Correlation-Aware Feature Attribution Based Explainable AI
Abstract: Explainable AI (XAI) is increasingly essential as modern models become more complex and high-stakes applications demand transparency, trust, and regulatory compliance. Existing global attribution methods often incur high computational costs, lack stability under correlated inputs, and fail to scale efficiently to large or heterogeneous datasets. We address these gaps with \emph{ExCIR} (Explainability through Correlation Impact Ratio), a correlation-aware attribution score equipped with a lightweight transfer protocol that reproduces full-model rankings using only a fraction of the data. ExCIR quantifies sign-aligned co-movement between features and model outputs after \emph{robust centering} (subtracting a robust location estimate, e.g., median or mid-mean, from features and outputs). We further introduce \textsc{BlockCIR}, a \emph{groupwise} extension of ExCIR that scores \emph{sets} of correlated features as a single unit. By aggregating the same signed-co-movement numerators and magnitudes over predefined or data-driven groups, \textsc{BlockCIR} mitigates double-counting in collinear clusters (e.g., synonyms or duplicated sensors) and yields smoother, more stable rankings when strong dependencies are present. Across diverse text, tabular, signal, and image datasets, ExCIR shows trustworthy agreement with established global baselines and the full model, delivers consistent top-$k$ rankings across settings, and reduces runtime via lightweight evaluation on a subset of rows. Overall, ExCIR provides \emph{computationally efficient}, \emph{consistent}, and \emph{scalable} explainability for real-world deployment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a fast and simple way to explain how AI models make decisions. The method is called ExCIR (Explainability through Correlation Impact Ratio). It ranks which input features (the “clues” the model looks at) matter most by checking how strongly each feature tends to move in the same direction as the model’s output. It also has a group version (BlockCIR) to handle features that are very similar to each other, and a “lightweight” trick to get almost the same explanations using only part of the data, which saves a lot of time.
What questions were the researchers trying to answer?
The researchers wanted to know:
- Can we explain a model’s decisions quickly without running the model over and over again?
- Can we make explanations stable and fair when some features are highly similar (like duplicate sensors or synonym words)?
- Can we get reliable explanations even if we only use a smaller sample of the data (to save time or protect privacy)?
How did they do it? (Methods in simple terms)
Think of an AI model like a machine that takes many clues (features) and produces a score or prediction (output). ExCIR checks which clues usually move together with the machine’s score.
Here’s the idea with simple analogies:
- Robust centering: Before comparing things, they “reset the zero point” by subtracting a middle value (like the average of the 25th and 75th percentiles) from each feature and from the model’s output. This is like leveling a scale so that extreme outliers don’t tilt it too much.
- Co-movement: For each data row, they multiply the centered feature value by the centered model output. If both are above their middles, or both below, the product is positive (they move together). If one is up and the other is down, the product is negative (they move in opposite directions).
- Scoring (ExCIR): For each feature, add up all these products and compare the “moving together” amount to the total movement (regardless of direction). This gives a score between 0 and 1:
- Near 1 means the feature mostly moves in the same direction as the model’s output.
- Around 0.5 means no clear pattern.
- Near 0 means it tends to move in the opposite direction.
- Group scoring (BlockCIR): When features are very similar (like two sensors measuring almost the same thing, or synonym words in text), scoring them one by one can “double-count.” BlockCIR groups such features and scores the group as a team to avoid splitting or duplicating credit.
- Lightweight transfer: You don’t always need all the data. The method can calculate rankings using only 20–40% of the rows and still be very close to the rankings you’d get from using 100%. This saves time and is helpful when computing power or data access is limited.
Technical bonus made simple:
- The method is single-pass and model-agnostic: it just needs the feature matrix and the model’s outputs, not the model’s internals.
- It’s stable if you shift or scale data (like changing units), and it works well for streaming data (you can update it as data arrives).
What did they find, and why does it matter?
Here are the main takeaways from testing on many kinds of datasets (text, tables, images, signals):
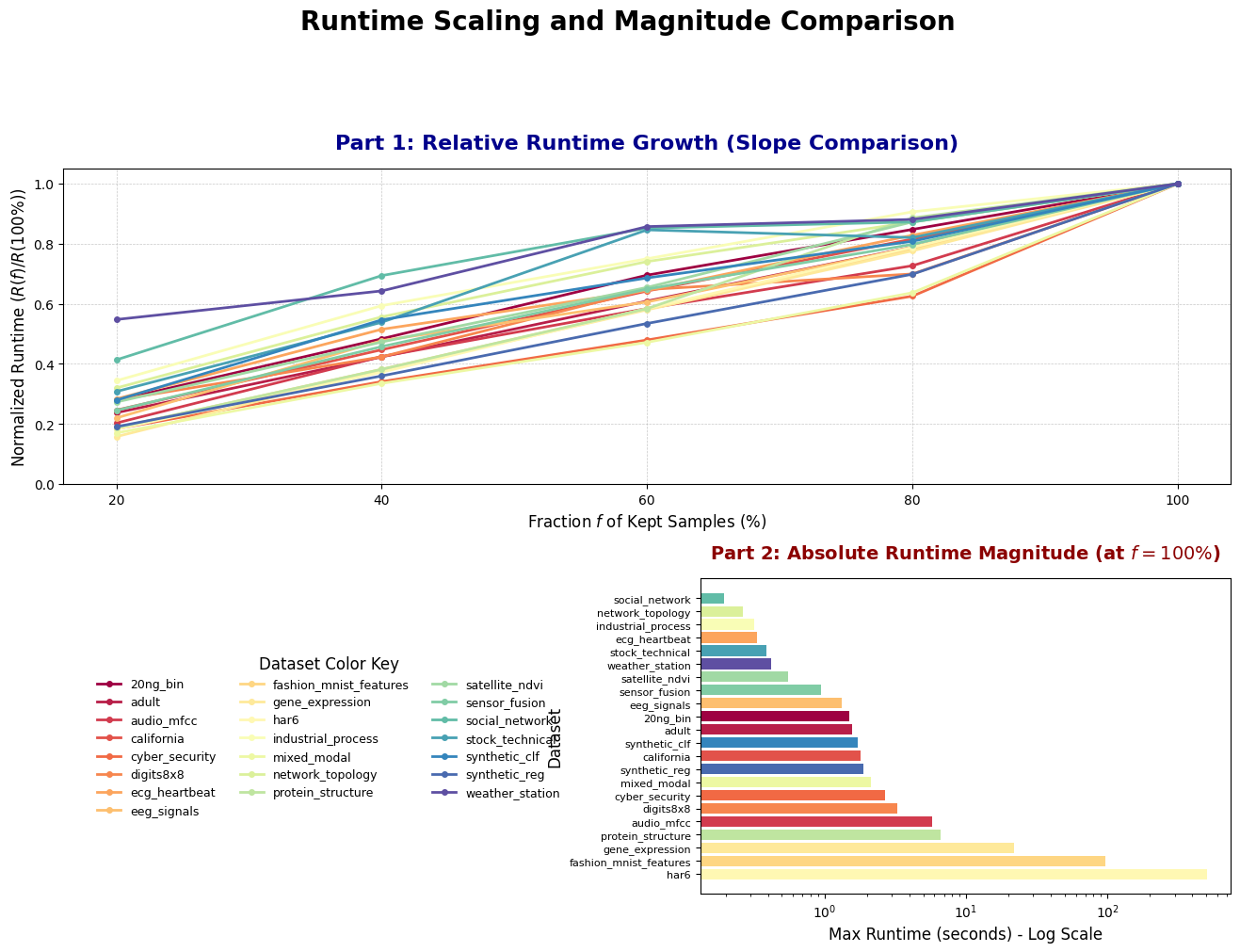
- Fast and efficient: ExCIR runs in a single pass over the data and avoids repeatedly calling the model, so it’s much quicker than many popular explainer methods.
