Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
Abstract: LLMs have demonstrated remarkable capabilities across diverse domains, but their training remains resource- and time-intensive, requiring massive compute power and careful orchestration of training procedures. Model souping-the practice of averaging weights from multiple models of the same architecture-has emerged as a promising pre- and post-training technique that can enhance performance without expensive retraining. In this paper, we introduce Soup Of Category Experts (SoCE), a principled approach for model souping that utilizes benchmark composition to identify optimal model candidates and applies non-uniform weighted averaging to maximize performance. Contrary to previous uniform-averaging approaches, our method leverages the observation that benchmark categories often exhibit low inter-correlations in model performance. SoCE identifies "expert" models for each weakly-correlated category cluster and combines them using optimized weighted averaging rather than uniform weights. We demonstrate that the proposed method improves performance and robustness across multiple domains, including multilingual capabilities, tool calling, and math and achieves state-of-the-art results on the Berkeley Function Calling Leaderboard.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Souper-Model: A simple explanation
Overview
This paper shows a surprisingly simple way to make big AI LLMs work better without retraining them from scratch. Instead of training a brand-new model, the authors “mix” several existing models of the same type together—like making a soup. Their new method, called Soup Of Category Experts (SoCE), picks the best “experts” for different kinds of tasks and combines them using smart, non-equal weights. This small change leads to state-of-the-art results on important tests, especially for AI models that call tools and functions.
Goals and questions
The paper asks two main questions, in everyday terms:
- If you have several models that are each good at different things, can you combine them to get a single model that’s good at many things at once?
- Is it better to “average” all models equally, or to give more weight to the ones that are experts in certain areas?
How it works (methods and analogies)
Think of each model as a player on a team:
- One model might be great at multi-step conversations.
- Another might be best at calling software tools.
- A third might be good at math or understanding long documents.
Instead of picking just one player, SoCE builds a team and sets the “volume” or “weight” for each player based on where they shine. It’s like making a smoothie: you don’t pour equal amounts of every ingredient—you add more of what improves the taste and nutrition for the goal you want.
Here’s the basic approach the paper takes:
- First, the authors look at “benchmark categories.” A benchmark is a test; categories are like school subjects (math, translation, tool use, etc.). They check how different models do across these categories.
- They measure “correlation” between categories. Correlation just means: do scores move together? If two categories are weakly related, being good at one doesn’t mean you’ll be good at the other—so different models might be experts in different ones.
- For each weakly related category group, they pick the model that’s the best “expert” at it.
- Then they try different weight combinations (like testing recipes) to see which weighted mix of expert models gives the highest overall score.
- Finally, they create the “souped” model by averaging the models’ internal settings (called “weights”) using the best recipe.
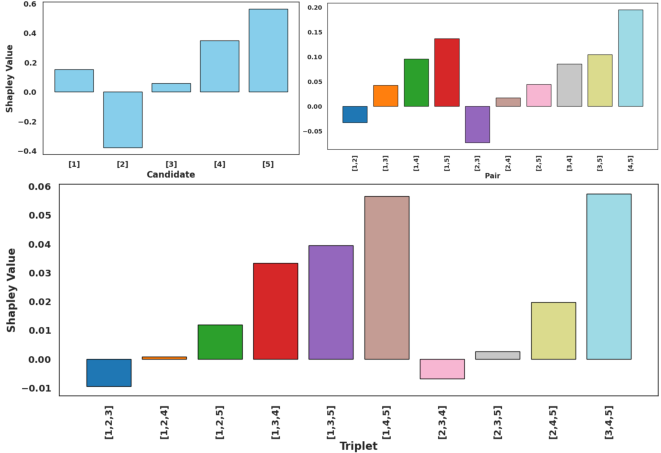
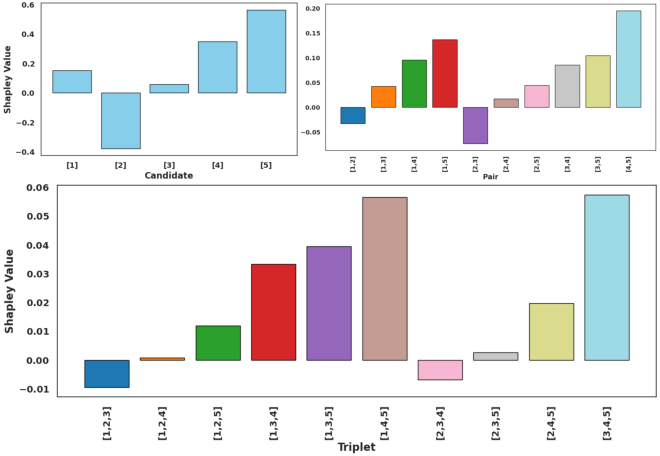
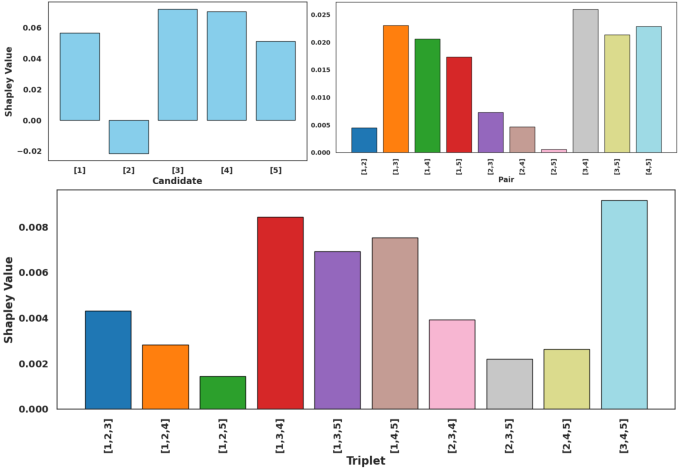
They also use a fairness idea from game theory called the “Shapley value.” In simple terms, it’s a way to share credit among teammates: it asks, “How much does each model really contribute to the team’s final score?” This helps confirm that SoCE really selects useful experts.
