Gaussian See, Gaussian Do: Semantic 3D Motion Transfer from Multiview Video
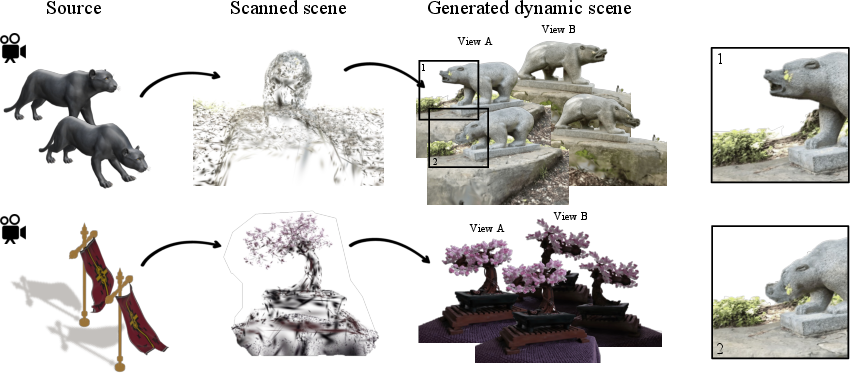
Abstract: We present Gaussian See, Gaussian Do, a novel approach for semantic 3D motion transfer from multiview video. Our method enables rig-free, cross-category motion transfer between objects with semantically meaningful correspondence. Building on implicit motion transfer techniques, we extract motion embeddings from source videos via condition inversion, apply them to rendered frames of static target shapes, and use the resulting videos to supervise dynamic 3D Gaussian Splatting reconstruction. Our approach introduces an anchor-based view-aware motion embedding mechanism, ensuring cross-view consistency and accelerating convergence, along with a robust 4D reconstruction pipeline that consolidates noisy supervision videos. We establish the first benchmark for semantic 3D motion transfer and demonstrate superior motion fidelity and structural consistency compared to adapted baselines. Code and data for this paper available at https://gsgd-motiontransfer.github.io/



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to make a still 3D object “come alive” by copying motion from a video, even when the source and target are very different. For example, it can take a bird’s wing-flapping and make an elephant cartoon’s ears flap, or take a horse rearing and make a car lift its front wheels. The method works without a traditional skeleton or “rig,” and uses a modern 3D format called 3D Gaussian Splatting (3DGS), which represents 3D objects as lots of tiny colored blobs.
What questions does the paper try to answer?
- How can we transfer the “idea” of motion from a video to a static 3D object, even if the two don’t share the same shape, bones, or structure?
- Can we do this using multiple camera views of the motion (so we don’t miss hidden parts) and keep the target’s identity and shape intact?
- How do we make the final animation smooth and stable, even if the AI-generated supervision videos have visual glitches?
- Can we measure how well motion transfer works, and compare methods fairly?
How does the method work?
Think of the system as teaching a statue to dance by watching videos of a dancer from different angles, then moving the statue’s “handles” to recreate that dance in 3D.
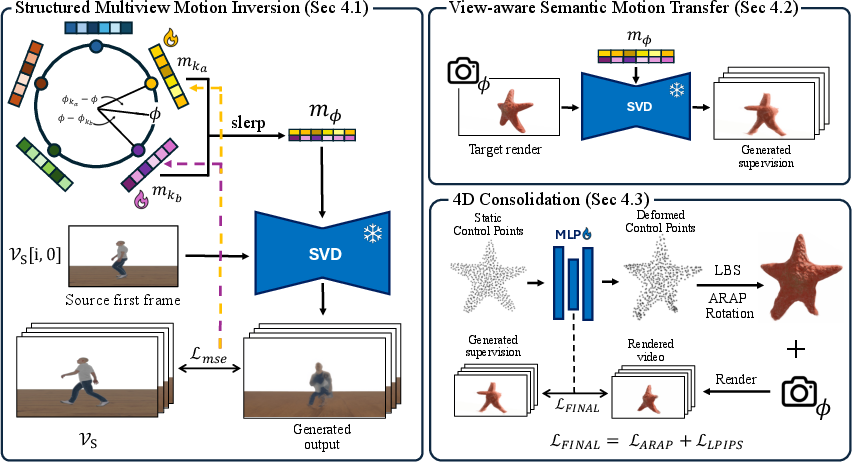
Step 1: Learn motion from multiview videos (the “motion code”)
- The system watches several videos of the source motion from different camera angles. It uses a powerful video-making AI (a “diffusion” model) in reverse: instead of generating a video from a code, it “inverts” the process to guess the code that could have produced the given motion. This code is called a motion embedding—like a compact recipe for “how this thing moves.”