- Works with less data: Using only 20–40% of the rows often gives almost the same top feature rankings as using all the data, with around 3–9× speed-ups.
- Stable with similar features: BlockCIR handles groups of similar or correlated features, reducing double-counting and producing smoother, more trustworthy rankings.
- Broad agreement: ExCIR’s rankings match well with well-known explainers (like SHAP) across many datasets, but at a much lower computational cost.
- Class-specific explanations: For multi-class problems (like classifying digits), it can explain which features matter for each specific class.
- Important cautions: ExCIR measures association (what tends to move together), not cause-and-effect. It may be less accurate when relationships are very nonlinear or when confounding is present (hidden factors that influence both a feature and the outcome).
These findings matter because they make explanations more practical in real-world settings where time, cost, and privacy are important—like hospitals, phones, cars, and IoT devices.
What is the potential impact?
- Practical transparency: Organizations can provide understandable feature rankings quickly, helping with trust, safety, and audits.
- Scales to big/fast data: Because it’s efficient and can work on samples, ExCIR fits well on edge devices and streaming systems.
- Fairer credit in correlated data: Group scoring (BlockCIR) prevents misleading double-counting when features are redundant.
- Easy to combine: Teams can pair ExCIR (fast, consistent, model-agnostic) with a slower, model-specific method when maximum “faithfulness” to a particular model is required.
In short, ExCIR and BlockCIR offer a simple, fast, and stable way to see which features matter most, even when features are correlated and when you can only use part of the data. It’s a practical step toward explainable, trustworthy AI in everyday applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be concrete and actionable for follow-up research.
- Theory: No finite-sample guarantees for ExCIR and the lightweight protocol (e.g., concentration bounds, sample complexity, or confidence intervals for CIR under subsampling). Derive statistical error bars for and top-k stability as a function of , , and .
- Near-zero mass behavior: No regularization for cases where (ratio instability). Develop shrinkage, Bayesian priors, or conservative intervals for small-evidence regimes beyond the current rule.
- Nonlinear relationships: ExCIR is linear-in-covariation and fails on strongly nonlinear (e.g., U-shaped, XOR) dependencies. Explore kernelized, rank-based, or monotone-transform variants that capture nonlinear co-movement while retaining single-pass efficiency.
- Feature interactions: BlockCIR aggregates features but does not quantify interaction effects (e.g., pairwise or higher-order synergy). Design interaction-aware CIR (e.g., cross-feature products or conditional scores) that remains computationally tractable.
- Direction vs magnitude: CIR conflates importance with directionality (anti-aligned features score low, even if strongly predictive). Provide a decoupled magnitude score (e.g., |alignment| with separate sign reporting) and study its impact on rankings.
- Group-size bias: BlockCIR sums over members; larger groups may accumulate more mass and receive inflated scores. Introduce group-size normalization, per-feature weights, or cardinality-adjusted aggregation; analyze sensitivity to |G|.
- Overlapping/uncertain groupings: No principled handling of overlapping groups or uncertainty in group assignment (correlation clusters are not unique). Develop overlap-aware credit allocation (e.g., Shapley-in-groups) and robust group discovery with stability guarantees.
- Per-feature scaling within groups: Group-level invariance to per-feature rescaling is not guaranteed; heterogeneous scales can implicitly reweight members. Investigate normalization schemes (e.g., per-feature standardization/whitening within groups) and quantify effects.
- Automatic grouping protocol: Group construction is left to domain heuristics; there is no algorithmic recipe or sensitivity analysis (thresholds, linkage, cluster stability). Provide end-to-end, data-driven grouping with hyperparameter selection and robustness diagnostics.
- Causal robustness: The paper acknowledges confounding and the non-causal nature of CIR but offers no correction. Explore causal variants (e.g., invariant risk minimization, instrumental variables) or sensitivity analyses to distinguish spurious vs stable associations.
- Covariate shift and drift: Lightweight transfer is demonstrated but not validated under distribution shift or temporal drift. Formalize stratified/importance sampling, sliding windows, and drift detection; measure ranking stability across shifts.
- Calibration dependence (classification): Guidance to use logits is qualitative; no quantitative study of how calibration (temperature scaling, Platt) affects CIR rankings across classes. Benchmark calibration strategies and propose calibration-robust scoring.
