- The paper introduces TexPainter, a method that achieves multi-view consistent texture generation for 3D meshes using diffusion-based latent optimization.
- It employs parallel denoising and color-space fusion techniques to blend textures across camera views, significantly reducing view-dependent artifacts.
- Quantitative evaluations using FID scores and ablation studies demonstrate its superior texture quality compared to methods like TEXTure and TexFusion.
TexPainter: Generative Mesh Texturing with Multi-view Consistency
TexPainter is a method designed for automatic texture generation for arbitrary 3D meshes. It achieves this by leveraging the capabilities of pre-trained diffusion models with a specific focus on multi-view consistency in the generated textures. The following sections detail the methodology, advantages, and evaluations of the approach.
Introduction and Motivation
Generative models have significantly progressed with diffusion models' success, particularly in 2D image generation. However, transferring these advances to 3D mesh texturing poses challenges due to the need for multi-view consistency in textures. TexPainter addresses this challenge by using pre-trained Denoising Diffusion Implicit Models (DDIM) to enforce multi-view consistency. It focuses on optimization-based color-fusion techniques to modify latent codes effectively across different camera views, thus improving texture quality and consistency.
The core insight is that while diffusion models independently denoise each camera view in latent space, TexPainter introduces a process to harmonize these views in the color space, achieving a cohesive final texture. This method avoids assumptions about sequential dependencies, which are inherent limitations in previous techniques.
Methodology
TexPainter operates by running separate denoising processes for each camera view in parallel using DDIM. The method involves the following key steps:
- Parallel Denoising: Each view generates a predicted noiseless latent code at the 0th timestep.
- Color-space Fusion: These latent codes are decoded into images, which are then blended in color space to create a consistent texture image.
- Optimization of Latents: The predicted latent codes are optimized to ensure the decoded images match the rendered scenes using the fused texture.
- Iterative Refinement: The process iterates over denoising steps, continually refining the texture and latent codes until convergence.
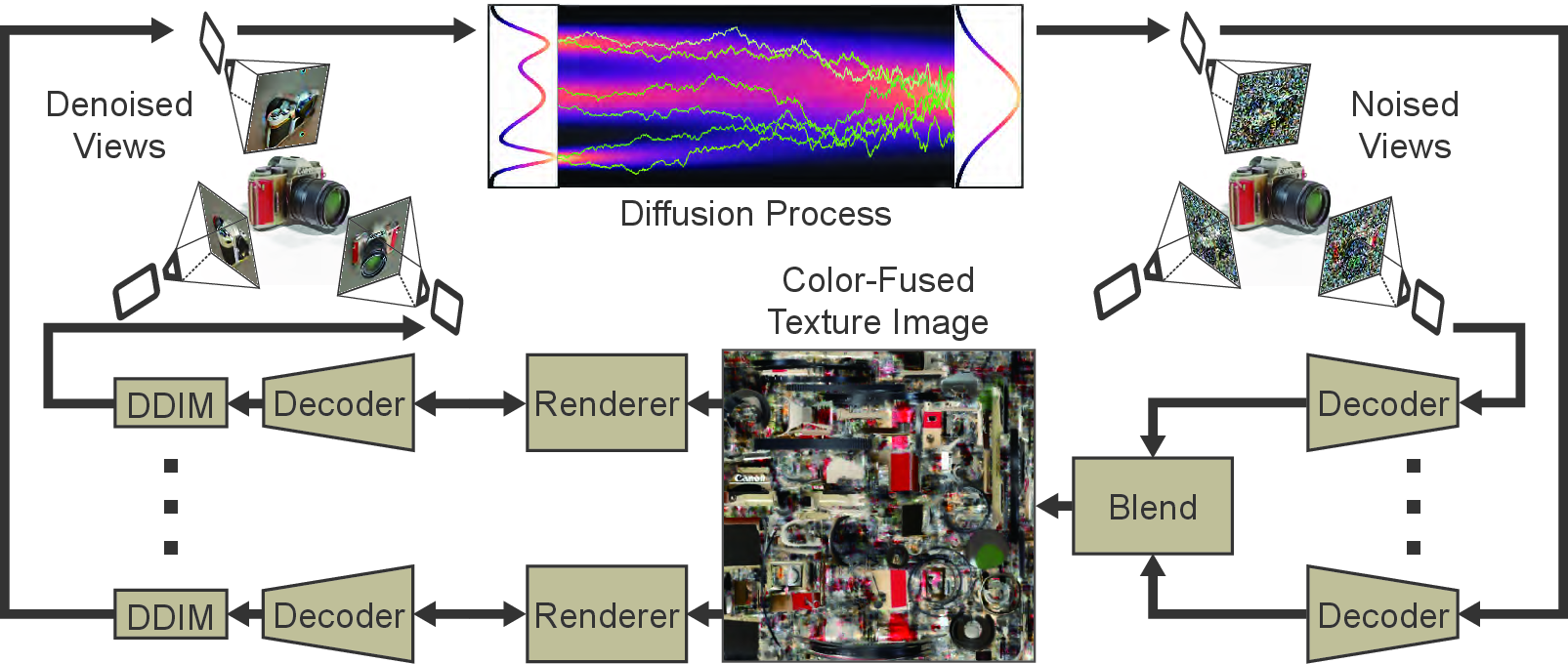
Figure 1: Illustration of TexPainter's pipeline, including parallel denoising, color-space fusion, and latent optimization.
The blending in color space using weighted averaging ensures that textures align with surface normals and camera views, promoting consistency across views. This is followed by an optimization step, using gradient backpropagation to adjust the latent space representation for each view, ensuring that they collectively form a unified and consistent texture when rendered.
Evaluation
TexPainter's effectiveness was compared against other state-of-the-art methods, such as TEXTure, TexFusion, and Fantasia3D. Evaluations involve both qualitative and quantitative assessments:
- Qualitative Comparison: Visual inspections show TexPainter produces clearer, more consistent textures across multiple views compared to methods like TEXTure and TexFusion, which suffer from view-dependent artifacts.
- Quantitative Metrics: The method was evaluated using Fréchet Inception Distance (FID), revealing superior performance in producing visually coherent images. The FID scores illustrate improved semantic alignment of textures with text prompts compared to competing methods.
- Ablation Studies: Experiments demonstrate the necessity of TexPainter's components, particularly the color-space fusion and optimization, which are critical to its success in achieving consistency and high-quality textures.






Figure 2: Ablation study results highlighting the importance of color-space fusion for maintaining texture consistency.
Implications and Future Work
The development of TexPainter marks a significant step toward automated high-fidelity texturing of 3D models using diffusion models. Its approach to multi-view consistency extends beyond just texturing and has implications for broader 3D content creation tasks.
Future work includes optimizing runtime performance and exploring dynamic camera view selection to improve coverage and further enhance texture fidelity. Additionally, integrating more advanced diffusion models and exploring their application in other 3D representation modalities could further expand the capabilities of generative texturing.
Conclusion
TexPainter advances mesh texturing by leveraging diffusion models for consistent multi-view texturing. Its novel color-space fusion strategy and optimization of latent representations yield significant improvements in quality and consistency over existing methods. This approach presents a substantial advancement in generative 3D texturing, with potential implications for broader applications in automated content creation within computer graphics.