Accepted with Minor Revisions: Value of AI-Assisted Scientific Writing
Abstract: LLMs have seen expanding application across domains, yet their effectiveness as assistive tools for scientific writing -- an endeavor requiring precision, multimodal synthesis, and domain expertise -- remains insufficiently understood. We examine the potential of LLMs to support domain experts in scientific writing, with a focus on abstract composition. We design an incentivized randomized controlled trial with a hypothetical conference setup where participants with relevant expertise are split into an author and reviewer pool. Inspired by methods in behavioral science, our novel incentive structure encourages authors to edit the provided abstracts to an acceptable quality for a peer-reviewed submission. Our 2x2 between-subject design expands into two dimensions: the implicit source of the provided abstract and the disclosure of it. We find authors make most edits when editing human-written abstracts compared to AI-generated abstracts without source attribution, often guided by higher perceived readability in AI generation. Upon disclosure of source information, the volume of edits converges in both source treatments. Reviewer decisions remain unaffected by the source of the abstract, but bear a significant correlation with the number of edits made. Careful stylistic edits, especially in the case of AI-generated abstracts, in the presence of source information, improve the chance of acceptance. We find that AI-generated abstracts hold potential to reach comparable levels of acceptability to human-written ones with minimal revision, and that perceptions of AI authorship, rather than objective quality, drive much of the observed editing behavior. Our findings reverberate the significance of source disclosure in collaborative scientific writing.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What This Paper Is About
This paper studies whether AI writing tools (like smart chatbots) actually help scientists write better, especially the short summary at the start of a paper called an “abstract.” The authors set up a realistic mini-conference with expert writers and reviewers to see:
- how much people rely on AI-written text,
- what kinds of edits they make,
- and whether knowing that a piece of text was written by AI changes how people treat it.
What Questions The Researchers Asked
Here are the main questions, in simple terms:
- If scientists are given AI-written abstracts, how much do they edit them compared to human-written ones?
- Does telling people that “this abstract was written by AI” change how they edit?
