NaTex: Seamless Texture Generation as Latent Color Diffusion
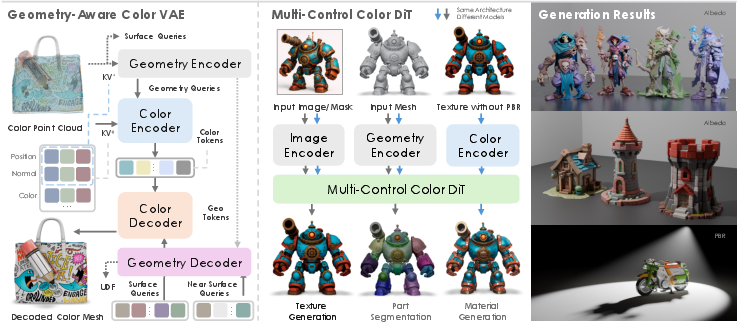
Abstract: We present NaTex, a native texture generation framework that predicts texture color directly in 3D space. In contrast to previous approaches that rely on baking 2D multi-view images synthesized by geometry-conditioned Multi-View Diffusion models (MVDs), NaTex avoids several inherent limitations of the MVD pipeline. These include difficulties in handling occluded regions that require inpainting, achieving precise mesh-texture alignment along boundaries, and maintaining cross-view consistency and coherence in both content and color intensity. NaTex features a novel paradigm that addresses the aforementioned issues by viewing texture as a dense color point cloud. Driven by this idea, we propose latent color diffusion, which comprises a geometry-awared color point cloud VAE and a multi-control diffusion transformer (DiT), entirely trained from scratch using 3D data, for texture reconstruction and generation. To enable precise alignment, we introduce native geometry control that conditions the DiT on direct 3D spatial information via positional embeddings and geometry latents. We co-design the VAE-DiT architecture, where the geometry latents are extracted via a dedicated geometry branch tightly coupled with the color VAE, providing fine-grained surface guidance that maintains strong correspondence with the texture. With these designs, NaTex demonstrates strong performance, significantly outperforming previous methods in texture coherence and alignment. Moreover, NaTex also exhibits strong generalization capabilities, either training-free or with simple tuning, for various downstream applications, e.g., material generation, texture refinement, and part segmentation and texturing.











Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces NaTex, a new way for computers to “paint” 3D objects. Instead of painting on flat pictures and then wrapping them around a 3D model, NaTex paints directly on the 3D surface itself. This helps avoid common problems like gaps in hidden areas, mismatched edges, and colors that don’t line up across different views.
What questions are the researchers trying to answer?
The authors focus on a simple idea: if textures belong on 3D objects, why not generate them directly in 3D? They ask:
- Can we create textures directly on a 3D surface instead of using many 2D images?
- Can we keep details neatly aligned with the shape (like stripes exactly following edges)?
- Can we avoid messy fixes for hidden parts that cameras can’t see?
- Can one system work for many tasks, like creating materials, improving existing textures, and coloring only certain parts?
How does NaTex work? (In everyday terms)
Think of a 3D model like a statue. “Texturing” is painting it so it looks real. Many older methods:
- Take lots of pictures of the statue from different angles
- Paint on those pictures
- “Bake” (wrap) the pictures back onto the statue
That process can leave blank spots (hidden areas), misaligned edges, and color mismatches.
NaTex does it differently:
- Texture as a “color point cloud” Imagine covering the object’s surface with tiny dots. Each dot knows where it is in 3D and what color it should be. That’s a color point cloud—basically a 3D painting made of many colored points.
- A smart compressor/decompressor (VAE)
- “Geometry-aware” means the VAE doesn’t just look at colors—it also pays attention to the shape (positions and surface directions) so colors stick precisely to the right places.
- The VAE has two branches that work together: one learns about the shape, the other learns about the colors. The shape branch guides the color branch, so textures follow bumps, edges, and boundaries correctly.