What they found (results) and why it matters
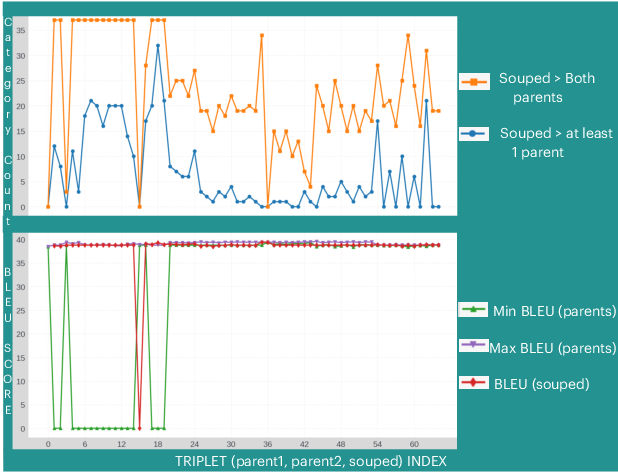
Across several tests, SoCE usually beats both:
- the single best individual model, and
- the classic “uniform soup” (which averages all models equally).
Key results:
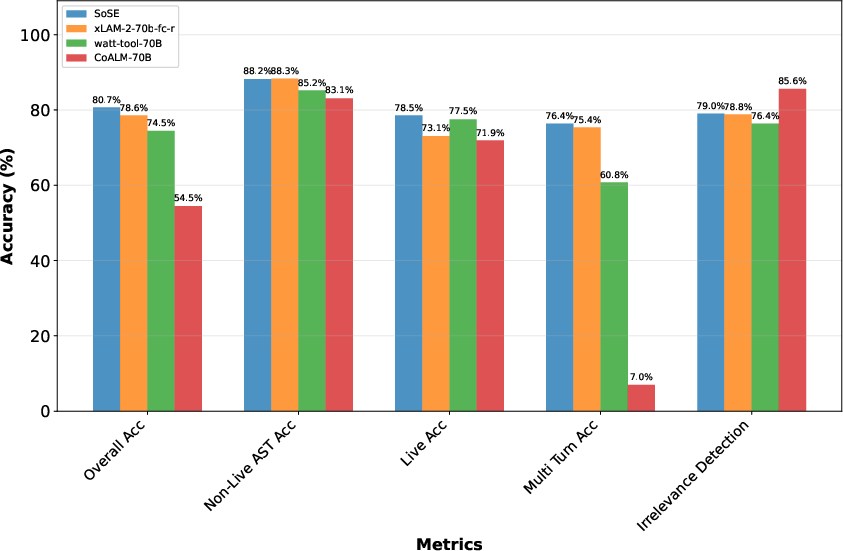
- Berkeley Function Calling Leaderboard (measures how well models call tools/functions):
- Big models (~70B parameters): SoCE reached 80.68% accuracy, beating the previous best 78.56%.
- Smaller models (~8B parameters): SoCE reached 76.50%, clearly above the prior best 72.37%.
- MGSM (multilingual grade-school math): SoCE slightly improved over the best single model and avoided the drop that happens when you naively average everything equally.
- ∞-Bench (long documents): The gains are smaller here, but SoCE still improved the best single model (from 27.44% to 28.0%).
- Consistency benefit: After souping, model performance across different categories becomes more stable and predictable. In other words, the souped model is less “spiky” and more balanced, which is useful in real-world use.
Why this matters:
- Training giant models is expensive and slow. SoCE gives you better performance by smartly combining existing models, saving time and computing power.
- The method is simple and general: it can be applied to many tasks where different “skills” don’t overlap much.