- Do reviewers accept or reject abstracts differently depending on whether the text started out as AI or human?
- What kinds of edits (like fixing wording or structure) make an abstract more likely to be accepted?
How The Study Worked
To run a fair, controlled test, the team created a small, pretend conference and did a randomized experiment. Think of it like a science fair where:
- “Authors” (domain experts in computer science) were given abstracts to improve.
- “Reviewers” (other experts) judged the edited abstracts without seeing the editing process.
Here’s the setup explained with everyday language:
- Abstracts: The team picked 45 recent computer science papers from top conferences. They used an AI model (GPT-4o) to create AI versions of these abstracts based on carefully extracted “research excerpts” from the original papers. This ensured the AI text was factually grounded.
- Two-by-two design: Authors were randomly placed into one of four groups: 1) Human-written abstract, no source info given 2) AI-generated abstract, no source info given 3) Human-written abstract, source disclosed (“this was written by a human”) 4) AI-generated abstract, source disclosed (“this was written by AI”)
- Editing: Authors edited the provided abstract in a custom web tool that tracked every keystroke (like a detailed “edit history”) so researchers could measure how much the text changed. Copy-paste into other tools was blocked to make sure the edits were truly theirs.
- Incentives: Authors earned a base payment and could win bonuses if their edited abstract got accepted. Reviewers also earned bonuses for careful, consistent judging. This motivated everyone to do their best.
- Reviewing: Each edited abstract was rated by three independent reviewers who compared it with the original abstract and decided whether the edited version did the research “justice.” A majority vote (2 out of 3) determined the final decision.
Technical terms explained:
- Randomized controlled trial: Like flipping a coin to fairly assign people to different conditions, so comparisons are trustworthy.
- Keystroke-level edits: The system recorded every single character added, deleted, or changed, to precisely measure editing effort.
- Double-blind elements: Reviewers didn’t know who edited what and weren’t told about the source during their decisions, reducing bias.
What They Found
The researchers reported several clear patterns:
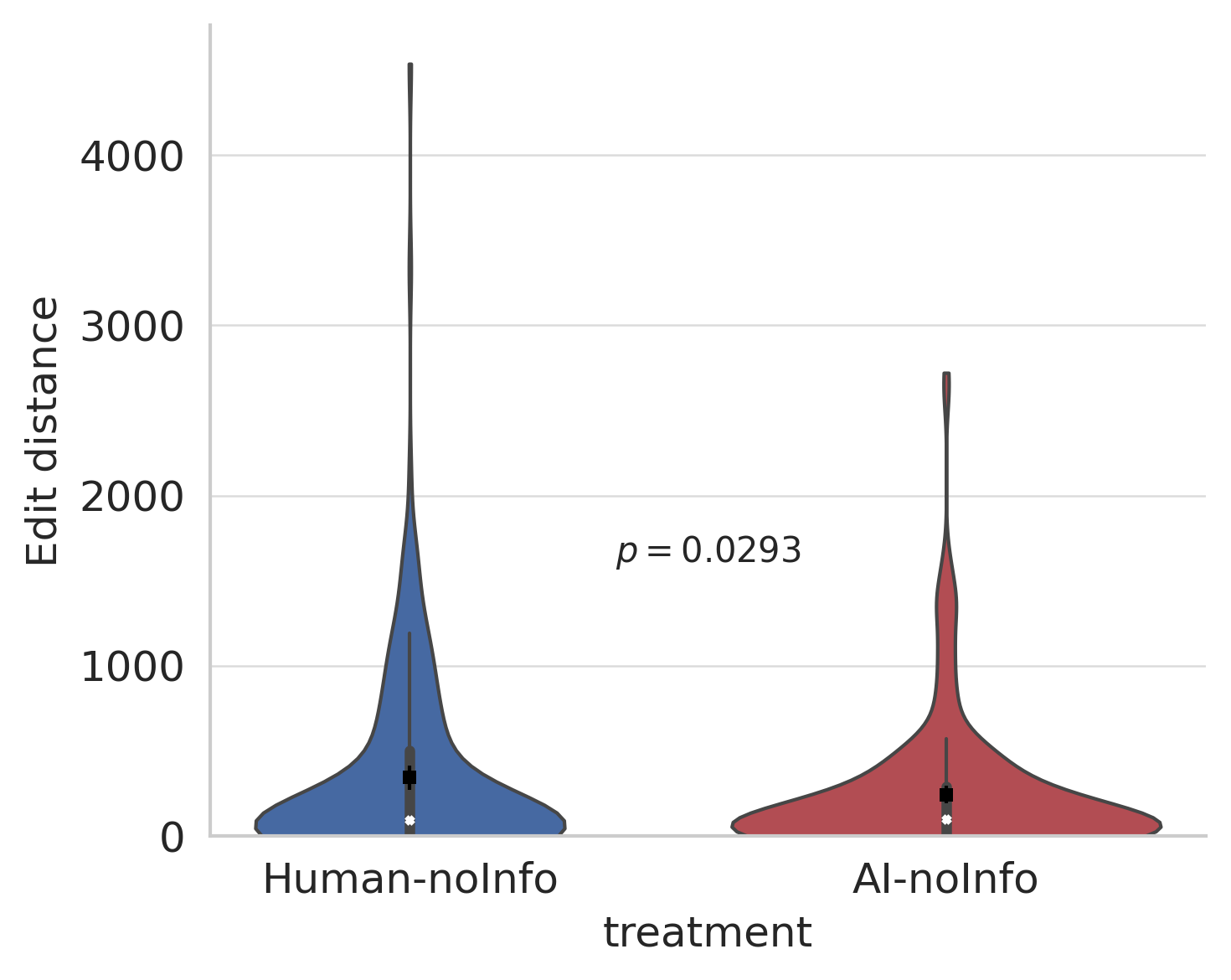
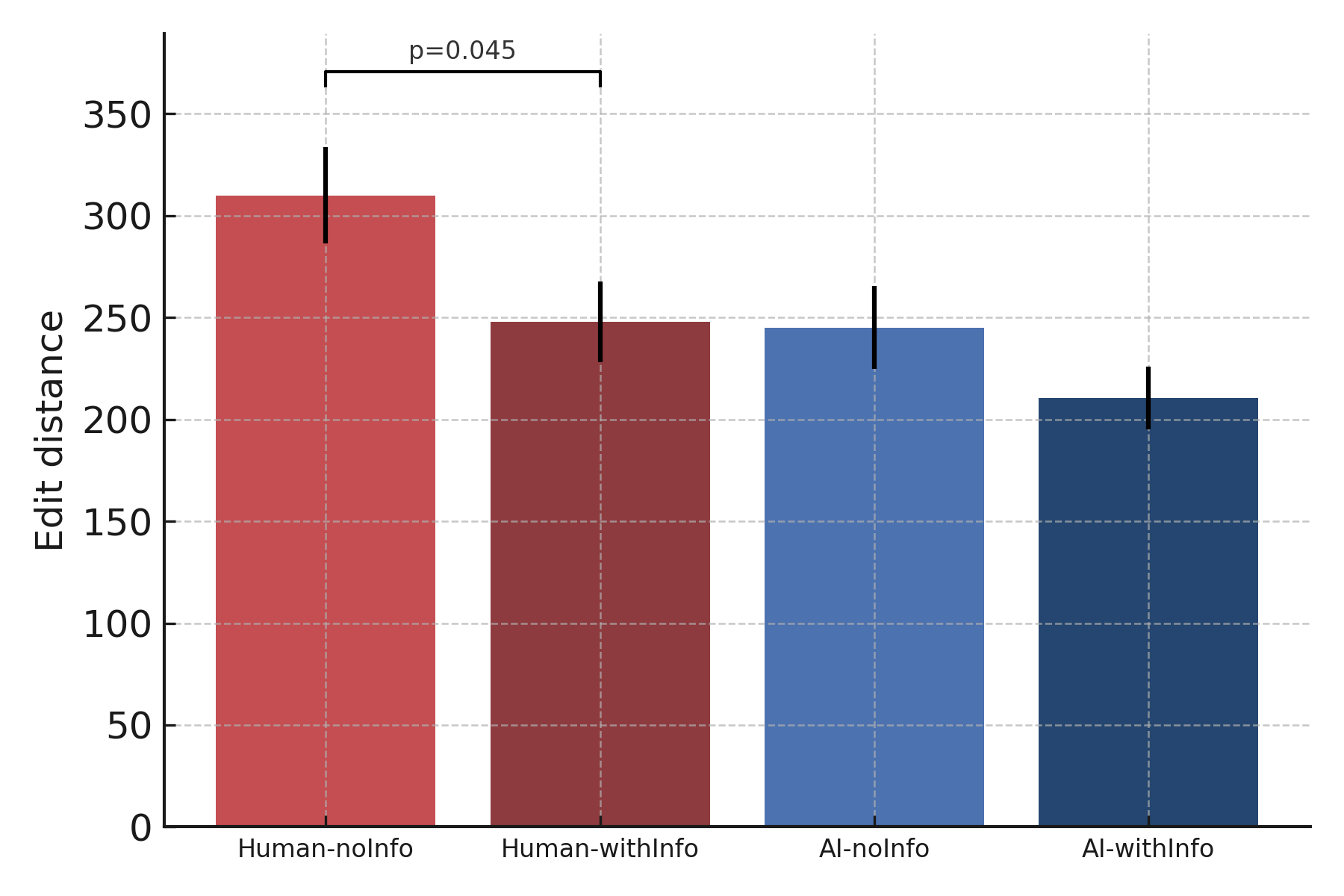
- When source wasn’t disclosed:
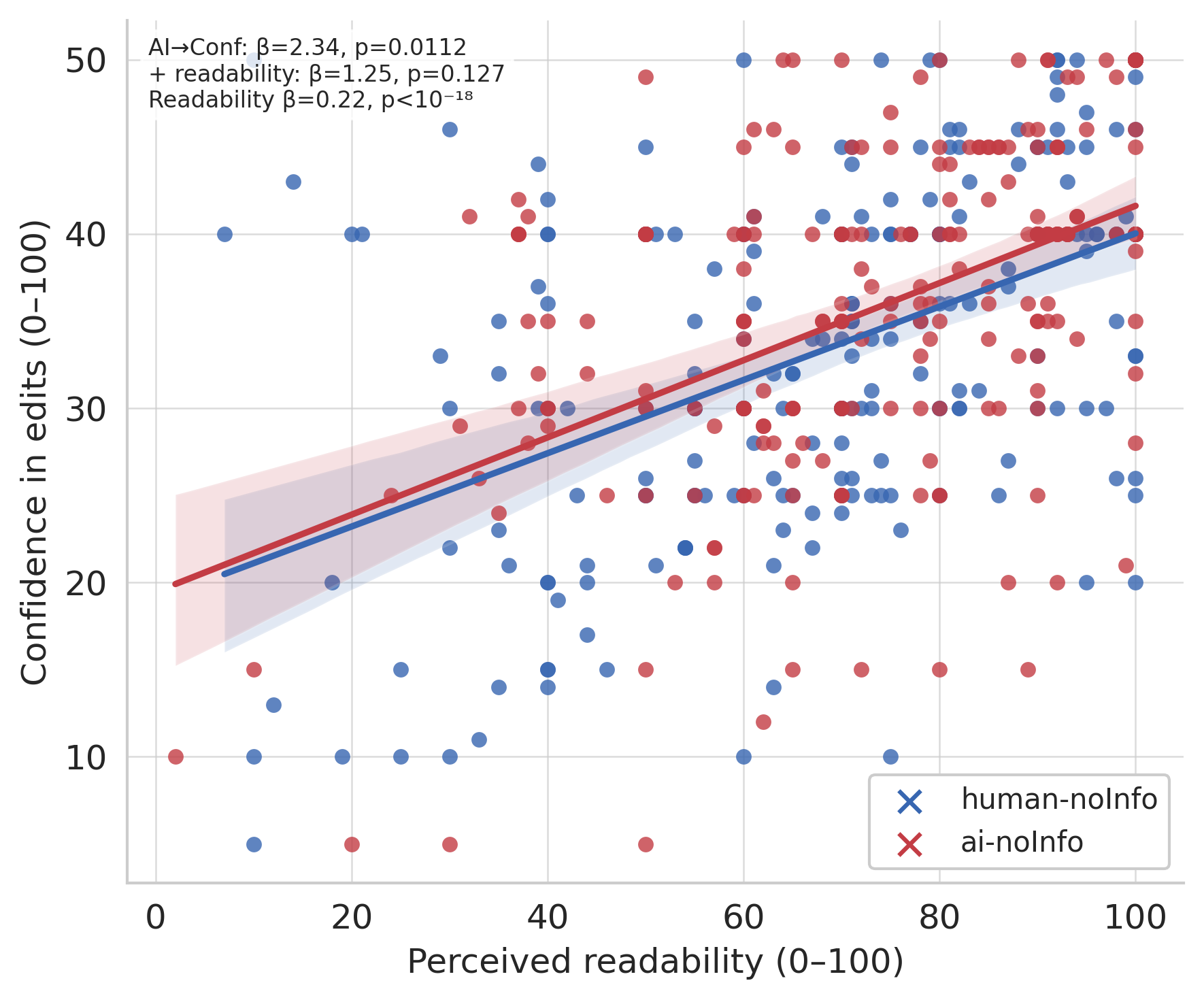
- Authors made fewer edits to AI-generated abstracts than to human-written ones. Many felt the AI text was already very readable and closer to “ready to submit.”
