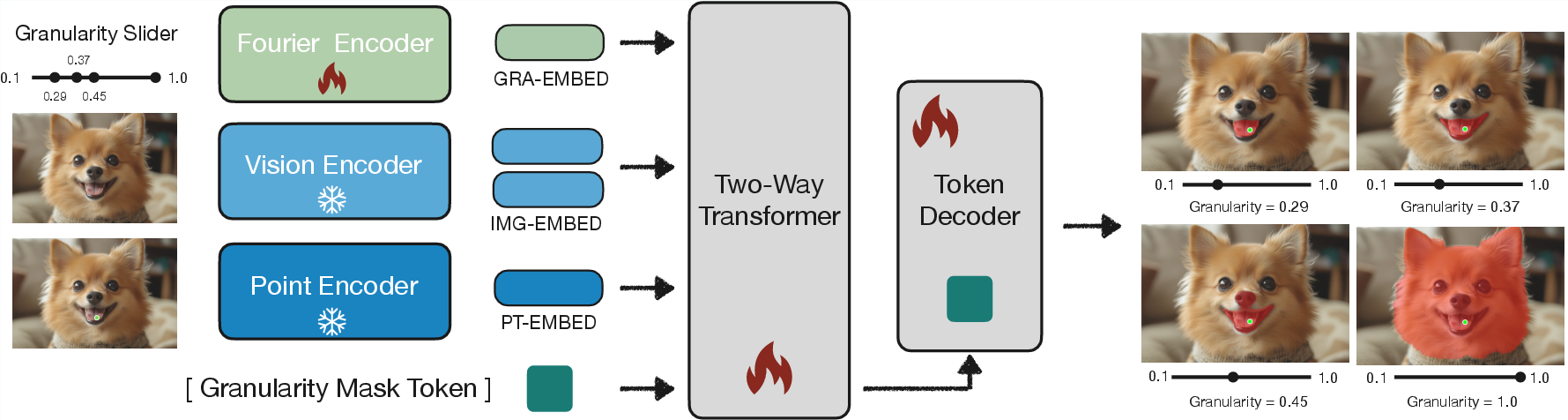
- The paper introduces a self-supervised, granularity-aware segmentation pipeline that enables precise, continuous control over mask outputs.
- It employs a Fourier-based granularity encoder and a learnable mask token to decode segmentation masks at arbitrary scales with minimal extra parameters.
- The method achieves state-of-the-art performance in interactive, whole-image, and video segmentation, notably surpassing SAM-2 benchmarks across 11 datasets.
UnSAMv2: Self-Supervised Learning Enables Segment Anything at Any Granularity
Overview and Motivation
UnSAMv2 addresses a fundamental gap in vision foundation models by enabling precise, continuous control over segmentation granularity without reliance on human annotations. Existing paradigms, especially those in the SAM (Segment Anything Model) family, are constrained by discrete, annotation-biased object definitions, yielding three candidate masks per user prompt and lacking hierarchical reasoning capabilities. UnSAMv2 challenges these constraints via a fully self-supervised pipeline that generates rich, continuous mask-granularity pairs, training a granularity-controllable segmentation model that generalizes across interactive, whole-image, and video segmentation tasks.

Figure 1: Segmentation results at various granularity.
Methodology
Granularity-Aware Divide-and-Conquer Pipeline
Central to UnSAMv2 is an unsupervised, hierarchical pseudo-label generation pipeline:
- Instance Discovery via Normalized Cuts: Using MaskCut, instance-level masks are extracted based on patch-wise feature similarity and confidence thresholds.
- Instance-Part Relationship Identification: Overlapping masks are partitioned into instance and part-level masks by area and IoU constraints, establishing a hierarchical structure.
- Fine-Grained Part Extraction: Instance masks are further decomposed into finer parts via patch merging, increasing mask diversity and granularity spectrum.
- Continuous Granularity Score Assignment: Each discovered mask is mapped to a scalar g∈[0.1,1.0] reflecting its relative scale in the mask hierarchy. This granularity assignment is relational, not absolute, aligning with hierarchical perception theories in human vision and cognition.
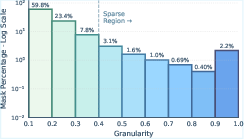
Figure 2: Granularity distribution of discovered masks—UnSAMv2's hierarchy construction is left-tailed, rich in fine-grained structures.
