- The paper introduces LiveRAG, a synthetic Q&A dataset benchmark evaluated with Item Response Theory to quantify question difficulty in RAG systems.
- It details a three-step generation process using DataMorgana to ensure diverse question types and support curriculum learning.
- The evaluation validates IRT-derived difficulty parameters while discussing limitations such as synthetic data biases affecting real-world applications.
Analyzing "LiveRAG: A Diverse Q&A Dataset with Varying Difficulty Level for RAG Evaluation" (2511.14531)
This essay provides an expert summary and analysis of the paper "LiveRAG: A Diverse Q&A Dataset with Varying Difficulty Level for RAG Evaluation." The paper focuses on developing a benchmark for evaluating Retrieval-Augmented Generation (RAG) systems, presenting a synthetic dataset, LiveRAG, to facilitate systematic evaluation thereby contributing to the advancement of RAG-based question-answering systems.
Introduction to RAG Evaluation
Retrieval-Augmented Generation (RAG) integrates retrieval mechanisms with generative models to enhance the capability of LLMs in question-answering (QA) tasks. The need for robust evaluation frameworks for RAG systems is increasingly critical as their efficacy becomes more widespread. The LiveRAG dataset emerges to address this necessity, offering a structured evaluation benchmark that was initially field-tested during the SIGIR'2025 Challenge.
Dataset Construction and Characteristics
The LiveRAG dataset consists of 895 synthetic question-answer pairs generated using the DataMorgana tool. To develop this dataset, several steps were taken to ensure diversity and challenge across questions. The dataset questions are evaluated using Item Response Theory (IRT), providing parameters such as difficulty and discriminability to assess the effectiveness and differentiation capacity of QA systems.