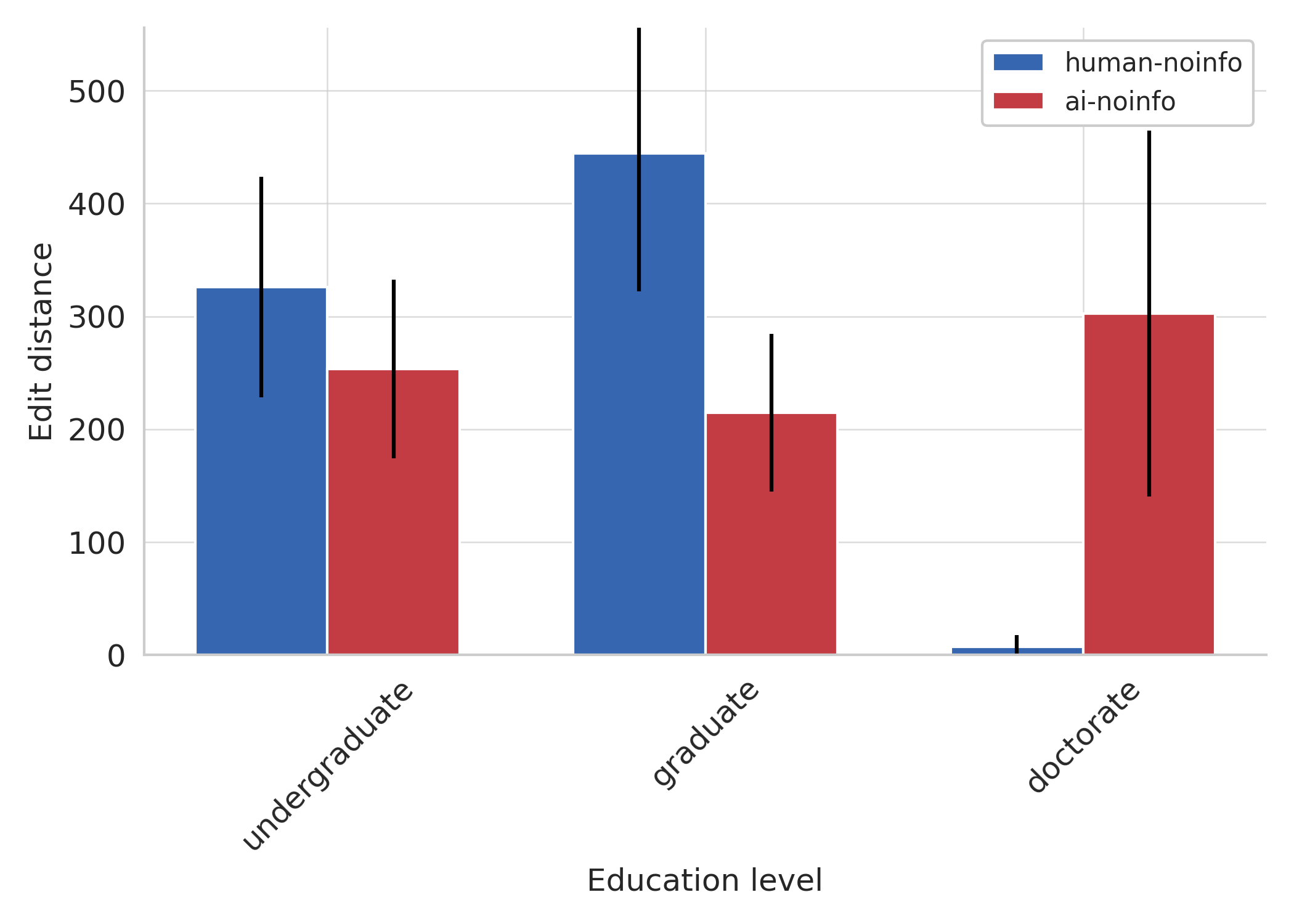
- Exception: Authors with PhDs made more edits to AI-generated abstracts, suggesting that more experienced writers spot subtle issues AI can miss.
- When source was disclosed (“this is AI” vs “this is human”):
- Editing effort became more similar across both types. Knowing the source seemed to change editing attitudes.