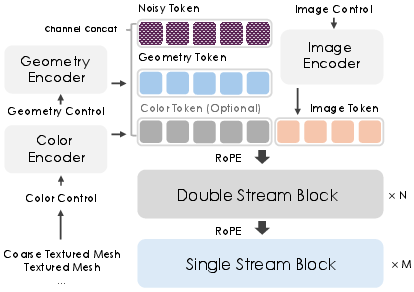
- A guided painter (Diffusion Transformer)
- Image control: a reference image (like a product photo)
- Geometry control: the 3D shape and each point’s location, so paint stays aligned
- Color control (optional): a rough or old texture as a starting point for refining or inpainting
- The model mixes these controls so it paints consistently across the whole object, even in areas a camera can’t see.
- Flexible outputs The result can be exported however you need: as a regular texture image (UV map) or as colors attached to the object’s points/faces/vertices.
What did they find, and why does it matter?
Main results:
- Cleaner, better-aligned textures NaTex beats previous methods on standard quality scores. Visually, stripes meet edges correctly, patterns don’t drift across seams, and fine details line up with the shape.
- No more “guessing” for hidden areas Because NaTex paints in 3D, it naturally fills in spots that a camera wouldn’t see—no extra inpainting step needed.
- More consistent colors across the whole object Since there’s one unified 3D “canvas,” colors and patterns stay coherent everywhere.
- Fast and scalable Despite using a powerful model, NaTex often needs only a few steps to produce results. It can even work in a single step in some cases because the geometry and image guidance are so strong.
- Works beyond basic texturing
- Generate materials (like roughness and metalness maps) by treating them like extra color channels
- Refine existing textures (fixing errors and filling gaps)
- Do part-based tasks, like coloring only the wheels of a car or segmenting parts from a simple 2D mask
Why it’s important:
- Artists and game developers spend tons of time making clean textures. NaTex can speed up that process and reduce tricky manual fixes.
- Fewer artifacts and better alignment mean more realistic results for games, films, AR/VR, and digital product design.
What’s the impact, and what’s next?
NaTex shows that painting directly in 3D is a strong and practical way to create textures. It simplifies pipelines (fewer steps and fewer errors), helps maintain detail, and adapts to many tasks without retraining from scratch.
The authors also note areas to improve:
- Even higher-resolution reconstructions from the compressor (VAE)
- Better training data for material properties
- Finer, more reliable part segmentation on very complex shapes
- Handling tricky cases where parts are tightly packed or surfaces overlap
Overall, NaTex could make 3D asset creation faster, cleaner, and more accessible—helping anyone from indie creators to large studios produce high-quality textured models with less hassle.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Dataset transparency and generalization: The paper does not specify the size, diversity, provenance, or licensing of the 3D textured asset dataset used to train NaTex. It is unclear how well the model generalizes to real-world photos, scanned meshes, or out-of-domain categories beyond the synthetic, rendered training regime.
- Physical correctness of materials: Material generation is limited to albedo, roughness, and metallic maps (with roughness/metallic encoded as two color channels). There is no modeling or evaluation of normal/bump/displacement/AO/emissive maps, anisotropic or layered BRDFs, or physical validation against measured materials.
- Illumination invariance: The illumination-invariant loss is introduced with a fixed weight and without ablation or theoretical analysis; there is no evaluation of how well albedo is disentangled from illumination under unknown lighting, nor how robust the method is in presence of strong specular highlights or shadows.
- Alignment metrics: Claims of superior texture–geometry alignment are supported mainly by visual comparisons. There is no quantitative metric or benchmark for boundary alignment, seam continuity, or feature locking to surface details (e.g., edge alignment error in UV or 3D space).
- Occlusion handling and inpainting evaluation: The “occlusion-free” claim is not accompanied by a rigorous evaluation. Comparisons are made against simple OpenCV-based inpainting rather than state-of-the-art 2D/3D inpainting or multi-view consistency methods, leaving open how NaTex performs against stronger baselines.
- Handling non-watertight or complex geometry: The training uses a truncated UDF due to non-trivial mesh correlation, but it remains unclear how the method behaves with highly non-watertight meshes, self-intersections, thin structures, or complex topology where normals and near-surface offsets are unreliable.
