Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
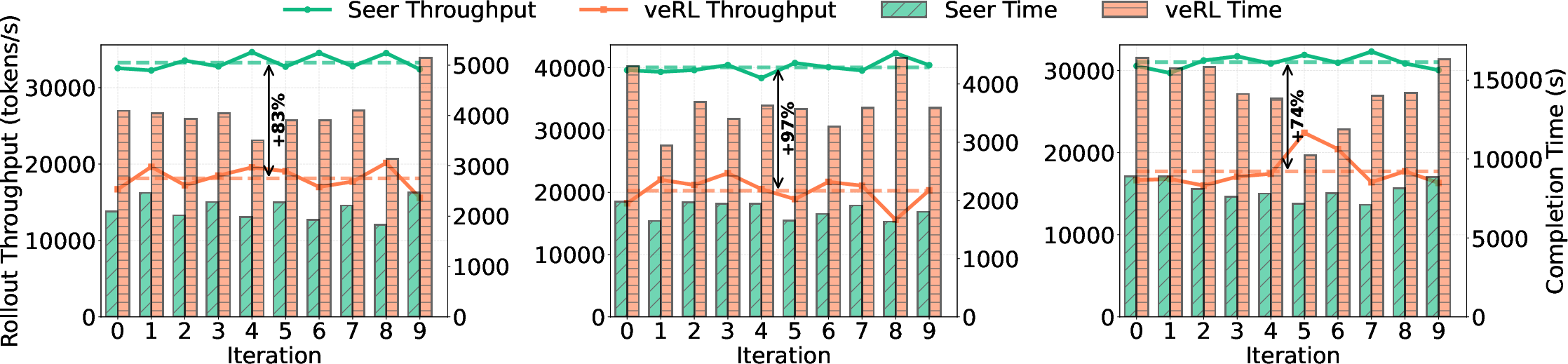
Abstract: Reinforcement Learning (RL) has become critical for advancing modern LLMs, yet existing synchronous RL systems face severe performance bottlenecks. The rollout phase, which dominates end-to-end iteration time, suffers from substantial long-tail latency and poor resource utilization due to inherent workload imbalance. We present Seer, a novel online context learning system that addresses these challenges by exploiting previously overlooked similarities in output lengths and generation patterns among requests sharing the same prompt. Seer introduces three key techniques: divided rollout for dynamic load balancing, context-aware scheduling, and adaptive grouped speculative decoding. Together, these mechanisms substantially reduce long-tail latency and improve resource efficiency during rollout. Evaluations on production-grade RL workloads demonstrate that Seer improves end-to-end rollout throughput by 74% to 97% and reduces long-tail latency by 75% to 93% compared to state-of-the-art synchronous RL systems, significantly accelerating RL training iterations.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces Seer, a system that makes a key part of training LLMs much faster. That key part is called the rollout phase, where the model writes many answers to many prompts so it can learn from them. Rollout is slow and wasteful today, especially when models write long, step‑by‑step explanations (“chain of thought”). Seer speeds this up by noticing patterns inside groups of answers that share the same prompt and by scheduling work more wisely.
What problem are they trying to solve?
In today’s LLM training with reinforcement learning (RL):
- Rollout takes the most time (often 63–87% of each training round).
- Some answers are very long—tens of thousands of tokens (think: lots of words and symbols). This causes:
- Memory trouble: long answers keep growing and can overflow GPU memory.
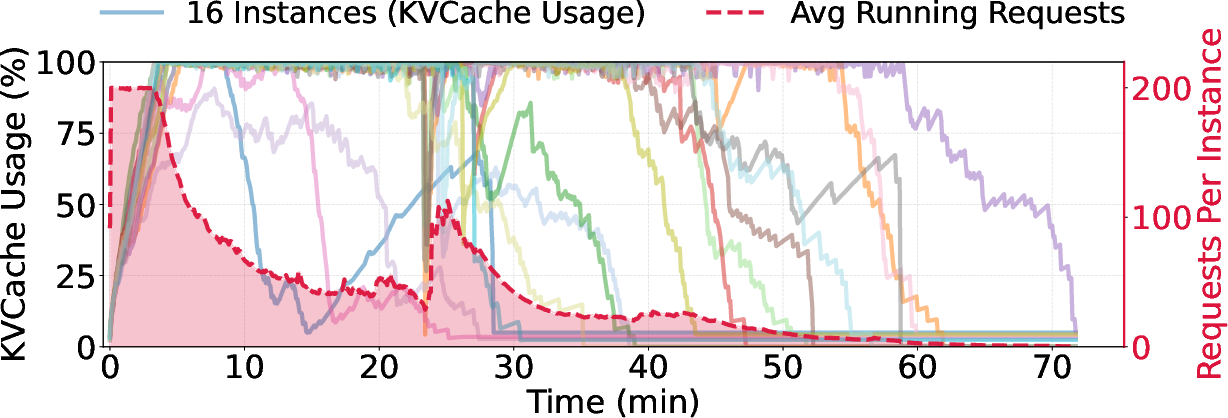
- The “long‑tail” problem: near the end, only a few very long answers are still running, leaving the expensive hardware mostly idle.
