- The paper introduces a novel Dynamic-Capacity MoE architecture with Top-P routing for adaptive expert allocation in unified audio generation.
- It demonstrates state-of-art results in both speech synthesis (UTMOS 4.36, WER 1.9) and music generation while effectively addressing data imbalance.
- The three-stage training curriculum ensures domain specialization and efficient integration, preventing catastrophic forgetting in underrepresented tasks.
UniMoE-Audio: Unified Speech and Music Generation with Dynamic-Capacity MoE
Introduction and Motivation
The unification of speech and music generation within a single generative model has been a persistent challenge due to two primary obstacles: task conflict and data imbalance. Speech and music, while both audio modalities, have fundamentally divergent objectives—speech prioritizes semantic intelligibility and speaker identity, whereas music emphasizes complex structures such as harmony and rhythm. This divergence leads to conflicting optimization pressures in joint models. Additionally, the abundance of high-quality speech data compared to the relative scarcity of music data exacerbates the risk of catastrophic forgetting and performance degradation for the underrepresented modality.
UniMoE-Audio addresses these challenges by introducing a unified generative framework based on a novel Dynamic-Capacity Mixture-of-Experts (MoE) architecture, coupled with a data-aware, three-stage training curriculum. The model demonstrates that with appropriate architectural and training strategies, it is possible to achieve synergistic performance across both speech and music generation tasks, surpassing naive joint training and even specialized baselines.
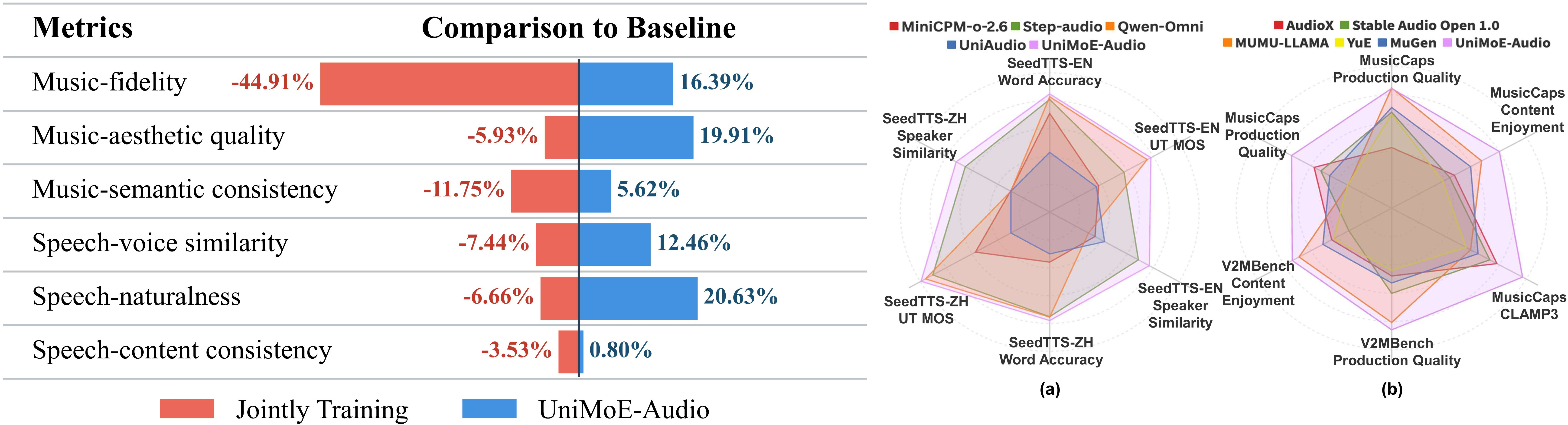
Figure 1: UniMoE-Audio outperforms naive joint training and specialized baselines, achieving synergistic gains in both speech and music generation tasks.
Architecture: Dynamic-Capacity MoE and Top-P Routing
UniMoE-Audio is built upon a Transformer backbone augmented with Dynamic-Capacity MoE layers. The core architectural innovations are:
- Top-P Routing: Unlike conventional Top-K routing, which statically assigns a fixed number of experts per token, Top-P routing dynamically selects the minimal set of experts whose cumulative routing probability exceeds a threshold p. This enables adaptive allocation of computational resources based on token complexity, improving both efficiency and expressivity.
- Hybrid Expert Design: The expert pool is functionally decoupled into three types:
- Routed Experts: Domain-specialized, activated conditionally for tokens requiring domain-specific knowledge.