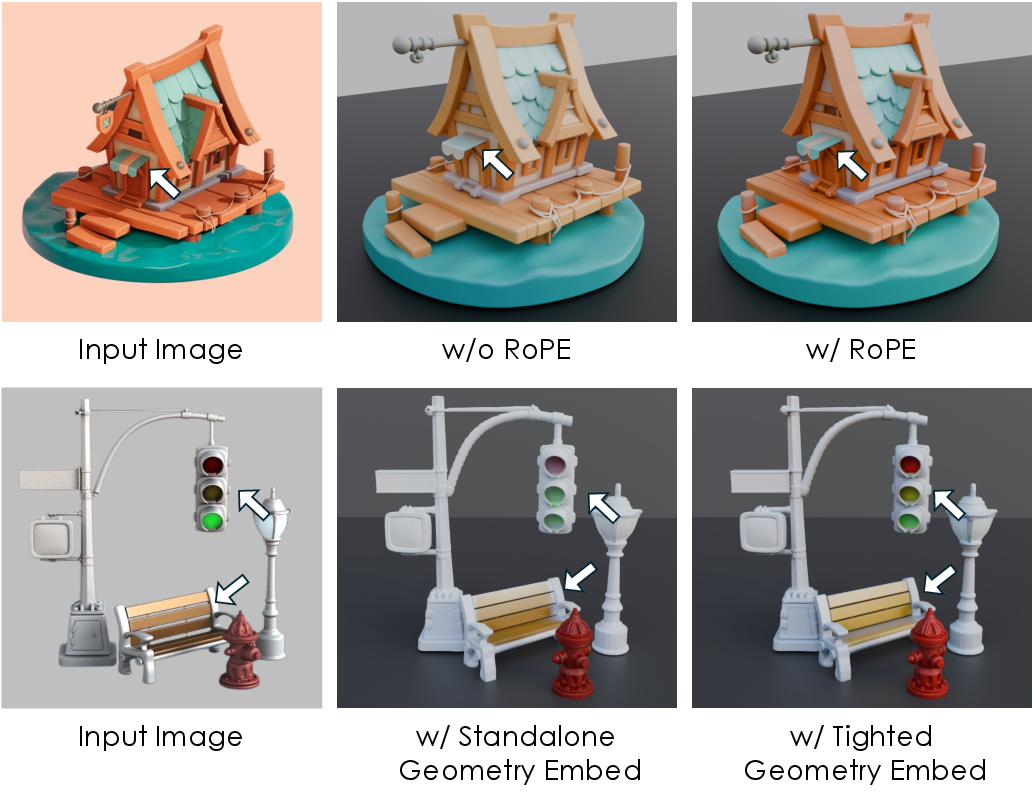
- Positional encoding design: NaTex uses RoPE on 3D positions; there is no analysis of rotational/scale invariance, canonicalization of coordinate frames, or how mesh scale/orientation affects conditioning and generated textures.
- Geometry latent integration: Geometry latents are concatenated channel-wise with texture latents, but alternative integration schemes (cross-attention, gating, modulation, or residual conditioning) are not explored or ablated to determine optimal coupling strength and granularity.
- Token length scaling and capacity: The model is trained with up to 6144 tokens but inferred with much larger token lengths (e.g., 24,576). There is no systematic study of memory/computation scaling, diminishing returns, or failure modes at high token counts, nor guidance on optimal tokenization with respect to mesh resolution/UV density.
- One-step generation: The paper notes “one-step generation” without distillation due to strong conditioning, but provides no quantitative assessment of quality vs. speed trade-offs, failure cases, or stability under varied inputs and controls.
- Color VAE reconstruction ceiling: The VAE reconstruction quality—while improved with larger latents—still limits very high-resolution textures. There is no exploration of alternative autoencoding architectures (e.g., octree sparsity, multires patches, hybrid 2D–3D VQ) or learned importance sampling to push resolution and detail.
- Robustness to mesh normals and sampling strategy: Near-surface color supervision relies on offsets along mesh normals; the sensitivity to noisy normals, sharp features, curvature extremes, and sampling density is not analyzed. A systematic study of sampling strategies (uniform vs. curvature-aware) is missing.
- UV map generation and seam handling: While NaTex can output UV textures by querying UV-mapped 3D positions, there is no evaluation of seam continuity, UV distortion, overlapping shells, or duplicate vertices—common practical issues in production pipelines.
- Real-image conditioning: Image conditioning is based on cropped DinoV2 embeddings at high resolution, but the sensitivity to object segmentation quality, background clutter, occlusions, or viewpoint mismatch is not studied. Domain gap from synthetic training renders to real photographs is unquantified.