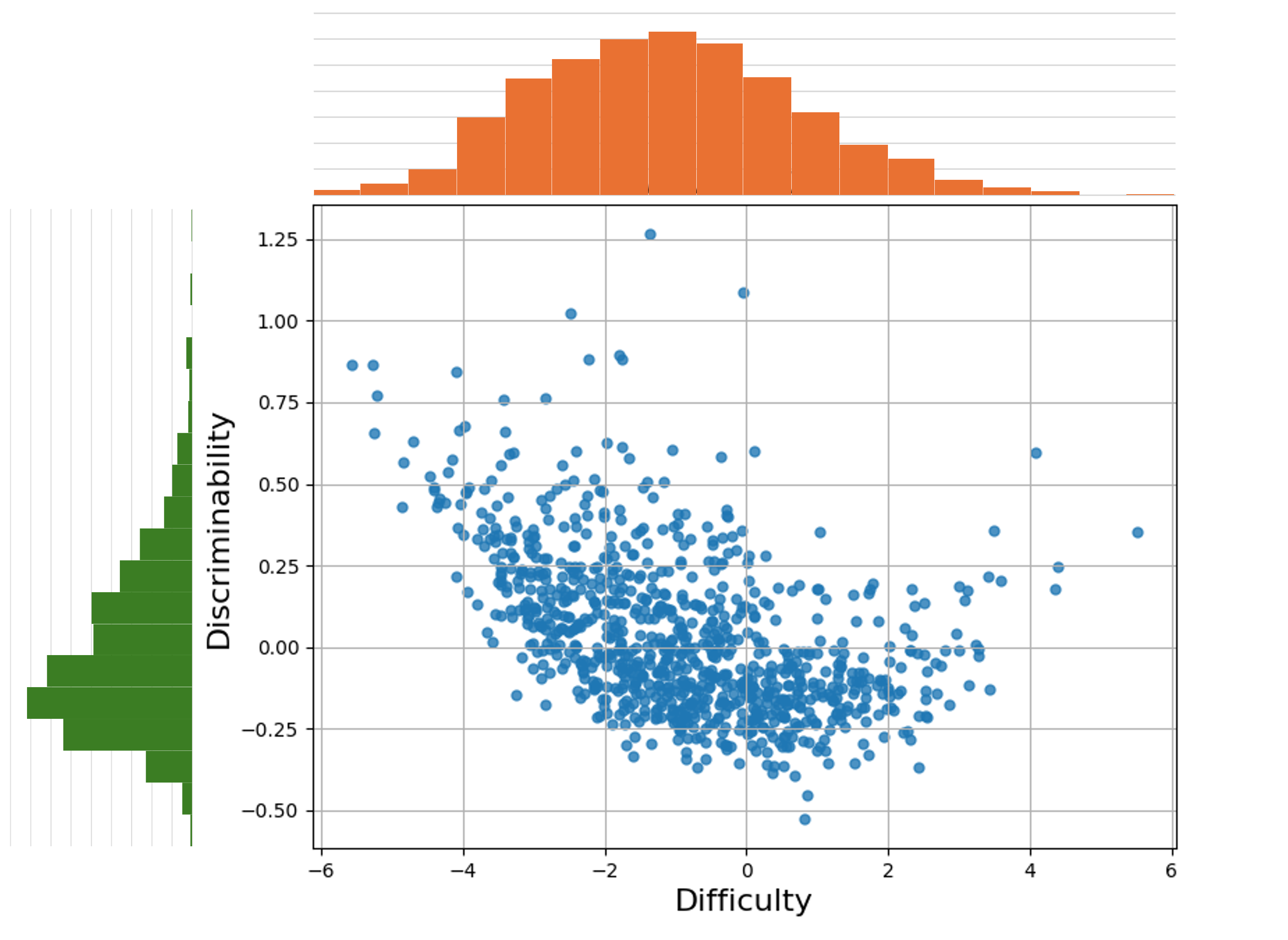
Figure 1: Question parameters learned by the IRT-2PL model for the dataset. Top: Difficulty distribution. Left: Discriminability distribution. Middle: Scatter plot of difficulty and discriminability scores of all benchmark questions.
The IRT model allows for the normalization of questions’ difficulty, which is crucial as the dataset merges different session questions from the original challenge, facilitating a common evaluation scale. Practitioners can exploit these parameters for training systems with questions of various difficulty levels, promoting methodologies like curriculum learning.