People tried running rollout and training at the same time (asynchronous RL) to hide the long tail, but that can make learning less reliable and harder to reproduce. So the authors focus on keeping training “on‑policy” and synchronous (more strict and dependable), while still making rollout fast.
What exact questions did they ask?
They set out to answer, in plain terms:
- Can we keep rollout strictly synchronized (no shortcuts) and still make it much faster?
- Can we reduce the long‑tail slowdown without breaking RL’s learning rules?
- Can we use similarities among answers to the same prompt to schedule work better and generate text faster?
How Seer works (with everyday analogies)
Seer speeds up rollout using three main ideas. To make them easy to digest, imagine a school with students (requests) doing projects (generations) in computer labs (GPU instances).
- Divided Rollout with a Global “Notebook”
- Analogy: Instead of forcing a student to finish their entire project in one sitting in the same lab, Seer lets the student work in small chunks and move between labs if another one is less busy.
- What this means:
- Requests are split into chunks (e.g., up to 8K tokens at a time).
- A shared “notebook” (called a global KVCache) stores what the model has already computed so nothing needs to be re‑done when a request moves. This “notebook” lives across machines (DRAM/SSD), so switching labs doesn’t mean starting over.
- Benefit: Better balancing across labs, fewer memory blowups, and less waiting.
- Context‑Aware Scheduling (smart ordering using a quick probe)
- Analogy: For each prompt group (say 8–16 answers to the same question), Seer runs one “probe” answer first to estimate how long the rest will take—like a teacher timing one student to guess how long the whole class needs.
- What this means:
- In GRPO‑style training, multiple answers are written for the same prompt. Those answers tend to be similar in length.
- Seer finishes short probes quickly and uses them to predict which groups are long.
- Then it schedules longer groups earlier (approximate “longest‑first”), mixing them with short ones to keep the labs full.
- Benefit: The end‑of‑round long tail shrinks because the longest work isn’t all left for last.
- Adaptive Grouped Speculative Decoding (fast drafting using shared patterns)
- Analogy: Students answering the same question often reuse similar phrases or steps. Seer builds a shared “phrase map” for each prompt group so it can guess several next words at once (draft), then quickly check and accept many of them in one go.
- What this means:
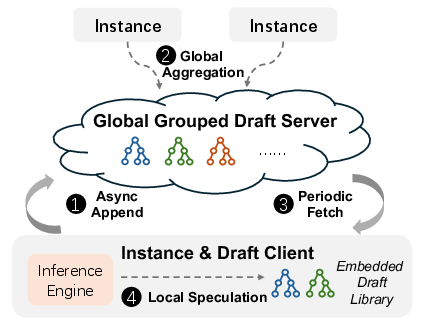
- Traditional “speculative decoding” drafts text using a small extra model—costly and quickly out‑of‑date during RL. Seer avoids that by using a model‑free pattern data structure called a compressed suffix tree (CST).
- A Distributed Grouped Draft Server collects token patterns from all answers in the same group and shares them with all labs. This becomes a live, lightweight “draft source” that matches what the main model is doing right now.
- It adapts draft length based on how busy the labs are and how well drafts are being accepted, and can explore multiple draft paths when helpful.
- Benefit: More tokens accepted per step, especially late in rollout when very long answers remain.
Key terms in simple words:
- Token: a small piece of text (part of a word, word, or symbol).
- KVCache: the model’s short‑term memory about what’s been written so far; it grows as the answer grows.
- Prefill: the model’s initial “read” of the prompt before it starts writing.
- Long‑tail: the slow, draggy end where just a few very long jobs are still running.
- Synchronous (on‑policy): training only uses data from the current model version—more reliable and easier to reproduce.
What did they find?
In tests on real RL workloads (reasoning tasks, including text and vision‑LLMs), Seer:
- Increased rollout throughput by 74% to 97% (more answers generated per unit time).
- Reduced long‑tail latency by 75% to 93% (finished the slowest, longest jobs much sooner).