- Because motion looks different from different angles, the paper trains a small set of “anchor” motion codes spread around the viewing circle (like compass points). When the system needs the motion from any angle, it smoothly blends the two nearest anchors (a process called slerp) to get the right motion code for that view. This makes learning faster and more consistent across views.
Everyday analogy: If you want to learn a dance, it helps to watch it from front, side, and back. The method creates a few “key dance guides” for those angles and blends them when you need a new viewpoint.
Step 2: Make supervision videos for the target object
- The target object is a still 3DGS model (imagine a 3D sculpture made of thousands of tiny colored blobs).
- The system renders the target from a chosen camera angle, then applies the source motion code to generate a short 2D video showing how the target should move from that angle. These supervision videos teach the system what the target’s motion ought to look like, view by view.
- These generated videos can be imperfect (they may have flickers or artifacts), so they are used carefully.
Everyday analogy: It’s like sketching how the statue should move from several viewpoints, even if the sketches aren’t perfect.
Step 3: Build a stable 3D animation over time (the “4D” result)
- The target’s 3DGS model gets a set of virtual “control points” (think of them as invisible handles placed across the object). Moving these handles over time bends and rotates nearby blobs to create motion.
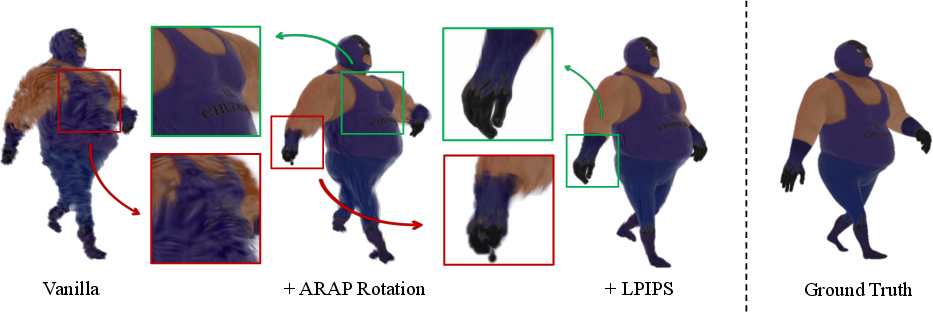
- The system learns how each handle should move over time to match the supervision videos. It uses two smart protections to avoid ugly distortions:
- As-Rigid-As-Possible (ARAP) rotation: keeps local parts from stretching like rubber, by making nearby pieces rotate together in a realistic way.
- Perceptual loss (LPIPS): instead of matching pixels exactly (which is too strict when videos are noisy), it matches overall look and feel in a way similar to how humans judge images. This reduces flicker and preserves fine details.
Everyday analogy: You’re animating a puppet by moving lots of small knobs, but you add rules so the puppet’s arms don’t stretch like taffy and its texture stays clear.
What did they find, and why is it important?