- Shared Experts: Always active, responsible for domain-agnostic features.
- Null Experts: Parameter-free, enabling true computation skipping for simple tokens.
The model supports multimodal conditional inputs, including text, audio, and video, enabling tasks such as Voice Cloning, Text-to-Speech (TTS), Text-to-Music (T2M), and Video-to-Music (V2M).
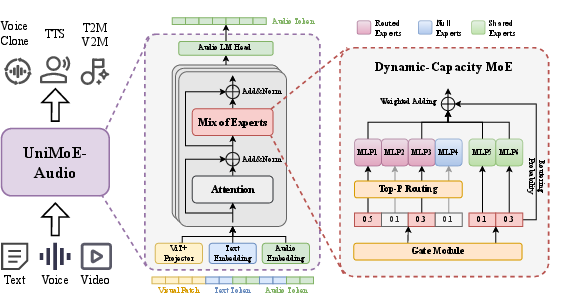
Figure 2: UniMoE-Audio framework overview, highlighting multimodal conditional inputs, the Transformer with Dynamic-Capacity MoE layers, and the Top-P routing strategy.
Implementation Details
- Audio Tokenization: Utilizes the DAC codec for efficient, multi-channel discrete token representation, with a multi-head output layer for all channels.
- Visual Embedding: Employs a ViT-based encoder with a projector to map visual features into the LLM embedding space.
- MoE Layer Output: For each token, the output is a weighted sum of selected experts' outputs, normalized by their gating probabilities.
Training Curriculum: Addressing Data Imbalance
The three-stage training curriculum is critical for mitigating data imbalance and preserving domain expertise:
- Independent Specialist Training: Each proto-expert is trained on its respective domain using the full, imbalanced raw dataset, ensuring maximal domain-specific knowledge acquisition.