Why that matters:
- Most of the training time was stuck in rollout, so these gains speed up the entire RL loop.
- Faster, cleaner rollout keeps training “on‑policy” and reproducible (good science), without needing risky shortcuts.
Why this is important and what it could change
- Faster learning cycles: Teams can run more RL iterations in less time, pushing models to reason better, faster.
- Lower costs: Better use of GPUs means less waste and smaller bills.
- More reliable science: Staying synchronous keeps experiments easier to debug and repeat.
- Better long‑form reasoning: By handling very long generations gracefully, Seer supports richer chain‑of‑thought training.
- Broad applicability: Although designed for strict synchronous RL, the same ideas (chunking, smart scheduling, grouped drafting) can also help asynchronous systems.
In short, Seer shows that we can make the slowest, most resource‑heavy part of LLM RL much faster—without bending the training rules—by learning from the context that’s already there: how answers in the same prompt group tend to be similar in length and in the patterns of tokens they use.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, actionable list of knowledge gaps and open questions the paper leaves unresolved. Each point highlights what is missing, uncertain, or unexplored and suggests specific directions for future work.
- End-to-end model quality: No evidence that Seer’s rollout acceleration preserves RL convergence and final policy quality across tasks and models. Evaluate downstream metrics (e.g., math/proof benchmarks, instruction-following, reward stability) against synchronous baselines at equal iteration budgets.
- Determinism and reproducibility: The paper claims “algorithmically lossless” synchronous RL, but does not show whether divided rollout, context-aware scheduling, and grouped speculation yield bitwise reproducible runs. Provide determinism tests under fixed seeds and varying cluster loads; document any nondeterminism sources (e.g., scheduling order, CST updates, multi-path drafts).
- Speculative decoding correctness under stochastic sampling: It is unclear how grouped CST-based drafts interact with non-greedy sampling (temperature, top-p) and whether acceptance is always validated against the target model logits. Formalize the acceptance check and prove that speculation does not alter the sampling distribution; quantify rejection-induced overheads.
- Generality beyond GRPO and grouping assumptions: Seer exploits groups sharing identical prompts (GRPO-like). Assess applicability to single-response RLHF/DPO, pairwise preference setups, or mixed prompts where G=1 or prompts differ. Characterize performance when group structure is absent or weak.
- Sensitivity to intra-group similarity: Length/pattern correlations may be weak for some prompts or models, reducing scheduler accuracy and speculation acceptance. Provide robustness analyses and fallback strategies (e.g., confidence-aware scheduling, disabling grouped speculation for low-similarity groups).
- Scheduling fairness and starvation risks: Approximate longest-first scheduling can starve short or mid-length groups. Define fairness guarantees, measure head-of-line blocking, and introduce bounded-delay or aging policies; analyze trade-offs between throughput and fairness.
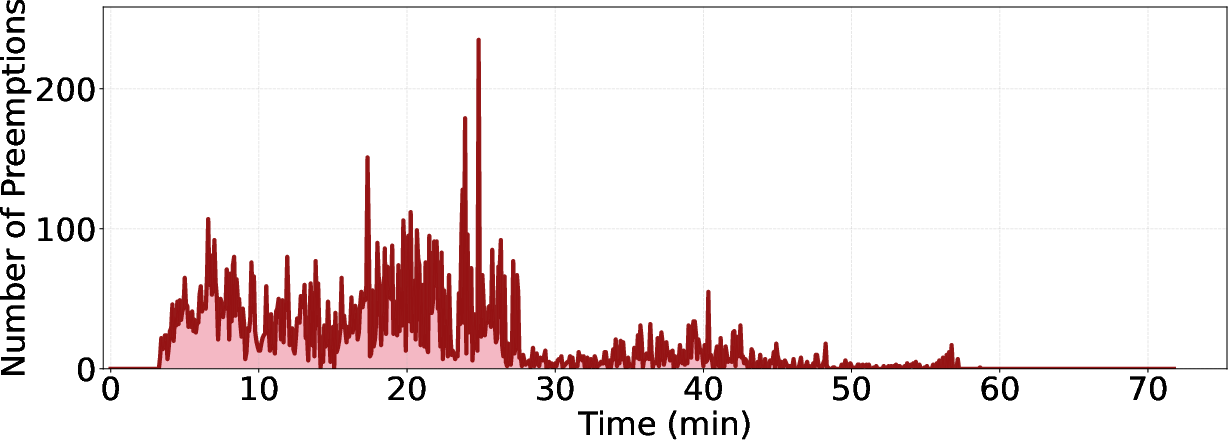
- Chunk size selection and tuning: Divided rollout uses fixed chunk sizes (e.g., 8K). System performance and preemption risk likely depend on chunk size, model architecture, and KV budget. Develop an adaptive chunk-size controller and report sensitivity curves.