- Control diversity and editability: The model supports image, geometry, and color controls, but does not offer or evaluate fine-grained user controls (text prompts, regional masks, style/material attributes, constraint satisfaction on specific parts), nor interactive editing workflows or stability during iterative edits.
- Evaluation protocol scope: Generation evaluation focuses on cFID, CMMD, CLIP-I, and LPIPS for albedo-only renders. Missing are application-relevant metrics: alignment/edge consistency, PBR rendering consistency under varied lighting/camera poses, perceptual user studies, and task-specific metrics for refinement/inpainting/part texturing.
- Fair comparison with commercial systems: Visual comparisons include commercial methods that use their own geometries, potentially confounding texture alignment and quality. An apples-to-apples comparison on shared geometry and standardized evaluation is needed.
- Part segmentation/texturing rigor: Zero-shot and finetuned part segmentation/texturing are shown visually, but lack quantitative benchmarks (e.g., IoU, boundary accuracy) and analyses of failure cases (ambiguous adjacencies, closed surfaces, occluded interiors). Strategies for disambiguating adjacent closed surfaces remain open.
- Material generation evaluation: The material pipeline’s effectiveness is demonstrated qualitatively, with no quantitative evaluation (e.g., reflectance fitting error, rendering-based comparisons under controlled lighting, perceptual studies) or controlled ablations against MVD baselines.
- Scalability and compute: Training involves a 300M-parameter VAE and a 1.9B-parameter DiT; the paper does not report training compute, inference memory footprints at different token lengths, or deployment feasibility on commodity hardware.
- Theoretical understanding of latent color diffusion in 3D: There is no analysis of why latent diffusion over color point sets yields strong alignment and consistency (e.g., inductive biases, conditioning geometry latent isomorphism), or formalization of the conditions under which the approach guarantees coherence on complex surfaces.
- Failure modes and robustness: The paper lacks a systematic catalog of failure cases (e.g., high-frequency decals, very thin features, repeated patterns, glossy/transparent materials, extreme occlusions) and proposed remedies or detection strategies.
- Multi-object and scene-level extension: The method targets single-object assets; open questions remain on handling multi-object scenes, inter-object occlusions, global illumination cues for materials, and scalable scene-level texture/material synthesis.
- Integration with industry pipelines: Practical issues such as compatibility with asset authoring tools, baking to multi-channel PBR maps, LOD management, mipmapping, texture atlas creation, and consistency across export formats are not addressed.
- Data curation for materials: The paper notes data curation should be enhanced for material generation but does not propose concrete protocols for collecting, annotating, or validating large-scale PBR datasets with ground-truth separation of albedo and material properties.
Practical Applications
Below is an overview of practical, real-world applications derived from the NaTex framework’s findings, methods, and innovations. Applications are grouped by deployability and linked to sectors, with notes on tools/workflows and feasibility assumptions.
Immediate Applications
- Native 3D Asset Texturing from a Single Image (gaming, VFX/animation, AR/VR, software)
- What: Generate UV textures or per-vertex/per-face colors directly on meshes with precise geometry–texture alignment, occlusion-free coverage, and cross-view coherence.
- Why: Avoids multi-view baking artifacts; five-step generation and even one-step sampling are feasible due to strong conditioning.
- Tools/Workflows: Blender/Maya/3ds Max/Omniverse plug-ins; Unity/Unreal integrations; a NaTex “Texture Generator” SDK/API; batch pipeline for content studios.
- Assumptions/Dependencies: High-quality meshes with normals; GPU memory for VAE (≈300M) and DiT (≈1.9B); Dinov2-based image conditioning; access to reference images.
- PBR Material Generation (albedo + roughness + metallic) (gaming, VFX, industrial design, digital twins)
- What: Produce physically-based material maps natively by treating roughness/metallic as channels in the color point cloud; illumination-invariant training improves robustness.
- Why: Better alignment and coherence than prior MVD pipelines; plug-and-play with downstream renderers.
- Tools/Workflows: Material authoring plug-in; export to MDL/GLTF/UDIM; “NaTex-Material” two-stage pipeline (albedo → roughness/metallic).
- Assumptions/Dependencies: Curated material datasets; consistent geometry sampling; renderer compatibility; possibly scene lighting metadata.