- Multi-label and hierarchical outputs: Class-conditioned ExCIR targets single multiclass logits; extensions to multi-label, hierarchical, or structured outputs are unaddressed. Define aggregation across labels and conflict resolution under label coupling.
- Local explanations: Although sample-level primitives exist (, ), the paper does not provide an instance-level explanation protocol or visualization. Develop per-instance CIR contributions, local maps, and instance-to-global consistency checks.
- Faithfulness metrics: Evaluation omits perturbation/insertion-deletion (e.g., AOPC, ROAR) and sufficiency/infidelity analyses beyond top-k overlap. Add standard faithfulness tests to quantify how CIR relates to model behavior under controlled removals.
- Deep architectures: Experiments focus on LR and XGBoost; generalization to modern deep models (CNNs, Transformers) and complex outputs is not assessed. Test scalability, agreement, and runtime on deep backbones and large-scale image/text tasks.
- Extreme sparsity: Behavior on ultra-sparse inputs (e.g., BoW with many zeros) is not analyzed; absolute product-based mass may under-credit informative rare features. Investigate sparsity-aware variants (e.g., nonzero-only accumulation, rare-token weighting).
- Missing data: No strategy for missing values (MAR/MNAR) in or ; products and centering may be biased. Provide missingness handling (imputation, partial contributions, pairwise deletion) and quantify its impact on CIR.
- Quantile approximation error: Streaming mid-mean relies on GK/t-digest; the effect of quantile approximation error on rankings is not quantified. Derive error propagation bounds and practical guidelines for sketch precision vs runtime/memory.
- Weighted variant guidance: Weighted CIR is defined but lacks a principled scheme for choosing (e.g., class imbalance, reliability, cost). Provide methodologies for weight learning/tuning and study their influence on rankings.
- BlockCIR scalability: Computing and for many (possibly overlapping) groups can be costly. Develop efficient data structures (e.g., sparse indices, incremental accumulators) and analyze complexity with large |𝔾|.
- Score uncertainty reporting: No uncertainty quantification is provided for the final rankings (e.g., bootstraps, Bayesian posteriors). Add uncertainty bands and stability summaries to avoid overinterpretation of close scores.
- Privacy and security: Claims of deployment friendliness are not paired with privacy guarantees (e.g., DP) or attack analyses (membership/model inversion via explanations). Evaluate privacy leakage and propose DP-compatible CIR variants.
- Fairness: No assessment of group fairness (e.g., whether rankings differ across protected subpopulations). Add subgroup analyses, fairness constraints, and bias mitigation for ExCIR/BlockCIR.
- Multi-output regression: Extension to vector-valued regression targets is not specified. Define CIR for multi-target settings (per-target vs aggregated) and study trade-offs.
- Image/vision grouping: Pixel/patch/channel groupings are mentioned but not systematically compared (e.g., superpixels vs patches). Provide empirical guidance for grouping strategies and their effect on stability/localization.
- Reproducibility details: Some notation/LaTeX issues and dataset references suggest potential reproducibility friction (e.g., inconsistent symbols, incomplete figures/tables). Publish complete, versioned artifacts (scripts, seeds, splits, data hashes) and resolve documentation gaps.
- Protocol confounding: Lightweight experiments may conflate retraining effects with explanation subsampling. Separate “explanation-only subsampling” (fixed model) from “full retrain” effects, and quantify their distinct impacts on agreement.
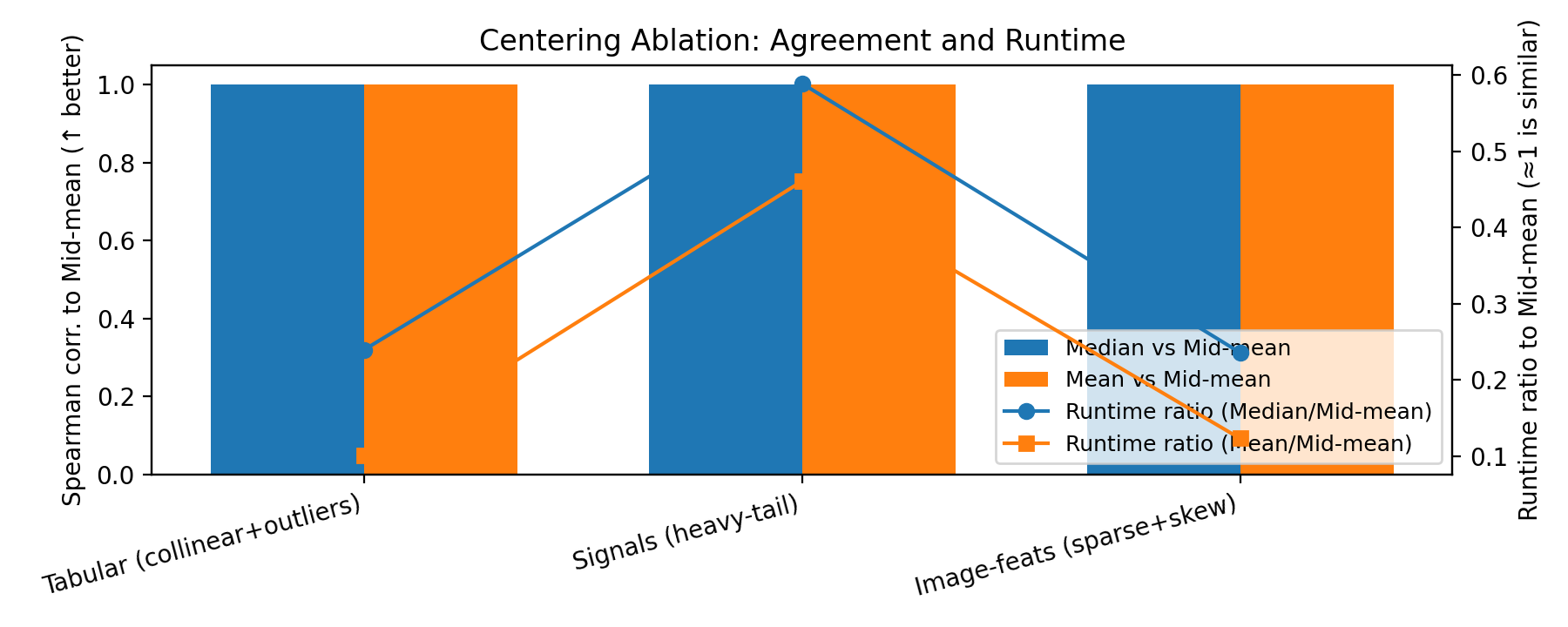
- Robust centering choice: Only a brief ablation on mid-mean vs median vs mean is provided; no adaptive criterion. Investigate data-adaptive centering (e.g., Huber location, skew-aware midhinge) and when each is preferable.
