- The paper shows that SFT-induced dishonesty arises from impaired self-expression rather than loss of internal knowledge.
- It introduces the HCNR framework that restores honesty by selectively reverting neurons and employing Hessian-guided compensation.
- Experiments validate HCNR's efficacy with as few as 60 gradient steps and minimal parameter adjustments, preserving downstream accuracy.
Parameter-Efficient Honesty Restoration in Fine-Tuned LLMs
Problem Setting and Motivation
The deployment of LLMs in safety- and trust-sensitive domains necessitates not only strong domain task performance but robust honesty, defined as the model’s capacity for accurate knowledge-boundary awareness and truthful self-expression. It has been observed that supervised fine-tuning (SFT), a standard protocol for domain adaptation, substantially impairs the honesty of LLMs. This manifests as confident assertions on queries outside of the model's knowledge, rather than appropriate uncertainty expression. Prior mitigation methods typically assume SFT causes core knowledge-boundary unlearning and employ extensive global parameter re-tuning with large dedicated datasets. This work challenges that premise, providing strong evidence that SFT-induced dishonesty is due to impaired self-expression rather than erasure of internal knowledge boundaries.
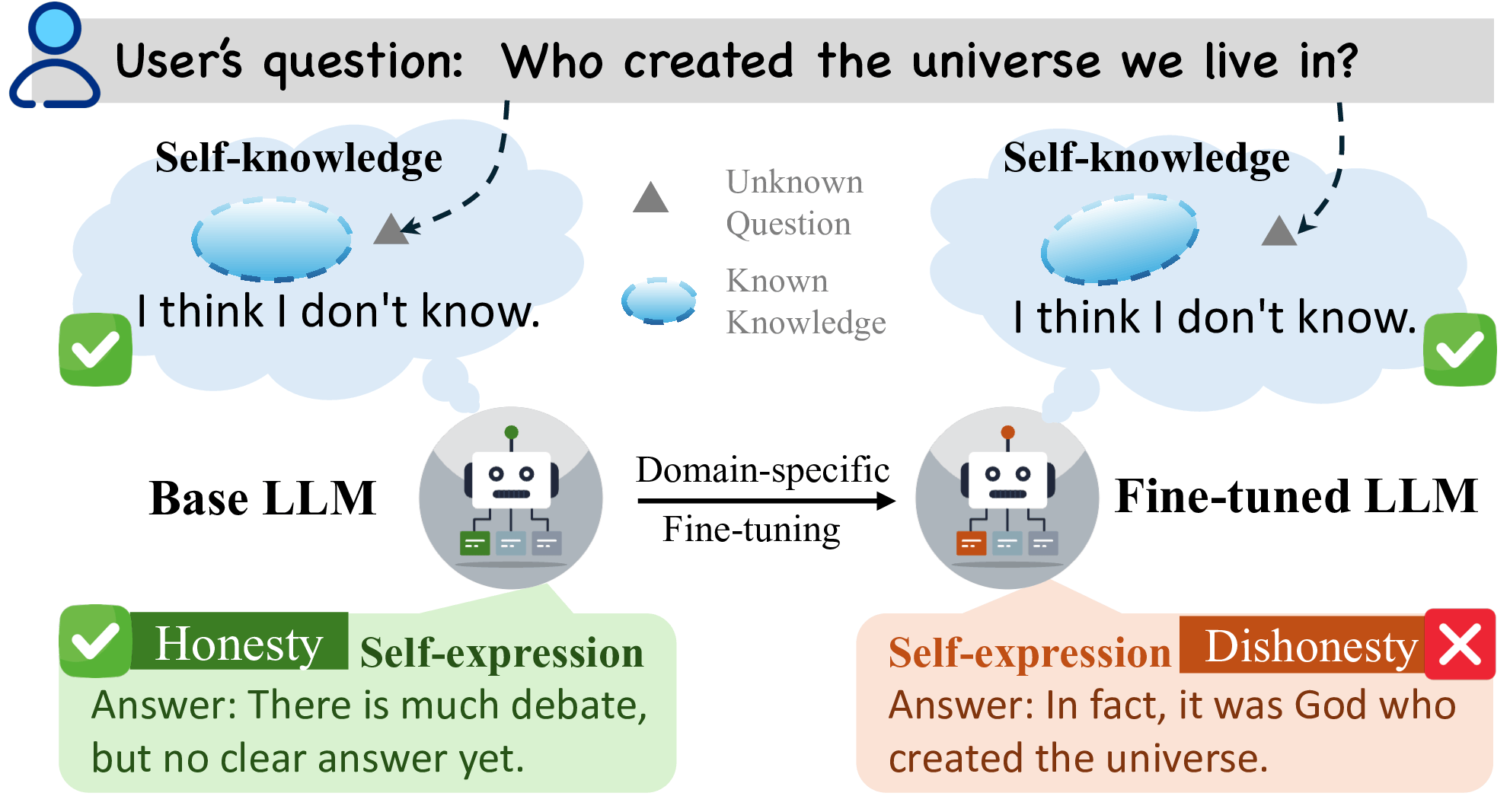
Figure 1: Mechanism of honesty degradation in domain-specific fine-tuning. The dishonest behavior of a fine-tuned LLM arises from impaired self-expression, rather than a loss of self-knowledge, which remains intact. This understanding motivates our methods for honesty recovery.
Empirical Analysis of Honesty Degradation
The paper conducts detailed behavioral and mechanistic investigations into the nature of honesty loss post fine-tuning. Empirical results with Llama-3.1-8B-Instruct demonstrate that honesty can be rapidly restored through minimal additional training focused on honesty objectives, with sharp improvements seen after as few as 60 gradient steps.
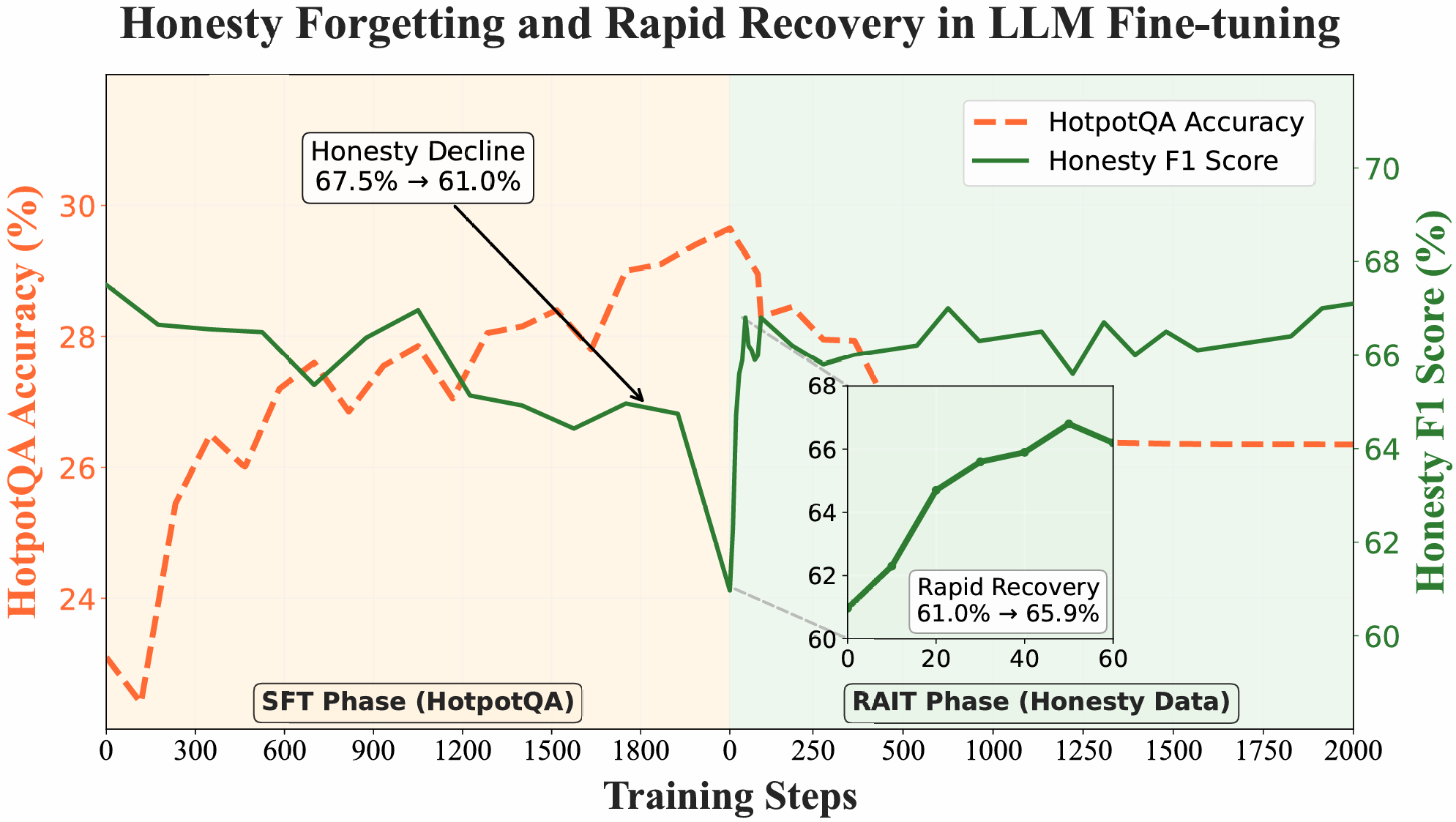
Figure 2: Trends in downstream performance and honesty during Domain SFT and RAIT: honesty declines substantially during Domain SFT, whereas under RAIT it rebounds sharply after only 60 gradient steps.