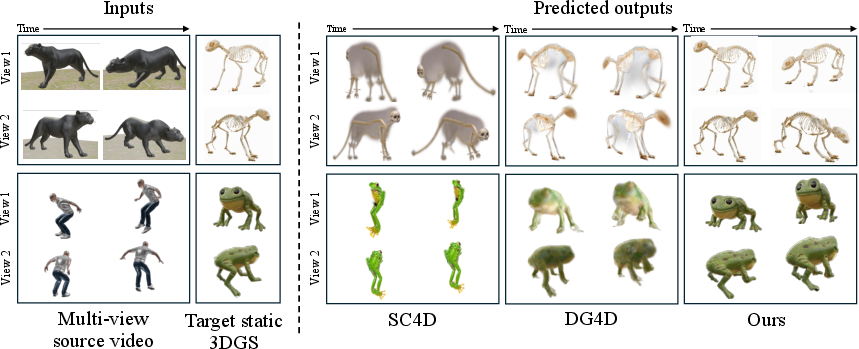
- The method transfers motion well across very different categories (like animals to vehicles), without needing a rig or matching skeletons.
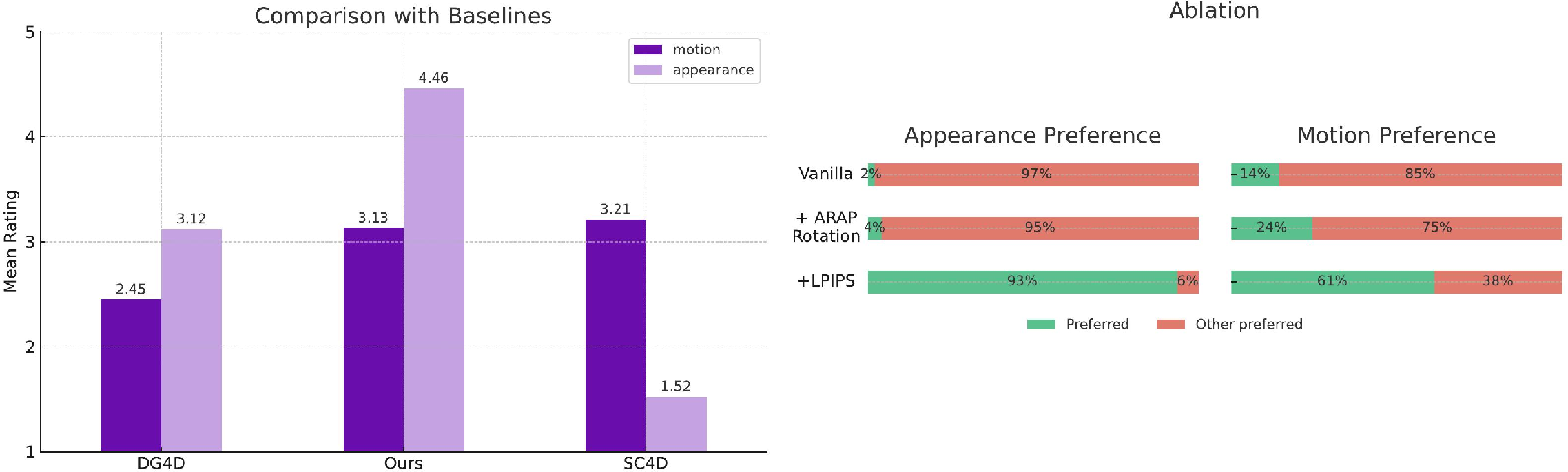
- It creates more faithful and structurally consistent animations than adapted competing methods. In tests, it scored higher on motion fidelity (does the movement match the source?), on appearance preservation, and on similarity measures.
- People preferred its results in a user study, saying it kept the target’s identity while moving realistically.
- It can even synthesize motion for camera angles not seen during training by smoothly blending the anchor codes, showing strong generalization.
- The authors also created the first benchmark for this task to help the community evaluate motion transfer in 3D fairly.
Why it matters: As 3D content explodes in games, AR/VR, films, and robotics, animating objects is still hard, especially when they don’t have a human-like skeleton. This method shows a practical, data-driven way to make diverse 3D assets move realistically by learning motion “semantics” from videos.