These items identify where theory, methodology, evaluation, and deployment practices could be strengthened to make ExCIR/BlockCIR more robust, general, and practically reliable.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, leveraging ExCIR’s single-pass, correlation-aware attribution (ExCIR) and groupwise extension (BlockCIR), plus its lightweight transfer protocol for faster explanations.
- Feature ranking and deduplication for model debugging and feature store hygiene (software/MLOps)
- Workflow: Run ExCIR to identify top contributors; use BlockCIR to merge near-duplicate or collinear features (e.g., highly correlated engineered features) and prune redundant inputs.
- Tools/products: “Correlation-Aware Feature Store” plugin for scikit-learn/XGBoost pipelines; CI job to flag redundant features.
- Assumptions/dependencies: Access to model predictions; reasonable stationarity of correlations; group definitions via domain knowledge or quick clustering.
- Low-latency explainability at the edge (IoT/embedded/robotics)
- Workflow: Compute mid-mean centering via streaming quantiles (t-digest/GK), then single-pass ExCIR on-device to provide global feature importance for safety monitors or resource-constrained controllers.
- Tools/products: Edge-XAI microservice; firmware module exposing “top-k features” for diagnostics.
- Assumptions/dependencies: On-device access to predictions; approximate quantiles are sufficient; global (not per-instance) explanations are acceptable in the use case.
- Sensor fusion diagnostics with block-level stability (energy/industrial monitoring)
- Workflow: Define sensor groups (by physical proximity, channel type, or correlation clusters); use BlockCIR to score groups for stability and to avoid double-counting; triage failing sensors or prioritize maintenance.
- Tools/products: “BlockCIR Dashboard” for fleet monitoring with group-level alerts.
- Assumptions/dependencies: Sensor grouping available or derivable; feature-output co-movement reflects operational states; global importance is meaningful for monitoring.
- Model governance and audit-ready global explanations (finance/insurance/compliance)
- Workflow: Generate global feature rankings that are shift/positive-scale invariant and deterministic; attach explainability reports to model versioning for auditors (e.g., EU AI Act, model risk management).
- Tools/products: “Explainability Report Generator” integrating ExCIR outputs, top-k Jaccard stability checks, and Procrustes alignment metrics.
- Assumptions/dependencies: Regulators accept global rankings as part of explainability artifacts; calibrated scores/logits available for class-conditioned runs.
- Healthcare triage and EHR feature transparency (healthcare)
- Workflow: Use class-conditioned ExCIR with logits to produce per-condition feature rankings; group codes (ICD, lab panels) via BlockCIR to avoid double-credit across synonyms/redundant entries.
- Tools/products: Clinical decision support dashboards rendering class-conditioned top-k features and group-specific importance.
- Assumptions/dependencies: Availability of robust feature groupings (codes/panels); interpretability policies; correlation-as-dependence (not causality) understood by clinicians.
- Lightweight cost-slashing explainability for batch scoring (software/MLOps)
- Workflow: Use the lightweight transfer protocol at f≈20–40% of rows to reproduce full-model rankings; set SLOs for runtime vs agreement (e.g., Jaccard@k≥τ).
- Tools/products: “Explainability Budgeter” that selects f on the Pareto frontier; integration with job schedulers.
- Assumptions/dependencies: Agreement thresholds defined; retraining variance controlled (fixed seed/splits); full data not always necessary for stable global rankings.
- NLP synonym/feature grouping to reduce attribution noise (software/NLP)
- Workflow: Map tokens to synonym/phrase groups; compute BlockCIR for cleaner topic/intent attribution; improve interpretability for compliance summaries.
- Tools/products: Token-group builder (word embeddings/thesauri) + BlockCIR.
- Assumptions/dependencies: Quality of grouping (domain lexicons/embeddings); logits preferred over softmax probabilities to avoid simplex coupling.
- Post-deployment drift and dependency shift monitoring (MLOps)
- Workflow: Periodically recompute ExCIR; track changes in aligned co-movement and rank overlap to detect evolving dependencies or drift.
- Tools/products: Drift monitor with rank-correlation and symmetric-KL alerts.
- Assumptions/dependencies: Stable training-validation environment; sufficient samples to estimate quantiles; thresholds for action defined.
- Classroom and lab demonstrations of model interpretability (education/academia)
- Workflow: Use ExCIR as a fast, deterministic explainer for student projects; demonstrate correlation-aware grouping and the impact of outliers/centering choices.
- Tools/products: Teaching notebooks with ExCIR and BlockCIR examples across modalities.
- Assumptions/dependencies: Availability of model outputs; students informed that ExCIR measures dependence, not causality.
- Privacy-conscious explainability in restricted data settings (policy/industry)
- Workflow: Apply ExCIR to a fraction of rows under privacy budgets; avoid repeated model queries and perturbation-based methods; report agreement metrics.
- Tools/products: Privacy-aware explainability pipeline minimizing data access and compute.
- Assumptions/dependencies: Policy permits aggregate reliance on correlations; subsampling adheres to privacy constraints.
Long-Term Applications
The following use cases require further research, scaling, or ecosystem development to fully realize their benefits.
- Training-time regularization via correlation-aware attribution (software/ML research)
- Idea: Integrate ExCIR/BlockCIR into training to penalize over-reliance on redundant features or encourage group-level sparsity.
- Potential product: “CIR-Regularized Learners” as scikit-learn/XGBoost extensions.