Implications and impact
- Practical boost without retraining: Companies, researchers, and the open-source community can get better models by combining strong checkpoints rather than starting from zero.
- Fairer access: Because it doesn’t require huge computing budgets, this approach can help smaller teams compete.
- More reliable AI helpers: The resulting models are not only stronger overall but also more consistent across different types of tasks.
Here are a few things to keep in mind:
- SoCE works best when tasks are different enough that different models are true “experts” in different areas. If all tasks are very similar, gains may be small.
- It requires models with the same architecture (the same kind of “brain”) so their weights can be averaged properly.
- The paper mainly tested models that share the same base (Llama-style), so it’s not yet proven across totally different pretraining origins.
- The method assumes you have benchmarks that are split into meaningful categories; if not, you may need to group or cluster tasks first.
- When releasing souped models, it’s important to say how they were made, so safety and interpretability research stays meaningful.
Takeaway
SoCE shows that “simple arithmetic”—carefully weighted averaging—can unlock top-tier performance. By choosing the right experts for different task categories and mixing them with the right recipe, you can build a single, stronger, more dependable LLM without the heavy cost of retraining.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s current scope.
- Benchmark dependence and category granularity:
- No method to construct or validate sub-category splits when benchmarks lack category structure; needs an automatic, statistically robust clustering pipeline (with stability checks and minimum sample sizes per cluster).
- Sensitivity of SoCE to the correlation threshold and clustering choices is unquantified; requires ablations over , clustering algorithms, and number of clusters.
- Data leakage and validation protocol:
- Candidate selection and weight tuning used leaderboard/test metrics; lacks a held-out development set protocol and cross-validation to prevent overfitting and quantify generalization.
- No statistical significance testing (e.g., confidence intervals, bootstrap) across runs; improvements could be within noise.
- Weight optimization procedure:
- Coarse grid search over weights (0.1 steps, capped in [0.1, 0.9]) is ad hoc and unscaled; needs principled, scalable optimization (e.g., gradient-based, Bayesian optimization, simplex constraints, per-layer weighting, or trust-region search).
- No analysis of combinatorial explosion in weight search with many candidates/categories; complexity bounds and pruning strategies (e.g., sparsity constraints, subset selection) are missing.
- No evaluation of negative or adaptive input-conditional weights; potential gains from instance-level or category-conditional weighting remain unexplored.
- Candidate selection strategy:
- “Top-per-category” expert selection is heuristic; comparisons against learned selection (e.g., reinforcement learning over subsets, submodular selection, diversity-regularized selection) are absent.
- No explicit metric for “diversity” among checkpoints; need a measurable diversity–performance trade-off analysis and minimal set size for gains.
- No robustness analysis when category correlations are unreliable due to small samples or noisy metrics.
- Scope of architectures and pretraining diversity:
- Only dense Llama-3 derivatives with the same pretraining checkpoint are evaluated; it remains unknown whether SoCE works with different pretraining seeds, families (e.g., Mistral, Qwen), or MoE models (and whether permutation/feature alignment is needed).
- No experiments on adapter-based or PEFT-weight merging (e.g., LoRA soups) vs full-weight merging; per-layer and per-module mixing is untested.
- Comparisons to stronger baselines:
- Lacks empirical comparisons to non-uniform merging methods such as greedy/learned soups (Wortsman et al.), AdaMerging, evolutionary merging (Akiba et al.), permutation-aligned merging, or function-space ensembles/distillation.
- No comparison to input-conditional ensembling (routing/gating at inference), which could compete with static soups.
- Theoretical understanding:
- No theoretical conditions under which weighted averaging improves performance (e.g., mode connectivity, local convexity, loss landscape geometry); absence of guarantees or failure-mode characterization.
- The observed increase in inter-category Pearson correlations post-souping is not theoretically interpreted; unclear whether this indicates desirable consistency or harmful homogenization (loss of specialization).
- Generalization and robustness:
- No tests under distribution shift/out-of-domain categories or adversarial prompts; robustness to real-world variation is unknown.
- Stability across evaluation seeds/checkpoint seeds is unreported; reproducibility and variance need quantification.
- Safety, alignment, and ethics:
- Empirical safety/harms assessment is missing (toxicity, jailbreak robustness, refusal correctness); interactions of mixed alignment states are not measured, only cautioned.
- License compatibility and IP risks when merging models with different licenses are not addressed; practical guidance for compliant souping is absent.
- Practical constraints and compute:
- Compute/time costs of candidate evaluation and weight search are unquantified; cost–benefit vs additional fine-tuning is not established.
- Impact on inference efficiency, memory footprint, quantization compatibility (INT8/INT4), and deployment constraints is unmeasured.
- Evaluation breadth and depth:
- Benchmarks are limited (BFCL, MGSM, subset of -Bench, FLORES-36 ablations); broader capabilities (reasoning beyond math, code generation, retrieval, safety/harms, multilingual breadth beyond targeted sets) are not covered.
