- The paper presents ARC-Chapter, a scalable multimodal framework that generates fine-grained, hierarchical chapters for hour-long videos using integrated visual and ASR cues.
- It achieves state-of-the-art performance, outperforming competitors by up to +17.5 F1 and doubling SODA scores on benchmark datasets.
- The approach demonstrates strong transferability to downstream tasks, setting a new paradigm for fine-grained video structuring and robust summarization.
Motivation and Problem Statement
The increasing prevalence of hour-long video content in educational, entertainment, and professional contexts necessitates advanced methodologies for efficient structuring and summarization. Current solutions either lack scalability, are constrained to short video durations, or provide only coarse, non-descriptive chapter boundaries. Furthermore, standard benchmarks and evaluation metrics do not capture the granularity and semantic nuances critical for human-aligned chaptering in long-form videos, limiting both the development and assessment of robust models.
ARC-Chapter Framework and Dataset
ARC-Chapter addresses these limitations through a large-scale, bilingual (English-Chinese) annotation and training pipeline. The dataset, VidAtlas, comprises 410,000+ videos spanning 115,000+ hours, with a rich semantic and temporal diversity across domains (lectures, reviews, documentaries, tutorials, podcasts, etc). A novel semi-automatic pipeline extracts multimodal cues—visual frame captions (including OCR) and temporally aligned ASR—unifying them into a chronological transcript, which is processed by an LLM for dense, multilevel chapter annotations.
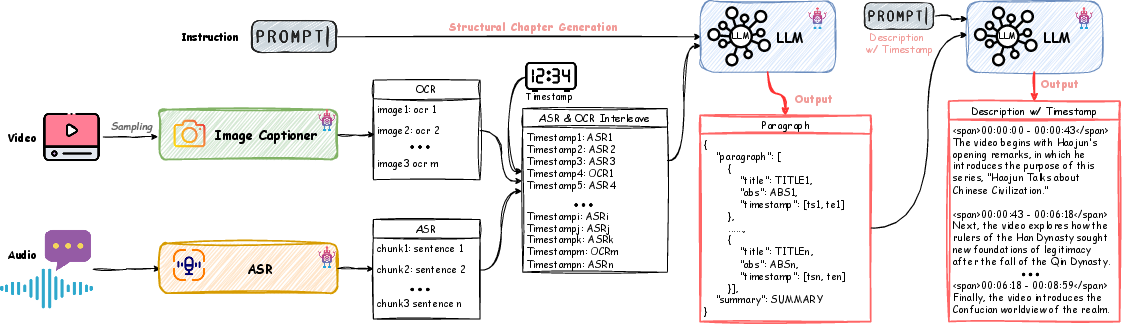
Figure 1: The multimodal annotation pipeline integrates OCR, visual captions, and ASR, generating hierarchical chapters and aligned narrative descriptions.
Each annotated chapter includes a concise short title, a detailed structural annotation (title, abstract, introduction), and a fine-grained timestamp-aligned video description, forming a hierarchical, information-dense ground truth.
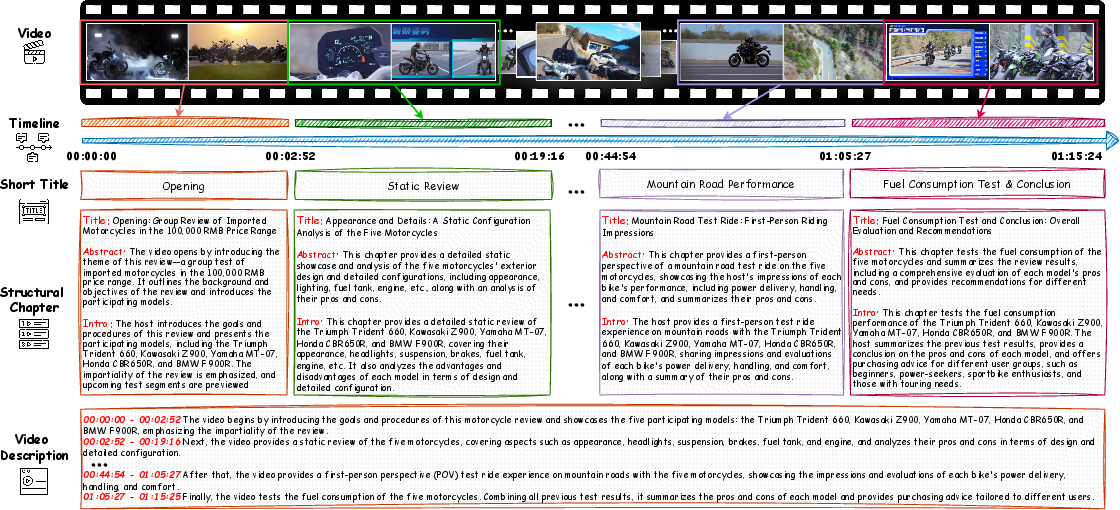
Figure 2: ARC-Chapter generates three-level outputs per chapter: Short Title, Structural Chapter, and timestamp-aligned description.