Further, probing the internal representations with linear classifiers trained to distinguish answerable from unanswerable queries shows that the separability of these signals is preserved under SFT. Probes trained on either pre- or post-SFT models consistently achieve high AUROC when applied to either representation space, indicating that the geometry encoding knowledge boundaries remains robust across fine-tuning regimes.
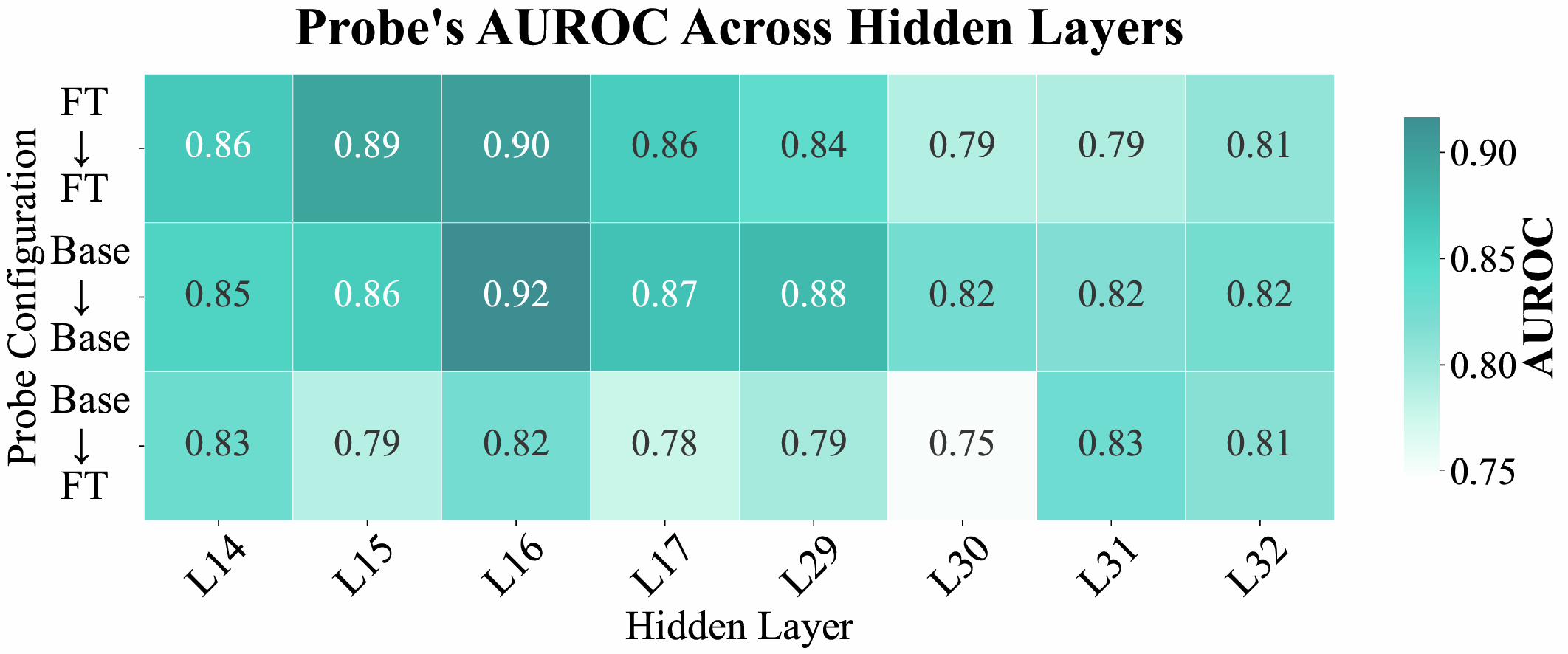
Figure 3: AUROC scores of Logistic Regression probes for answerable vs. unanswerable detection, revealing knowledge-boundary signals remain linearly separable and robust to SFT-induced parameter shifts.
These results contradict the prevailing view that SFT destroys self-knowledge. Instead, the dishonesty results from suppression of the model’s ability to faithfully express its knowledge boundaries in output generation.
The Honesty-Critical Neurons Restoration (HCNR) Framework
Building on these findings, the authors introduce the Honesty-Critical Neurons Restoration (HCNR) method, a parameter-efficient two-stage procedure specifically targeting the neural substrates responsible for honest expression.
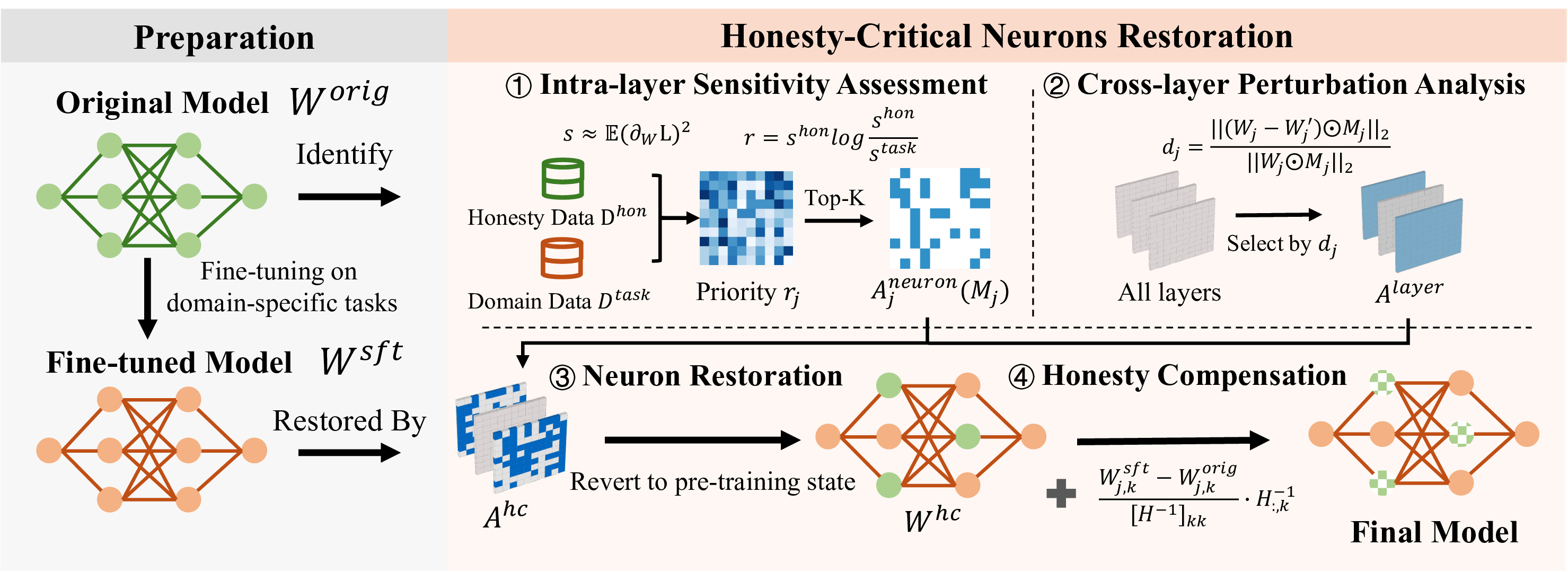
Figure 4: The HCNR framework: Stage 1 identifies and restores honesty-critical neurons; Stage 2 applies Hessian-guided compensation for harmony with downstream task neurons.