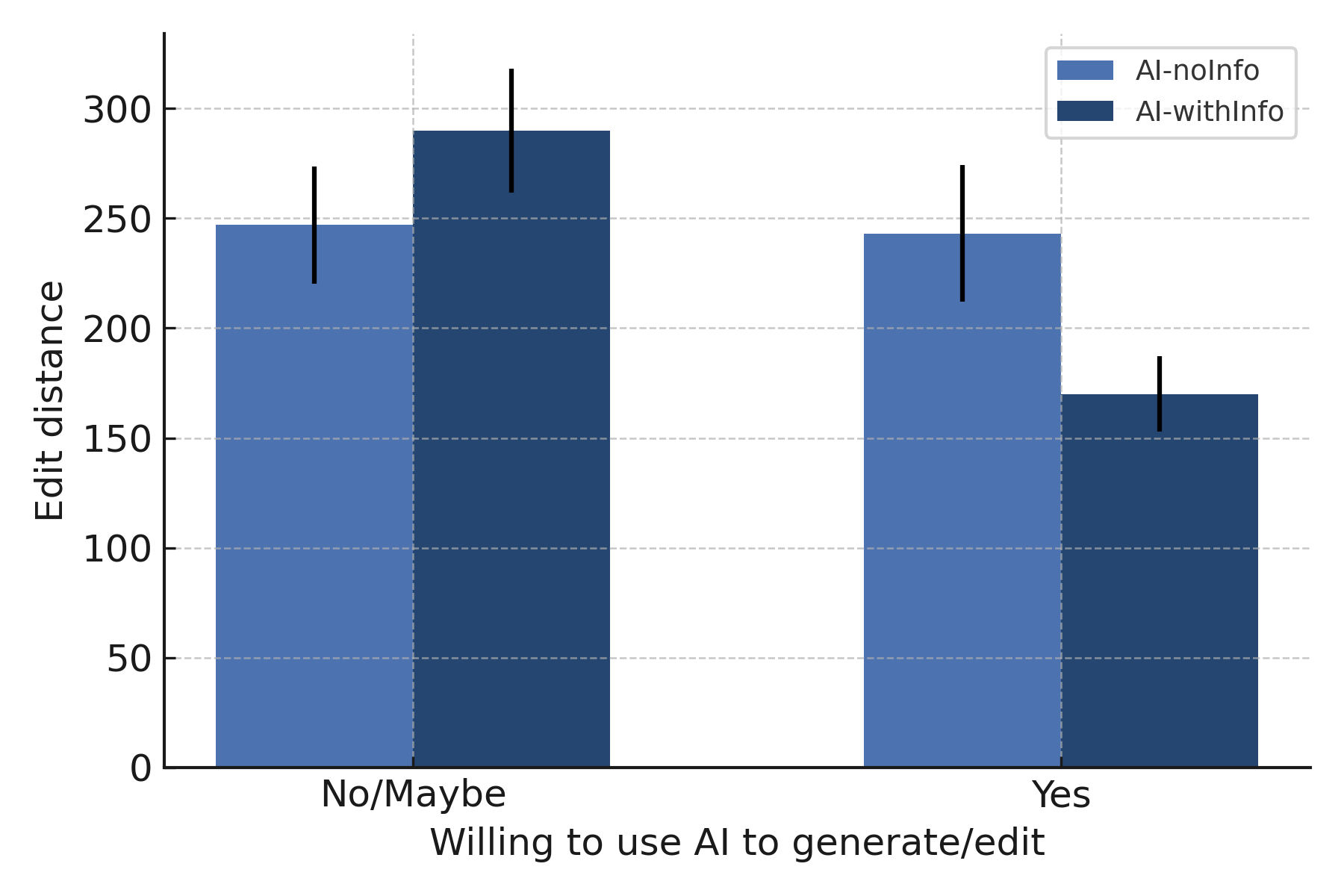
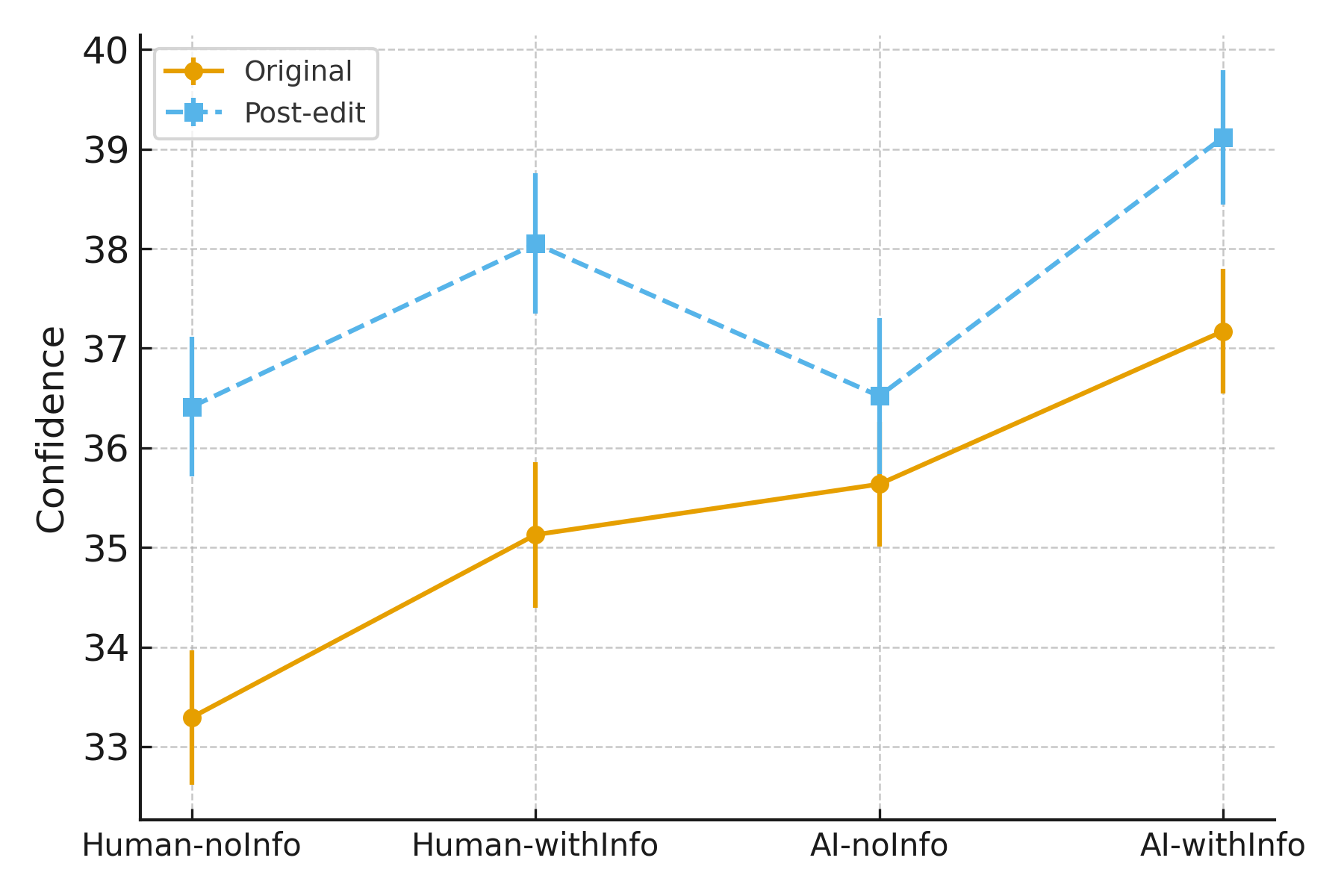
- Authors made careful, stylistic tweaks to AI-written abstracts when the AI label was shown, which increased the chances of acceptance.
- Reviewer decisions:
- Reviewers didn’t accept or reject abstracts based on whether they began as AI or human. They focused on the final edited quality.
- However, they were influenced by how much authors edited: more thoughtful edits tended to lead to acceptance.