- Assumptions/dependencies: Differentiable surrogates or alternating optimization; careful handling of nonlinearity; empirical validation across models.
- AutoML with group-aware feature engineering (software/AutoML)
- Idea: Use BlockCIR to automatically detect feature groups, prune duplicates, and prioritize salient blocks during search.
- Potential product: “AutoML-CIR” that co-optimizes model quality and explainability.
- Assumptions/dependencies: Robust group discovery at scale; evaluation pipelines that include agreement metrics; integration with diverse model families.
- Real-time safety explainability for autonomous systems (robotics/automotive)
- Idea: Deploy class-conditioned ExCIR on sensor fusion stacks; generate interpretable global importance across sensor groups; build safety policies that react to shifts in aligned co-movement.
- Potential product: Safety explainability engine for ADAS/AVs.
- Assumptions/dependencies: Hard real-time guarantees; certified implementations; validation against safety cases and standards.
- Causal-aware extensions combining ExCIR with causal graphs (academia/industry)
- Idea: Augment correlation-based attribution with causal structure (DAGs/IVs) to differentiate association from causation; use ExCIR as a robust dependence prior.
- Potential product: “CIR+Causal” toolkit merging dependency and causal attribution.
- Assumptions/dependencies: Availability of causal knowledge or identifiable instruments; new theory and empirical studies.
- Sector-specific explainability standards and benchmarks (policy/consortia)
- Idea: Standardize correlation-aware global explanations for regulatory reporting (finance, healthcare) with agreed-upon metrics (Jaccard@k, rank correlations, shape alignment).
- Potential product: Open standard/spec for correlation-aware XAI; certifiable explainability profiles.
- Assumptions/dependencies: Multi-stakeholder alignment; governance frameworks; alignment with GDPR/EU AI Act.
- Adaptive data acquisition and sensor placement using BlockCIR (energy/industrial IoT)
- Idea: Use group-level importance to optimize sensor layouts, sampling rates, and redundancy strategies.
- Potential product: “CIR-Driven Sensor Planner” for industrial sites or grids.
- Assumptions/dependencies: Longitudinal data; integration with operations; evaluation against reliability/cost constraints.
- Model interoperability and cross-calibration explainability (software/platforms)
- Idea: Use ExCIR’s shift/positive-scale invariance to compare feature reliance across models or calibrations; unify explanations in multi-model ensembles.
- Potential product: Cross-model explainability hub with alignment diagnostics.
- Assumptions/dependencies: Consistent centering and score choices (logits/margins); ensemble-level agreement measures.
- Hybrid local–global XAI systems (software/ML research)
- Idea: Combine fast ExCIR global summaries with selective local explanations (e.g., Integrate Gradients or SHAP on a small subset) to get comprehensive coverage at reasonable cost.
- Potential product: “Tiered XAI” orchestrator that budgets local explainability around ExCIR’s global map.
- Assumptions/dependencies: Strategy for selecting instances; workflow tooling; user studies on combined interpretability.
- Curriculum learning and data curation guided by ExCIR (academia/ML)
- Idea: Use aligned co-movement mass to identify informative samples/features and design curricula or curation strategies for efficient training.
- Potential product: “CIR-Curriculum” module for data selection and training schedules.
- Assumptions/dependencies: Stable correlation patterns; transferability across tasks; careful analysis of bias and fairness.
- Explainability-aware feature marketplaces (software/data economy)
- Idea: Score third-party features via ExCIR/BlockCIR to quantify contribution and redundancy before purchase or integration.
- Potential product: Marketplace vetting tool with correlation-aware importance and overlap checks.
- Assumptions/dependencies: Access to sandbox predictions; agreements on evaluation metrics; legal frameworks for data trials.
Notes on feasibility:
- ExCIR provides global, correlation-aware dependence—not causal attributions. In highly non-linear or confounded settings, complementary methods or causal tools are recommended.
- Class-conditioned runs should prefer logits or calibrated scores to avoid probability simplex coupling.
- Group definitions are critical for BlockCIR; domain knowledge or robust clustering greatly improves outcomes.
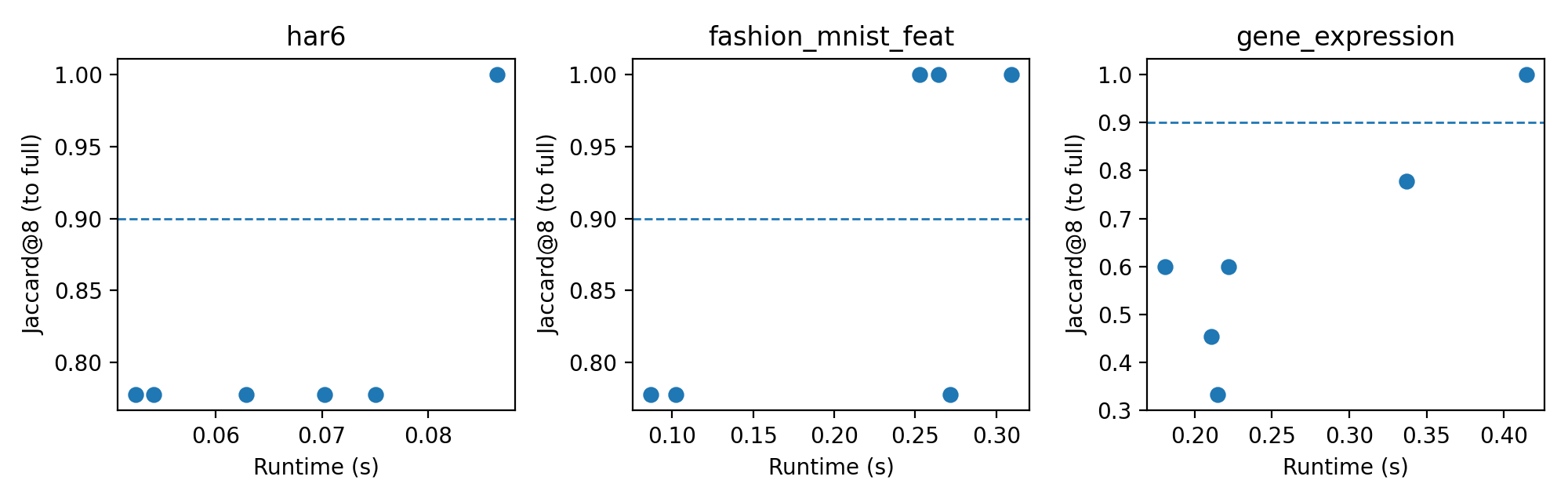
- Lightweight transfer assumes similar training/validation environments and stable correlation structures; agreement thresholds (e.g., Jaccard@k) should be set per context.