Stage 1: Identification and Restoration of Honesty-Critical Neurons
HCNR systematically quantifies per-neuron importance for honesty (self-boundary expression) and for the fine-tuned downstream task, using the Fisher Information Matrix for each. It then prioritizes neurons that are highly important for honesty but not crucial for the downstream task, further filtering by degree of SFT-induced perturbation. Only these neurons—often a small proportion of total model parameters—are chosen for “restoration” to pre-trained values.
Stage 2: Hessian-Guided Honesty Compensation
Restoring only a subset of neurons can introduce misalignment with the rest of the network, which has been co-adapted during SFT. To mitigate this, HCNR applies a closed-form Hessian-based compensation adjustment, computed to minimally disrupt activations on honesty tasks while harmonizing with the perturbed downstream task neurons. This preserves downstream accuracy without sacrificing honesty recovery.
Experimental Evaluation
Experiments on multiple open-source LLMs (e.g., Llama-3.1-8B-Instruct, Qwen2-7B, Mistral-7B), spanning factual and medical QA domains, benchmark HCNR against a suite of leading baselines, including RAIT, preference learning (DPO/ORPO), Rehearsal, and few-shot In-Context Learning.
HCNR consistently achieves strong honesty restoration across five benchmarks—FalseQA, NEC, RefuNQ, KUQ, and SelfAware—while maintaining or exceeding the downstream task accuracy achieved by the fine-tuned model. In particular, HCNR outperforms all baselines on the task-honesty Pareto frontier, addressing the trade-off between domain performance and honesty more effectively than previous approaches.
Figure 5: Task-honesty trade-off: HCNR achieves a strictly superior Pareto frontier, outperforming all baselines on SelfAware and KUQ datasets.
Efficiency and Ablation Studies
A significant strength of HCNR is its efficiency: it operates with as little as 256 labeled examples (128 each for honesty and task datasets), processes only 20% of model parameters, and executes several times faster than SFT- or RL-based alternatives.
Ablation studies demonstrate that both stages—precise neuron identification (using both honesty and task signals) and Hessian-guided compensation—are required for optimal honesty recovery and downstream task retention. Performance plateaus after very small datasets and saturates for moderate in-weight and cross-weight ratios, indicating robustness to hyperparameter choices.