- Texture Refinement and Neural Inpainting (software, gaming/VFX, 3D scanning/photogrammetry)
- What: Use color control to repair occluded regions, correct misalignments, and enhance legacy textures from MVD or scans.
- Why: Outperforms traditional 2D inpainting in occluded or complex geometry regions; fast (≈5 steps).
- Tools/Workflows: “NaTex Refine” module; batch clean-up pipeline; CLI/REST endpoints for post-processing.
- Assumptions/Dependencies: Initial textures and mesh topology; compute budget for iterative passes on large asset libraries.
- Part-Aware Texturing and Zero-/Few-Shot Part Segmentation (manufacturing/CAD, robotics simulation, education)
- What: Condition on 2D masks to produce aligned part-level textures; finetuning yields accurate 3D part segmentation on complex structures.
- Why: Native geometry control enables clean boundaries and occlusion handling between parts.
- Tools/Workflows: SAM-based 2D mask creation → NaTex part texturing; “Part Seg” finetune; selective texture export per submesh.
- Assumptions/Dependencies: Reliable 2D segmentation (e.g., SAM); part hierarchy or mask definitions; mesh consistency (closed surfaces may need extra care).
- E-commerce/Product Visualization from Catalog Images (retail, marketing, content platforms)
- What: Turn product photos into realistic 3D textures for 360° spins, AR previews, and configurators.
- Why: Cuts manual texturing time; maintains brand-consistent look under varying viewpoints.
- Tools/Workflows: CMS integration; auto-texture service (image + mesh input → PBR maps); QC review loop with fast re-generation.
- Assumptions/Dependencies: Product meshes (from CAD or scans); clear, high-quality reference images; brand compliance review.
- Architectural and Interior Visualization (AEC, real estate)
- What: Texture building exteriors/interiors from reference photos; generate aligned materials across complex surfaces (nooks, corners).
- Why: Handles occlusions and fine details better than view-projection methods; speeds up scene dressing.
- Tools/Workflows: DCC plug-in for scene texturing; material library augmentation from mood boards; export to BIM/renderer-friendly formats.
- Assumptions/Dependencies: Clean geometry with correct normals and scale; curated texture/mood references; material parameter validation.
- Robotics Simulation Domain Randomization (robotics, autonomy)
- What: Generate coherent, parameterized textures/materials for simulated environments/objects to improve sim-to-real transfer.
- Why: Consistent, occlusion-free textures reduce visual artifacts that confound perception models.
- Tools/Workflows: Procedural randomization harness backed by NaTex; integration with Gazebo/Isaac Sim/Unity Robotics.
- Assumptions/Dependencies: Mesh repositories of target domains; constraints on material ranges; simulator compatibility.
- Research Bench for 3D-Native Texture Fields (academia)
- What: Use color point cloud VAE + multi-control DiT as a testbed for studying geometry-conditioned generation, compression (>80×), and flow-matching on 3D color fields.
- Why: Provides a unified framework to encode appearance, materials, semantics in the same latent space.
- Tools/Workflows: Open benchmarks for reconstruction (PSNR/SSIM/LPIPS) and generation (cFID/CMMD/CLIP-I); ablations on RoPE vs. geometry latents.
- Assumptions/Dependencies: Access to 3D textured datasets; reproducible sampling/render pipelines; compute for scaling token lengths.
- Creator and Education Tools (daily life, education)
- What: Hobbyist-friendly texture generation/refinement for mods, avatars, 3D prints with color, and classroom demonstrations of 3D texturing principles.
- Why: Five-step sampling and one-step generation feasibility lower barriers for non-experts.
- Tools/Workflows: Simplified UI; preset workflows (“From Photo,” “Fix Texture,” “Add Material”); integration with maker platforms.
- Assumptions/Dependencies: Consumer GPUs or cloud access; curated starter meshes; basic familiarity with asset import/export.
Long-Term Applications
- Real-Time, On-Device Texturing for XR (AR/VR/headsets, mobile)
- What: Distilled or compressed NaTex variants enabling interactive texturing/editing on XR devices.
- Why: One-step generation signals promise for low-latency experiences; native geometry control ensures consistency.
- Tools/Workflows: Mobile-optimized DiT; token-merging/quantization; XR authoring apps with live capture → texture.