- No human evaluations; all conclusions rely on automatic metrics that may not capture quality nuances.
- Failure analyses:
- Conditions where uniform souping regresses performance are incompletely analyzed (e.g., MGSM regression); no diagnostic framework to predict when souping will hurt or to detect/mitigate negative transfer pre-merge.
- No per-category regression reporting for the best soups; uneven gains/losses across languages or tasks remain hidden.
- Shapley/game-theoretic insights:
- Shapley analysis is ex post and not used to compute weights or guide selection; an algorithm that uses cooperative game theory to produce weights/sets is not proposed or validated.
- Computational overhead of Shapley value estimation (especially for larger candidate sets) and approximation accuracy are not assessed.
- Methodological details and reproducibility:
- Hyperparameters (e.g., , number of experts per cluster, search grid design, stopping criteria) and their sensitivity are under-specified.
- Exact data mixes and training variations for the internal checkpoints, and their seed control, are insufficiently documented for full reproducibility.
- Dynamics and scaling laws:
- No exploration of scaling with number of candidates, capability gaps, or diversity; diminishing returns and “sweet spots” for candidate count are not mapped.
- No analysis of intermediate training-stage soups (pretraining-phase soups, post-training EMA-like soups) vs final checkpoint soups.
- Alternative merging granularity:
- Per-layer or module-wise mixing, neuron-matching/permutation alignment, and representation-space merging (e.g., feature alignment) are not explored.
- No investigation of category- or input-conditional layer-wise weighting, which might retain specialization while boosting aggregate performance.
- Downstream integration:
- Distillation from soups into a single model (to retain gains with simpler deployment) is untested.
- Continual souping over time (versioned parents) and stability/drift management are not studied.
- Calibration and reliability:
- Effects on probability calibration, uncertainty, and confidence alignment are not measured; risk of overconfident errors remains unassessed.
- Multilingual fairness and coverage:
- For multilingual tasks, fairness across languages, low-resource settings, and script diversity is not analyzed; potential uneven improvements/regressions are unknown.
- Negative/soft constraints:
- The method enforces non-negative weights summing to 1; the utility (or risks) of relaxing this (e.g., allowing negative weights, sparsity-inducing penalties) is not evaluated.
- Category definition drift:
- Sensitivity to benchmark category definition changes over time (leaderboard updates, new sub-tasks) is not assessed; need for adaptive re-selection/re-weighting remains open.
Practical Applications
Immediate Applications
Below is a concise set of practical, deployable use cases enabled by the paper’s Soup Of Category Experts (SoCE) method and its empirical findings. Each item notes relevant sectors, potential tools/workflows, and feasibility assumptions/dependencies.
- Industry: Reliability upgrades for tool-using AI agents
- Sectors: Software, ecommerce, customer support, IT operations
- Tools/workflows: Apply SoCE to merge multiple function-calling fine-tunes (e.g., “multi-turn,” “irrelevance detection,” language-specific calling) of the same base architecture; deploy souped models in agent frameworks (LangChain, LlamaIndex, internal orchestration), API routers, and support bots to reduce failed or irrelevant tool calls
- Assumptions/dependencies: Ingredient models must share architecture and licensing compatibility; access to category-level benchmark metrics (e.g., BFCL) for expert selection; safety alignment must be preserved
- Industry: Cost-effective model performance boosts without full retraining
- Sectors: MLOps, cloud AI, enterprise ML platforms
- Tools/workflows: Integrate SoCE into post-training pipelines; automatically select candidate checkpoints by low inter-category correlations, run grid weight search (0.1–0.9 step 0.1), and produce a weighted soup; add a CI/CD step to evaluate the souped model on internal benchmarks
- Assumptions/dependencies: Shared base pretrain (preferably), robust evaluation harness, monitoring for regression in non-targeted capabilities
- Industry and Academia: Benchmark-aware ensemble design for multilingual math and long-context tasks
- Sectors: Education tech, finance (risk/calculation assistance), legal/compliance, research