- Types of edits:
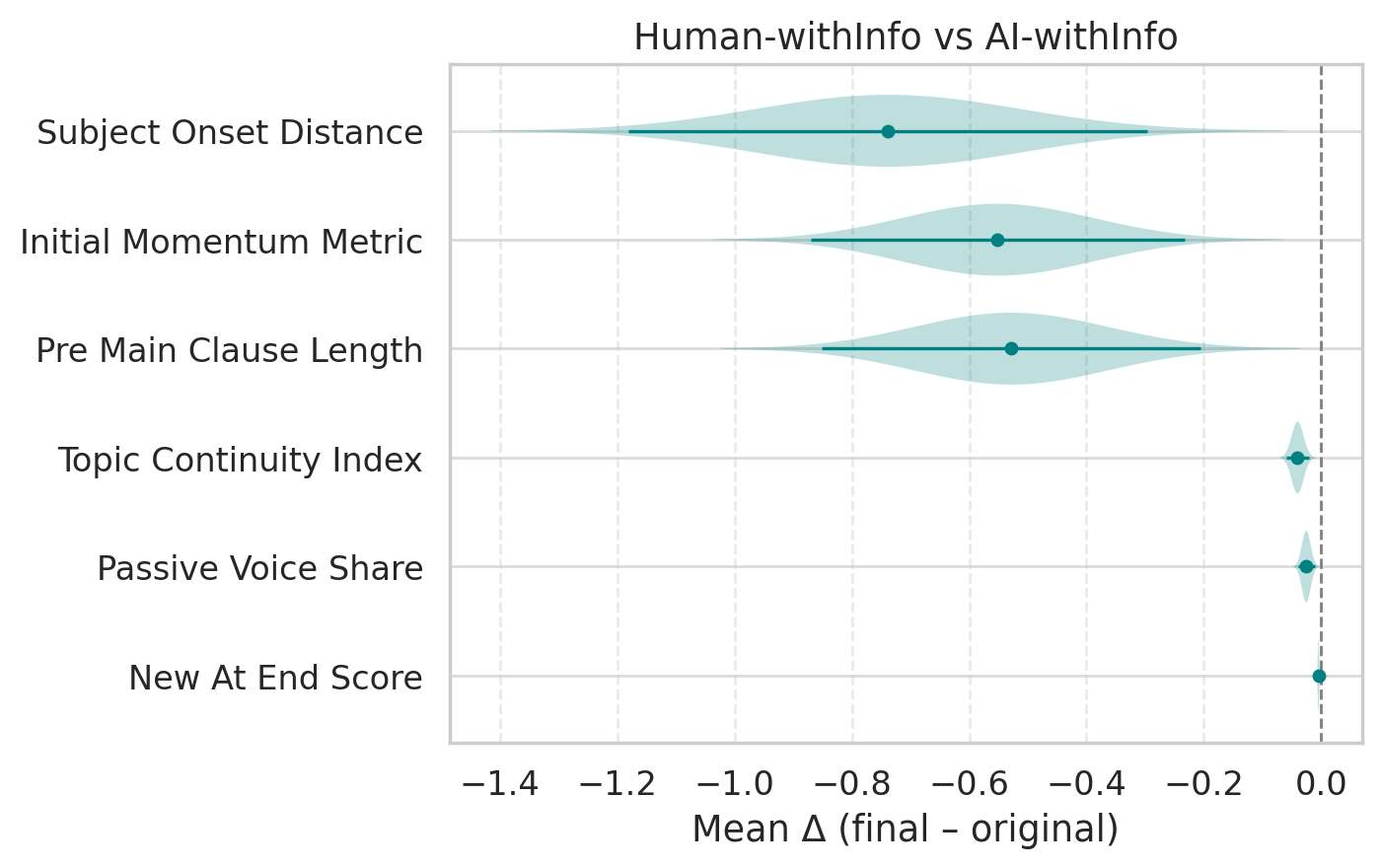
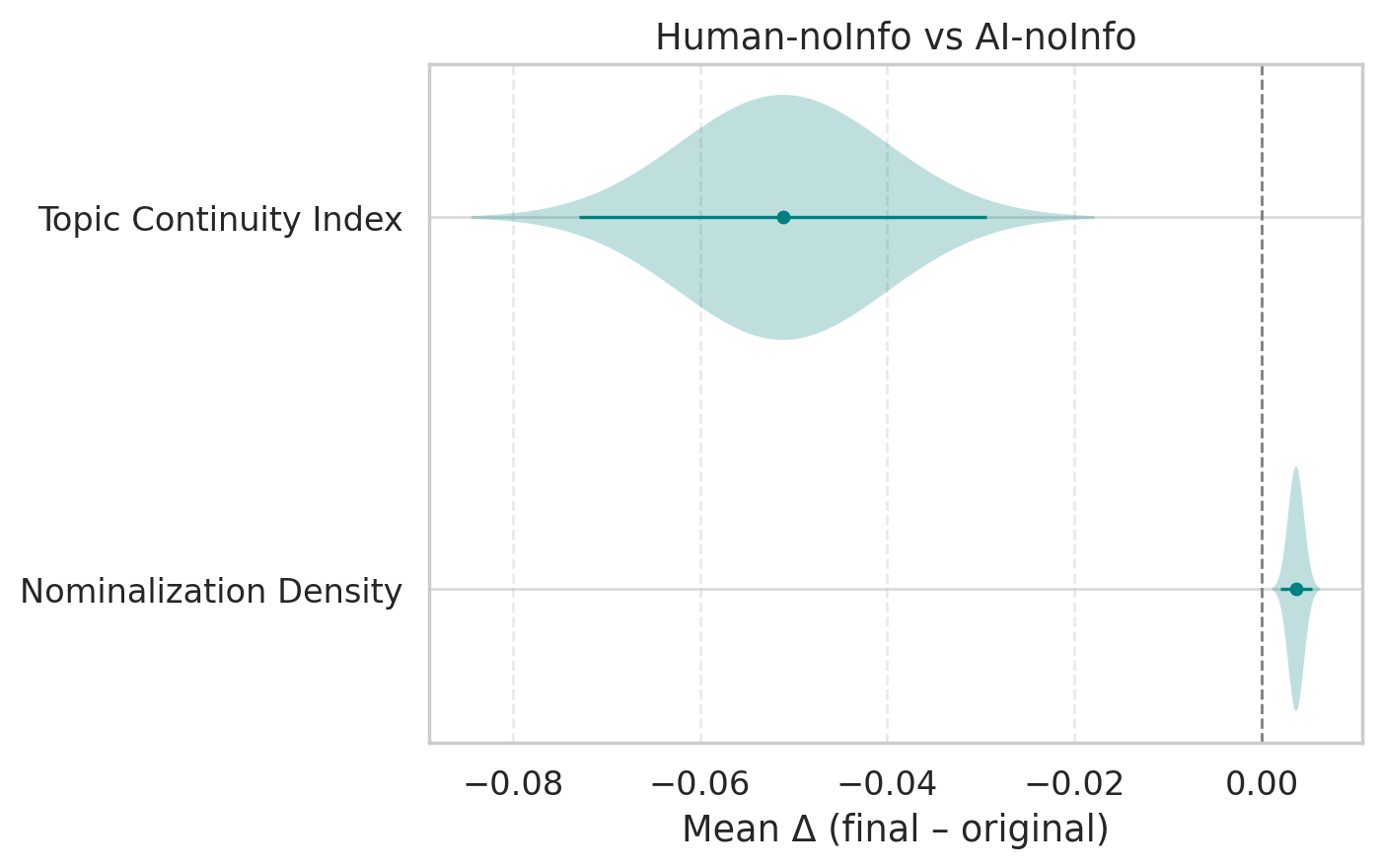
- For AI-generated abstracts, authors often improved flow, reduced overly “noun-heavy” wording (nominalizations), and made sentences more informative and cohesive.
