the network is a residual block comprising Group Normalization, Swish activation, and 1D convolution."
- Temporal Feature Enhancement Mechanism (TFEM): A cross-domain module to enrich temporal details in frequency-based processing; example: "we propose a Temporal Feature Enhancement Mechanism (TFEM) to mitigate this limitation."
- Temporal Feature Extraction (TFE): The TFEM submodule that transforms features between DCT and time domains; example: "TFEM is composed of two modules: Temporal Feature Extraction (TFE) and Temporal Feature Fusion (TFF)."
- Temporal Feature Fusion (TFF): The TFEM submodule that fuses time-domain features via attention-like operations; example: "TFEM is composed of two modules: Temporal Feature Extraction (TFE) and Temporal Feature Fusion (TFF)."
- Truncation (of DCT coefficients): The process of retaining only informative low-frequency coefficients; example: "Truncation of DCT coefficients for 10-s signals sampled at 360 Hz by retaining the first 1000 coefficients to preserve frequency content below 50 Hz."
- U-Net: An encoder–decoder architecture with skip connections widely used for denoising; example: "The architecture of the noise predictor, as depicted in Fig.\autoref{fig5}, incorporates an encoder-decoder framework developed from the classical U-Net \cite{bib41}."
Practical Applications
Immediate Applications
Below are actionable, sector-linked applications that can be deployed now based on TFCDiff’s findings, methods, and innovations.
- Robust ECG denoising in wearables during high-motion activities (Healthcare, Consumer Electronics)
- Description: Plug-and-play denoising module for smartwatches, chest straps, and fitness trackers to reduce baseline wander, EMG, and electrode motion artifacts in 10-second windows.
- Potential tools/products/workflows: On-device SDK (Python/C++/ONNX), embedded firmware module using truncated DCT + TFCDiff sampling (T≈50 steps), optional model-k ensemble for quality vs. latency trade-off.
- Assumptions/Dependencies: Sufficient edge compute; battery/performance constraints for diffusion sampling; validation on diverse populations and device form factors.
- Improved signal preprocessing in ambulatory/remote cardiac monitoring (Healthcare, Telemedicine)
- Description: Pre-processing pipeline that increases SNR and preserves morphology for Holter monitors, patch ECGs, and RPM (remote patient monitoring) platforms, enhancing automated arrhythmia detection accuracy.
- Potential tools/products/workflows: Cloud microservice for ECG upload → DCT truncation → TFCDiff denoising → downstream detection; integration with WFDB-compatible systems.
- Assumptions/Dependencies: Clinical validation for targeted indications; integration with existing telemetry workflows; adherence to data privacy and cybersecurity standards.
- Alarm fatigue reduction in ICUs and step-down units via post-processing (Healthcare)
- Description: Lower false positives caused by motion and EMG artifacts in bedside monitors by deploying TFCDiff as a post-filter.
- Potential tools/products/workflows: Vendor-neutral plugin or middleware between ECG feed and alarm logic; tunable sampling (model-k) for low latency.
- Assumptions/Dependencies: Real-time constraints (sub-second latency); regulatory evaluation for safety-critical alarms.
- Higher-quality ECG datasets for research and algorithm development (Academia, Software)
- Description: Use TFCDiff to clean training/test sets, improving annotation quality and downstream ML models (e.g., QRS detection, AF classification).
- Potential tools/products/workflows: Batch-denoising pipeline; reproducible scripts (from the provided GitHub) with documented fRMN synthesis and DCT truncation.
- Assumptions/Dependencies: Transparent reporting that denoising has been applied; monitoring for possible bias if denoised signals deviate from raw distributions.
- Sports cardiology analytics in noisy, free-living conditions (Healthcare, Sports/Fitness)
- Description: More reliable ECG features (e.g., HRV, morphology-based metrics) during workouts or competitions.
- Potential tools/products/workflows: Mobile app plugin that denoises workout ECG segments; offline edge processing to preserve privacy.
- Assumptions/Dependencies: Validation across exercise modalities; careful handling of windowing (10 s) for time-sensitive analyses.
- Telehealth triage enhancement with artifact-resilient ECG (Healthcare, Telemedicine)
- Description: Clinician dashboards with denoised overlays to improve remote interpretation and triage decisions.
- Potential tools/products/workflows: PACS/EHR-integrated viewer that displays raw vs. denoised traces; configurable SNR scaling (c≈150) for different acquisition setups.
- Assumptions/Dependencies: UX and clinical workflow adoption; encryption and secure transmission.
- Consumer mobile apps for HRV and rhythm notifications with fewer false alarms (Daily Life, Software)
- Description: In-app TFCDiff denoising before feature extraction to stabilize HRV and rhythm classification in real-world use.
- Potential tools/products/workflows: Lightweight inference via quantized models; fallback to fewer sampling steps for low-power devices.
- Assumptions/Dependencies: Model calibration to each device’s sampling rate (e.g., 250–500 Hz); transparent disclosures that outputs are not medical diagnoses.
- Vendor toolkits for ECG hardware manufacturers (Medical Devices, Software)
- Description: OEM-embeddable denoising library to improve out-of-the-box signal quality across device lines.
- Potential tools/products/workflows: API/SDK with configurable DCT truncation thresholds (e.g., preserving <50 Hz); production-ready model export (ONNX/TFLite).
- Assumptions/Dependencies: Cross-device generalization; performance/latency benchmarking and certification needs.