- Tools/workflows: For multilingual math tutors or calculation assistants, soup models with complementary strengths across language-specific MGSM categories; for long-context document assistants, combine long-context fine-tunes with general reasoning models using SoCE
- Assumptions/dependencies: Category splits must exist or be defined; adequate test sets per category; safe to merge post-trained/aligned models from the same stage
- Academia: Low-compute method for performance and robustness gains
- Sectors: AI research, ML education
- Tools/workflows: Use the provided open-source code to replicate SoCE; apply correlation analysis and non-uniform weighting to student/research labs’ checkpoint collections; teach ensemble attribution using Shapley analysis on soups to understand contribution by candidate subsets
- Assumptions/dependencies: Availability of multiple compatible checkpoints; clear benchmark category definitions; reproducible evaluation
- Policy/Procurement: Sustainability-oriented AI optimization
- Sectors: Government digital services, public-sector AI, NGO tech programs
- Tools/workflows: Encourage post-training souping of same-architecture models to reduce retraining compute; include SoCE in procurement guidelines for cost/performance trade-offs
- Assumptions/dependencies: Disclosure of souping procedures; documented evaluation to meet governance requirements; compatible model licenses
- Industry: Production-ready function-calling reliability upgrades for multilingual APIs
- Sectors: Global SaaS, developer tooling, cloud platforms
- Tools/workflows: Soup language-specific function-calling specialists (Java/JS/Python calling) with multi-turn experts; deploy as a single multi-lingual function-calling endpoint with better BFCL accuracy and consistency
- Assumptions/dependencies: Access to representative function-calling data; strong monitoring of tool-calling correctness and irrelevance detection; safe deployment practices
- Industry: Catastrophic forgetting mitigation in continual fine-tuning
- Sectors: Enterprise AI, applied ML teams
- Tools/workflows: Use SoCE to merge domain-adapted fine-tunes back into a strong general base to recover forgotten capabilities while maintaining new domain skills
- Assumptions/dependencies: Same architecture and alignment stage; explicit evaluation across prior capabilities to avoid hidden regressions
- Daily life: More reliable personal assistants for scheduling, home automation, and multi-turn tasks
- Sectors: Consumer apps, smart home
- Tools/workflows: Soup assistants tuned for multi-turn dialogue, tool use, and irrelevance detection to reduce erroneous actions and misfires in home automation or personal scheduling
- Assumptions/dependencies: Compatible assistant models; transparent souping and safety alignment; rigorous validation on non-professional tasks
- Industry: Data mix diagnostics and training strategy refinement
- Sectors: MLOps, model training services
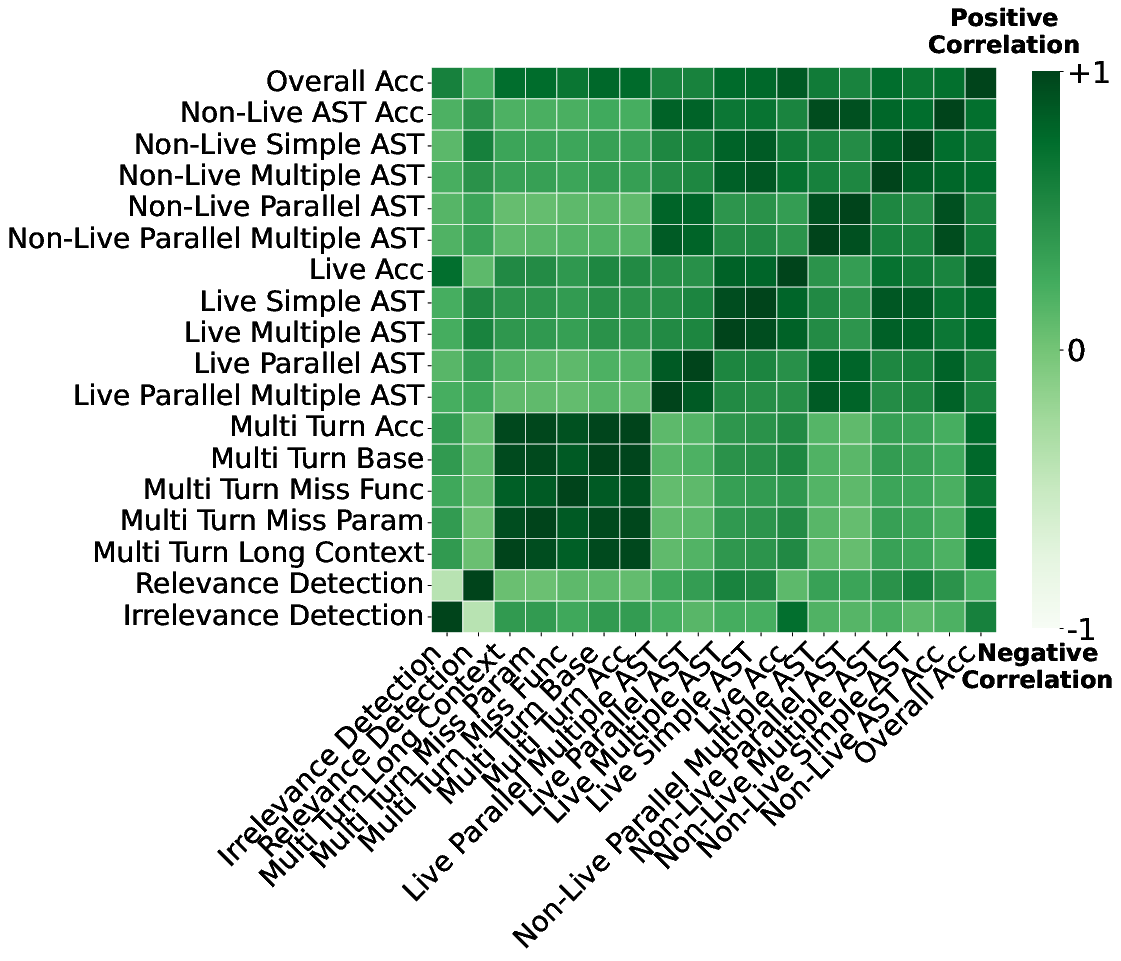
- Tools/workflows: Use SoCE’s correlation heatmaps to identify weakly/negatively correlated capability clusters; prioritize targeted fine-tunes and soup the resulting experts; iteratively refine data recipes using category-level signals
- Assumptions/dependencies: Access to comprehensive category evaluations; process discipline to avoid leakage from test to training; tracking of data provenance
- Academia and Industry: Capability consistency tracking
- Sectors: Evaluation and monitoring
- Tools/workflows: Adopt post-soup Pearson correlation tracking across benchmark categories to quantify cross-capability coherence; add to QA gates before model promotion
- Assumptions/dependencies: Multiple category metrics; consistent evaluation harness; stored model lineage for traceability
- Open-source community: Community-driven “soup kitchens” for Llama derivatives
- Sectors: OSS ecosystems, model hubs
- Tools/workflows: Curate sets of same-architecture derivatives; publish category-aware soups and metadata (weights, candidates, benchmarks); attach disclosure for interpretability research
- Assumptions/dependencies: License compatibility; explicit safety checks; benchmark metadata transparency
- Industry: Rapid A/B testing of weight recipes
- Sectors: Product ML teams
- Tools/workflows: Implement a lightweight weight search service to auto-tune soups per product KPI (e.g., support resolution rate, tool-call success); freeze winning recipe and deploy