- KVCache pool scalability and overheads: The global DRAM/SSD KVCache pool’s network traffic, SSD IO, prefetch hit rate, and tail latencies under large clusters (hundreds–thousands of GPUs) are not quantified. Measure bandwidth consumption, cache eviction policies, and performance under failures or congestion.
- Failure handling and consistency: The paper does not describe fault tolerance for DGDS or KVCache servers (e.g., token loss, CST corruption, partial cache eviction). Define recovery protocols, transactional semantics, and their impact on rollout throughput and correctness.
- Privacy and data isolation: Grouped CST aggregates token sequences across requests; in RL on user data, tokens may be sensitive. Investigate privacy risks (e.g., leakage via CST), add tenant isolation, encryption-at-rest/in-flight for KVCache/SSD, and opt-out mechanisms.
- Multi-modal applicability: Qwen2-VL-72B is multimodal, but the CST and grouped speculation focus on text tokens. Clarify support for image/video tokens, multi-modal KV segments, and whether speculation helps downstream text conditioned on visual inputs.
- Interaction with other decoding strategies: Study compatibility with diverse sampling strategies (top-k, top-p, temperature schedules, repetition penalties) and decoding variants (contrastive, guidance). Report acceptance rates and performance impacts per strategy.
- Adaptive speculative thresholds: The paper mentions pre-computed thresholds for dense vs MoE models but gives no method to derive/update them online. Develop a principled controller that uses real-time telemetry (acceptance length, load, batch shape) to set max_spec_tokens and multi-path k.
- CST growth management: No discussion of CST memory footprint, pruning, and incremental sync costs as G or group diversity increases. Measure CST size over time, propose pruning strategies (frequency-based, entropy-based), and bound sync overheads.
- Migration policy and prefetch accuracy: Dynamic sub-request migrations depend on KV usage telemetry and prefetching. Quantify misprediction costs (e.g., wasted prefetch, cold misses), define migration heuristics, and compare against learned or predictive policies.
- Memory footprint modeling: Provide a formal model or estimator of per-request VRAM usage under divided rollout (sequence length, batch size, architecture) to compute safe concurrency budgets and reduce preemption risk.
- Reward overlap implications: Reward computation is overlapped with rollout, but the paper does not confirm whether training strictly waits for all rewards (to remain on-policy). Specify synchronization barriers and verify the absence of distributional skew from early-arriving short samples.
- Comparison to strong asynchronous baselines: While focusing on synchronous RL, the paper does not quantify Seer’s quality/throughput trade-offs against state-of-the-art asynchronous systems under matched hardware and datasets. Provide head-to-head comparisons including final policy quality.
- Energy and cost efficiency: Throughput gains are reported, but energy consumption, CPU overheads (DGDS), and SSD wear are unmeasured. Report joules-per-token, total cost of ownership impacts, and amortized overheads.
- Hardware heterogeneity: Evaluate Seer across accelerators (A100, H100, Gaudi, TPU) and model families (dense, MoE with variable expert counts), including NUMA effects and interconnect differences affecting KVCache pool and DGDS performance.
- Extremely long sequences edge cases: For outputs near ~100K tokens, divided rollout introduces many chunk boundaries. Quantify scheduling overheads, CST utility at long horizons, and whether acceptance rates degrade; explore hierarchical chunking or late-stage specialized policies.
- Cross-iteration context reuse: Investigate whether CSTs or length predictors can be safely reused across iterations or curriculum stages without off-policy contamination; quantify drift and acceptance collapse across weight updates.
- Security and compliance for KVCache on SSD: KVCache persistence on SSD can contain sensitive content. Document data retention policies, encryption keys, secure deletion, and auditability to meet compliance requirements.
- Synergy with prefix-caching/fused attention systems: Explore integration with prefix sharing (e.g., SGLang, Mooncake) beyond KVCache reuse, including template-aware batching or fused attention kernels, and quantify cumulative gains.
- Evaluation completeness: The paper cites 74–97% throughput gains and 75–93% long-tail reductions but lacks detailed workload specs (prompt distribution, output length profiles), acceptance rate curves, and per-component ablations (divided rollout vs scheduling vs DGDS) across diverse tasks.
- Theoretical underpinnings of length correlation: Formalize and test statistical models explaining intra-group length correlation; develop predictive models that generalize across prompts and models, and integrate them into the scheduler.
