- The paper introduces an abstractive-to-extractive transformation pipeline that converts human-annotated abstractive summaries into high-fidelity extractive case summaries.
- It utilizes candidate sentence selection with ROUGE metrics and maximal marginal relevance to balance relevance and diversity in legal content.
- Empirical results across seven datasets show that AugAbEx outperforms unsupervised baselines in legal entity retention, semantic similarity, and structural alignment.
Motivation and Context
Legal judgment summarization poses a significant challenge due to the inherent complexity of legal language, the necessity of domain knowledge, and the requisite precision for downstream use by practitioners. While progress in generic text summarization has been dominated by abstractive methods, legal summarization introduces risk factors such as hallucinations and misinterpretation of legal entities, which are highly problematic in this domain. There is therefore increasing interest in extractive summarization, which, by construction, better preserves legal fidelity and transparency. However, the limited availability of gold-standard extractive summaries has been a critical bottleneck, due to the high annotation cost and expert time required.
The paper introduces AugAbEx, a pipeline for transforming existing human-annotated abstractive summaries present in prominent legal case datasets into aligned extractive gold-standard summaries. The proposed method is both scalable and transparent, ensuring the preservation of expert salience judgments while producing resource-efficient extractive references. The approach is tested across seven datasets spanning multiple jurisdictions and evaluation is carried out along multiple dimensions: legal entity preservation, lexical, semantic, and structural similarity.
The transformation pipeline comprises two main stages: candidate sentence selection and summary synthesis via maximal marginal relevance (MMR).
First, for each sentence in the original abstractive summary (OAG), the top-k most similar sentences from the source judgment document are identified using averaged ROUGE-1, ROUGE-2, and ROUGE-L metrics. These high-overlap candidates populate the extractive pool while maintaining fidelity to expert-labeled salience inherent in the OAG.
Second, the candidate pool is pruned using MMR to maximize relevance to the summary intent (approximated by similarity to the OAG and parent document), while simultaneously minimizing redundancy via penalizing overlap with already-selected summary sentences. λ is fixed at $0.5$ to balance relevance and diversity. The result is a Transformed Extractive Gold (TEG) summary that maintains length and information density comparable to its abstractive counterpart.

Figure 1: Pipeline to transform original abstractive gold (OAG) summary to transformed extractive gold (TEG) summary.
Automatic Evaluation Framework
A comprehensive evaluation framework, depicted in Figure 2, is put forth to critically assess the quality of the TEG summaries relative to both the OAG and alternative unsupervised extractive summaries. Comparison is multi-faceted:
- Domain attributes: LegalNER-based entity counts and recall over referenced provisions measure domain informativeness.
- Semantic attributes: LSA-based topic overlap, LegalBert embedding cosine similarity, and semantic proximity to the source document.
- Lexical attributes: Vocabulary overlap (ROUGE), Jensen-Shannon distance on term distributions, and Kullback-Leibler divergence with respect to the parent document.
- Structural attributes: Length-based (word and sentence), and Flesch-Kincaid reading ease.
Many-to-many and instance-level comparative assessments are carried out via the Bradley-Terry model, addressing limitations of mean/median aggregation that often obscure instance-wise strengths.

Figure 2: Automatic Evaluation Framework for Transformed Extractive Gold Summary.
Dataset Coverage and Statistical Diversity
The approach is systematically applied to seven datasets, including IN-Jud-Cit, ILC, IN-Abs, CivilSum, UK-Abs, Australian, and BillSum. These datasets vary widely in jurisdiction, document length, summary form (sentential vs. phrasal), and compression ratio, which establishes the generality and robustness of the proposed methodology.
Empirical Analysis
Domain Attribute Retention
TEG summaries are generally found to match or surpass OAG summaries in legal entity density, with notable exceptions in datasets featuring phrasal OAGs (CivilSum, Australian). Provision recall in TEG is maximized at k=2 candidate sentences, indicating optimal coverage of critical legal content with minimal redundancy.