- Assumptions/Dependencies: Further model distillation; hardware acceleration on-device; energy/thermal constraints.
- Full Material Stack Generation Beyond R/M (PBR+BRDF) (VFX, engineering, product design)
- What: Extend to normals, AO, specular, clearcoat, displacement, measured BRDFs, and cross-channel physical consistency.
- Why: Enables turnkey materials ready for demanding production-quality renders and engineering analyses.
- Tools/Workflows: Multi-head VAE/DiT; physical priors; material validators; renderer integration tests.
- Assumptions/Dependencies: High-quality labeled datasets; physically consistent losses; cross-domain generalization.
- End-to-End Single-Image → Textured 3D Asset Studios (software platforms, content factories)
- What: Combine Hunyuan3D geometry generators with NaTex to deliver one-click, high-quality, textured assets at scale.
- Why: Eliminates multi-stage 2D lifting; reduces artisanal bottlenecks significantly.
- Tools/Workflows: Asset pipelines (ingest → geometry → texture → QC → publish); cloud orchestration; versioning/asset provenance.
- Assumptions/Dependencies: Robust geometry generators across categories; automated QA metrics for alignment/coherence; governance for IP and licensing.
- CAD/PLM Integration with Part Semantics and Compliance (manufacturing, policy/standards)
- What: Embed part-aware textures and labels into CAD/PLM systems for digital prototyping, BOM linkage, and compliance checks (e.g., coatings).
- Why: Unifies appearance and semantics; accelerates downstream manufacturing decisions.
- Tools/Workflows: CAD plug-ins; USD/GLTF/STEP with part annotations; compliance dashboards.
- Assumptions/Dependencies: Standardized 3D-native texture representations; enterprise data access; domain-specific ontologies.
- Large-Scale Digital Twins and Synthetic Data Generation (smart cities, industrial IoT)
- What: Auto-texture vast libraries of assets (buildings, machines) for accurate simulation and visualization; generate diverse synthetic datasets for CV models.
- Why: Native 3D textures scale better across occlusions and complex geometry than 2D baked approaches.
- Tools/Workflows: Distributed generation; content deduplication; telemetry-linked material updates.
- Assumptions/Dependencies: High-throughput compute; data pipelines; careful governance for realism vs. bias.
- Color 3D Printing Workflows (manufacturing, maker ecosystems)
- What: Map generated textures to printer profiles (CMYK/voxel) for full-color prints and specialized coatings.
- Why: Geometry-aligned textures translate well to printable color fields.
- Tools/Workflows: Slicer integration; color management; ICC profiling for 3D devices.
- Assumptions/Dependencies: Print hardware/material constraints; color calibration; mesh watertightness.
- Asset Provenance, Watermarking, and Moderation (policy, platform governance)
- What: Embed provenance/watermarks in texture latent codes; detect/flag AI-generated textures on content platforms.
- Why: Supports responsible AI and content authenticity at scale.
- Tools/Workflows: Watermarking at decode time; platform-side detectors; audit trails.
- Assumptions/Dependencies: Community standards; low-impact watermarking on visual quality; cooperation across tool vendors.
- Standardization of 3D-Native Texture Representations (standards bodies, ecosystem tooling)
- What: Formalize “color point cloud” textures and geometry-aware latents within USD/USDZ/GLTF; define interop for DCC and game engines.
- Why: Reduces pipeline fragmentation; helps vendors adopt native texturing.
- Tools/Workflows: Reference converters (UV ↔ color field); spec proposals; test suites.
- Assumptions/Dependencies: Consensus across industry; backward compatibility; performance targets for real-time apps.
- Advanced Robotics Sim-to-Real Transfer (robotics, autonomy)
- What: Joint material and texture generation optimized for perception-in-the-loop training, with controllable variability and photometric consistency.
- Why: Texture realism and alignment impact feature extractors and robustness.
- Tools/Workflows: Curriculum-based domain randomization; evaluation harnesses; multi-sensor rendering pipelines.
- Assumptions/Dependencies: Photometric calibration; dataset curation for target domains; integration with digital twin environments.
Notes on global feasibility across applications:
- Compute and memory: Current models (≈2B parameters total) benefit from high-end GPUs; compression and distillation can reduce cost over time.