What are the broader implications?
- Creators could animate any 3D object—characters, props, or scanned real-world assets—by showing the system example motions, rather than writing complex animation scripts or building detailed rigs.
- It can reduce manual labor in animation pipelines and unlock playful cross-category motion (like a chair dancing or a robot arm gliding like a cat).
- The anchor-based approach suggests a path to faster, more view-consistent motion learning from real footage, which could help with sports analysis, robotics training, or digital doubles.
Limitations and future directions
- Speed: “Inverting” motion in the video AI is computationally heavy. The anchor trick helps, but more speedups are needed.
- Measurement: There isn’t yet a perfect metric to judge 3D semantic motion transfer; better evaluation tools would help.
- View synthesis: The method shows promise in producing motion from new angles; integrating that more tightly could further improve results.
Overall, the paper introduces a creative, practical way to teach 3D objects to move by “seeing” motion in multiview videos, then “doing” it in 3D—hence the name “Gaussian See, Gaussian Do.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several aspects unresolved that future work could address to strengthen semantic 3D motion transfer from multiview video.
- Dependence on multiview source videos with known, static camera extrinsics; no support for single-view inputs or moving/handheld cameras; quantify minimal view requirements and robustness to extrinsic calibration errors.
- Anchor interpolation appears to assume a 1D azimuth angle; handling full 6-DoF viewpoints (including elevation and roll) and generalizing across the entire viewing sphere remains unaddressed.
- No principled analysis of the motion embedding space geometry; slerp may not be appropriate if the space isn’t spherical or isotropic; validate embedding structure and compare against learned view-conditioned encoders.
- High runtime and computational cost of condition inversion and generating multiple supervision videos; develop amortized motion encoders, efficient training schemes, and report detailed runtime/memory profiles.
- Supervision videos from 2D generative models are noisy and cross-view inconsistent; explore 3D-aware priors, multi-view-consistent video generation, and joint cross-view consistency constraints during supervision synthesis.
- Lack of quantitative 3D motion semantics metrics; design correspondence-free metrics for 3D motion fidelity, temporal stability, and identity preservation (geometry, texture), beyond adapted 2D measures and CLIP scores.
- Benchmark scale and diversity limitations; expand dataset size, include real multiview captures with varied lighting/backgrounds/occlusions, and provide ground-truth motions for cross-category pairs to enable fair evaluation.
- No systematic robustness analysis to source video artifacts (compression, motion blur), occlusions, and partial visibility; stress-test the pipeline under realistic degradation.
- Control point initialization and weighting are fixed (furthest-point sampling, non-learned β); evaluate learning radii, adaptive placement/number of control points, and part-aware or segmentation-guided control point strategies.
- Missing treatment of contacts, self-collisions, and topology changes during deformation; incorporate collision handling, volume preservation, and physical constraints to avoid unrealistic stretching or interpenetration.
- Temporal consistency isn’t quantitatively measured; introduce velocity/acceleration smoothness metrics, jitter/drift detection, and long-sequence stability analyses.
- Reuse of motion codes across targets is asserted but not rigorously quantified; measure transfer across shape/scale differences, and develop amplitude/time-warping mechanisms to adapt motion to target morphology.
- Limited semantic controllability; no explicit mapping from source motion parts to target parts; investigate user constraints, text/sketch guidance, or learned semantic part correspondences to steer transfer.
- Sensitivity to number and placement of anchors is only partially explored; devise automated anchor selection/optimization, non-uniform spacing strategies, and per-scene view coverage policies.
- Interpolation across anchors is angle-based; compare to continuous view-conditioned networks or meta-learned embedding generators that could reduce artifacts and improve generalization.
- LPIPS improves perceptual robustness but is appearance-focused; add geometry-aware losses (silhouette IoU, multi-view consistency, Chamfer to canonical geometry) to better preserve structure during consolidation.