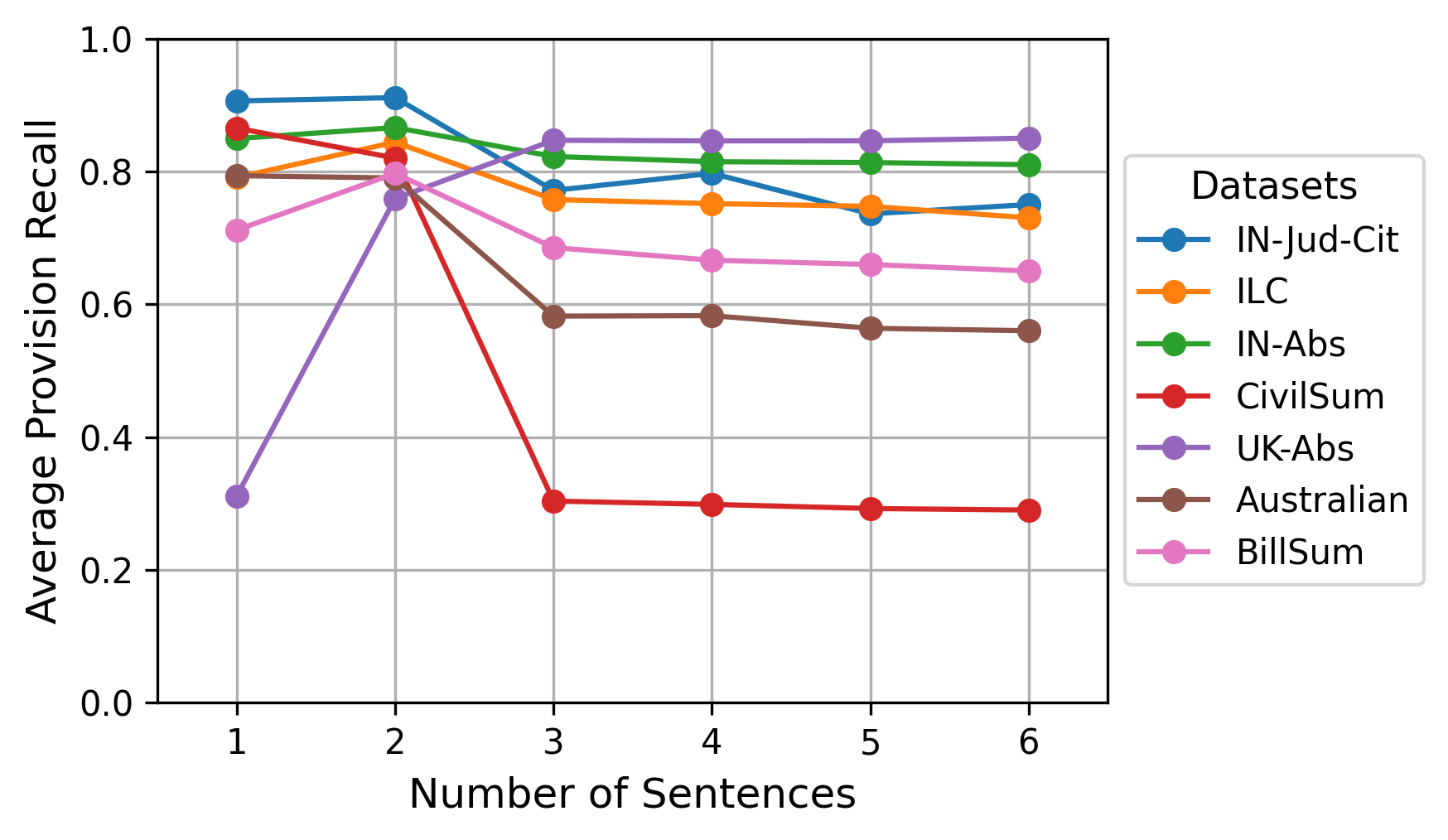
Figure 3: Comparison of macro-Averaged recall score of provisions in the transformed extractive gold summaries for varying number of candidate sentences.
Semantic Alignment
TEG summaries achieve consistently high semantic similarity to OAG across both LSA and LegalBert embedding spaces, with LegalBert-derived metrics in excess of 0.95 for the majority of datasets. Semantic alignment to the full case document is also high, demonstrating that TEGs encapsulate core document content as effectively as their abstractive references, even across jurisdictional and format divergences.
Lexical and Structural Comparisons
Lexical overlap via ROUGE is high except where OAG is phrasal (CivilSum, Australian). Jensen-Shannon distances confirm strong alignment of term distributions. Structural analysis indicates that TEG lengths closely track OAG lengths for most datasets, with longer extractive outputs in datasets where the reference is notably compressed or phrasal.