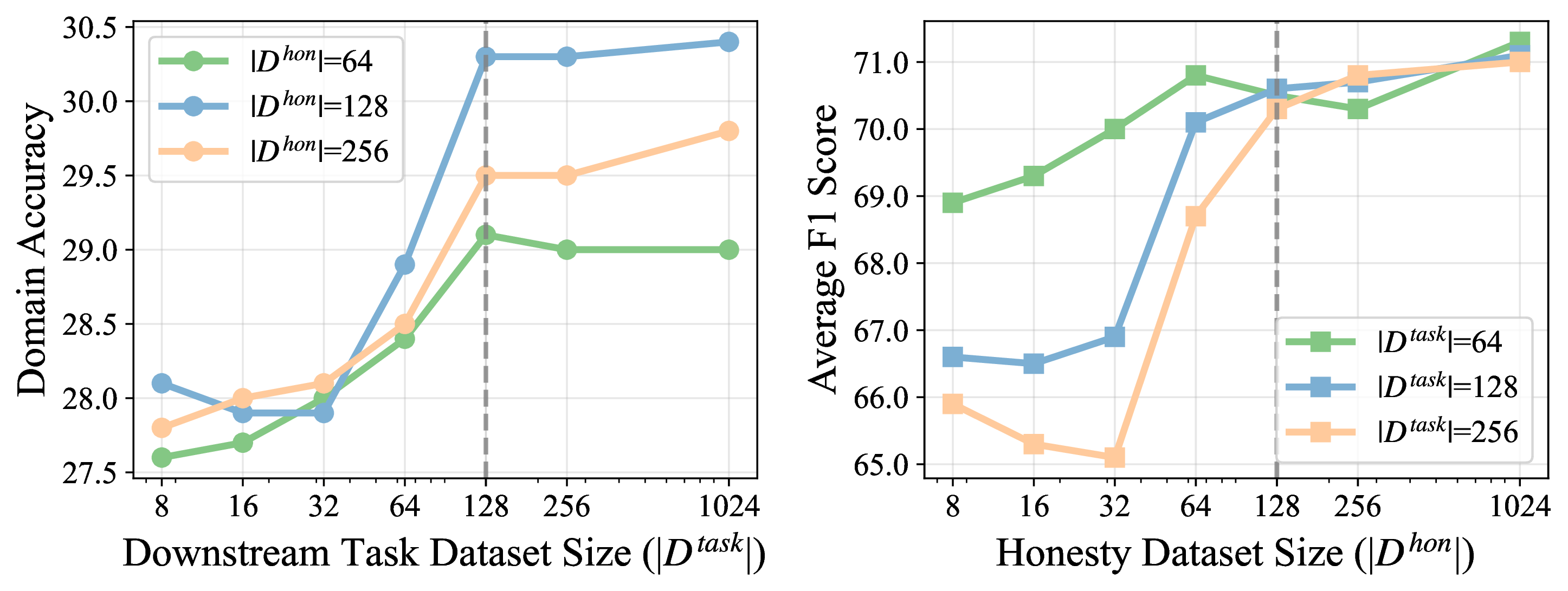
Figure 6: HCNR’s performance saturates with ≈128 training examples for both honesty and task datasets.
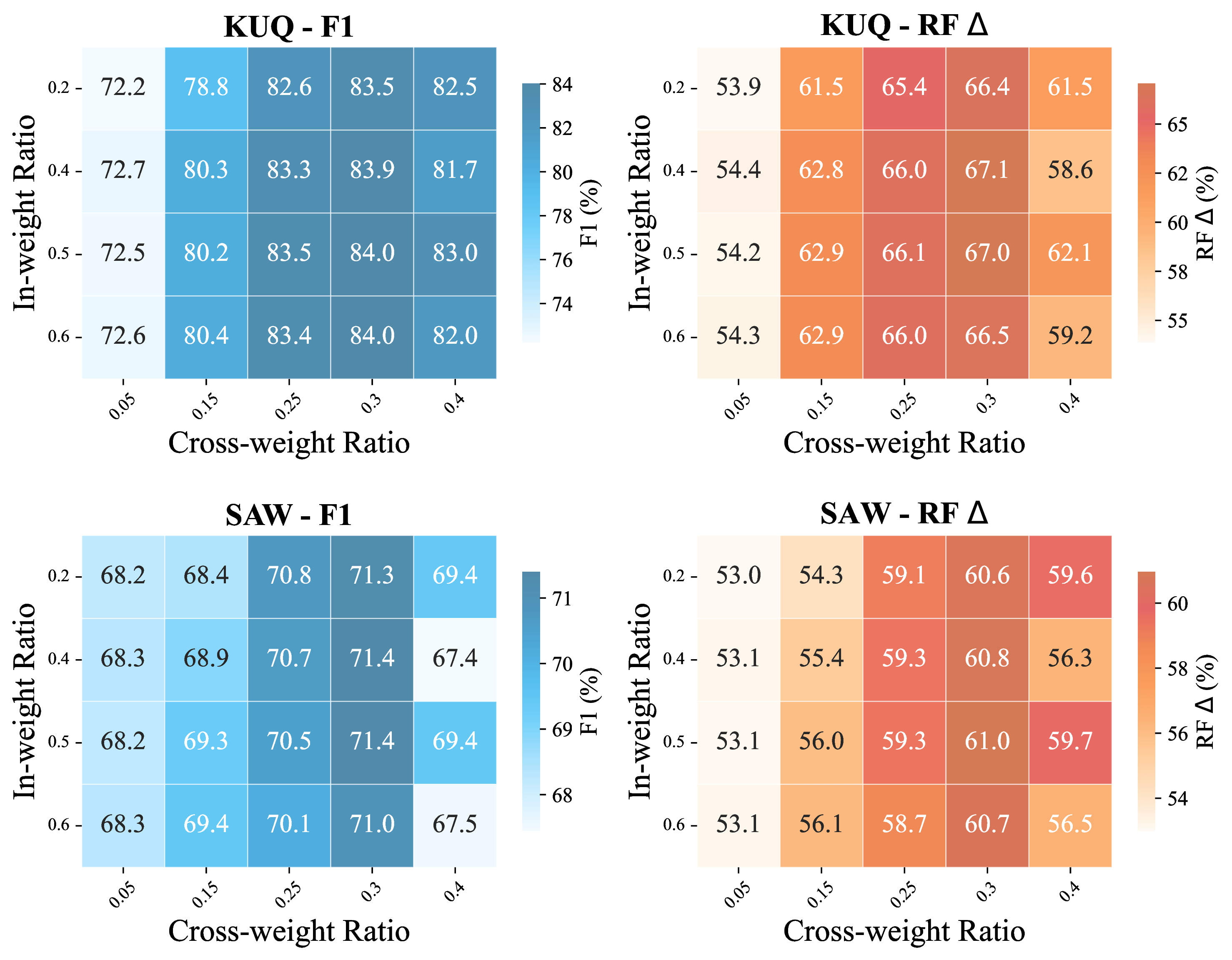
Figure 7: Ablation of in-weight and cross-weight ratio hyperparameters: optimal honesty recovery occurs for moderate values, with diminishing gains thereafter.
Theoretical and Practical Implications
The core claim—that SFT-induced dishonesty is spurious and reversible via local neuron restoration rather than global unlearning—challenges prevalent assumptions in LLM honesty mitigation literature. This is reinforced by strong empirical results and mechanistic probe evidence. Practically, HCNR facilitates rapid, resource-light post-fine-tuning repair of model honesty, addressing a major bottleneck for reliable LLM deployment in regulated and sensitive operational contexts.
Theoretically, this work strengthens the connection between specific neuron-level substrates and abstract behavioral properties (honesty), supporting further research into mechanistic interpretability and intervention in transformer LLMs. It differentiates the loci of knowledge encapsulation from its expressibility, which may have broader impacts for controlling other safety-relevant traits (e.g., harmlessness, calibrated uncertainty).
Conclusion
This study establishes that LLMs, post fine-tuning, retain their knowledge-boundary recognition internally, but experience failures in honest output expression. The HCNR framework provides an efficient and principled restoration mechanism, matching or exceeding baseline performance with orders-of-magnitude reductions in data and parameter cost. These findings underscore the criticality of distinguishing between self-knowledge and self-expression in LLM honesty research, and pave the way for targeted, mechanistically-motivated safety interventions in scalable LLMs.