Glossary
- AOPC: A perturbation-based metric (Area Over the Perturbation Curve) used to assess explanation fidelity. "We omit perturbation-based metrics (e.g., AOPC) and focus on agreement, shape alignment, and distributional match"
- Affine-alignment residual: A measure of geometric discrepancy after optimal affine alignment (often via Procrustes) between two score vectors. "High Jaccard@8 typically co-occurs with a small affine-alignment residual: remaining differences are largely explained by a global scale/shift of scores."
- BlockCIR: A groupwise extension of ExCIR that scores sets of correlated features as a single unit to avoid double-counting. "We further introduce BlockCIR, a groupwise extension of ExCIR that scores sets of correlated features as a single unit."
- Calibration-invariant: Property that feature scores remain stable under changes to model score calibration (shift/scale). "We target global feature ranking that is calibration-invariant and efficient at large datasets without model re-evaluation"
- Correlation–Impact Ratio (CIR): A normalized measure of sign-aligned co-movement between features (or groups) and model output after robust centering. "For any nonempty , define the CorrelationâImpact Ratio (CIR):"
- Covariate shift: A distributional change in input features between training and deployment that can invalidate background assumptions. "trade faithfulness for compute budgets and rely on background-distribution assumptions that may be invalid under covariate shift."
- Greenwald–Khanna: A streaming quantile sketch algorithm for approximating quantiles in one pass with small memory. "it requires only streaming-friendly quantile estimates that can be updated in one pass with small memory footprints (e.g., GreenwaldâKhanna and t-digest)"
- Hilbert–Schmidt Independence Criterion (HSIC): A kernel-based dependence measure for assessing statistical independence between random variables. "Global dependence measures such as the HilbertâSchmidt Independence Criterion (HSIC)~\cite{gretton2005hsic}"
- Integrated Gradients: A path-integral based attribution method that accumulates gradients from a baseline to the input. "Gradient-based saliency maps~\cite{simonyan2013saliency} and Integrated Gradients~\cite{sundararajan2017integratedgradients}"
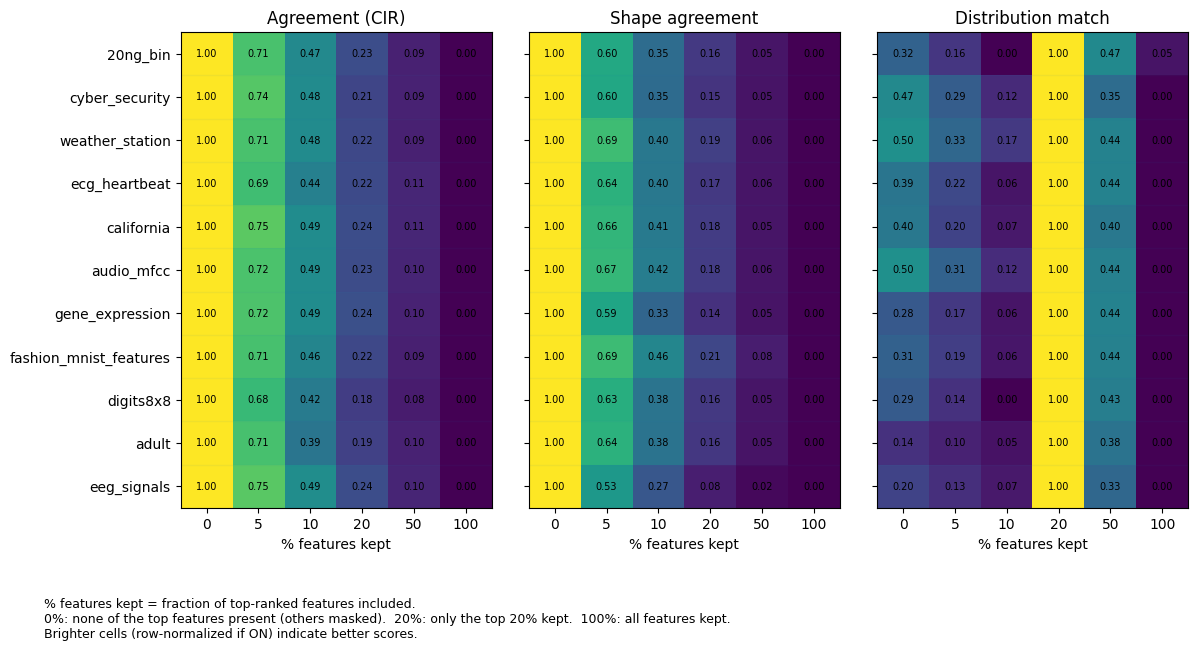
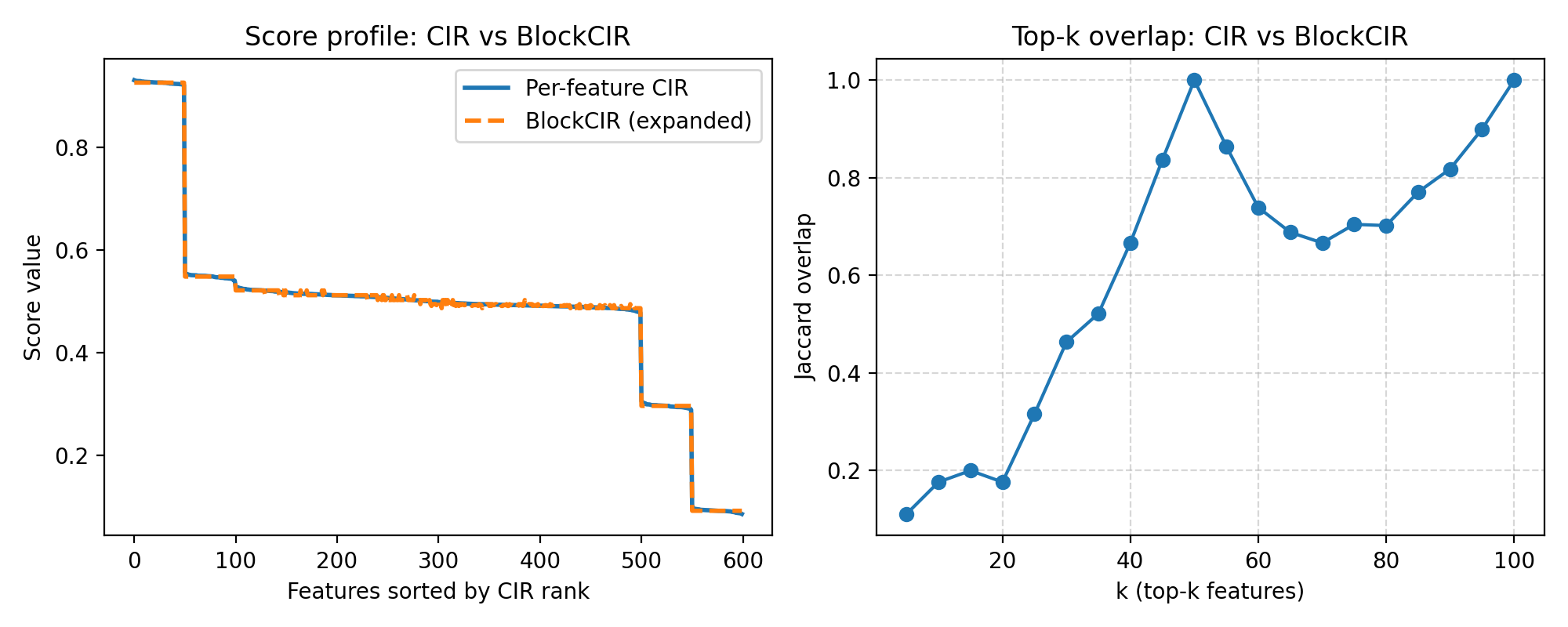
- Jaccard overlap: Set similarity metric for comparing top-k feature sets via intersection over union. "This controlled subsampling achieves multi-fold speed-ups with minimal loss of agreement, quantified non-perturbatively via top- Jaccard overlap"
- Kernel density estimation (KDE): A non-parametric method to estimate a probability density function from samples. "distributional match (symmetric-KL of 1D KDEs)"
- Kendall’s τ: A rank correlation coefficient measuring ordinal association between two rankings. "Notably, even with only 10â20\% of the data, it achieved a Kendallâ of 0.51 and 0.47 when compared to the full-data attribution vector"