Comparative Analysis to LSA Baseline
Across all evaluation dimensions, AugAbEx TEG summaries outperform unsupervised LSA-based extractive baselines. Improvements are observed in domain-level provision recall, semantic similarity (both latent and embedding-based), lexical overlap, and readability. This supports the claim that leveraging expert-anchored abstractive summaries delivers extractive references of superior utility compared to generic, unsupervised approaches.
Case Study: Dataset Nuances
Analysis of IN-Abs and IN-Jud-Cit (for which TEGs perform especially well) and CivilSum/Australian (where phrasal structure impedes extractive alignment) highlights the dependence of transformation quality on OAG style. For datasets constructed via dense phrasal abstraction, the TEG pipeline’s sentential constraint yields longer summaries and lower lexical overlap, but still retains high semantic fidelity.
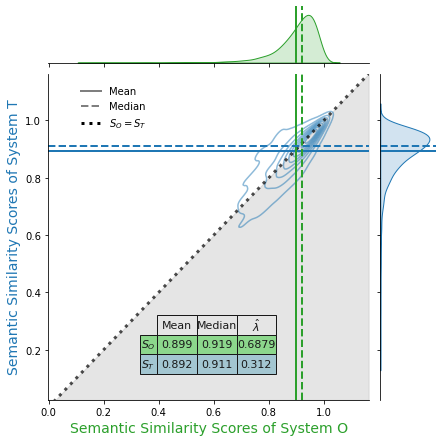
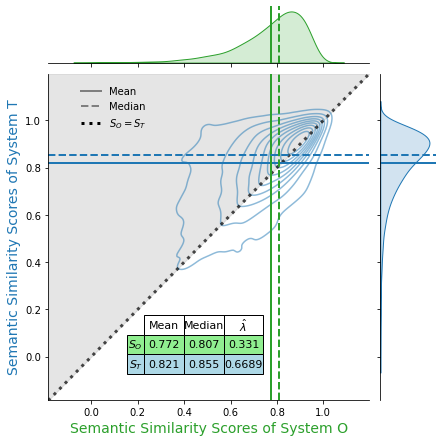
Figure 4: IN-Abs
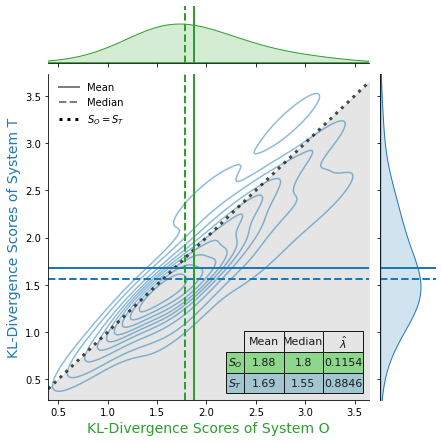
Figure 5: IN-Jud-Cit
Human Evaluation
Expert annotator grading demonstrates high concordance with automatic metrics: the top-scoring TEG summaries are rated as equally informative as their OAG references, with a Pearson correlation of 0.886 between expert grade and ROUGE-L F1. This evidences that the evaluation framework is robust and proxies real user utility.
Implications and Future Directions
AugAbEx introduces a scalable paradigm for curating high-quality extractive references informed by domain-expert abstraction. With the public release of the augmented datasets, this is likely to have tangible impact on future supervised and unsupervised extractive summarization methods in the legal domain. The study empirically substantiates that extractive methods, when expertly anchored, excel in preserving legal fidelity and are preferred by practitioners.
The methodology is extensible to new datasets and jurisdictions, particularly those with limited extractive reference availability but containing high-value human abstraction. As the NLP field progresses toward more reliable, transparent, and domain-sensitive summarization, AugAbEx establishes a practical baseline. Future work should emphasize further legal entity enrichment in extraction strategies, domain adaptation for NER tools, and broader human-in-the-loop evaluations for cross-jurisdictional transfer.
Conclusion
AugAbEx addresses a fundamental bottleneck in legal case summarization by engineering a transparent, low-cost, and statistically robust pipeline to generate aligned extractive gold summaries using existing human-annotated abstractive resources. The transformed summaries exhibit strong numerical alignment with their abstractive counterparts in all salient evaluation dimensions, surpass LSA-extracted baselines, and score favorably in human evaluation. This resource addresses the legal NLP community’s data needs and sets a new benchmark for future modeling and evaluation. Extractive algorithms should further advance context- and entity-sensitive sentence selection to approach the information condensation prowess of human-annotated summaries.