- Applicability to extreme deformations, non-articulated objects, soft bodies, fluids, hair/clothing motions is untested; define tasks and evaluate failure modes in these regimes.
- Handling dynamic lighting and shadows is not addressed; 3DGS SH color may not capture time-varying illumination; explore lighting-aware reconstruction or relighting in dynamic scenes.
- Requirement for calibrated, static cameras for source videos remains; develop methods to estimate extrinsics from uncalibrated multi-view footage or to handle moving cameras via SLAM/SfM integration.
- Novel-view motion synthesis is demonstrated but not integrated; quantify benefits of view densification for transfer quality, and formalize how/when to inject synthesized views into the pipeline.
- Ethical and bias considerations of motion semantics learned from the video prior are not analyzed; assess potential biases, domain gaps, and failure cases across different motion categories (human/animal/object).
- Baselines omit rig-free 3D motion transfer methods beyond generative 4D pipelines (e.g., Temporal Residual Jacobians); include and adapt such methods for a more comprehensive comparison.
- Scalability to large, complex targets or full scenes with multiple moving objects is unclear; develop multi-object motion disentanglement and control mechanisms within dynamic 3DGS.
- Reproducibility details (specific video diffusion model, noise schedules, hyperparameters) are sparse; provide full configuration to enable fair replication and deeper ablations.
Practical Applications
Immediate Applications
Below are use cases that can be deployed now using the released code, commodity multiview capture setups, and existing 3DGS pipelines.
- Rigless animation for 3D assets in DCCs and game engines (software, media/entertainment, VR/AR)
- Description: Animate static 3DGS assets without manual rigging by transferring motion from multiview source videos (e.g., dance, animal locomotion, mechanical actions).
- Workflow/Tools: Multiview capture (e.g., multi-phone rig), camera calibration, anchor-based motion embedding inversion, target view rendering, 4D consolidation (SC-GS with ARAP rotation and LPIPS), export to Blender/Maya/Unreal/Unity.
- Potential products: “Rigless Animator” plugin; “View-Aware Motion SDK.”
- Assumptions/Dependencies: Requires known camera extrinsics, a pre-trained image-to-video diffusion model, GPU resources, and 3DGS assets; motion fidelity depends on multiview coverage and clean supervision.
- Previsualization and concept exploration for advertising, film, and games (media/entertainment, design)
- Description: Quickly test “semantic motion ideas” across categories (e.g., bird wing flap → product packaging flaps; horse rear → vehicle tilt) to ideate shots and gameplay.
- Workflow/Tools: Rapid motion embedding extraction from reference footage; batch motion transfer onto product or character mockups; turntable generation for reviews.
- Potential products: “Motion Sketch-to-Previs” service; studio pipeline integrations.
- Assumptions/Dependencies: Multiview source references; legal rights to source motions; time cost for condition inversion; artifacts if supervision videos are noisy.
- Dynamic previews for 3D asset marketplaces (software, e-commerce)
- Description: Sellers attach reusable motion embeddings or dynamic 3DGS previews to static assets to communicate motion potential without rigging.
- Workflow/Tools: Curate motion embeddings from public datasets (e.g., Mixamo, AIST Dance) and publish alongside assets; automated batch transfer and preview rendering.
- Potential products: “Motion Embedding Library” and marketplace; embedding metadata schema.
- Assumptions/Dependencies: Licensing and consent for source motions; platform support for dynamic 3DGS playback; storage costs for embeddings and previews.
- In-the-wild AR object animation (VR/AR, marketing/retail)
- Description: Animate reconstructed real-world objects or scenes (via 3DGS from mobile captures) with semantically matched motions for interactive AR experiences.
- Workflow/Tools: 3DGS reconstruction from phone photos; motion embedding extraction; AR viewer integration.
- Potential products: “Rigless AR Props” toolkit; retail demo activations.