- LIME: A local surrogate-based explainer that fits simple models to perturbed samples around an instance. "Popular perturbation- or sampling-based methods such as LIME~\cite{ribeiro2016lime}, SHAP~\cite{lundberg2017shap}"
- Logit: The raw (pre-softmax) score output for a class in multinomial logistic models. "Per-class logit or calibrated score"
- Logistic regression (OvR, L2): Multinomial classification via one-vs-rest scheme with L2 regularization. "Text (TFâIDF) & Logistic regression (OvR, L2) & Per-class logit or calibrated score"
- Mid-mean: A robust location estimate equal to the average of the 25th and 75th percentiles (trimmed central mean). " & Mid-mean operator (trimmed mean of central 50\%)"
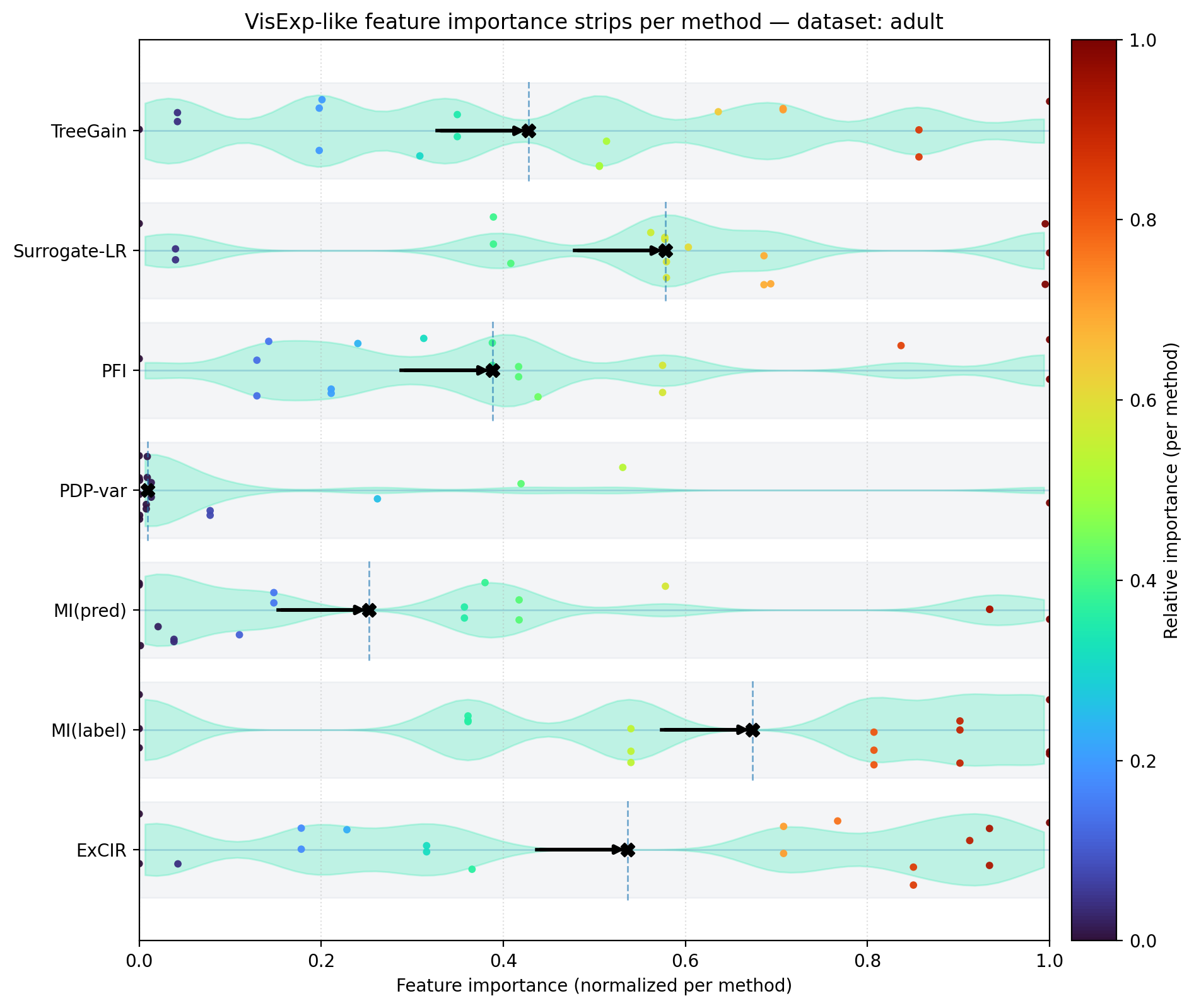
- Mutual information: An information-theoretic measure of dependence between variables (feature and label/prediction). "mutual information with labels or predictions~\cite{ross2014mi}"
- NDVI: Normalized Difference Vegetation Index, a remote sensing feature capturing vegetation health. "Remote sensing (derived) & satellite_ndvi & NDVI-based features aggregated over time/tiles; regression/classification variants for vegetation dynamics \cite{excirdemo2025}."
- Orthogonal Procrustes residual: The residual error after optimal orthogonal alignment between two vectors or matrices. "shape alignment (orthogonal Procrustes residual)~\cite{schonemann1966procrustes}"
- OvR (one-vs-rest): A strategy for multi-class classification by training one binary classifier per class versus all others. "Logistic regression (OvR, L2)"
- Pareto frontier: The trade-off curve showing optimal balances between competing objectives (e.g., runtime vs. agreement). "This protocol exposes a favorable runtimeâagreement Pareto frontier: operating at typically preserves high top- overlap"
- Partial Dependence Plot (PDP-variance): A global explanation that measures variance of model output under marginalizing other features; used here as a global importance baseline. "PDP-variance~\cite{friedman2001pdp}"
- Pearson correlation: A standardized covariance measure of linear correlation between two variables. "This centered product is the standard primitive underlying covariance and Pearson correlation~\cite{wasserman2004}."
- Permutation Feature Importance (PFI): A model-based global importance metric computed by measuring performance drop after permuting a feature. "permutation feature importance (PFI)~\cite{breiman2001randomforest}"
- Platt calibration: A method to calibrate classifier outputs via logistic regression on scores. "For class-conditioned runs we feed logits (or temperature/Platt-calibrated scores) into "
- Probability simplex coupling: The dependence between class probabilities due to their normalization to sum to one, affecting attributions. "work directly on softmax probabilities, where the simplex coupling makes attributions sensitive to calibration and to the presence/absence of competing labels (label-set dependence)."