Generation Process using DataMorgana
DataMorgana employs document sampling and a three-step generation process to produce question-answer pairs. The benchmark is designed with comprehensive categorizations that influence question types, such as answer type and style, linguistic correctness, and user persona, enhancing the dataset's diversity and coverage.
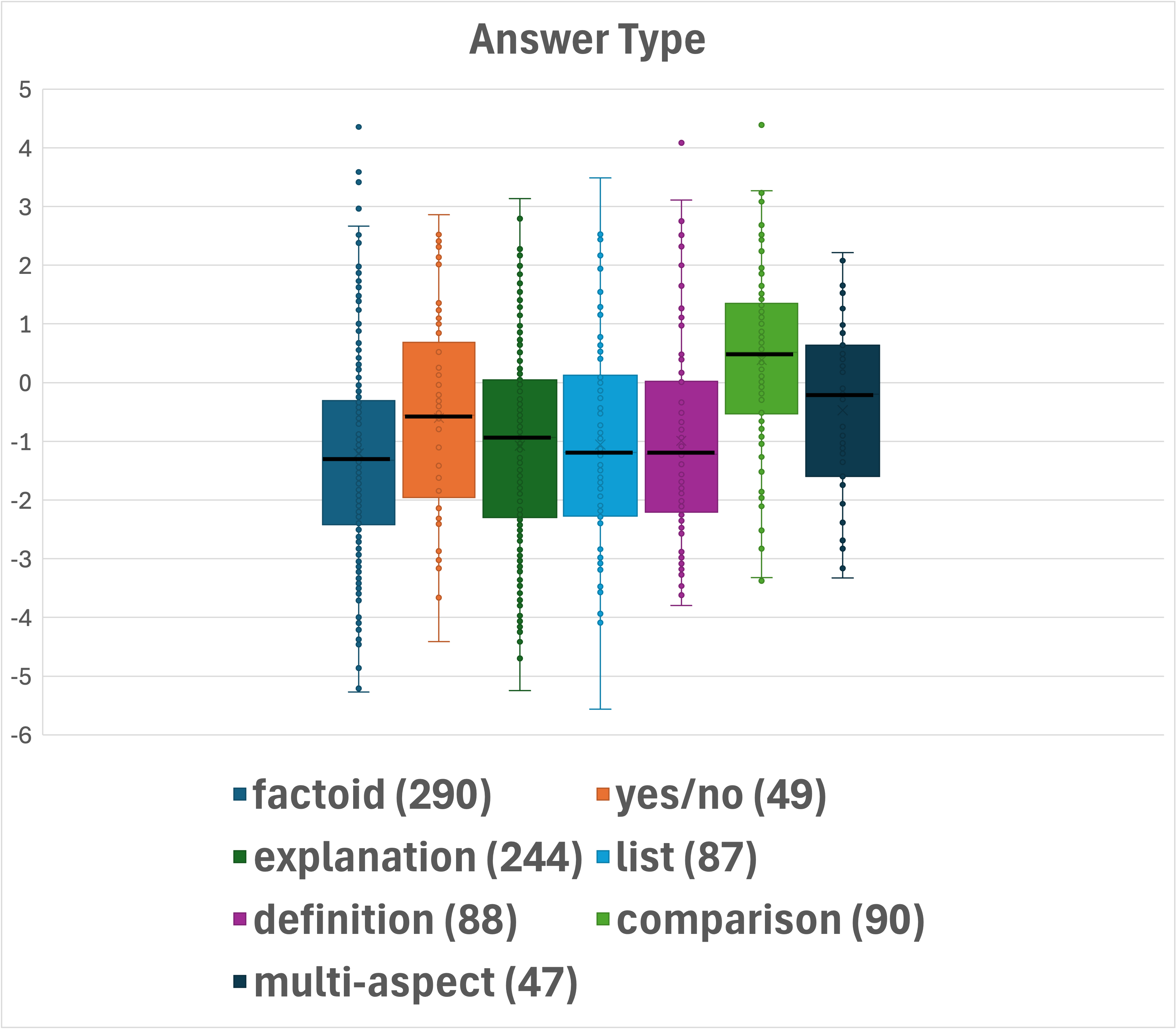
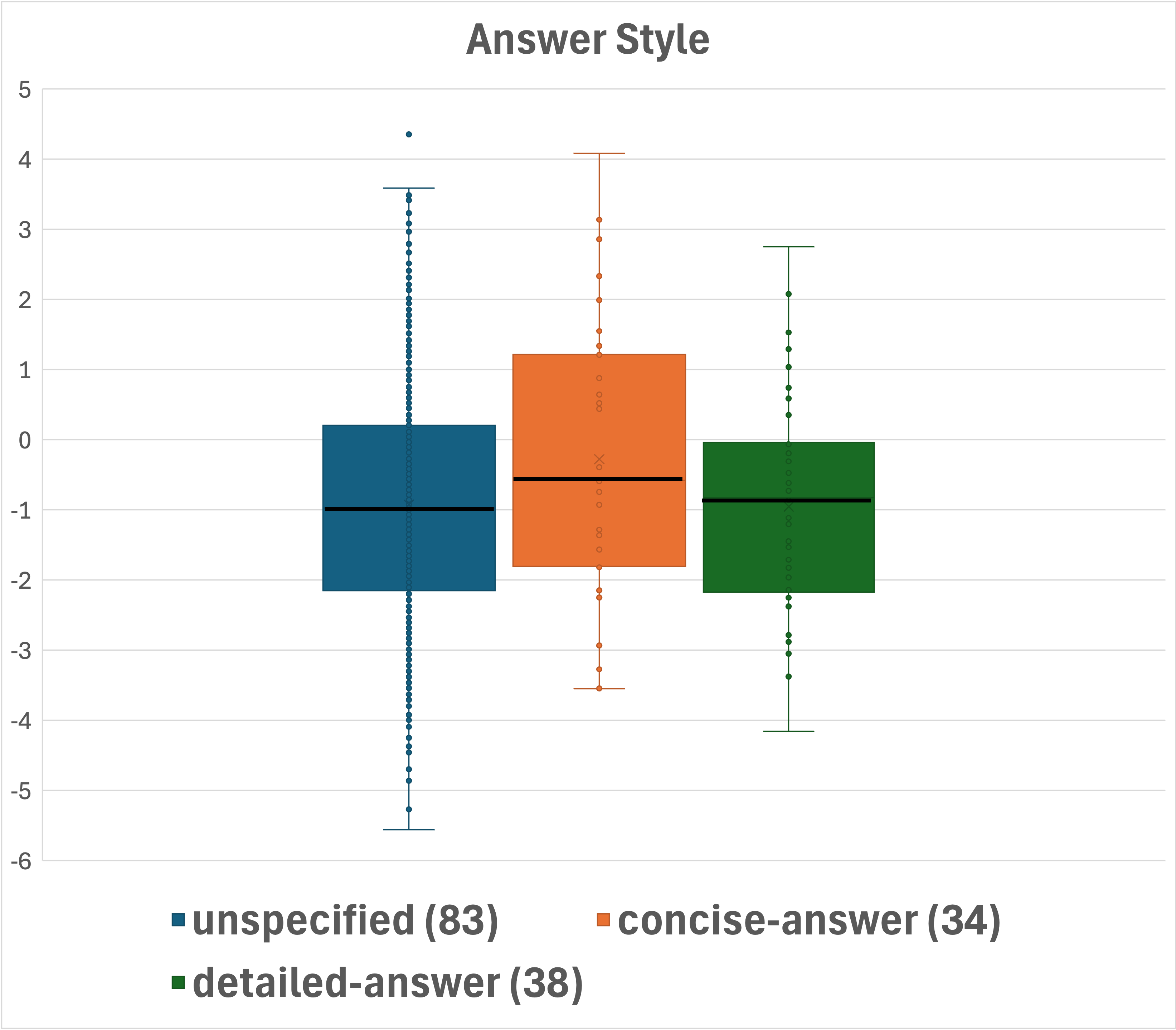
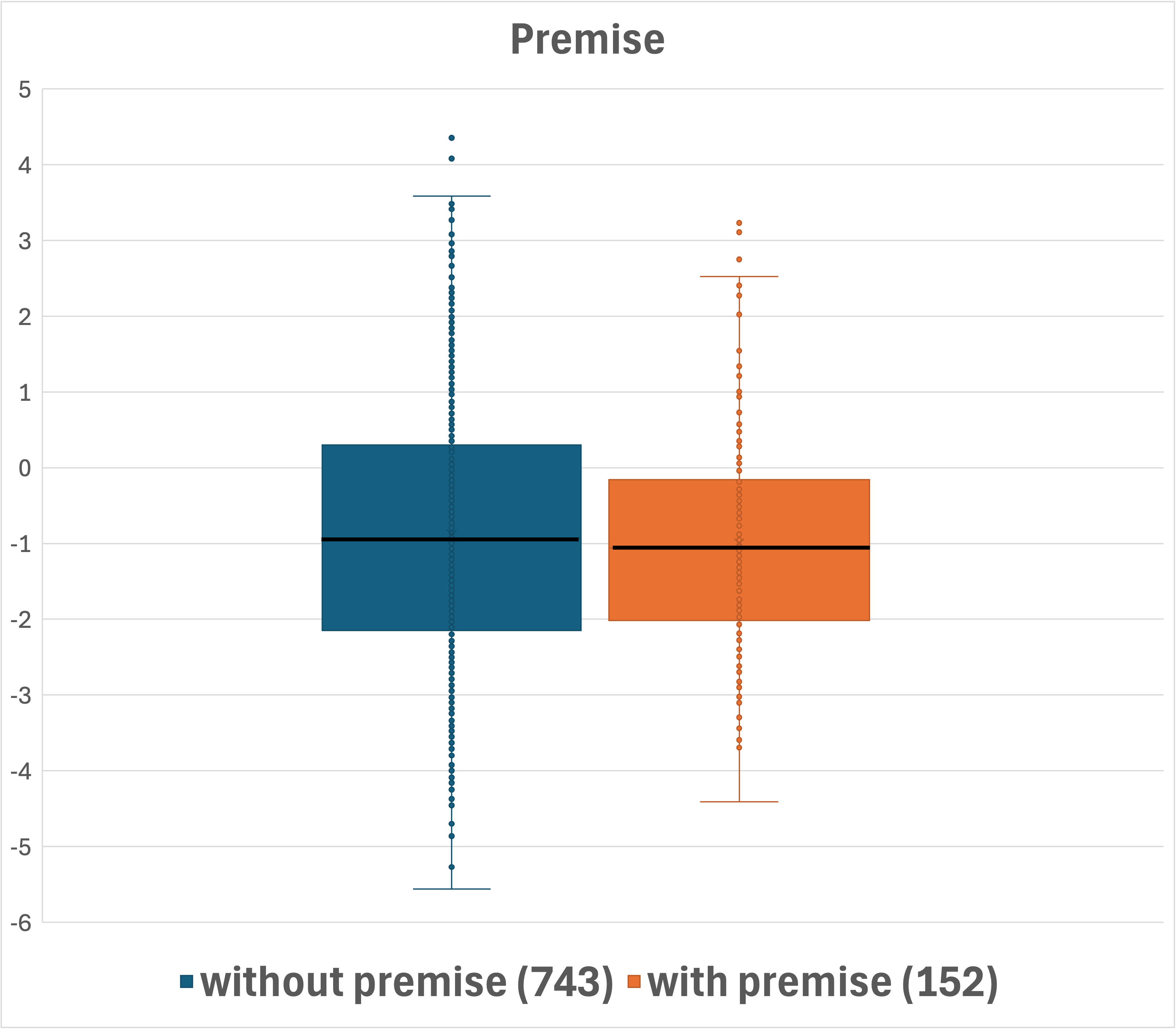
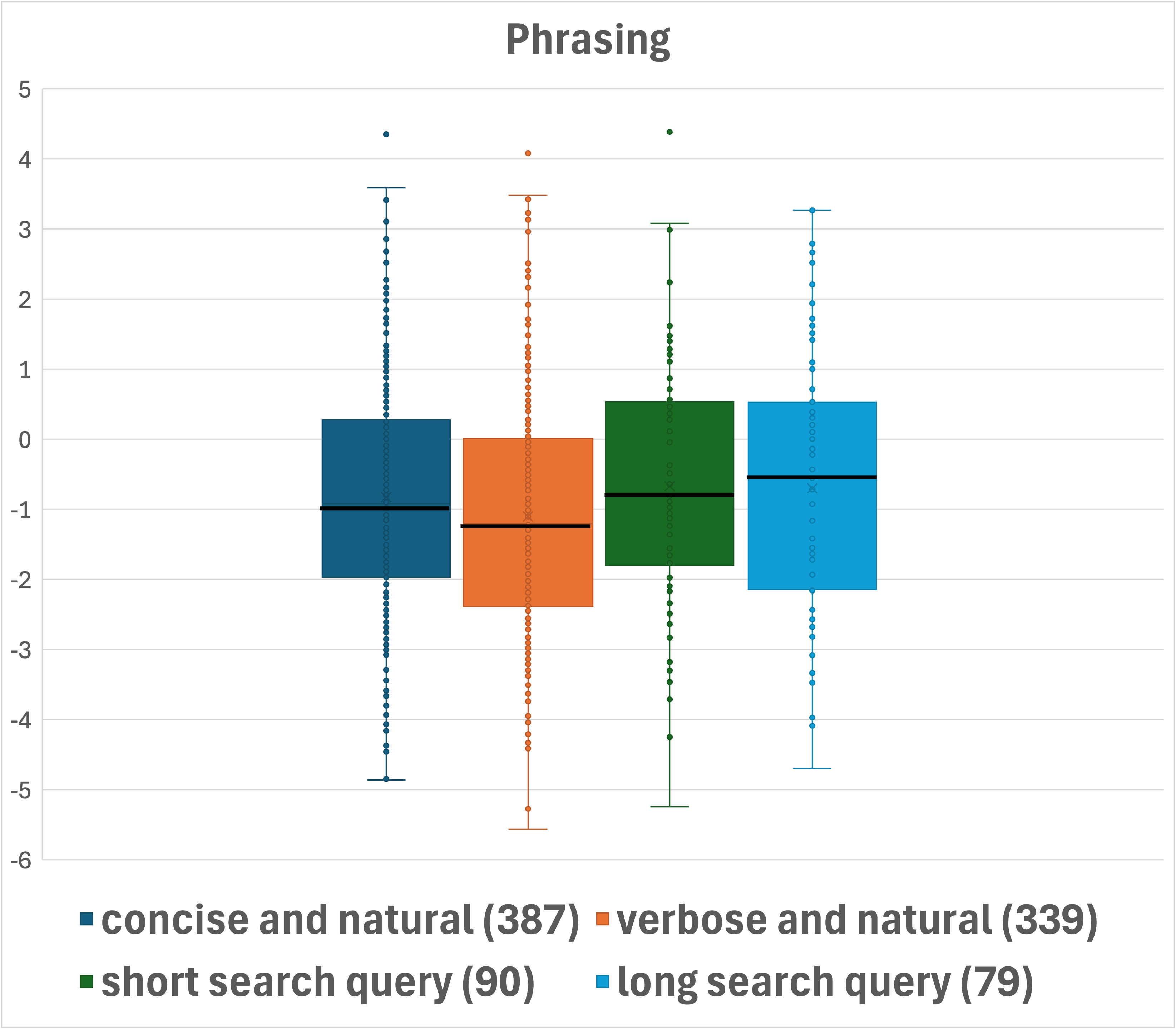