- Assumptions/Dependencies: Robust 3DGS reconstruction from in-the-wild imagery; consent for motion sources; runtime optimization for mobile/edge.
- Synthetic data generation for vision tasks requiring dynamic scenes (AI/ML, academia, software)
- Description: Create controllable dynamic sequences to augment training for object tracking, optical flow, and multi-view consistency.
- Workflow/Tools: Programmatic generation of supervision videos via anchor interpolation; dynamic 3DGS export; dataset pipelines.
- Potential products: “Dynamic Scene Synthesizer” for ML data pipelines.
- Assumptions/Dependencies: Domain gap from synthetic-to-real; model bias from diffusion priors; reproducibility requires consistent evaluation metrics.
- Privacy-preserving motion sharing (social media, education, daily life)
- Description: Share dance/sports movement by transferring it onto neutral avatars, reducing identity exposure while preserving motion intent.
- Workflow/Tools: Motion embedding extraction from multiview footage; transfer to anonymized targets; export for social platforms.
- Potential products: “Motion-to-Avatar” creator apps.
- Assumptions/Dependencies: Adherence to OpenRAIL-M license (no impersonation/deepfakes without consent); quality depends on capture setup and target identity preservation.
- Robotics and industrial pre-viz for motion intent (robotics, manufacturing/design)
- Description: Visualize high-level motion intent on robot arms or mechanical assemblies before formal kinematic mapping or control policy design.
- Workflow/Tools: CAD-to-3DGS conversion; motion transfer from task demonstrations (e.g., cube sliding → end-effector motion); 4D consolidation for review.
- Potential products: “Rigless Motion Ideation” viewer for robotics teams.
- Assumptions/Dependencies: Not a control solution; semantic motion may not respect hardware constraints; requires later retargeting to kinematics.
- Benchmark-driven research adoption (academia)
- Description: Use the released benchmark to evaluate semantic motion fidelity and structural consistency across cross-category pairs; compare methods and ablations.
- Workflow/Tools: Benchmark assets and curated pairs; Motion Fidelity (2D-derived) and CLIP-based metrics; user studies.
- Potential products: Leaderboard; reproducibility kits.
- Assumptions/Dependencies: Lack of robust 3D semantic motion metrics; community consensus needed for standardization.
Long-Term Applications
These use cases need further research, scaling, or productization (e.g., runtime speedups, single-view robustness, kinematic mapping, policy standardization).
- Real-time, single-view rigless motion transfer (software, media/entertainment, VR/AR)
- Description: Stream motion transfer at interactive frame rates from a single camera, enabling live performances and real-time avatar animation.
- R&D needs: Faster condition inversion or learned encoders; stronger priors for occlusions; edge deployment; novel-view synthesis built-in.
- Dependencies: Efficient inference; hardware acceleration; robust camera estimation.
- Motion embeddings as high-level controllers for robots and morphologically diverse agents (robotics)
- Description: Map view-aware motion embeddings to executable kinematic trajectories for heterogeneous platforms (arms, quadrupeds) while respecting constraints.
- R&D needs: Learning alignment between motion embeddings and control policies; safety, robustness, sim-to-real; constraint-aware optimization.
- Dependencies: Accurate dynamics models; policy learning; certification for safety-critical tasks.
- Viewpoint densification for volumetric capture (media/entertainment, software)
- Description: Use anchor interpolation to synthesize novel-view motion for sparse camera arrays, reducing capture cost while maintaining motion fidelity.
- R&D needs: Formalizing view-aware interpolation quality; temporal coherence; integration with volumetric studios.
- Dependencies: Calibration pipelines; capture standards; evaluation protocols.
- Standardized metrics and governance for 3D semantic motion (academia, policy)
- Description: Establish validated 3D motion fidelity metrics, consent practices, and provenance/watermarking for motion embeddings.
- R&D needs: Metric design grounded in perception and biomechanics; dataset governance; tooling for consent tracking.