Model Architecture
UnSAMv2 extends SAM-2 via two architectural innovations:
The encoder introduces less than 0.02% extra parameters, preserving scalability and efficiency.
Results
Interactive Segmentation
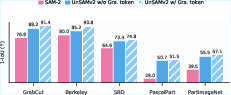
UnSAMv2 is trained with only 6,000 unlabeled images in 8 GPU hours (A100). It surpasses SAM-2 and prior SOTA methods across 11 benchmarks on all metrics:
- NoC90: 4.75 (vs. 5.69 SAM-2)
- 1-IoU: 73.1 (vs. 58.0 SAM-2)
- AR1000: 68.3 (vs. 49.6 SAM)
These results indicate strong improvements in both segmentation accuracy and efficiency, especially in part-level object segmentation.
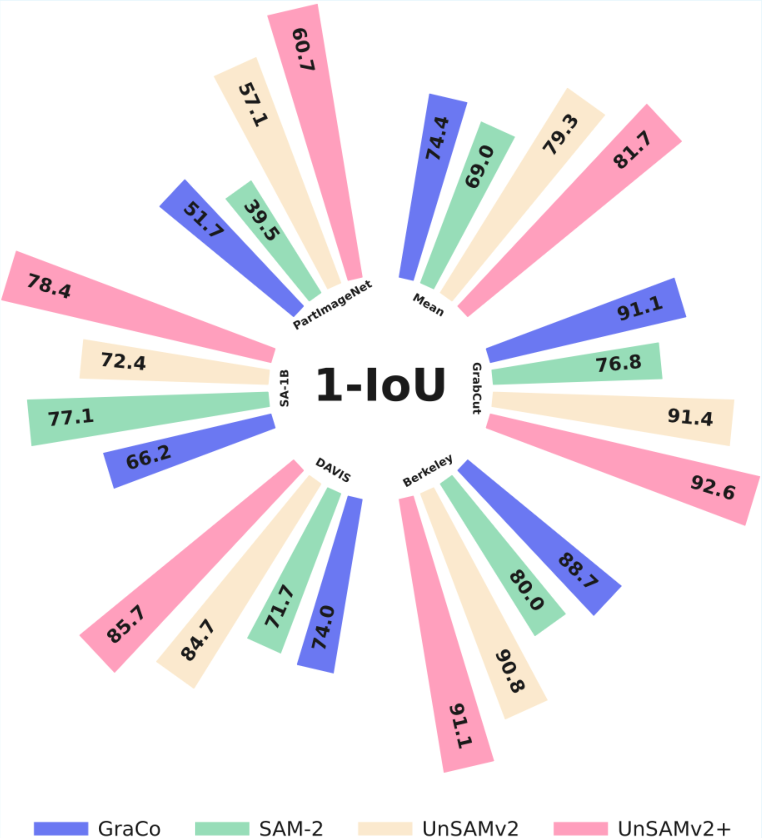
Figure 4: UnSAMv2 achieves state-of-the-art performance across interactive segmentation benchmarks by turning segmentation into a controllable, interpretable process.

Figure 5: Qualitative comparison with GraCo—UnSAMv2 provides clear, consistent masks and smooth scale transitions.
Whole-Image and Video Segmentation
UnSAMv2 generalizes robustly to whole-image segmentation and video, despite training solely on static images. It consistently discovers entities of all granularities, even in dense multi-object scenes.
- On whole-image segmentation over COCO, LVIS, ADE20K, and SA-1B, UnSAMv2 delivers superior AR1000 (up to +26.9 over previous SOTA).

Figure 6: Whole-image segmentation—UnSAMv2 reveals fine parts at low granularity and objects at high granularity, enabling scalable, controllable discovery.
- In videos, granularity-controllable masks retain temporal coherence and transferability without explicit video training.