- Robust centering: Centering features and outputs using robust statistics (e.g., mid-mean) to reduce outlier influence. "ExCIR quantifies sign-aligned co-movement between features and model outputs after robust centering"
- Saliency maps: Gradient-based visualizations highlighting input regions that most affect model output. "Gradient-based saliency maps~\cite{simonyan2013saliency}"
- SHAP: Shapley-value-based explainer estimating feature contributions via coalitional game theory. "Popular perturbation- or sampling-based methods such as LIME~\cite{ribeiro2016lime}, SHAP~\cite{lundberg2017shap}"
- Sign-aligned co-movement: The tendency of a feature and model output to move in the same direction after centering. "ExCIR quantifies sign-aligned co-movement between features and model outputs after robust centering"
- Spearman’s ρ: A rank correlation coefficient based on monotonic relationships between two rankings. "Ground-truth recovery experiments indicated moderate correlations with true importance (Kendallâ, Spearman )"
- Stochastic Block Model (SBM): A generative model for community-structured graphs used in network benchmarks. "Networks (synthetic) & sbm_communities & Stochastic block model graphs with community labels; node/graph classification under controlled correlation \cite{excirdemo2025}."
- Symmetric KL: The symmetric Kullback–Leibler divergence (Jeffreys) used to compare score distributions. "distributional similarity (symmetric KL)~\cite{jeffreys1946}"
- t-digest: A streaming algorithm for accurate quantile estimation, especially for extreme percentiles. "it requires only streaming-friendly quantile estimates that can be updated in one pass with small memory footprints (e.g., GreenwaldâKhanna and t-digest)"
- Temperature scaling: A post-hoc calibration method that rescales logits to improve probability calibration. "Marginal calibration differences (1D-KDE symmetric-KL) are small and, where needed, close with temperature scaling."
- TreeGain: Model-intrinsic importance metric based on gain (split improvement) in tree ensembles (e.g., XGBoost). "model-intrinsic statistics such as TreeGain~\cite{chen2016xgboost}"
- Tukey’s mid-mean (midhinge): A robust center defined as the average of the first and third quartiles. "Using a robust midhinge (Tukeyâs mid-mean) dampens the impact of outliers and heavy tails"
- Whitening: A preprocessing step that decorrelates and scales features to have unit variance, affecting attribution behavior. "Whitening the feature space lowered the sufficiency score to 0.32"
- XGBoost: A gradient-boosted tree library used as a backbone for tabular, time-series, and remote-sensing tasks. "Tabular & Gradient-boosted trees (XGBoost) & Raw margin (clf.) or prediction (reg.)"
Collections
Sign up for free to add this paper to one or more collections.