- Practical deployment guidance: Provide recipes for parameter defaults, monitoring signals, and alert thresholds (e.g., acceptance-length plateau, KVCache pressure), plus playbooks for switching modes (disable DGDS, adjust chunking) when signals indicate degraded similarity or overload.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage Seer’s techniques (divided rollout, context‑aware scheduling, and adaptive grouped speculative decoding) to improve end-to-end efficiency in synchronous LLM RL workflows.
- Sector: AI infrastructure (industry R&D labs, model providers)
- Use case: Accelerate synchronous RL training of reasoning LLMs (e.g., GRPO/GRPO-like training with chain-of-thought, code, math, or multimodal reasoning).
- Tools/products/workflows:
- “Seer Rollout Orchestrator” integrated into existing stacks using vLLM/Megatron/TRL/DeepSpeed-Chat.
- Request Buffer with chunked
max_tokensexecution to prevent preemptions and stabilize VRAM usage. - Global KVCache Pool (DRAM/SSD-backed) for cross-instance KV reuse and zero re-prefill migration.
- Context Manager for online length estimation and approximate longest-first scheduling.
- Distributed Grouped Draft Server (DGDS) with Compressed Suffix Trees for pattern-aware speculative decoding; multi-path drafting for long-tail acceleration.
- Impact: 74–97% rollout throughput gains and 75–93% long-tail latency reduction (paper’s reported results), allowing faster policy iteration without sacrificing on-policy fidelity.
- Assumptions/dependencies:
- Grouped sampling is used (e.g., GRPO with G ≥ 8); same-prompt groups produce length/pattern similarities.
- Inference engine support for KV migration and chunked decoding (e.g., vLLM + extensions).
- Sufficient interconnect and storage bandwidth (high-throughput networks; DRAM/SSD tiering).
- Workloads feature long, variable-length generations; benefits shrink for consistently short outputs.
- Sector: Cloud providers and MLOps platforms
- Use case: Managed synchronous RL training service with reduced GPU-hours per experiment.
- Tools/products/workflows:
- Turnkey “KVCache Pool” microservice for clusters (with prefetch and release).
- Seer-aware scheduler plug-ins for Kubernetes/Ray/SLURM to balance memory and long-tail load.
- DGDS as a multi-tenant, sharded service keyed by job/group ID (job-scoped context).
- Impact: Higher accelerator utilization, reduced iteration time, lower cost per policy update, and improved carbon efficiency.
- Assumptions/dependencies:
- Job-scoped grouping and isolation; no cross-job token sharing to avoid privacy issues.
- Operator support for node telemetry (KV usage, concurrency) and co-scheduling rollout with reward servers.
- Sector: Academia and open research
- Use case: Faster, reproducible on-policy RL experiments and ablation studies at lower cost.
- Tools/products/workflows:
- Drop-in orchestration for campus clusters; reduced preemptions and faster long-tail completion.
- Deterministic rollout order and on-policy compliance, easing debugging and reproducibility.
- Impact: More experiments per budget, improved iteration cadence for method development.
- Assumptions/dependencies:
- Availability of modest DRAM/SSD for KV pooling and cluster networking with adequate throughput.
- Sector: Synthetic data generation and evaluation pipelines (industry/academia)
- Use case: Speed up multi-sample per prompt generation (self-consistency, bootstrapping datasets, multi-beam evaluation).
- Tools/products/workflows:
- Repurpose divided rollout and DGDS for batched offline inference where multiple candidates per prompt are needed.
- Impact: Higher throughput for large batch jobs (e.g., generating many CoTs per prompt or multiple rubric-constrained outputs).
- Assumptions/dependencies:
- Prompts are repeated with multiple samples; grouped pattern similarity holds. Benefits diminish for highly diverse, one-off prompts.
- Sector: Multimodal model training (vision-language, robotics simulators with language components)
- Use case: Accelerate synchronous RL for VLMs (e.g., Qwen2-VL-72B-style workloads) where outputs are long and variable.
- Tools/products/workflows:
- Same Seer components; DGDS operates over tokenized multimodal outputs (text tokens).
- Impact: More stable and faster rollout for vision-language reasoning tasks.
- Assumptions/dependencies:
- Tokenization pipeline for multimodal tokens is compatible with CST-based speculation; long reasoning traces are prevalent.
- Sector: Energy/cost management (Ops/FinOps)
- Use case: Reduce GPU-hours and energy bills for RL training programs, with better cluster utilization.
- Tools/products/workflows:
- Seer telemetry for cost and energy dashboards; proactive long-tail mitigation to minimize idle accelerators.