- Dependencies: Cross-institution consortia; alignment with licenses (e.g., OpenRAIL-M); standards bodies engagement.
- Consumer-grade capture rigs and automated calibration (daily life, software, hardware)
- Description: Multi-phone or camera kits with automated extrinsic estimation and guided capture flows for non-experts.
- R&D needs: Robust self-calibration from casual video; UX for capture guidance; efficient on-device processing.
- Dependencies: Mobile OS APIs; privacy-by-design; energy-efficient compute.
- Healthcare and rehab motion coaching via personalized avatars (healthcare)
- Description: Clinician-demonstrated motions transferred to patient-specific avatars for at-home guidance and progress visualization.
- R&D needs: Clinical validation; biomechanical accuracy; accessibility; HIPAA/GDPR compliance.
- Dependencies: Medical device regulations; secure data pipelines; motion correctness checks.
- Sports training and analysis (sports technology, education)
- Description: Transfer elite motion patterns to trainee avatars for comparative analysis and instruction.
- R&D needs: Objective motion metrics; context-aware feedback; integration with wearables.
- Dependencies: Sensor fusion; licensing of source motions; coach workflow integration.
- Runtime rigless motion components for game engines (software, media/entertainment)
- Description: Native engine modules that apply semantic motions to arbitrary assets during gameplay (NPCs, props) without rigs.
- R&D needs: Performance tuning; memory footprint control; content authoring tools for embeddings.
- Dependencies: Engine SDKs; content pipelines; QA for edge cases.
- Physics- and material-aware deformation (engineering, manufacturing, robotics)
- Description: Incorporate physical plausibility (stiffness, constraints) into motion fields to produce reliable product and mechanism animations.
- R&D needs: Differentiable physics integration; hybrid data-driven/physics priors; validation tests.
- Dependencies: Material models; computational budgets; domain-specific datasets.
- Motion embedding marketplaces with provenance and compliance tooling (software, policy)
- Description: Platforms to share, license, and audit motion embeddings with consent verification, provenance tracking, and misuse safeguards.
- R&D needs: Embedding standards; watermarking; policy enforcement; moderation tools.
- Dependencies: Legal frameworks; interoperable formats; trust infrastructure.
Cross-cutting assumptions and dependencies impacting feasibility
- Multiview source capture and accurate camera extrinsics are currently important for high motion fidelity; single-view inputs may miss occlusions and produce artifacts.
- Pre-trained image-to-video diffusion models provide the motion prior; their biases and licensing terms (OpenRAIL-M) constrain use (e.g., no impersonation/deepfakes without consent).
- Significant GPU compute is required for condition inversion and 4D consolidation; runtime reductions and encoder-based approaches would broaden accessibility.
- 3DGS assets are the target representation; if meshes or other formats are desired, conversion layers or native support must be developed.
- Motion quality depends on anchor configuration (number and distribution), supervision noise, and the robustness of consolidation (ARAP rotation, LPIPS); poor settings can degrade structural consistency.
- Lack of standardized 3D semantic motion metrics may hinder objective comparisons; community efforts are needed to establish evaluation norms.
Glossary
- 3D Gaussian Splatting (3DGS): A neural rendering representation that models volumetric radiance fields using projected 3D Gaussian primitives. "applies them to a static 3D Gaussian Splatting (3DGS) asset"
- 4D reconstruction pipeline: A procedure that recovers a dynamic 3D representation over time (3D + temporal) from noisy supervision videos. "a robust 4D reconstruction pipeline that consolidates noisy supervision videos."