- MoE Integration and Warmup: Proto-experts are integrated into the MoE architecture. The routing module and shared experts are exclusively trained on a balanced, high-quality dataset, with routed experts frozen, to calibrate the router and stabilize integration.
- Synergistic Joint Training: The entire model is unfrozen and fine-tuned end-to-end on the balanced dataset, with an auxiliary load-balancing loss to prevent expert collapse and encourage efficient routing.
Experimental Results
UniMoE-Audio achieves state-of-the-art or highly competitive results across a comprehensive suite of benchmarks and metrics for both speech and music generation. Notably:
Ablation and Comparative Analysis
- MoE vs. Dense Baseline: The dynamic-capacity MoE architecture consistently outperforms a dense baseline of equivalent parameter count, demonstrating the necessity of expert specialization and dynamic routing for multi-domain excellence.
- Data Imbalance Mitigation: The curriculum prevents catastrophic forgetting of data-scarce tasks (e.g., music, V2M), a failure mode observed in naive joint training.
Analysis of Training Dynamics and Expert Utilization
Training Loss Dynamics
The staged training approach is validated by loss curves, which show substantial loss reduction during the warmup phase and improved stability during joint training. The higher loss for music generation reflects its intrinsic complexity and justifies the need for architectural and curriculum innovations.
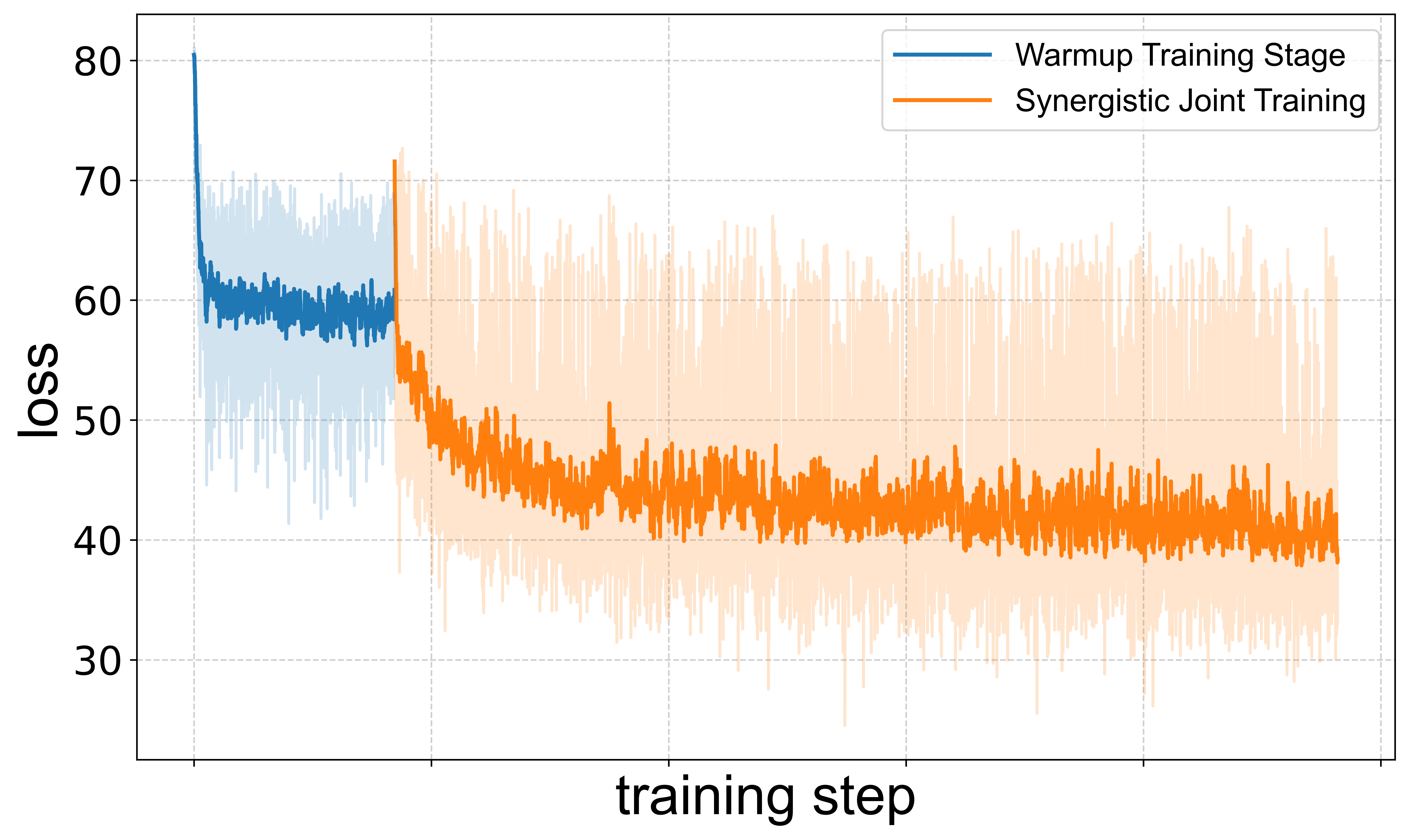
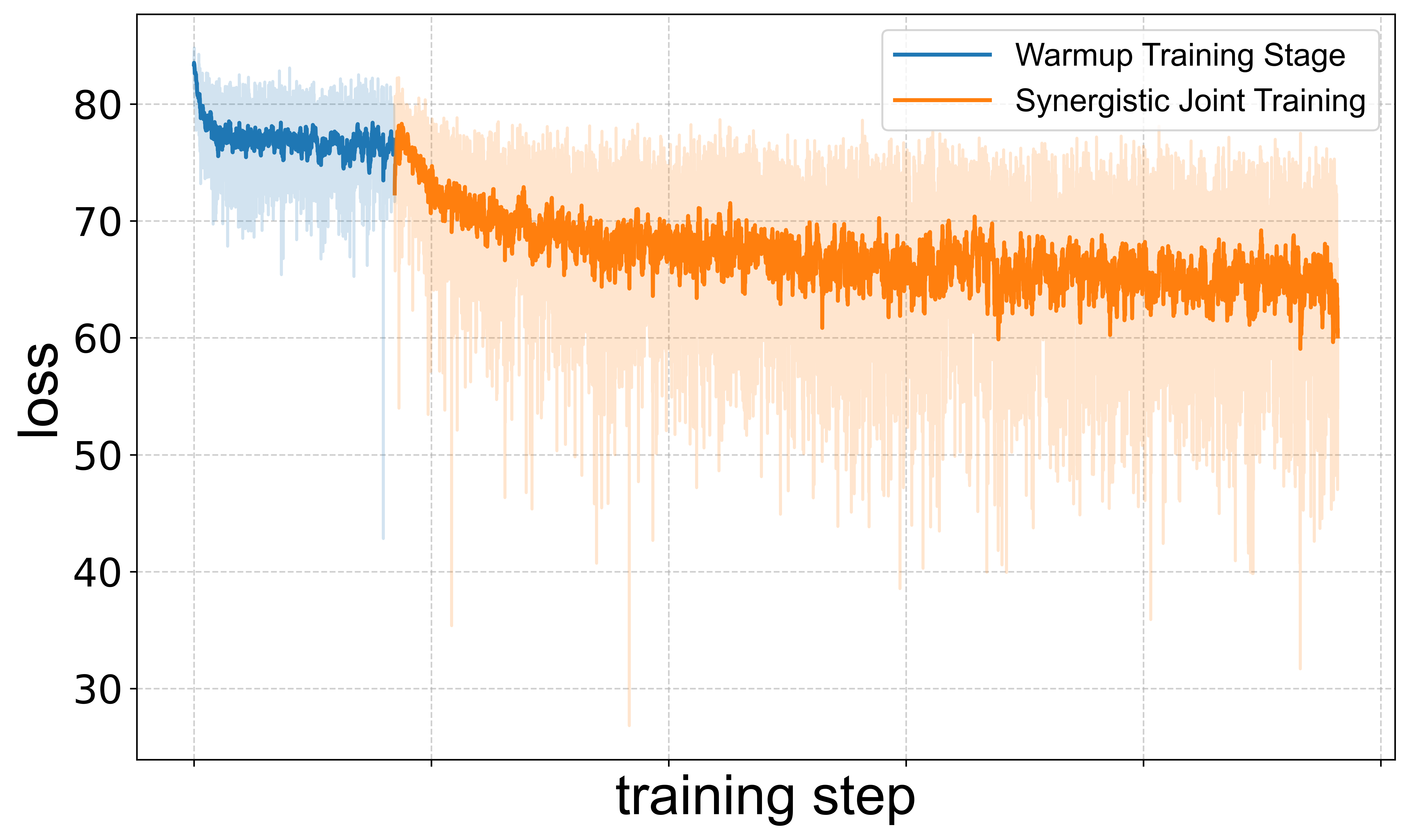
Figure 3: Training loss curves for speech (top) and music (bottom) tasks, illustrating the impact of warmup and joint training stages.
Dynamic Expert Allocation
Top-P routing enables non-uniform, layer-wise allocation of computational resources, with more experts activated in middle layers for complex feature abstraction and fewer in shallow/deep layers for low-level or output processing.
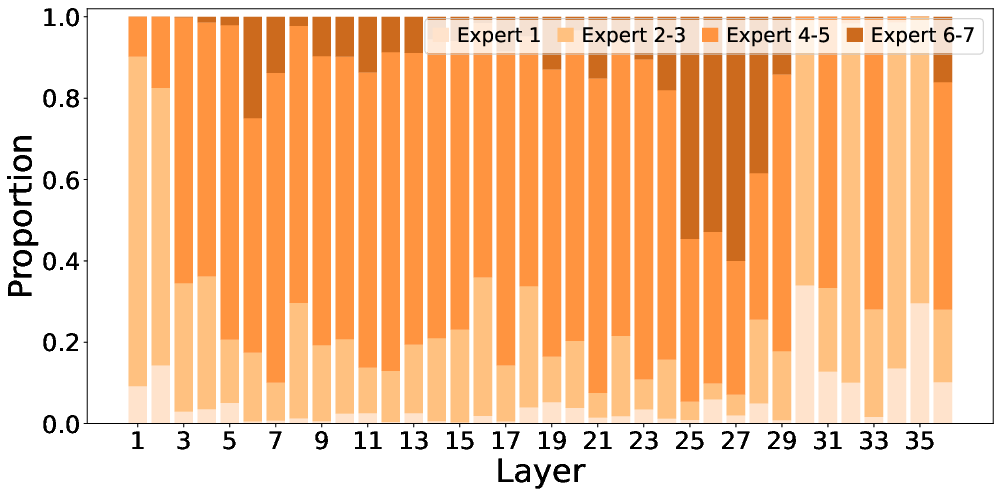
Figure 4: Proportion of tokens activating varying numbers of experts per layer, showing adaptive allocation with a "rise-and-fall" pattern.
Expert Routing and Specialization
Expert routing statistics reveal:
- Effective Load Balancing: All experts, including the null expert, are actively utilized, preventing expert collapse.
- Task Specialization: Experts 1-4 specialize in speech, 5-8 in music, with specialization increasing in deeper layers.
- Adaptive Computation: The null expert is preferentially activated for speech in deeper layers, indicating learned efficiency and task complexity awareness.