- For human-written abstracts, authors tended to make the opening longer or reshaped the structure for emphasis.
- Disclosure itself (just knowing the source) made only small changes to writing style, but it affected how accountable and careful people felt.
- Big takeaway:
- AI-generated abstracts can reach similar acceptability to human-written ones with relatively minimal, smart human revisions.
- People’s behavior was strongly affected by perceptions of AI authorship—not just the actual quality of the text.
Why This Matters
- For scientists and students: AI can be a helpful writing starting point, but human editing still matters—especially for clarity, structure, and style.
- For journals and conferences: Transparency (disclosing when AI was used) influences editing effort and may lead to better final submissions without biasing reviewers.
- For tool builders: Improving AI’s cohesion and reducing vague or overly complex wording could make drafts even closer to submission-ready.
- For education and policy: Teach users to critically edit AI drafts and encourage source disclosure to build trust and accountability.
Simple Conclusion
AI writing tools can produce solid first drafts of scientific abstracts. When people don’t know where the text came from, they often trust AI writing to be pretty polished. But when told “this was written by AI,” they edit more carefully—and those careful edits make the abstract more likely to be accepted. Reviewers judge the final quality, not the source. Overall, the best results come from combining AI’s speed with humans’ judgment and transparency about how the text was made.
Knowledge Gaps
Below is a single, actionable list of knowledge gaps, limitations, and open questions that remain unresolved and can guide future research.
- Generalizability beyond computer science—results were obtained only in CS; test whether patterns hold in other disciplines (e.g., biomedicine, social sciences) with differing writing norms, stakes, and reviewer cultures.
- Full-manuscript applicability—study focuses on abstracts; evaluate AI assistance on full papers (methods, results, discussion, figures, tables, citations) where factual precision, structure, and multimodal synthesis are harder.
- Effect of allowing actual co-writing—authors were prohibited from using external AI during editing; compare forced manual editing to realistic co-writing workflows with AI suggestions, iterative prompts, and revision cycles.
- Model dependence—AI-generated abstracts were produced by GPT-4o only; benchmark across multiple LLMs, versions, and prompting paradigms to test robustness and model-specific effects.
- Generation pipeline validity—LLM-produced abstracts were built from curated excerpts extracted by the same model; assess biases introduced by excerpt selection, compare to human-prepared excerpts, and test generation from raw notes or incomplete inputs.
- Attribution modalities—only binary disclosure (AI vs human) to authors was studied; evaluate alternative disclosures (e.g., “co-authored with AI,” confidence levels of AI involvement, provenance metadata) and their impact on editing behavior.
- Reviewer-side disclosure—reviewers were blinded to source; test whether disclosing AI authorship to reviewers changes accept decisions, calibration, and perceived credibility.
- Measurement of reliance—using edit distance as reliance proxy may conflate quality with effort; develop richer dependence measures (e.g., semantic edit types, structural changes, time-on-task, intentionality) and validate against independent quality assessments.
- Edit quality vs edit quantity—volume of edits correlated with acceptance, but causal mechanisms are unclear; identify which specific edit types (e.g., cohesion improvements, de-nominalization, restructuring) most strongly drive acceptance.
- Baseline quality control—original abstracts (from published papers) may be high-quality; calibrate results by varying baseline quality, including weaker human-written abstracts, and normalize acceptance outcomes accordingly.
- Reviewer evaluation construct—“justice to the original” emphasizes alignment rather than absolute quality; include blind, standalone quality ratings, readability metrics, and domain adequacy without referencing the original.
- Inter-rater reliability—majority vote was used without reported reliability; compute and report kappa/ICC, examine reviewer calibration, and mitigate fatigue/order effects in multi-abstract assignments.
- Topic familiarity effects—authors were randomly assigned abstracts; quantify how topic expertise modulates editing behavior, reliance on AI, and acceptance outcomes; consider matching authors to subfield familiarity levels.
- Time dynamics—analyze time spent per abstract and per edit, fatigue, and session-level learning; test whether longer editing leads to better outcomes and whether there are diminishing returns.
- Longitudinal impacts—assess whether repeated AI-assisted editing changes writers’ skills, trust, algorithm aversion/automation bias, and reliance over time; test lasting effects on writing competence.
- Detection and perception—without disclosure, do authors or reviewers infer source? Measure perceived AI authorship, detection accuracy, and how misattribution (intentional or accidental) influences behavior and outcomes.
- Factuality stress-tests—excerpts ensured factual grounding; evaluate AI-assisted writing when inputs are partial, noisy, or ambiguous, including the prevalence and detection of hallucinations introduced by either AI or human edits.
- Cross-linguistic and non-native contexts—most authors were native English speakers; study non-native authors, other languages, and cross-cultural review norms where AI’s stylistic and grammatical assistance may have different effects.
- Ecological validity of incentives—performance-contingent rewards may induce strategic editing behaviors; compare outcomes under varied incentive designs and in non-incentivized, naturalistic settings (e.g., class assignments, journal submissions).
- Real-world peer review—lab evaluation differs from conference/journal review with full manuscripts, scope checks, and novelty assessment; test interventions in real submission pipelines or controlled shadow-review settings.
- Interface design factors—editing was done in Firepad without suggestion features; assess how interface affordances (e.g., sentence vs paragraph suggestions, explainability, provenance tracing) shape editorial strategies and outcomes.
- Ethical and policy guidance—identify best practices for AI authorship disclosure, credit attribution, and accountability in collaborative scientific writing; test how different policies affect behavior and acceptance.
- Dataset transparency and replication—clarify data/code availability, anonymization, and reproducibility; enable multi-site replications, cross-domain studies, and meta-analyses.
- Subfield heterogeneity—analyze whether effects vary across CS subfields (e.g., NLP vs systems) or venues; extend reviewer assignment and author matching to quantify subfield-specific dynamics.
- Demographic and social factors—beyond education, systematically test the roles of gender, career stage, and attitudes toward AI in editing strategies and acceptance; use pre-registered hypotheses to isolate causal pathways.
Practical Applications
Immediate Applications
The following list distills actionable, near-term uses that can be deployed with current tools and processes. Each item notes sector(s), likely tools/products/workflows, and key assumptions or dependencies.