The duration and topic distributions reflect the dataset’s extensiveness, essential for model generalization and robustness over various video lengths and contents.
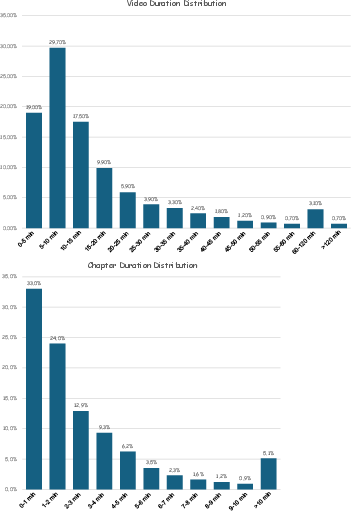
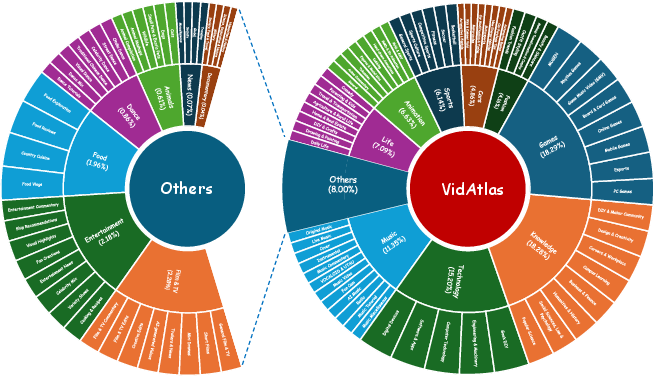
Figure 3: Distribution of video and chapter durations within the VidAtlas dataset.
Model Architecture
ARC-Chapter builds upon Qwen2.5-VL-7B with a fixed vision encoder to maximize context-window efficiency. The architecture integrates three key input streams:
- Task-specific textual prompt
- Temporally sampled video frames (up to 768, with dynamic frame-token allocation)
- Timestamp-aligned ASR transcripts
Inputs can flexibly include any subset (ASR-only, video-only, both), enabling robust deployment under limited modality conditions. Visual frames are encoded into tokens through Qwen2.5-VL’s vision module, while the ASR is injected as timestamped text. Adaptive modality dropping during training compels the model to leverage whichever modalities are available.
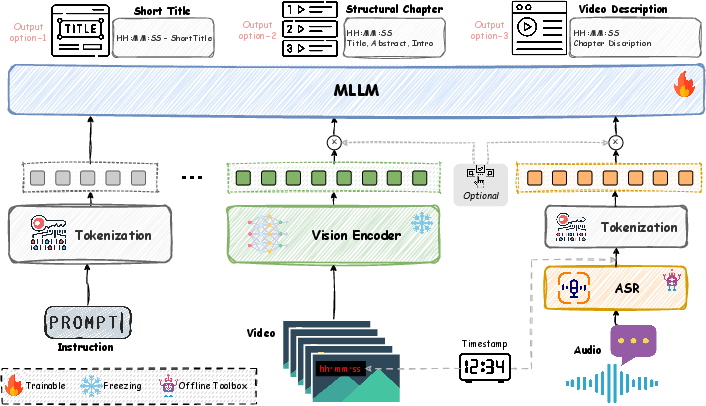
Figure 4: Schematic of ARC-Chapter's multimodal input integration and generation pipeline.
