An International Agreement to Prevent the Premature Creation of Artificial Superintelligence
Abstract: Many experts argue that premature development of artificial superintelligence (ASI) poses catastrophic risks, including the risk of human extinction from misaligned ASI, geopolitical instability, and misuse by malicious actors. This report proposes an international agreement to prevent the premature development of ASI until AI development can proceed without these risks. The agreement halts dangerous AI capabilities advancement while preserving access to current, safe AI applications. The proposed framework centers on a coalition led by the United States and China that would restrict the scale of AI training and dangerous AI research. Due to the lack of trust between parties, verification is a key part of the agreement. Limits on the scale of AI training are operationalized by FLOP thresholds and verified through the tracking of AI chips and verification of chip use. Dangerous AI research--that which advances toward artificial superintelligence or endangers the agreement's verifiability--is stopped via legal prohibitions and multifaceted verification. We believe the proposal would be technically sufficient to forestall the development of ASI if implemented today, but advancements in AI capabilities or development methods could hurt its efficacy. Additionally, there does not yet exist the political will to put such an agreement in place. Despite these challenges, we hope this agreement can provide direction for AI governance research and policy.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine building a super-smart computer brain that is not just better than us at some things, but better at almost everything. The authors call that artificial superintelligence (ASI). They worry that rushing to build ASI could be extremely dangerous—even risking human extinction—if it doesn’t follow our values or if bad actors use it.
This paper proposes a practical plan for the world to hit “pause” on the riskiest kinds of AI development until we have strong safety methods, while still letting people use today’s safer AI tools.
The main questions the paper asks
- How can countries work together to stop anyone from creating ASI too soon?
- How can we make sure everyone follows the rules even if they don’t fully trust each other?
- How can we pause the dangerous parts of AI progress but keep the useful parts?
How their plan would work (explained simply)
Think of this like a global “speed limit” and “safety inspection” for AI.
- Training vs. using: “Training” an AI is like teaching it for months with lots of computers so it can learn new abilities. “Using” (inference) is when you ask a trained AI to answer questions or help with tasks.
- FLOPs: A FLOP is one tiny math step a computer does. Training powerful AIs takes mind-boggling numbers of FLOPs. The authors want limits based on FLOPs, like setting a maximum number of math steps you can use for training.
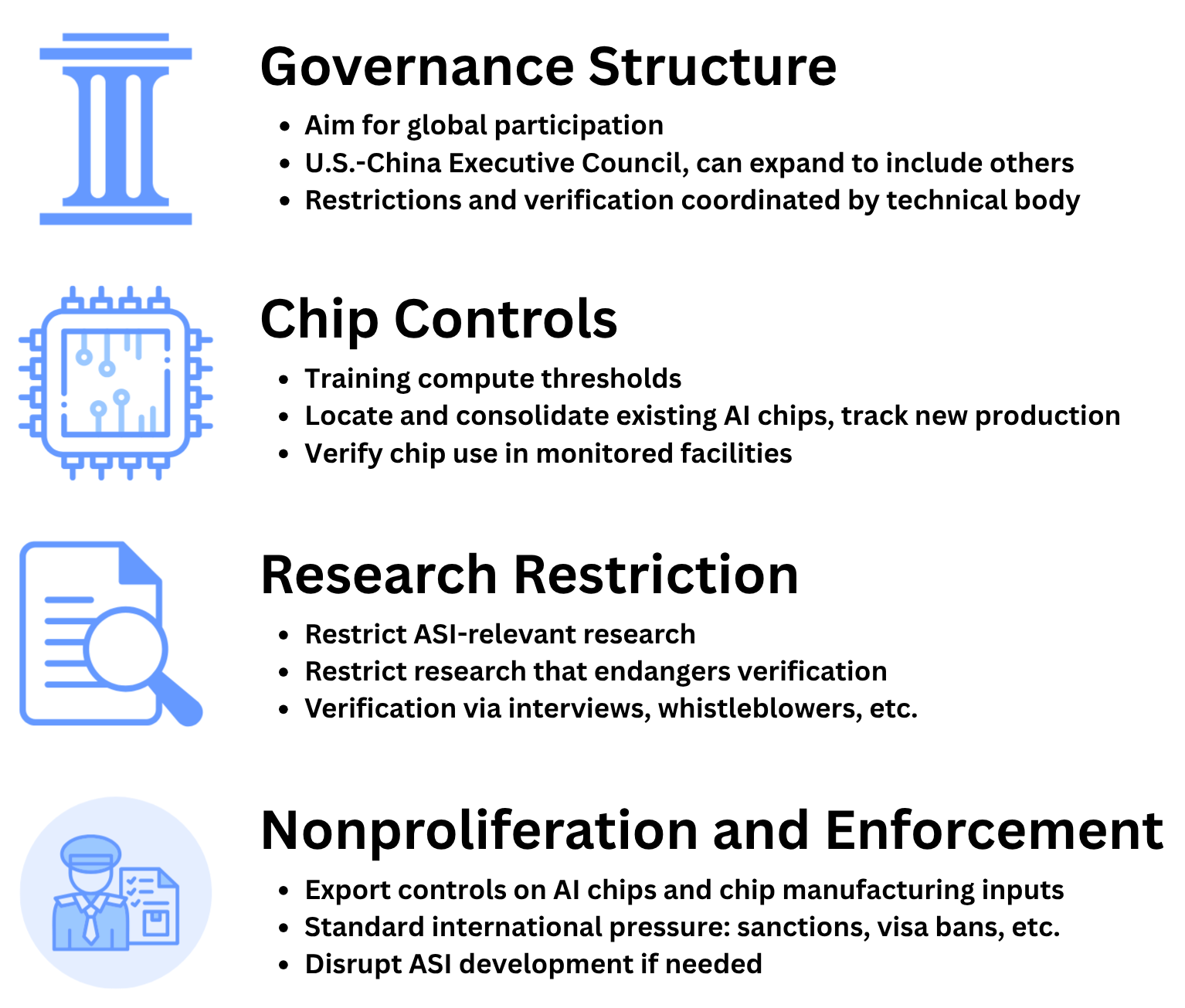
Here are the key parts of the plan, explained with everyday ideas:
- A global coalition led by the U.S. and China sets AI “speed limits.”