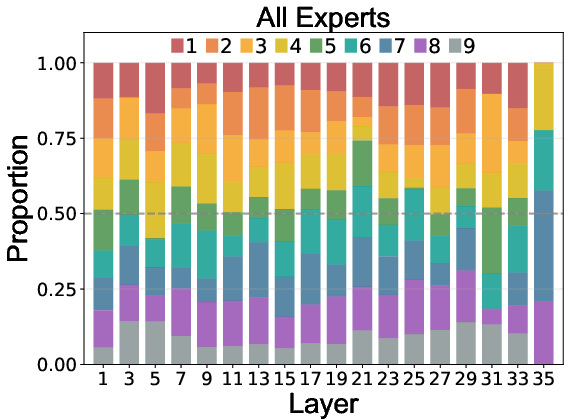
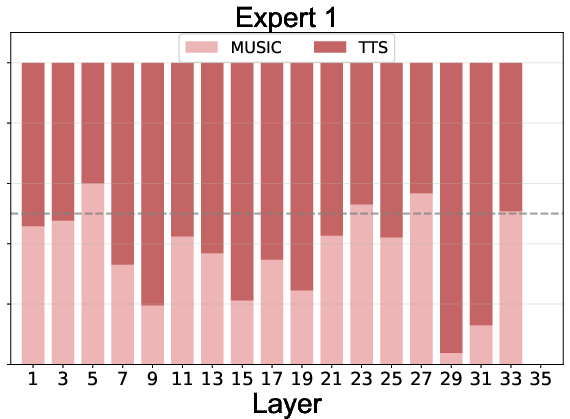
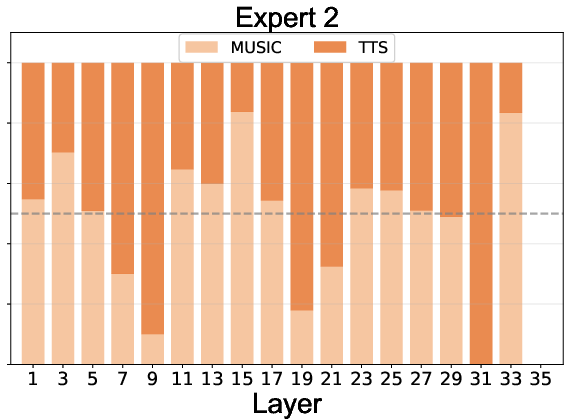
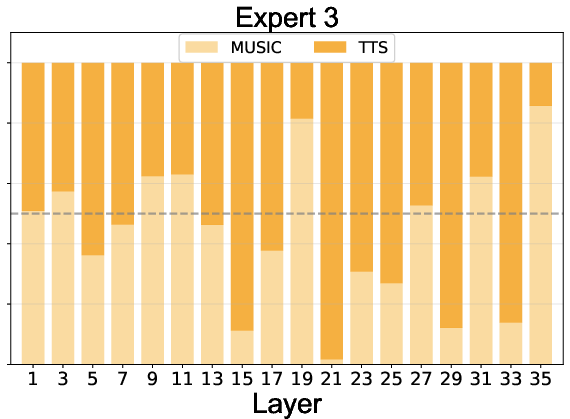
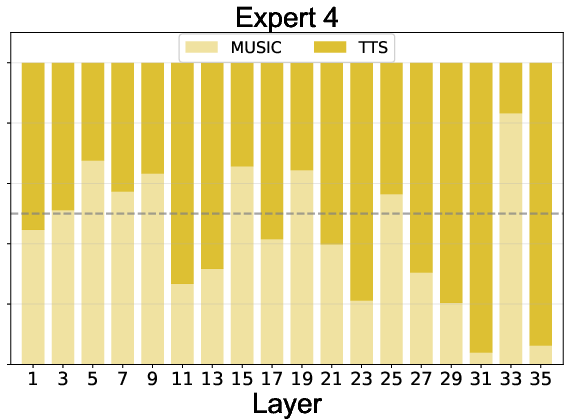
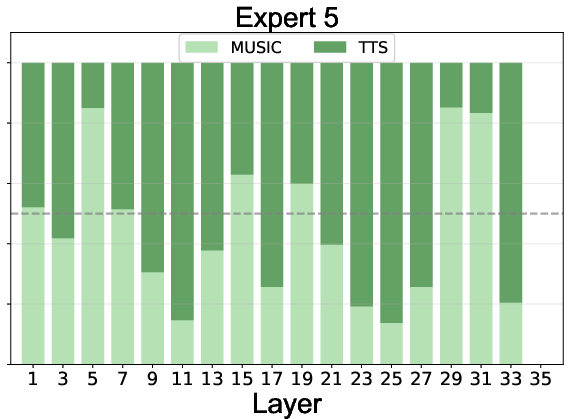
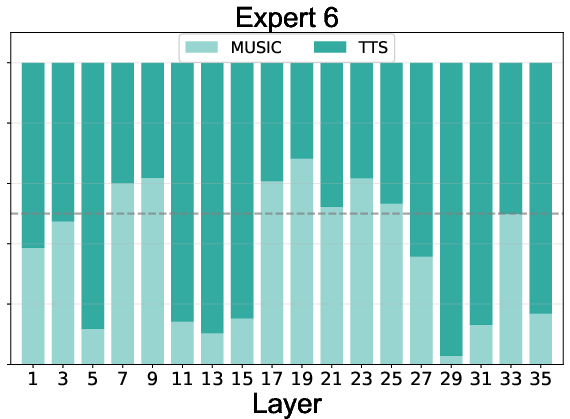
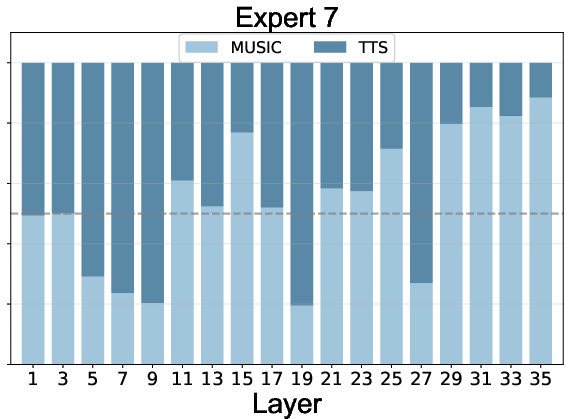
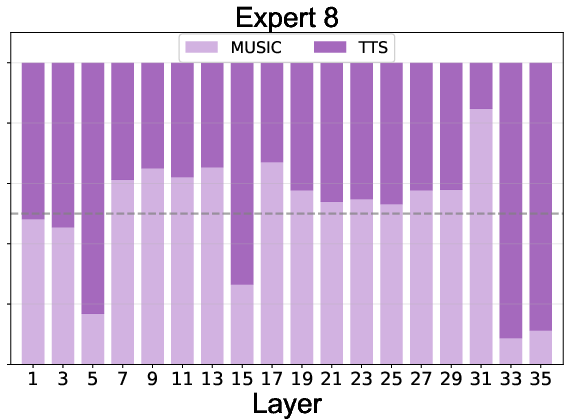
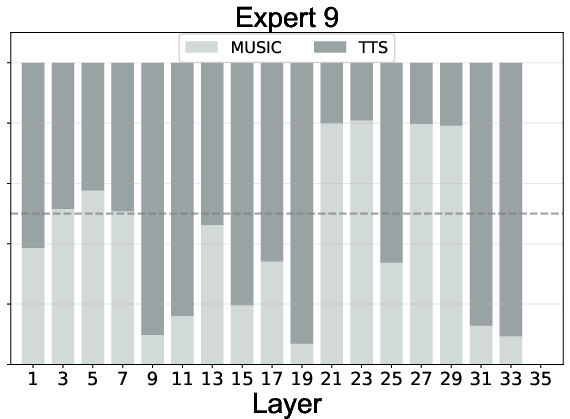
Figure 5: Expert routing dynamics across layers, showing task specialization and adaptive computation via the null expert.
Implications and Future Directions
UniMoE-Audio demonstrates that dynamic-capacity MoE architectures, when combined with a principled training curriculum, can overcome the longstanding challenges of task conflict and data imbalance in unified audio generation. The model's ability to achieve synergistic gains across speech and music tasks, without sacrificing performance in either domain, has significant implications for the development of truly universal audio generative models.
Potential future directions include:
- Extending the framework to additional audio modalities (e.g., sound effects, environmental audio).
- Further optimizing MoE architectures for efficiency and scalability.
- Investigating more granular expert specialization and routing strategies.
- Exploring transfer learning and continual learning scenarios in unified audio models.
Conclusion
UniMoE-Audio provides a robust and scalable solution to unified speech and music generation, leveraging dynamic-capacity MoE and a data-aware training curriculum to achieve state-of-the-art performance and cross-domain synergy. The architectural and methodological insights from this work offer a blueprint for future research in universal audio generation and multimodal generative modeling.