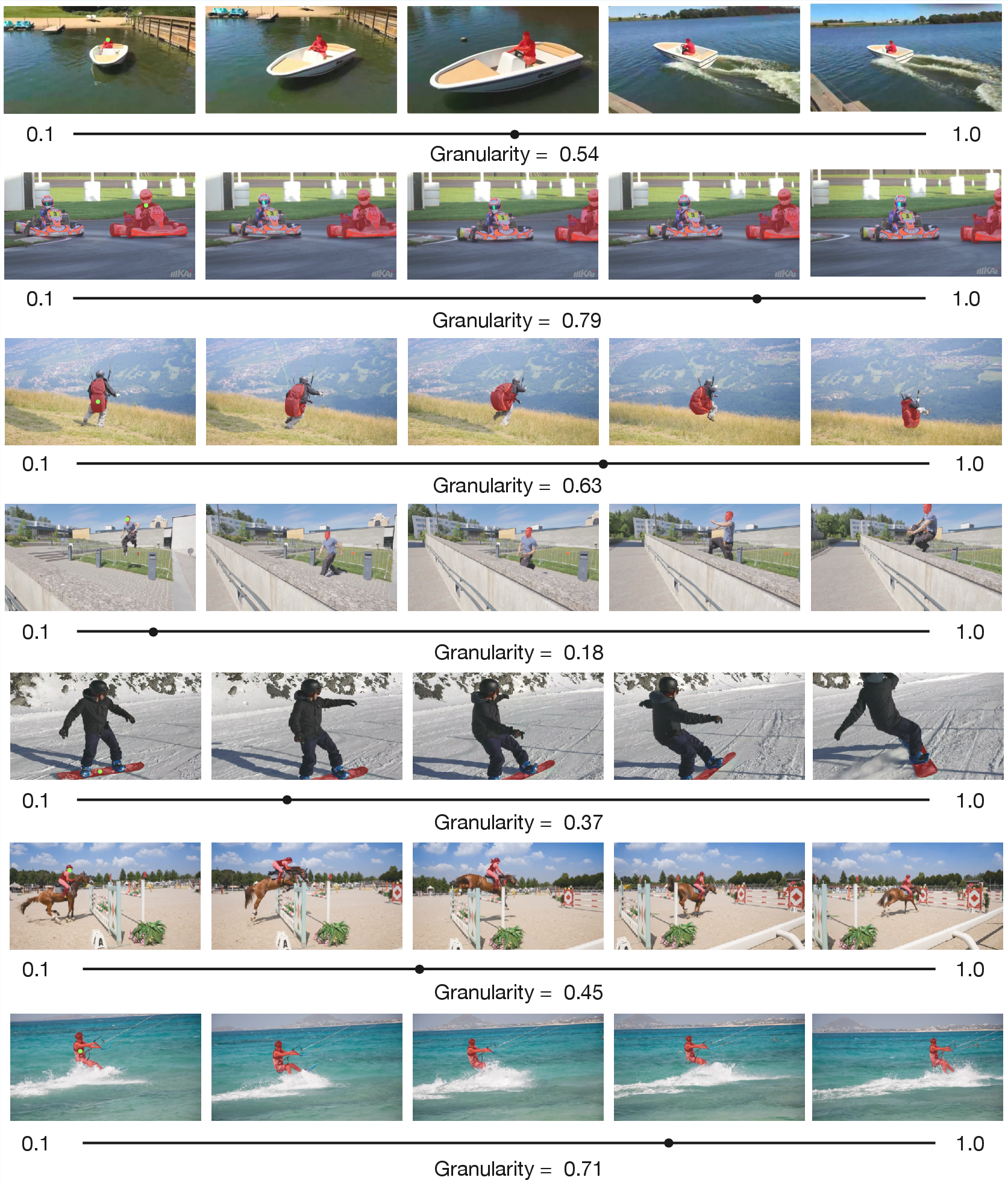
Figure 7: Granularity generalizes to video—Masks prompted on frame 1 propagate coherently, despite training only on images.
Resolving Ambiguity and Enabling Control
UnSAMv2 resolves the multi-mask ambiguity of SAM/SAM-2 by turning discrete mask prediction into a continuous reasoning process, enabling users to specify the target object/part via a scalar granularity input.