- Source disclosure policies in manuscript submissions
- Sectors: academia, scholarly publishing policy
- Tools/workflows: mandatory AI-use disclosure fields in submission portals (e.g., OpenReview, Editorial Manager), standardized author statements on AI assistance
- Assumptions/dependencies: relies on honest self-reporting; detection is unreliable, so compliance culture and clear guidelines are essential; findings are based on CS abstracts, not full papers
- AI-first abstract drafting with human stylistic revision
- Sectors: academia, research labs, software (writing platforms)
- Tools/workflows: Overleaf/Word plugins that generate draft abstracts from research excerpts, followed by guided human edits focusing on cohesion, reducing nominalizations, and informative sentence construction (as identified in the study)
- Assumptions/dependencies: current LLMs (e.g., GPT-4o) produce readable drafts that need targeted, careful edits; generalization beyond CS abstracts needs validation
- Style-focused editing assistance for scientific prose
- Sectors: software (authoring tools), academia
- Tools/products: “Scientific Style Checker” modules that flag nominalizations, cohesion issues, and sentence informativeness in AI-generated text; real-time revision suggestions and metrics dashboards
- Assumptions/dependencies: stylistic metrics and edit heuristics derived from CS abstracts; may need domain tuning for other fields
- Keystroke-level edit telemetry for writing courses and HCI studies
- Sectors: education, HCI research, writing centers
- Tools/workflows: Firepad-like editors that capture character-level edits with timestamps; assignment designs that reward quality revisions; privacy-preserving data collection and consent flows
- Assumptions/dependencies: IRB/ethics compliance; storage and security for telemetry data; institutional buy-in
- Reviewer assignment pipeline using topical similarity and constrained optimization
- Sectors: academic conferences/journals (software), research operations
- Tools/workflows: Semantic Scholar/G Scholar profile ingestion, LLM-based semantic similarity scoring, min-cost flow optimization to assign reviewers while avoiding contamination across versions
- Assumptions/dependencies: access to reviewer metadata and citations; fairness and workload constraints; deployment within conference tooling
- Reviewer guidance and rubrics that ignore source identity
- Sectors: academia, peer review policy
- Tools/workflows: rubrics emphasizing clarity, fidelity to results, and coherence, not origin; explicit training to counter algorithm aversion/automation bias
- Assumptions/dependencies: study shows reviewer decisions were unaffected by source under no-disclosure; consistent implementation and reviewer education needed
- Incentive-aligned editing tasks for internal tool evaluations
- Sectors: industry (AI product teams), academia (UX/HCI labs)
- Tools/workflows: randomized controlled trials with performance-contingent rewards and confidence calibration bonuses to evaluate AI-assisted writing tools
- Assumptions/dependencies: budget for incentives; experimental design expertise; results depend on task scope (abstracts vs. full papers)
- Editorial dashboards correlating edit volume and acceptance likelihood
- Sectors: journals, conference program committees, writing support services
- Tools/products: analytics panels that show edit-distance and types of edits alongside acceptance outcomes; triage queues for editorial support
- Assumptions/dependencies: observed correlation in this study; caution—correlation ≠ causation; domain-specific calibration needed
- Collaboration features that nudge accountability via disclosure toggles
- Sectors: software (collaborative editors), academia, industry teams
- Tools/workflows: UI indicators of AI-authored segments, version history with attribution, “disclosure mode” to influence careful editing behavior when appropriate
- Assumptions/dependencies: UX needs experimentation to balance algorithm aversion and automation bias; privacy and team norms matter
- Personal writing checklists for AI-assisted summaries
- Sectors: daily life, education
- Tools/workflows: lightweight checklists for revising AI drafts—simplify overly fluent text, fix cohesion, reduce nominalizations, ensure informativeness; sliders for self-rated acceptance confidence
- Assumptions/dependencies: transferability from scientific abstracts to general summaries; user discipline in applying the checklist
Long-Term Applications
The following opportunities require further research, scaling, productization, or policy development. Each item notes sector(s), likely tools/products/workflows, and key assumptions or dependencies.
- Bias-aware editor UX to counter algorithm aversion and automation bias
- Sectors: software (authoring platforms), HCI research
- Tools/workflows: controlled disclosures, suggestion granularity tuning (sentence vs. paragraph), accountability cues; A/B tested UX interventions to modulate cognitive biases
- Assumptions/dependencies: cross-domain validation; careful ethical design to avoid undue influence
- LLM training using human edit traces to improve scientific style
- Sectors: AI/ML model development, academia
- Tools/workflows: datasets of keystroke-level edits for RLHF/SFT; objective functions targeting cohesion, nominalization reduction, informativeness
- Assumptions/dependencies: large-scale, consented datasets; privacy-preserving pipelines; domain coverage beyond CS
- End-to-end AI co-authoring systems with excerpt extraction and safe generation
- Sectors: software (research tooling), academia, enterprise R&D
- Tools/workflows: pipelines that extract factual research “excerpts,” generate drafts, and enforce attribution + edit audit trails; human-in-the-loop governance
- Assumptions/dependencies: robust factuality safeguards; integration with experiment planning and data analysis tools; standards for provenance
- Standardized, machine-readable AI contribution metadata and audit trails
- Sectors: policy (funders, journals), standards bodies
- Tools/workflows: metadata schemas for AI assistance, edit provenance logs, repository-linked disclosure; compliance audits
- Assumptions/dependencies: community consensus; interoperability across submission systems; privacy concerns for telemetry
- Peer-review process reform for AI attribution handling
- Sectors: academia, scholarly societies
- Tools/workflows: controlled experiments on when to disclose AI source to authors/reviewers; policies that maximize fairness and quality
- Assumptions/dependencies: broader, cross-disciplinary evidence; stakeholder buy-in
- Acceptance predictors beyond edit volume
- Sectors: software (author support), academia
- Tools/workflows: models using multi-feature signals (stylistic metrics, semantic fidelity, reviewer comments) to forecast acceptance likelihood and recommend edits
- Assumptions/dependencies: large labeled datasets across venues; risk of gaming; ethical considerations
- Enterprise content quality management via edit telemetry
- Sectors: industry (regulated content, technical documentation)
- Tools/workflows: dashboards monitoring reliance on AI drafts, edit quality, and reviewer outcomes; governance policies for disclosure and accuracy
- Assumptions/dependencies: legal/privacy compliance; sector-specific quality standards
- Scalable educational curricula integrating edit analytics
- Sectors: education (graduate programs, writing centers)
- Tools/workflows: programmatic assignments with telemetry, incentive-compatible confidence calibration, and feedback loops on style targets
- Assumptions/dependencies: LMS integration, IRB/ethics, faculty training
- Cross-domain extension to healthcare, law, finance, and engineering
- Sectors: healthcare, legal, finance, engineering
- Tools/workflows: domain-tuned style assistants and disclosure policies; trials on abstracts, executive summaries, case reports, and regulatory filings
- Assumptions/dependencies: domain-specific conventions and stakes; rigorous validation; varying tolerance for AI-origin text
- Shift from AI detection to “process disclosure and audit” frameworks
- Sectors: policy, compliance, publishing
- Tools/workflows: verifiable process logs, attestation mechanisms, audit-friendly editors; reduced reliance on unreliable detectors
- Assumptions/dependencies: standards development; acceptance by institutions; careful balance of transparency and privacy
Cross-cutting assumptions and dependencies
- Scope limits: findings are for CS abstracts, not full papers; replication needed across disciplines and document types.
- Model choice: GPT-4o was used; performance and behaviors may shift with different or future models.
- Experimental setting: incentivized RCT in a simulated conference environment; external validity should be assessed in live venues.
- Ethical and privacy considerations: keystroke-level logging and attribution features require consent, secure storage, and clear governance.