- Assumptions/dependencies: Clear KPIs; sufficient traffic for rapid measurements; guardrails for safety and fairness
Long-Term Applications
These applications are promising but require further research, scaling studies, expanded tooling, or broader ecosystem norms.
- Cross-pretrain or cross-architecture soups (dense + MoE + adapter stacks)
- Sectors: Foundation model providers, advanced R&D
- Tools/products/workflows: Generalized model-merging frameworks that align representations across different pretrains or architectures; adapter-aware soups; automated gating and calibration
- Assumptions/dependencies: Methods for representation alignment; new safety/interpretability studies; robust licensing and provenance controls
- Automated category discovery for benchmarks without predefined splits
- Sectors: Evaluation research, tool vendors
- Tools/workflows: Unsupervised clustering of tasks and metrics to infer category structure; plug into SoCE to select experts and weights
- Assumptions/dependencies: Reliable clustering quality; avoidance of overfitting; standardized data schemas for benchmark tasks
- Dynamic, task-aware “Ensemble-as-a-Service”
- Sectors: Cloud AI platforms, enterprise AI
- Tools/products/workflows: On-demand soup creation and weight optimization per customer domain; continuous evaluation; automatic rollback and safety controls
- Assumptions/dependencies: Scalable evaluation infrastructure; real-time telemetry; robust governance and disclosure practices
- Personalized soups for user-specific workflows
- Sectors: Productivity suites, vertical SaaS
- Tools/workflows: Merge a user’s domain-specific fine-tune (e.g., legal templates, medical notes, engineering CAD comments) with general capabilities; optimize weights based on usage analytics
- Assumptions/dependencies: Privacy-preserving pipelines; federated or edge options; per-user safety and fairness evaluations
- Training recipe optimization guided by correlation patterns
- Sectors: Model training and data engineering
- Tools/workflows: Use inter-category correlations to design multi-task curricula and data mixes; pretrain/post-train loops that target low-correlation clusters and then soup
- Assumptions/dependencies: Longitudinal measurement of capability trade-offs; scalable data curation; reproducible experiment tracking
- Policy: Standardized disclosure and audit requirements for souped models
- Sectors: Regulators, standards bodies, public-sector AI
- Tools/workflows: Mandate public metadata of souping procedures, weights, candidate provenance, and evaluation results; include interpretability caveats for research
- Assumptions/dependencies: Stakeholder consensus; legal frameworks for licensing compatibility; assessment methods for safety and fairness
- Marketplace attribution and compensation via Shapley-like valuation
- Sectors: OSS model hubs, developer ecosystems
- Tools/workflows: Attribute contributions (candidates, pairs, triplets) to soups using Shapley-inspired metrics; enable credit, payments, or badges for high-value contributors
- Assumptions/dependencies: Reliable valuation pipelines; anti-gaming safeguards; governance of incentives
- Robust safety-preserving soups (alignment-first merging)
- Sectors: Safety research, healthcare, finance, legal
- Tools/workflows: Methods to ensure merged models preserve or improve alignment and guardrails; selective weighting to prioritize safety-tuned parents
- Assumptions/dependencies: New safety benchmarks with category splits; formal analyses of risk inheritance; red-teaming and continuous monitoring
- Federated and edge deployment of domain soups
- Sectors: Mobile, IoT, robotics
- Tools/workflows: Create device- or site-specific soups from local fine-tunes and a general base; synchronize via federated protocols; optimize for on-device inference
- Assumptions/dependencies: Lightweight merging on-device; privacy guarantees; hardware-aware quantization and memory constraints
- Long-context enterprise knowledge assistants
- Sectors: Legal, compliance, R&D knowledge management
- Tools/workflows: Combine long-context reasoning models with domain experts via SoCE; deploy assistants for 100K+ token documents with robust retrieval and synthesis
- Assumptions/dependencies: Scalable context windows; reliable evaluation on real-world corpora; guardrails for confidential data
- Auto-soup orchestration with continuous learning
- Sectors: MLOps platforms
- Tools/workflows: Pipelines that detect capability drift across categories, spawn new fine-tunes per weak cluster, and re-soup with updated weights periodically