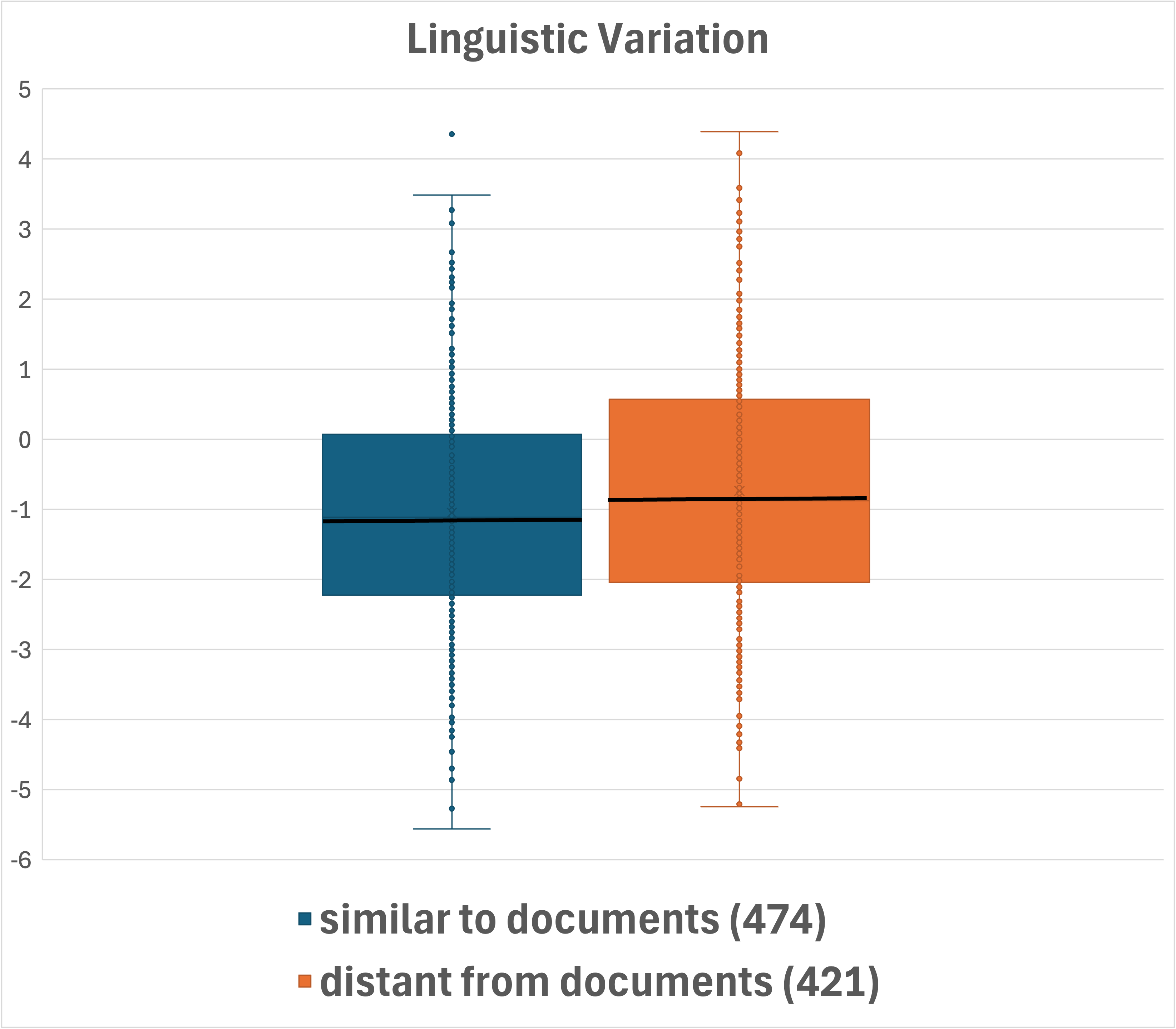
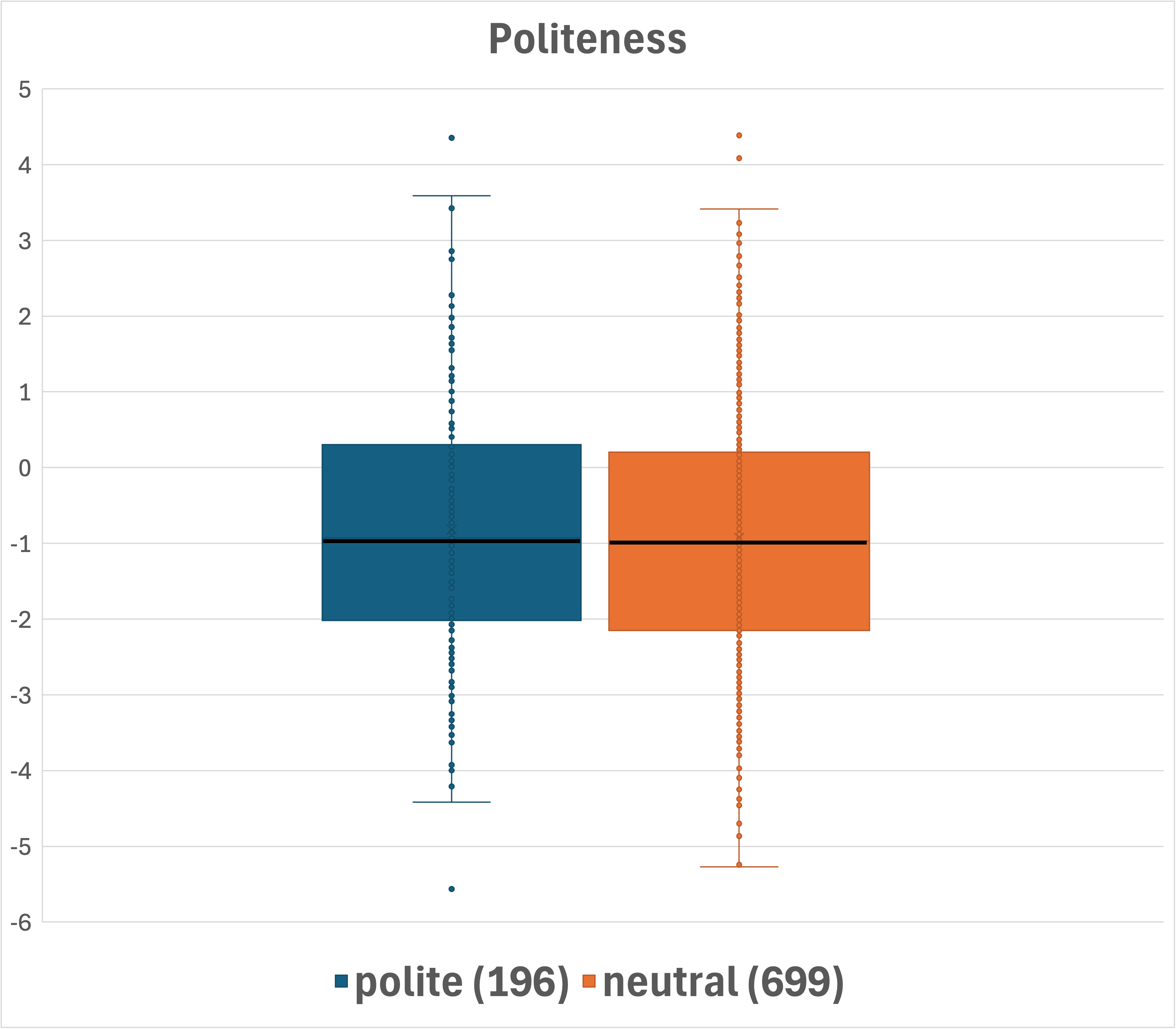

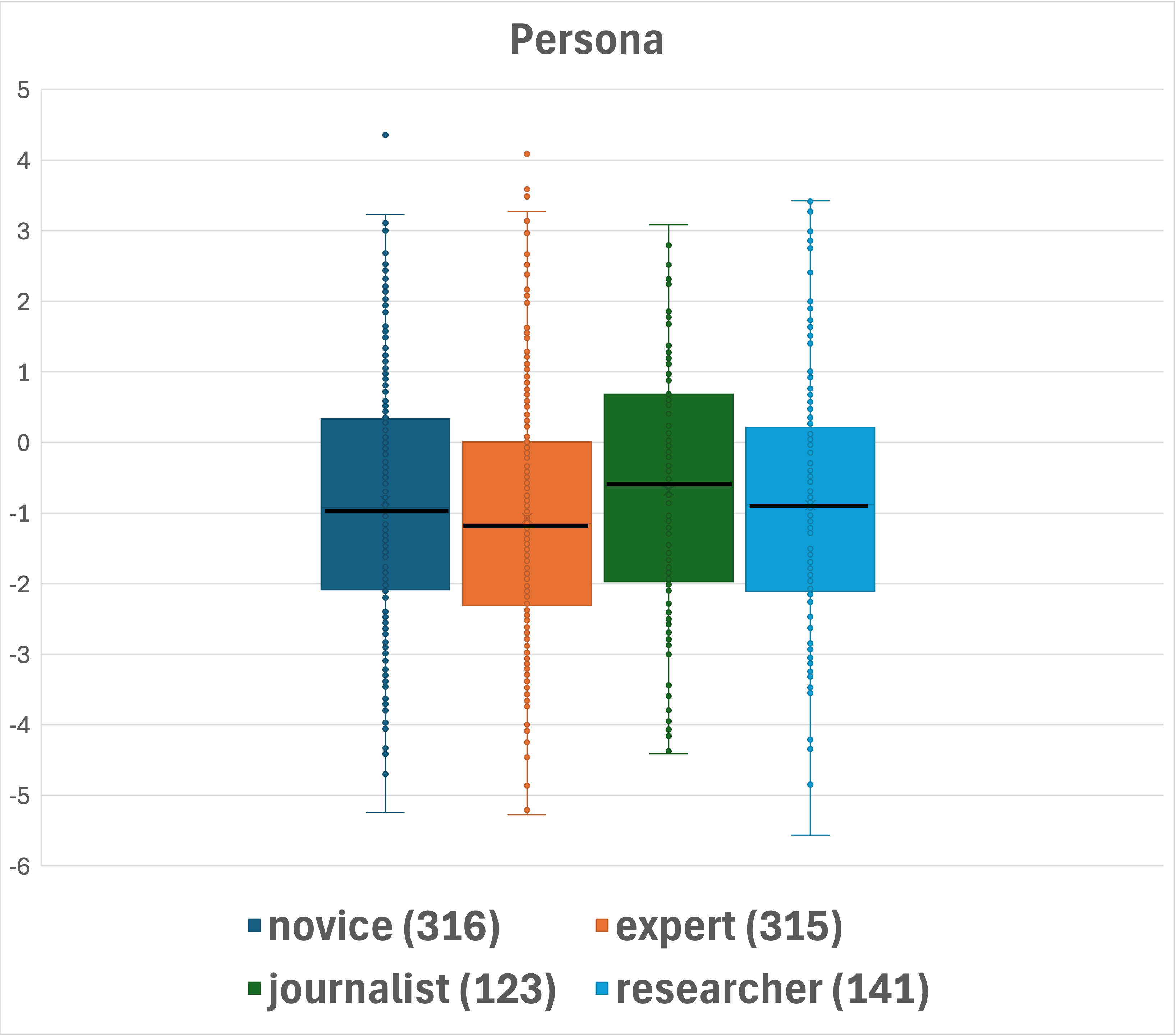
Figure 2: Box-plot presentation of the distributions across question categorizations. Median values are shown in bold. Number of questions per category is indicated in parentheses.
Difficulty Validation and Analysis
The dataset undergoes rigorous difficulty validation through its distribution analysis across predefined difficulty quartiles. Systems' performance consistency with difficulty levels validates IRT-derived scores as effective indicators of question challenge levels. The results highlight the indispensable nature of RAG for handling hard questions, emphasizing the challenges posed by complex inquiries requiring sophisticated reasoning and multiple document synthesis.
Implications and Limitations
While the LiveRAG benchmark is a significant advancement in RAG evaluation, it faces limitations such as the inherent biases introduced by using synthesized data. The dataset's synthetic nature may not fully replicate real-user inquiries, which could affect the conclusions drawn regarding system performance in real-world settings. The benchmark's reliance on a particular RAG model architecture during the challenge may also influence how difficulty is perceived.
Conclusion
LiveRAG sets a pioneering standard for RAG evaluation, providing a robust dataset designed to stimulate progress in QA system development. The paper underscores the importance of diverse and well-structured benchmarks, equipped with rigorous difficulty assessment metrics like those derived from IRT. It invites future exploration into further enhancing RAG methodologies and addressing existing challenges within the synthetic data landscape, promoting advancements in AI-driven question-answering capabilities.