- Data quality: Mesh topology, normals, and curated texture/material datasets materially affect outcomes; lighting metadata helps material generation.
- Integration: Export formats (UV, per-vertex, UDIM) and renderer compatibility are essential; USD/GLTF support improves interoperability.
- Controls: Dinov2 for image conditioning and SAM for masks are dependencies; geometry latents and RoPE are core to alignment quality.
- Governance: IP licensing for training data, watermarking, and provenance tracking should be planned for commercial deployment.
Glossary
- Albedo: The base color component of a material in physically based rendering, excluding shading or lighting. "All methods are rendered with albedo only."
- Backprojection: A geometric process that reconstructs 3D information by projecting 2D observations back into 3D space using known camera parameters. "a deterministic backprojection process is employed to reconstruct 3D textures from the 2D views."
- Baking: The process of converting multi-view or procedural data into 2D texture maps aligned to geometry (e.g., UVs). "rely on baking 2D multi-view images synthesized by geometry-conditioned Multi-View Diffusion models (MVDs)"
- CLIP-based FID (c-FID): A version of Fréchet Inception Distance computed in CLIP embedding space to assess generative image quality against references. "CLIP-based FID (c-FID), Learned Perceptual Image Patch Similarity (LPIPS), CLIP Maximum-Mean Discrepancy (CMMD), and LIP-Image Similarity (CLIP-I)."
- CLIP-I: A CLIP-based image similarity metric evaluating how closely generated images match input prompts or references. "CLIP-based FID (c-FID), Learned Perceptual Image Patch Similarity (LPIPS), CLIP Maximum-Mean Discrepancy (CMMD), and LIP-Image Similarity (CLIP-I)."
- CMMD (CLIP Maximum-Mean Discrepancy): A distributional distance computed in CLIP space to compare sets of features from generated and real images. "CLIP-based FID (c-FID), Learned Perceptual Image Patch Similarity (LPIPS), CLIP Maximum-Mean Discrepancy (CMMD), and LIP-Image Similarity (CLIP-I)."
- Classifier-free guidance: A sampling technique that mixes conditional and unconditional model predictions to steer diffusion outputs without a separate classifier. "We adopt classifier-free guidance by replacing conditioning embeddings with zero embeddings at a 10% probability during training."
- Color point cloud: A set of 3D points augmented with RGB values, representing texture directly in 3D space. "viewing texture as a dense color point cloud."
- Color regression loss: A supervision term that penalizes discrepancies between predicted and ground-truth colors at on-surface and near-surface locations. "We also introduce a new color regression loss that supervises both on- and near-surface regions."
- Cross-attention: An attention mechanism that lets one set of tokens query another, used here to compress point-cloud inputs into latent sets. "We retain the use of cross-attention for compressing the input point cloud into a set of latent vectors queried by points,"
- Dinov2-Giant: A large vision transformer used for robust image conditioning by providing high-quality feature embeddings. "we use Dinov2-Giant for image conditioning, utilizing the embedding from the last hidden layer without the class token."
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion-based generation, operating over latent tokens. "a multi-control diffusion transformer (DiT), entirely trained from scratch using 3D data, for texture reconstruction and generation."
- Flow matching: A training objective that matches the model’s vector field to the target flow, enabling efficient diffusion-like sampling. "The model is trained with a flow matching~\cite{lipman2022flow} loss."
- Gaussian Splatting: A 3D scene representation that renders point-based Gaussians for efficient view synthesis or texture proxying. "rely on intermediate representations such as Gaussian Splatting~\cite{kerbl20233d,xiong2025texgaussian} or UV Maps~\cite{liu2025texgarment, yu2023texture}"
- Geometry latents: Learned latent tokens encoding geometric information, used to condition texture generation for alignment. "the geometry latents are extracted via a dedicated geometry branch tightly coupled with the color VAE,"
- Geometry tokens: Tokenized geometric embeddings concatenated or attended to by texture tokens to provide pointwise surface guidance. "geometry tokens are deeply intertwined with color tokens,"
- HDRI maps: High dynamic range environment images used to simulate realistic lighting in rendering. "including point lights, area lights, and HDRI maps."