- Reviewer behavior: source-independent acceptance observed under no-disclosure conditions; policy decisions on disclosure should weigh author behavior effects against reviewer outcomes.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim usage example.
- 2×2 between-subject design: An experimental setup with two independent variables, each having two levels, where different participants experience different treatment combinations. "Our between-subject design expands into two dimensions: the implicit source of the provided abstract and the disclosure of it."
- Algorithm aversion: A tendency to prefer human judgment over algorithmic outputs even when algorithms perform as well or better. "On the other hand, algorithm aversion describes a tendency to prefer human judgment over algorithmic judgment, even in cases where the algorithm is demonstrably better or equivalent"
- Automation bias: The tendency to over-rely on automated systems, using them as shortcuts and potentially overlooking errors. "On one hand, automation bias describes the tendency to over-rely on or excessively trust automated outputs, often using them as a cognitive shortcut to reduce mental effort"
- Between-subject experiment: A study design where each participant is assigned to only one condition, enabling comparisons across independent groups. "In a between-subject experiment, we compare two treatments, Human-noInfo and AI-noInfo."
- Binarize: To convert a continuous or multi-valued measure into two categories (e.g., accept/reject). "If the score is , then we binarize that decision to be \"Accept\" (else \"Reject\") since the original abstract is from a published work."
- Cohesion: The property of a text where sentences and ideas connect smoothly, aiding readability and comprehension. "Our quantitative analysis of stylistic metrics reveals that edits to AI-generated abstracts are to improve cohesion, reduce nominalizations, and produce informative sentences."
- Double-blind: A protocol in which both authors and evaluators (or evaluators and subjects) lack key source information to reduce bias. "The edited abstracts are then evaluated by a group of (incentivized) reviewers in a double-blind fashion, who vote to accept or reject the submitted abstract."
- Ecological validity: The extent to which study conditions reflect real-world settings and behaviors. "Second, the widespread adoption of AI tools by researchers in CS provides ecological validity for examining human-AI collaboration in this context."
- Errors of commission: Mistakes that result from acting on incorrect information provided by automation. "This can lead to errors of commission (accepting incorrect AI-generated information) and errors of omission (failing to notice problems that the AI missed)"
- Errors of omission: Mistakes that result from failing to act or notice issues that automation did not flag. "This can lead to errors of commission (accepting incorrect AI-generated information) and errors of omission (failing to notice problems that the AI missed)"
- Heteroskedasticity-consistent standard errors: Regression standard errors adjusted to be robust against non-constant variance in residuals. "We use ordinary least squares (OLS) regression with heteroskedasticity-consistent standard errors to estimate that the authors made significantly smaller edits to AI-generated abstracts compared to human-written ones"
- Incentive-compatible: A mechanism designed so that truthful reporting or effortful behavior maximizes a participant’s expected payoff. "we use an incentive-compatible method to elicit authors' second-order beliefs about the overall use of GPT in writing tasks."
- Incentivized behavioral experiments: Studies that use payments or rewards to elicit genuine effort and reveal preferences or behaviors. "using the methodology of incentivized behavioral experiments~\citep{azrieli2018incentives}"
- Incentivized randomized controlled trial: An RCT in which participants receive rewards contingent on performance or outcomes. "We design an incentivized randomized controlled trial with a hypothetical conference setup where participants with relevant expertise are split into an author and reviewer pool."
- Joint Wald test: A statistical test assessing whether multiple parameters are jointly significant. "Authors with doctoral degrees made substantially more edits to AI-generated abstracts (; joint Wald test), reversing the average effect."
- Keystroke-level edits: Fine-grained logging of text changes at the character level, capturing insertions, deletions, and substitutions. "These experiments result in a collection of model-generated and human-edited texts, where we capture keystroke-level edits."
- Levenshtein distance: A string metric measuring the minimum number of character edits (insertions, deletions, substitutions) to transform one text into another. "edit distance score measures the character-level Levenshtein distance"
- Minimum-cost flow: A network optimization problem to send flow through a graph at minimum total cost under capacity and demand constraints. "Finally, we solve the reviewer assignment as a constrained optimization problem by a minimum-cost flow, with constraints that each submitted abstract gets exactly three reviewers and each reviewer preferably does not review edit versions of the same original abstracts."
- Multimodal synthesis: Integrating information across different modalities (e.g., text, figures, tables) into coherent writing. "LLMs have seen expanding application across domains, yet their effectiveness as assistive tools for scientific writing—an endeavor requiring precision, multimodal synthesis, and domain expertise—remains insufficiently understood."
- Nominalizations: The use of noun forms of verbs/adjectives (e.g., “implementation” from “implement”), often reducing clarity and directness. "Our quantitative analysis of stylistic metrics reveals that edits to AI-generated abstracts are to improve cohesion, reduce nominalizations, and produce informative sentences."
- OpenReview: An open peer-review platform used by many CS conferences for submissions, reviews, and assignments. "We adopted an automated pipeline to assign abstracts to recruited reviewers by mimicking the in-practice reviewer assignment mechanism in OpenReview, adopted by several CS conferences \cite{stelmakh2023gold}."
- Ordinary least squares (OLS) regression: A linear regression method that minimizes the sum of squared residuals to estimate relationships. "We use ordinary least squares (OLS) regression with heteroskedasticity-consistent standard errors to estimate that the authors made significantly smaller edits to AI-generated abstracts compared to human-written ones"
- Peer-alignment incentive: A reward structure that pays reviewers whose evaluations align closely with the consensus of their peers. "This peer-alignment incentive helps ensure careful, calibrated judgments and reduces random or inattentive responding."
- Randomized controlled trials (RCTs): Experiments that randomly assign participants to treatments to identify causal effects. "Randomized controlled trials are widely regarded as the gold standard for establishing causal relationships in behavioral interventions"
- Semantic similarity: A measure of how close two texts are in meaning, often computed with LLMs. "Then we compute the semantic similarity between reviewer publications and base original abstracts using GPT-4o."
- Second-order beliefs: Beliefs about others’ beliefs or behaviors (e.g., what percentage of peers use GPT). "we use an incentive-compatible method to elicit authors' second-order beliefs about the overall use of GPT in writing tasks."
- Source disclosure: Revealing whether text was authored by humans or AI, which can shape perceptions and behavior. "Upon disclosure of source information, the volume of edits converges in both source treatments."
- Source identity bias: Bias that arises from the perceived identity of the text’s source (human vs. AI), affecting judgments. "allowing us to investigate whether a \"source identity bias\" influences the authorial and review process in a similar manner to established forms of author bias."
- Thematic analysis: A qualitative method for identifying and interpreting patterns in textual data (e.g., interviews). "Finally, thematic analysis of our interviews with authors confirms that authors adopt different strategies depending on the origin of the abstracts"
- Topical fit: The alignment between a reviewer’s expertise and the subject matter of a submission. "In addition to topical fit, we also try to ensure that no reviewer can review more than one version of an edited abstract originating from the same original abstract to avoid contamination."
Collections
Sign up for free to add this paper to one or more collections.