- Alpha-blending: A depth-ordered compositing technique that blends overlapping contributions using opacity (alpha) weights. "by alpha-blending in depth order:"
- Anchor-based interpolator: A mechanism that interpolates motion embeddings between anchor viewpoints to improve cross-view consistency and convergence. "we introduce an anchor-based interpolator that optimizes embeddings collaboratively across views"
- As-Rigid-As-Possible (ARAP) loss: A regularization that enforces local rigidity during deformation by minimizing distortion of relative positions. "The As-Rigid-As-Possible (ARAP) loss \cite{sorkine2007rigid} is a widely used technique"
- ARAP Rotation: A training constraint that replaces predicted rotations with the rotations optimized under ARAP to enforce rigid motion. "we propose an ARAP Rotation mechanism, which explicitly enforces rigid rotational constraints during training."
- CLIP-I: An appearance-preservation metric based on CLIP image embeddings used to assess identity fidelity. "We also assess appearance preservation using CLIP-I \cite{rahamim2024bringing,zhao2023animate124}"
- Condition inversion: An optimization that learns the conditioning embeddings needed for a generative model to reproduce a specific input video. "extract motion embeddings from source videos via condition inversion"
- Control points: Spatial handles with learnable positions and radii that drive deformation in dynamic 3D Gaussian Splatting. "control points with a learnable coordinate and radius."
- Deformation field: A function or network mapping control points and time to transformations that animate the 3D representation. "optimize a deformation field network "
- Denoising score matching loss: The diffusion objective used to learn motion embeddings by matching denoiser outputs to the target video. "minimizing the denoising score matching loss:"
- Extrinsics (camera extrinsics): The pose parameters (rotation and translation) that specify camera orientation and position in world coordinates. "known camera extrinsics $[R_{C_{i}|T_{C_{i}] \in SE(3)$"
- Furthest point sampling: A strategy to initialize a well-spread set of control points over the target geometry. "using furthest point sampling."
- Linear Blend Skinning (LBS): A standard deformation method that blends transformations from multiple control points or bones. "Gaussians are then deformed using Linear Blend Skinning (LBS) \cite{sumner2007embedded}"
- LPIPS: A learned perceptual similarity loss that compares images in a deep feature space to improve robustness to noise and inconsistencies. "we replace pixel-wise losses with the LPIPS \cite{zhang2018perceptual} loss"
- MLP (time-conditioned MLP): A multi-layer perceptron that predicts time-dependent rotations and translations for control points. "A time-conditioned MLP predicts the rotation and translation of control points at time "
- Motion embeddings: Learned token representations that encode motion intent disentangled from appearance for transfer across subjects. "extract motion embeddings from source videos"
- Motion Fidelity: A metric that quantifies how well the transferred motion matches the source motion. "Motion Fidelity measure from \cite{yatim2024space}"
- Quaternion: A 4D rotation representation with operations such as quaternion multiplication used in skinning and deformation. " is the quaternion form of and symbolizes a product of quaternions."
- Radiance field: A volumetric function that describes light emission and absorption used for rendering scenes and objects. "to model volumetric radiance fields."
- Rasterization: The rendering process that projects primitives to image space for fast compositing. "alpha-composited through rasterization"
- Score Distillation Sampling (SDS): A guidance technique that uses generative-model scores to optimize scene parameters under inconsistent views. "Score Distillation Sampling (SDS) loss~\cite{poole2022dreamfusion}"
- SE(3): The group of 3D rigid transformations combining rotations and translations. ""
- Spherical Harmonic coefficients: Basis function coefficients used to represent view-dependent color on Gaussians. "view dependent color modeled with Spherical Harmonic coefficients."
- Spherical Linear Interpolation (SLERP): An interpolation method on the unit sphere that smoothly blends between two embeddings or rotations. "Spherical Linear Interpolation, ensuring smooth transitions between the closest anchor embeddings"
- Video diffusion model: A generative model that denoises noisy inputs to produce videos conditioned on images or embeddings. "pre-trained video diffusion model "
- View-aware motion embedding: An embedding strategy that accounts for camera viewpoint to maintain motion consistency across views. "an anchor-based view-aware motion embedding mechanism"
Collections
Sign up for free to add this paper to one or more collections.