- Illumination-invariant loss: A constraint encouraging predictions to remain consistent under different lighting conditions. "we also include an illumination-invariant loss, which results a hybrid loss:"
- Inpainting: Filling in missing or occluded regions in images or textures to produce coherent results. "occluded regions that require inpainting"
- Janus problem: A multi-view inconsistency where a single object exhibits multiple contradictory faces or appearances. "commonly referred to as the “Janus problem” (multi-faced objects)."
- KL divergence: A regularization term in VAEs that aligns the latent distribution with a prior. "jointly optimized with a KL divergence term,"
- Latent diffusion: Generative modeling that performs diffusion in a compressed latent space rather than pixel space. "via a latent diffusion approach,"
- LPIPS (Learned Perceptual Image Patch Similarity): A perceptual metric measuring visual similarity using deep features. "CLIP-based FID (c-FID), Learned Perceptual Image Patch Similarity (LPIPS), CLIP Maximum-Mean Discrepancy (CMMD), and LIP-Image Similarity (CLIP-I)."
- Metallic (map): A PBR texture channel indicating metallicity of surfaces, often paired with roughness. "representing roughness and metallic as two channels in an RGB color point cloud."
- Multi-View Diffusion (MVD): Diffusion models trained to produce consistent images across multiple camera views, often conditioned on geometry. "geometry-conditioned Multi-View Diffusion models (MVDs)"
- Octree representation: A hierarchical spatial partitioning data structure for compressing and processing 3D data efficiently. "adopt octree-representation for compression,"
- PBR (Physically Based Rendering): A rendering approach that models light-material interactions using physically grounded parameters. "High-quality PBR-textured assets generated by NaTex."
- Positional embeddings: Encodings of spatial coordinates injected into models to preserve geometric structure. "conditions the DiT on direct 3D spatial information via positional embeddings and geometry latents."
- Rectified flow: A flow-based generative approach that “rectifies” the training target for improved sampling and stability. "We adopt an architecture similar to the rectified flow diffusion transformer~\cite{flux2024} for generating the texture latent set."
- RoPE (Rotary Position Embedding): A positional encoding method that rotates queries/keys to inject relative position into attention. "we incorporate RoPE~\cite{su2024roformer} based on the positions of sampled point queries,"
- Roughness (map): A PBR texture channel controlling microfacet smoothness, affecting specular highlights. "representing roughness and metallic as two channels in an RGB color point cloud."
- Score Distillation Sampling (SDS): A technique that distills guidance from a pretrained diffusion model to optimize 3D or texture parameters. "employs Score Distillation Sampling (SDS) \cite{poole2022dreamfusion} for iterative texture optimization"
- Signed Distance Function (SDF) loss: A loss based on distances signed by inside/outside of a surface, requiring watertight geometry. "correlating the color point cloud with a watertight mesh (required for standard SDF loss) is non-trivial."
- Triplane representation: A 3D representation using three orthogonal feature planes to encode volumetric fields. "limited at low resolution due to the complexity of triplane representation."
- Truncated UDF: A modification of the unsigned distance function that caps values to stabilize learning near surfaces. "we introduce a truncated UDF loss:"
- UDF (Unsigned Distance Function): Distance to the nearest surface without sign; useful when meshes are not watertight. "the truncated UDF is adopted because correlating the color point cloud with a watertight mesh (required for standard SDF loss) is non-trivial."
- UV maps: 2D parameterizations of 3D surfaces used to store texture images aligned to geometry. "rely on intermediate representations such as Gaussian Splatting~\cite{kerbl20233d,xiong2025texgaussian} or UV Maps~\cite{liu2025texgarment, yu2023texture}"
- UV unwrapping: The process of mapping 3D surface coordinates to 2D UV space, often introducing distortions or seams. "excessive reliance on UV unwrapping."
- Variational Autoencoder (VAE): A probabilistic autoencoder that learns latent distributions for reconstruction and generation. "we propose a color point cloud Variational Autoencoder (VAE)"
- Watertight mesh: A mesh with no holes or self-intersections, enabling well-defined inside/outside for distance-based losses. "correlating the color point cloud with a watertight mesh (required for standard SDF loss) is non-trivial."
- Zero-shot: Performing a task without task-specific training by leveraging generalization from pretrained models. "Nevertheless, this zero-shot strategy may produce fragmented or inconsistent results for complex structures."
Collections
Sign up for free to add this paper to one or more collections.