The model is instruction-tuned to generate outputs in three formats: short titles, structured chapters (title, abstract, intro), and dense timestamp-aligned descriptions. Supervised learning is performed with standard autoregressive loss, complemented by reinforcement learning with a granularity-robust temporal alignment reward.
Evaluation and Metrics
Standard event segmentation (F1, tIoU), dense video captioning metrics (CIDEr, SODA), and the newly proposed GRACE metric are used for comprehensive evaluation. Unlike SODA, which enforces one-to-one matching and penalizes annotation granularity discrepancies, GRACE adopts a many-to-one strategy, computing semantic and temporal consistency between set-matched chapter groupings, aligned via Dynamic Time Warping. This provides granularity-invariant and semantically robust assessment of both prediction quality and chapter boundary alignment.
Experimental Results
ARC-Chapter demonstrates clear state-of-the-art (SOTA) performance across multiple benchmarks:
Ablation studies confirm robust gains from hierarchical annotation and reinforcement learning (GRPO), with temporal precision improvements (F1, tIoU) not coming at the expense of semantic output quality (CIDEr, SODA, GRACE).
Transferability and Qualitative Analysis
Pretraining ARC-Chapter yields strong positive transfer to downstream dense video captioning tasks, achieving new SOTA on YouCook2 and ActivityNet Captions in both segmentation and captioning metrics.
Visualizations on challenging English and Chinese finance-related videos show the model’s capability to generate structurally consistent, contextually accurate hierarchical chapters and timestamped summaries in both languages.

Figure 6: Example outputs on an English finance/cryptocurrency video, demonstrating the clarity and informativeness of chapter and description generation.
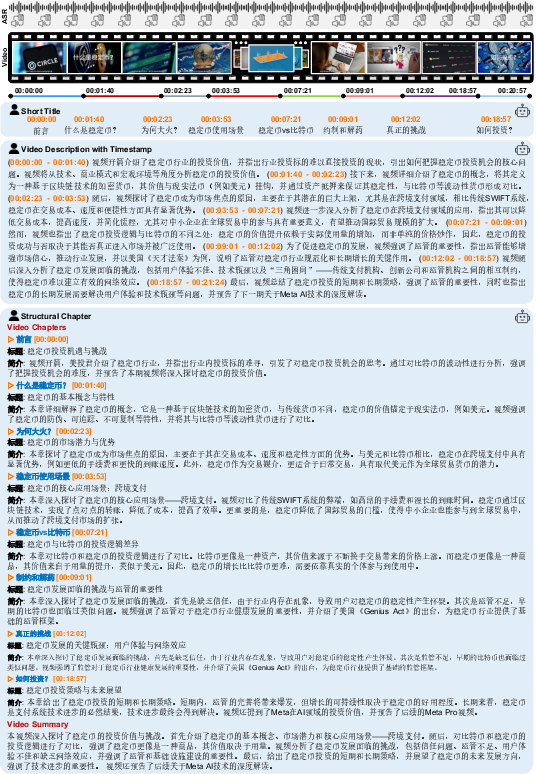
Figure 7: Multilingual generalization: hierarchical chaptering of a Chinese stablecoin discussion video.
Implications and Future Directions
ARC-Chapter establishes a new experimental paradigm for fine-grained, long-form video structuring by leveraging scalable multimodal data curation and robust hierarchical annotation. Its combination of architectural flexibility, versatile training objectives, and granularity-robust evaluation supports real-world deployment for content navigation, educational retrieval, and video summarization. Methodologically, the observed scaling law underscores the value of increasing both data volume and annotation intensity.
Potential future developments include expanding multilingual coverage, integrating specialized temporal compression for raw audio/visual signals, and extending the annotation pipeline for personalized content summarization. The granularity-robust evaluation framework (GRACE) could influence broader benchmarks in event localization and multimodal reasoning where annotation ambiguity and semantic alignment are critical.
Conclusion
ARC-Chapter advances the field of long-form video understanding through a scalable, hierarchically structured annotation and modeling framework. Empirical results across multiple benchmarks, languages, and output modalities confirm its superiority over prior methods. By demonstrating strong scaling behaviors and transferability, ARC-Chapter sets a new baseline for navigable chapter generation and hierarchical summarization of hour-long videos, paving the way for further research in multimodal temporal structuring and interactive content retrieval.