- Assumptions/dependencies: Streaming evaluation; model lifecycle management; safety, fairness, and stability gates
- Interpretability-aware souping practices
- Sectors: Research, regulatory science
- Tools/workflows: Develop interpretability protocols for souped checkpoints; tooling to separate parent contributions; audits that account for blurred mechanistic signals
- Assumptions/dependencies: New interpretability methods for merged weights; standardized reporting; community norms around disclosure and reproducibility
Glossary
- adapters: Lightweight modules attached to pretrained models to enable parameter-efficient fine-tuning or merging. "with adapters\footnote{\url{https://huggingface.co/docs/peft/en/developer_guides/model_merging}"
- anti-correlation criterion: A selection rule that favors combining models whose strengths are in categories with low cross-model correlation. "Uniform Souping with model selection only combines the selected models using the anti-correlation criterion"
- Automated Checkpoint Souping: A structured procedure to automatically select and combine model checkpoints based on benchmark signals. "Automated Checkpoint Souping: We introduce Soup Of Category Experts (SoCE), a novel model souping technique that leverages benchmark composition through an automatic category-aware expert selection mechanism."
- benchmark composition: The set and structure of categories within an evaluation benchmark used to guide model selection and weighting. "utilizes benchmark composition to identify optimal model candidates and applies non-uniform weighted averaging to maximize performance."
- benchmark clustering: Grouping benchmark items or categories into clusters (e.g., by correlation) to enable expert selection or weighting. "we propose benchmark clustering as a future work to this approach."
- Berkeley Function Calling Leaderboard (BFCL): A benchmark evaluating LLM tool/function calling across multiple categories and settings. "Berkeley Function Calling Leaderboard (BFCL) ~\cite{BFCL}: evaluates tool calling and function invocation capabilities of LLMs across multiple categories including multi-turn interactions, irrelevance detection, and cross-language function calling."
- catastrophic forgetting: The loss of previously learned capabilities when a model is fine-tuned on new tasks. "mitigate issues like catastrophic forgetting"
- category-aware expert selection mechanism: An automatic method to pick best-performing models for specific benchmark category clusters. "through an automatic category-aware expert selection mechanism"
- characteristic function: In cooperative game theory, a mapping from coalitions to their achieved utility/value. "and a characteristic function "
- checkpoint: A saved model state (parameters) at a training stage, used for evaluation, fine-tuning, or merging. "We conducted model souping and evaluation experiments on a comprehensive set of candidate checkpoints"
- coalition: A subset of players/models in a cooperative game analysis whose collective performance is evaluated. "which assigns to each coalition a real value representing the utility or performance achieved by that coalition."
- correlation heatmap: A visualization of pairwise correlation coefficients among category performances. "presents a correlation heatmap showing Pearson correlation coefficients between category performances across all models on the leaderboard"
- correlation threshold: A numeric cutoff used to identify low-correlation category pairs for expert selection. "\Require Correlation threshold for identifying low-correlation categories"
- cooperative game theory: A framework analyzing how multiple agents collaborate and contribute to joint outcomes. "Cooperative game theory addresses situations where multiple agents collaborate as a team."
- cross-lingual generalization: The ability of a model to transfer reasoning or skills across different languages. "testing both computational skills and cross-lingual generalization."
- dense models: Neural models without sparsity or expert routing; all parameters are active for all inputs. "We compare souping for two sets of models on BFCL, i.e., 70 billion and 8 billion parameter dense models."
- entropy minimization: An optimization principle reducing uncertainty to discover merging parameters without supervision. "unsupervised methods to discover optimal merging parameters based on entropy minimization."