- Impact: Immediate cost savings and improved sustainability metrics.
- Assumptions/dependencies:
- Accurate cluster telemetry; integration with existing cost accounting systems.
Long-Term Applications
These opportunities require additional research, engineering, or safeguards (e.g., privacy, hardware co-design, or extending beyond grouped RL).
- Sector: Online inference and serving (software/consumer products)
- Use case: Group-aware speculative decoding for production inference with repeated templates (forms, code refactoring, structured QA) to reduce latency/cost.
- Tools/products/workflows:
- “Privacy-preserving DGDS”: job- or tenant-scoped pattern servers; differential privacy or per-tenant isolation.
- Inference engines offering chunk-based scheduling and KV migration for long outputs (e.g., long CoT explanations on demand).
- Impact: Latency/cost reductions in high-volume, template-heavy services.
- Assumptions/dependencies:
- Strong privacy and isolation guarantees; similarity across requests is sufficiently high.
- Serving SLOs are compatible with chunking/migration; careful QoS management.
- Sector: Hardware–software co-design (accelerators, systems vendors)
- Use case: Native hardware support for global KV pooling, cross-GPU KV migration, and speculation primitives.
- Tools/products/workflows:
- NIC offload for KV transfers; device-level KV tiering; hardware-accelerated CST traversal.
- Impact: Lower overhead for migration/speculation; broader adoption at scale.
- Assumptions/dependencies:
- Vendor support; standardization of KV formats and migration APIs across inference engines.
- Sector: Generalization beyond GRPO and beyond RL
- Use case: Apply divided rollout and context-aware scheduling to:
- Other grouped sampling regimes (e.g., best-of-N decoding, self-consistency in reasoning).
- Multi-agent rollouts and hierarchical planners that produce multiple trajectories per scenario.
- Long-horizon generative pipelines (e.g., multi-step tool use or program synthesis traces).
- Tools/products/workflows:
- “Grouped Context Server” abstracting from GRPO to any multi-sample-per-input workflow.
- Impact: Systematic speedups in a wider set of long-sequence generation tasks.
- Assumptions/dependencies:
- Persistence of length/pattern correlations in the new domains; adaptation of CST and scheduling heuristics.
- Sector: Cluster autoscaling and capacity planning (cloud/MLOps)
- Use case: Provisioning controllers that forecast remaining rollout work via online length estimates; energy-aware scheduling of long-tail phases to off-peak hours.
- Tools/products/workflows:
- “Seer-Aware Autoscaler” using estimated remaining tokens/KV footprints to drive pod/gpu allocations and time-shift workloads.
- Impact: Reduced cost, better SLA adherence for multi-experiment fleets.
- Assumptions/dependencies:
- Stable forecasting from early probes; integration with cluster schedulers and billing windows.
- Sector: Policy, compliance, and auditing
- Use case: Standardized, reproducible on-policy RL runs with auditable logs for rollout scheduling, KV migrations, and speculation decisions.
- Tools/products/workflows:
- “Rollout Provenance Logs” capturing scheduling and speculative acceptance trails; replay tools for regulators and third-party auditors.
- Impact: Stronger reproducibility claims and easier compliance in safety-critical domains.
- Assumptions/dependencies:
- Community/industry agreement on logging standards; privacy filters for any token sharing within a job.
- Sector: Education and democratization of RL
- Use case: “Seer-in-a-box” for teaching labs, enabling affordable synchronous RL training on small clusters.
- Tools/products/workflows:
- Prepackaged KVCache pool and DGDS containers; simplified installers for campus clusters.
- Impact: Lower barrier to hands-on RL research and coursework.
- Assumptions/dependencies:
- Simplified defaults for small-scale hardware; documentation and community support.
- Sector: Domain-specific RL in finance/healthcare/enterprise
- Use case: Faster, on-policy domain fine-tuning under strict reproducibility and traceability constraints (e.g., risk analyses, coding assistants with compliance).
- Tools/products/workflows:
- Job-scoped grouped speculation; audit-ready rollout orchestrators; integration with domain reward models (LLM-as-a-Judge, sandbox evaluators).
- Impact: Shorter iteration cycles for domain updates, with preserved methodological rigor.
- Assumptions/dependencies:
- Strong isolation; domain prompts yield meaningful length/pattern correlations; governance approval.
- Sector: Robotics and embodied AI
- Use case: Apply divided rollout and grouped speculation to long-horizon language-plan rollouts in simulators (multiple trajectories per scene).