Long-Term Applications
These applications require further research, scaling, optimization, or regulatory development before broad deployment.
- Real-time streaming denoising with accelerated diffusion (Healthcare, Edge AI)
- Description: Continuous artifact removal on sliding windows with reduced-step samplers (DDIM, distillation) or hardware acceleration.
- Potential tools/products/workflows: Distilled TFCDiff variants; FPGA/ASIC or NPU implementations; adaptive noise schedules tailored to device and context.
- Assumptions/Dependencies: Significant engineering to cut latency/compute; robust performance across arrhythmias and edge cases.
- Multi-lead and multi-modal conditioning (12-lead ECG with accelerometer, impedance) (Healthcare)
- Description: Conditioning TFCDiff on additional signals to better model motion artifacts and electrode dynamics.
- Potential tools/products/workflows: Sensor fusion architectures; cross-domain embeddings; calibration protocols per lead configuration.
- Assumptions/Dependencies: Dataset availability for multi-modal training; more complex integration in clinical monitors.
- Regulatory-grade clinical validation and certification (Policy, Healthcare)
- Description: Prospective trials demonstrating improved diagnostic accuracy and reduced false alarms across demographics and pathologies.
- Potential tools/products/workflows: Study protocols; harmonized evaluation metrics; submissions to FDA/CE and alignment with AAMI/IEC standards.
- Assumptions/Dependencies: Multi-center data; endpoints tailored to clinical outcomes; post-market surveillance.
- Specialized workflows for high-risk populations (e.g., pacemakers, pediatric patients) (Healthcare)
- Description: Customized denoising profiles that avoid suppressing clinically relevant high-frequency events (e.g., pacemaker spikes).
- Potential tools/products/workflows: Adaptive DCT truncation (beyond <50 Hz); safety rails and morphology-preserving constraints; clinician-configurable presets.
- Assumptions/Dependencies: Careful assessment of frequency content requirements; expanded training data for special populations.
- Cross-signal extensions (PPG, EEG, fetal ECG extraction, EMG) (Healthcare, Research)
- Description: Adapting time-frequency conditional diffusion with TFEM to other biomedical signals prone to motion/EMG artifacts.
- Potential tools/products/workflows: Signal-specific truncation rules; domain-informed conditioning (e.g., respiration for PPG); benchmarks for artifact suppression.
- Assumptions/Dependencies: New datasets and clinical validation; tailoring noise schedules and feature fusion to each modality.
- Population-scale monitoring and risk stratification (Healthcare, Insurance)
- Description: More reliable longitudinal ECG features enabling better risk scoring and early intervention programs.
- Potential tools/products/workflows: Cloud-scale pipelines; privacy-preserving federated deployment; standardized denoising for cohort analyses.
- Assumptions/Dependencies: Ethical use and compliance; bias auditing; alignment with payer/provider policies.
- Education and training in digital cardiology (Academia, Education)
- Description: Use TFCDiff as a teaching tool to demonstrate modern denoising and time–frequency techniques in biomedical engineering curricula.
- Potential tools/products/workflows: Course modules; interactive notebooks; comparative labs against classic filters and DAEs.
- Assumptions/Dependencies: Maintenance of open-source resources; accessibility of datasets.
- Standardization of artifact handling in wearable ECG data (Policy, Standards)
- Description: Inform guidelines for denoising and reporting in consumer and clinical devices to improve interoperability and trust.
- Potential tools/products/workflows: Best-practice documents; conformance tests; inclusion in digital health quality frameworks.
- Assumptions/Dependencies: Consensus-building with professional societies; evidence of clinical benefit and minimal risk.
- Vendor-neutral quality scoring and benchmarking (Software, Healthcare)
- Description: SNR-based quality indicators and reproducible benchmarks for denoising algorithms across vendors and datasets.
- Potential tools/products/workflows: Open evaluation suite using TFCDiff’s metrics (SSD, MAD, PRD, CosSim, ImSNR); fRMN-based synthetic stress tests.
- Assumptions/Dependencies: Community adoption; governance for benchmark updates; dataset sharing agreements.
- Hardware co-design for low-power denoising (Medical Devices, Energy)
- Description: Joint optimization of model and hardware to minimize energy use while meeting clinical performance targets.
- Potential tools/products/workflows: Model compression, quantization, and sparse inference; DCT/IDCT accelerators; pipeline co-design with sensor front-ends.
- Assumptions/Dependencies: Investment in hardware R&D; clear specs for acceptable delay and fidelity.
General Assumptions and Dependencies Across Applications
- Training and validation data represent the noise distributions encountered in target settings; further datasets (e.g., multi-ethnic, multi-lead, varied activities) may be needed.
- The default DCT truncation (<50 Hz) suits typical clinical ECG but may require adjustment for cases needing higher-frequency fidelity (e.g., pacemaker spikes, microvolt T-wave alternans).
- Diffusion sampling (T≈50, model-k ensemble) introduces latency and compute demands; practical deployments may need acceleration, reduced steps, or distillation.
- Regulatory clearance is required for clinical decision support or alarm-related use; current results show technical SOTA but not clinical outcomes.
- Device sampling rates and amplitude scales must be harmonized (e.g., 250–500 Hz, scaling factor η) to ensure stable inference.
- Transparency that denoised outputs are algorithmic reconstructions; downstream clinical algorithms should be audited for shifts in performance after denoising.
Collections
Sign up for free to add this paper to one or more collections.