- evolutionary algorithms: Search methods inspired by biological evolution used to optimize model merging recipes. "\citet{Akiba_2025} apply evolutionary algorithms to model merging"
- FLORES-101: A multilingual machine translation benchmark covering many language pairs. "FLORES-101 ~\citep{flores101_goyal2021}: Measures translation quality and multilingual understanding across a diverse set of language pairs."
- FLORES-36: A subset of FLORES-101 focusing on translations between English and 18 languages. "We will refer to this subset at FLORES-36."
- function invocation: Executing specified functions via LLM tool-use interfaces. "evaluates tool calling and function invocation capabilities of LLMs"
- Greedy Souping: A souping strategy that adds models one at a time in decreasing order of performance. "Greedy Souping (add 1 model at a time in decreasing order of performance)"
- -Bench: A long-context benchmark evaluating model performance on sequences averaging over 100k tokens. "-Bench~\citep{zhang2024bench}: evaluates long-context processing capabilities"
- irrelevance detection: Identifying when a tool/function call is unnecessary or unrelated to the prompt. "including multi-turn interactions, irrelevance detection, and cross-language function calling"
- LLMs: Transformer-based models trained on vast text corpora to perform a wide range of language tasks. "LLMs have emerged as transformative technologies"
- Learned-Souping: A souping method that learns soup weights via gradient descent. "Learned-Souping (soup weights are learned via gradient descent)"
- long-context processing: The capability of an LLM to understand and reason over very long input sequences. "evaluates long-context processing capabilities"
- marginal contribution: The performance gain from adding a player/model to a coalition or ordering. "The marginal contribution of in permutation is"
- MGSM (Multilingual Grade School Math Benchmark): A benchmark testing math reasoning across multiple languages. "Multilingual Grade School Math Benchmark (MGSM) ~\citep{mgsm_shi2022}: assesses mathematical reasoning abilities across multiple languages"
- mixture of experts: An architecture where specialized (expert) subnetworks are selectively activated per input. "such as mixture of experts."
- model merging: Combining parameters from multiple models to create a merged model without retraining. "Automatic model merging. Several works explore automatic model merging techniques"
- model souping: Averaging weights from multiple models of the same architecture to improve performance. "model soupingâthe practice of averaging weights from multiple models of the same architectureâ"
- non-uniform weighted averaging: Averaging model weights using different weights per model to maximize performance. "applies non-uniform weighted averaging to maximize performance."
- oracle development set: A hypothetical or privileged dev dataset assumed available for candidate selection. "we would have an oracle development set to select candidates without leaking any information."
- Pearson correlation: A measure of linear association between two variables/categories. "Souped models exhibit significantly higher Pearson correlations between category performances across model populations"
- permutation: An ordering of players used in Shapley value computation to average contributions. "Let denote the set of all permutations of the players"
- post-training: Model optimization steps performed after pretraining, such as alignment or souping. "post-training technique to enhance performance without requiring expensive retraining."
- pretraining: Large-scale initial training on diverse corpora to learn general language representations. "massive-scale pretraining on diverse corpora"
- reinforcement learning from human feedback: Training method where human preferences guide policy optimization. "reinforcement learning from human feedback~\citep{ouyang2022training,bai2022towards}"
- Shapley value: A principled attribution method that fairly distributes coalition gains among players. "The Shapley value~\cite{shapley:book1952} is a fundamental concept in cooperative game theory"
- state-of-the-art: The best known performance achieved on a benchmark at the time of reporting. "and achieves state-of-the-art results on the Berkeley Function Calling Leaderboard."
- supervised fine-tuning: Training a pretrained model on labeled examples to improve task performance. "followed by supervised fine-tuning and reinforcement learning from human feedback"
- Soup Of Category Experts (SoCE): A souping framework that selects category experts and combines them with optimized weights. "Our proposed method, Soup Of Category Experts (SoCE), exploits these correlation patterns to strategically select and weight models for souping."
- tool calling: LLM capability to invoke external tools/functions via structured outputs. "evaluates tool calling and function invocation capabilities of LLMs"
- transferable-utility: A cooperative game setting where utility can be freely redistributed among players. "A (transferable-utility) cooperative game is specified by a set of players"
- uniform averaging: Averaging model weights with equal weights across all models. "uniform averaging of model weights can lead to improved performance"
- Uniform Souping: A baseline souping strategy where all models are weighted equally. "Uniform Souping (where all models are weighted equally)"
- weight optimization: Searching for the best set of soup weights to maximize aggregate performance. "weight optimization to maximize aggregate performance"
- weight space: The set of possible weight combinations considered during optimization. "We iterate over all combinations in the weight space with the highest weight 0.9 and lowest of 0.1"
- weighted averaging: Combining model parameters using specified weights rather than equal weighting. "aggregate their expertise using non-uniform weighted averaging to maximize overall performance."
Collections
Sign up for free to add this paper to one or more collections.