- Tools/products/workflows:
- Integration with simulator farms; per-scenario grouped context for plan token streams.
- Impact: Faster data generation loops for policy training and evaluation.
- Assumptions/dependencies:
- Sufficient similarity across trajectories in a scenario; compatibility with hybrid vision-language tokens.
Notes across applications:
- Feasibility improves with long and variable-length generations (chain-of-thought, program traces, multi-turn plans). Gains diminish for uniformly short outputs or highly diverse, creative generations with weak pattern overlap.
- Networking and storage are first-class dependencies (for KV pooling and CST syncing). RDMA/NVLink-class interconnects and SSD endurance planning mitigate bottlenecks and wear.
- Privacy and isolation are vital if extending grouped context beyond a single job or tenant; most immediate deployments should constrain DGDS to per-job scope.
Glossary
- Adaptive Grouped Speculative Decoding: A rollout acceleration technique that adjusts draft lengths based on system load and uses shared group context to improve acceptance rates. "Seer employs Adaptive Grouped Speculative Decoding (\S\ref{sec:speculative_decoding})"
- Advantage: In reinforcement learning, a normalized measure of how much better a sampled action is compared to the group average; used for policy gradient updates. "normalize these rewards within the group to compute the advantages "
- Asynchronous RL: Reinforcement learning that overlaps rollout and training, allowing training on data from older policy versions (off-policy). "have proposed asynchronous RL"
- Chain-of-Thought (CoT): A prompting and generation approach where models produce step-by-step reasoning to solve complex tasks. "complex chain-of-thought (CoT) reasoning"
- Clipped ratio loss: A PPO-style objective that clips the probability ratio to stabilize policy updates. "update the policy with a clipped ratio loss and KL regularization toward a reference model "
- Compressed Suffix Tree (CST): A compact index over token sequences enabling fast pattern lookups for speculation. "maintains a Compressed Suffix Tree~\cite{weiner1973linear} (CST) for each group"
- Context-Aware Scheduling: A scheduling policy that uses online length estimates from speculative requests to prioritize longer groups and minimize tail latency. "Seer implements Context-Aware Scheduling (\S\ref{sec:context_aware_scheduling})"
- Divided Rollout: A mechanism that splits requests into smaller chunks for dynamic load balancing and stable memory usage. "Seer introduces Divided Rollout (\S\ref{sec:divided_rollout})"
- Distributed Grouped Draft Server (DGDS): A distributed service that aggregates grouped token patterns via CSTs to supply high-quality draft tokens to all instances. "Seer deploys a Distributed Grouped Draft Server (DGDS) that maintains a Compressed Suffix Tree~\cite{weiner1973linear} (CST) for each group"
- Draft model: An auxiliary generator used in speculative decoding to propose candidate tokens before verification by the target model. "draft models obtained through distillation or incremental fine-tuning struggle to adapt to continuously evolving target models"
- Global KVCache Pool: A distributed DRAM/SSD-backed store of attention key/value states shared across instances to avoid recomputation and enable migration. "Seer leverages the Global KVCache Pool to enable efficient divided rollout."
- Group Relative Policy Optimization (GRPO): A group-based preference optimization method for LLMs that normalizes rewards within prompt groups, obviating a critic network. "the most widely adopted algorithm is Group Relative Policy Optimization~\cite{guo2025deepseek} (GRPO)."