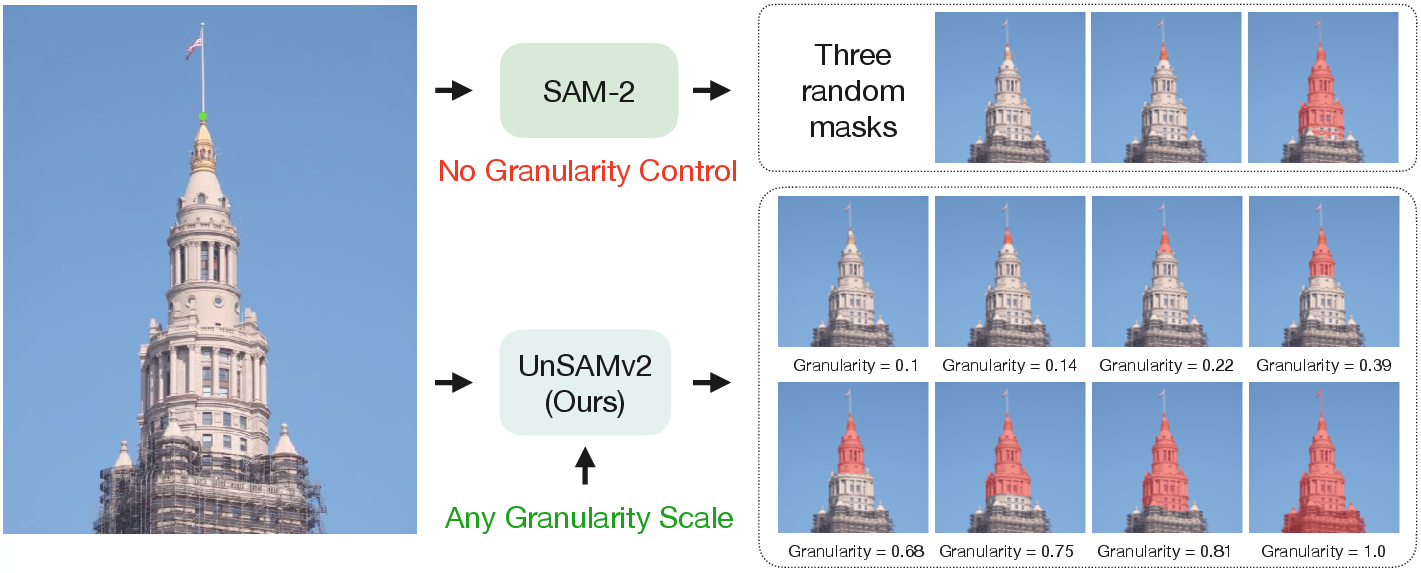
Figure 8: From ambiguity to control—Continuous granularity variable resolves selection ambiguity and allows segmentation at any desired scale.
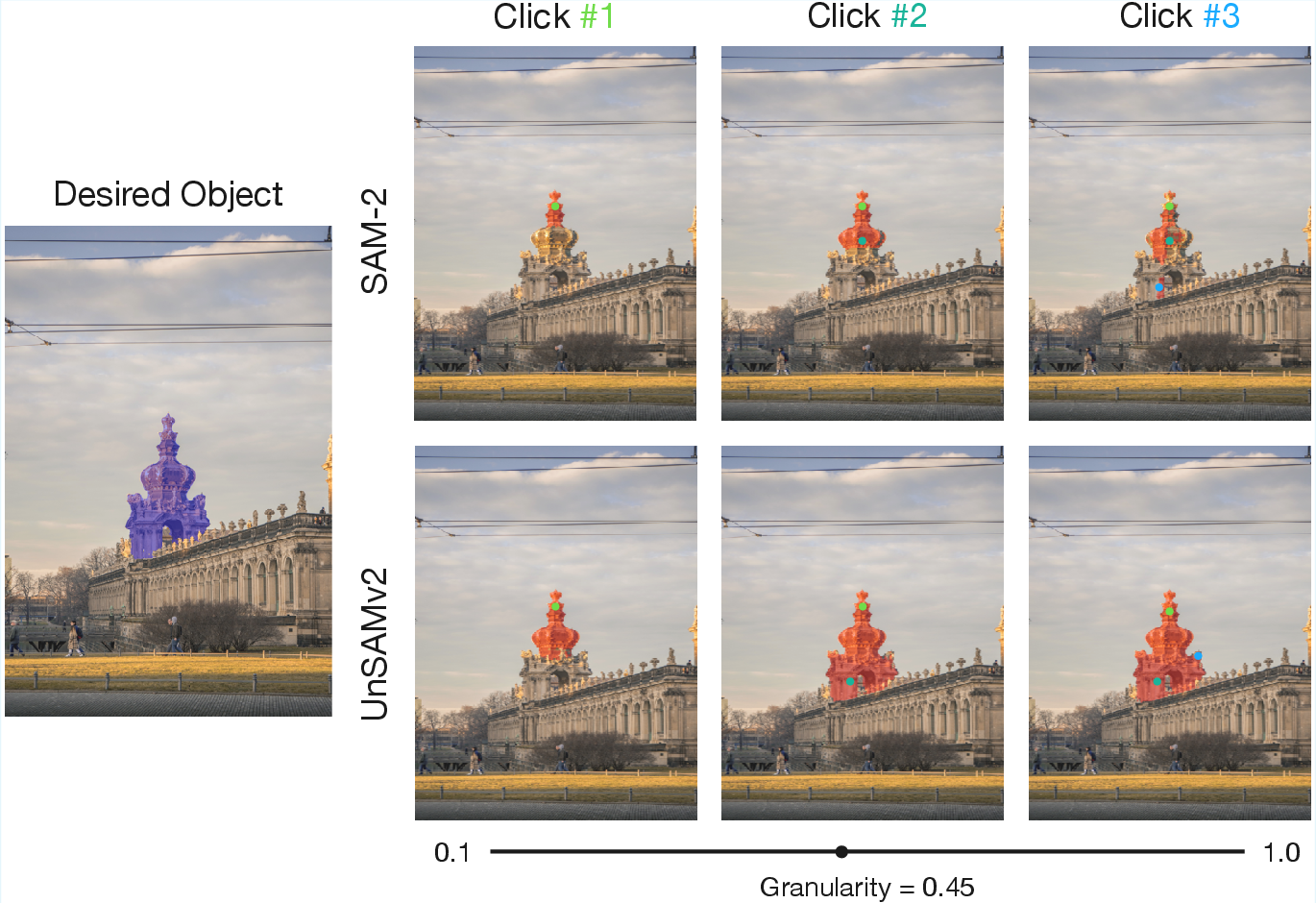
Figure 9: Fewer prompts, more control—UnSAMv2 finds the correct mask with a single granularity value; multi-point prompts provide even finer control.
Critical Design Ablations
Ablation studies highlight the importance of granularity-aware mask tokens, efficient granularity encoding, and sample efficiency:
Theoretical and Practical Implications
UnSAMv2 demonstrates that hierarchical perception and controllable scale traversal can be induced in large vision models using fully unsupervised data, without the annotation bias of human-labeled datasets. Its granularity-controllable architecture introduces a paradigm shift—segmentation models can be interpreted and manipulated as continuous reasoning engines, traversing the part-whole spectrum fluidly.
Practically, UnSAMv2 expands the utility of segmentation models to flexible part-level analysis, scalable entity grouping, structural scene understanding, and robust video tracking under minimal supervision. In theory, it validates the hypothesis that vision foundation models contain latent hierarchical structure that can be unlocked via self-supervised learning, bridging model-centric and human-centric definitions of objectness.

Figure 11: Granularity as a relative notion—Mask sizes at fixed granularity vary, consistent with relational human perception of object parts and wholes.
Prospective Directions
- Application to open-world, cross-domain, and medical segmentation tasks where granularity requirements vary.
- Integration with promptable multimodal models for richer part-whole semantic reasoning and editing pipelines.
- Further exploration of self-supervised hierarchical learning strategies in vision, possibly extending to 3D scene and temporal structure learning.
Conclusion
UnSAMv2 fundamentally augments promptable segmentation models by enabling scalable, continuous, and controllable segmentation granularity through hierarchical self-supervised pseudo-labeling and novel architectural designs. It achieves superior performance with extreme sample efficiency, highlighting both practical and theoretical advances in unsupervised vision model training. The approach paves the way for future controllable segmentation paradigms across image, video, and open-world domains.

Figure 12: Whole image segmentation—UnSAMv2 robustly discovers masks in scenes with varying entity density and scale, outperforming SAM-2.

Figure 13: Interactive video segmentation—UnSAMv2's masks at various granularity levels maintain coherence and adaptability across frames.