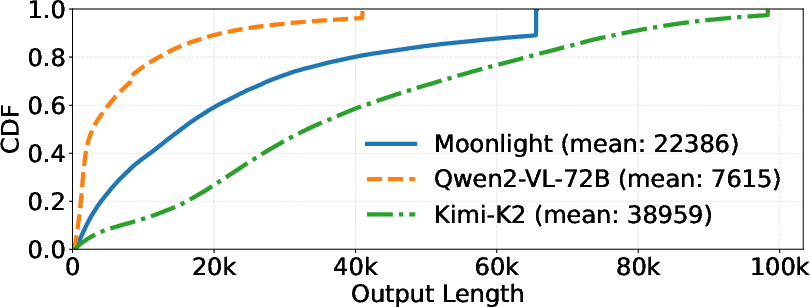
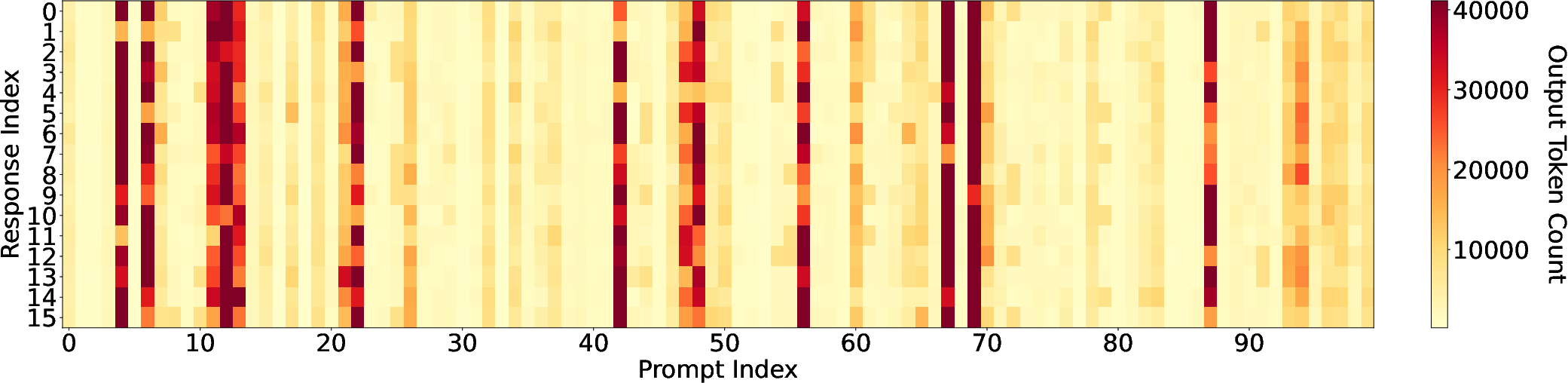
- Heavy-tailed length distribution: A distribution where a small fraction of requests have extremely long outputs, causing load imbalance and latency. "These long-generation requests inherently create a heavy-tailed length distribution"
- KL regularization (Kullback–Leibler): A penalty guiding the learned policy toward a reference policy to stabilize training. "update the policy with a clipped ratio loss and KL regularization toward a reference model "
- KVCache: The transformer attention key/value state cache used to avoid recomputing past tokens during decoding. "the KVCache can occupy several gigabytes of memory."
- LLM-as-a-Judge: A reward modeling approach that uses an LLM to evaluate generated responses during RL training. "using the LLM-as-a-Judge~\cite{son2024llm} reward model."
- Longest-job-first (LFS) scheduling: A policy that prioritizes longer tasks to reduce tail latency and improve batch density. "implement an approximate longest-job-first policy"
- Mixture-of-Experts (MoE) model: A neural architecture that routes tokens to specialized expert sub-networks to improve efficiency and capacity. "such as dense and Mixture-of-Experts (MoE) models"
- Model-based speculative decoding: Speculation that relies on a separate draft model to propose tokens prior to verification. "Model-based SD approaches face key limitations in RL scenarios due to their static draft models and substantial overhead."
- Model drift: The divergence of a target model over training iterations, making previously trained draft models less predictive. "causing rapid \"model drift\""
- Model-free speculative decoding: Speculation using pattern matching (e.g., n-grams) rather than a dedicated draft model. "For model-free SD methods, n-gram-based approaches~\cite{fu2024break,vllm2025} are commonly employed."
- Multi-path speculative decoding: Generating multiple candidate draft sequences per step to improve acceptance length. "We also implement multi-path speculative decoding to further improve the acceptance length in the long-tail stage."
- N-gram speculative decoding: A speculative method that proposes tokens by matching n-gram patterns from existing sequences. "simulated n-gram speculative decoding using compressed suffix trees (CSTs)."
- Off-policy learning: Training a policy with data generated by a different (older) policy, potentially affecting stability and fidelity. "these systems introduce a degree of off-policy learning"
- On-policy rollout: Synchronous data generation where training uses experiences from the current policy only. "synchronous (or \"on-policy\") rollout remains critical"
- Prefill recomputation: Recomputing the initial attention states (prefill) after preemption or migration, incurring extra latency. "eliminates the expensive overhead of prefill recomputation."
- Shortest-first scheduling (SFS): Prioritizing requests with the smallest generated length to quickly surface long-tail tasks. "shortest-first scheduling (SFS) approach"
- Speculative decoding (SD): A technique to accelerate decoding by drafting candidate tokens and verifying them with the main model. "Speculative decoding~\cite{leviathan2023fast} (SD) presents another promising direction for accelerating memory-bound generation."
- Tree-based drafting: A speculative strategy that builds a tree of token candidates (e.g., beam-like paths) for verification. "a variant of tree-based drafting~\cite{wang2025opt}."
Collections
Sign up for free to add this paper to one or more collections.