- Above a strict training limit (a very large number of FLOPs), training new frontier models is banned.
- In a middle zone, training is allowed but only with approval and monitoring.
- Below a small limit, training is freely allowed (so everyday and many research uses can continue).
- Track the “engines” that power AI: Advanced AI chips are like powerful car engines—you need lots of them to train big models. The plan tracks where these chips are, how many exist, and how they’re used, so no one can secretly build a super-powerful AI.
- Verify use: Inspections, smart chip features, and other checks make sure chips are used for safe purposes (like running existing models) and not for risky training.
- Limit only the dangerous research: Some kinds of research make AIs stronger even without more chips (smarter training tricks, new algorithms). The plan temporarily restricts this specific frontier research so the “speed limit” can’t be dodged. It doesn’t ban normal, helpful AI work (like for healthcare tools or self-driving safety).
- Nonproliferation and enforcement: Stop advanced chips from spreading to rule-breakers, use trade rules and sanctions if needed, and escalate only if a country tries to break the deal openly.
- Start small, grow over time: The authors recommend a staged rollout—begin with transparency and trust-building, then expand to full monitoring once there’s political support.
Analogy: It’s like countries agreeing not to build certain kinds of rockets until we have strong safety systems, with inspectors checking rocket parts and factories, and with rules that still let people use regular airplanes.
What they found or concluded
This is a policy proposal, not an experiment, so there aren’t lab “results.” But the paper argues:
- If we set FLOP-based limits, track advanced AI chips, and verify how they’re used, we can realistically prevent the creation of ASI with today’s technology.
- To make the pause actually work, we must also limit the narrow slice of research that would rapidly push us toward ASI or break the monitoring system.
- Politically, it’s hard right now—there isn’t enough will to sign such a deal today. But the authors believe support could grow as risks become clearer.
- The plan has costs (slower AI progress, added oversight, risk of misuse of monitoring), but they argue the cost is worth it to avoid even a 10% chance of catastrophe.
Why this matters:
- A global pause would reduce the chances of misaligned ASI taking control, AI-fueled wars, or misuse like advanced cyberattacks or engineered biothreats.
- It buys time to solve the hard problem: making super-powerful AIs reliably care about human safety and values.
Why not simpler options?
The authors consider common objections and explain their answers in plain language:
- Why not wait and pause later? We can’t reliably predict when AI will cross dangerous lines. If we wait, it might be too late—and chips might be too widespread to monitor.
- Why limit research? Because clever new methods can make AIs much more capable without more hardware. If we only limit chips, algorithm breakthroughs could bypass the rules.
- Won’t this help authoritarian control? They argue the current path (a few companies or states racing to ASI) risks an even worse concentration of power. Their plan tries to add safeguards and transparency, and it’s temporary—just until safety is proven.
- Can’t we just build defenses? Some AI-enabled threats are offense-friendly and hard to defend against (think fast cyberattacks or bio-risks). Prevention is safer than betting everything on defense.
- Why track existing chips? Because a hidden stock of powerful chips could enable a secret project. Knowing where the “engines” are is essential for trust and verification.
What happens after the pause?
The pause is not forever. The restrictions could be lifted when:
- There are proven, widely trusted ways to align super-powerful AI with human values.
- We have strong protections against misuse and proliferation.
- There’s a stable, transparent way to develop very advanced AI safely (possibly a global, carefully monitored project).
- Societies have plans for other big issues, like job changes, power concentration, and geopolitical stability.
What this could mean for the world
If adopted, this agreement could:
- Greatly lower the chance of a disaster from misaligned or misused ASI.
- Keep everyday helpful AI tools available while stopping the riskiest leaps.
- Give time to build safety science, rules, and institutions strong enough to handle super-powerful AI.
- Encourage cooperation between major powers (especially the U.S. and China) on a shared survival issue.
In short, the paper’s message is: Let’s set smart global guardrails now—like speed limits, inspections, and targeted research rules—so we don’t sprint into building something super-powerful and unsafe. Once we have reliable safety methods, we can move forward more confidently.
Knowledge Gaps
Below is a single, consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each item is phrased to be concrete and actionable for future research or policy design.
- Lack of a validated, dynamic method for setting and updating FLOP thresholds: no empirical mapping from training FLOPs to dangerous capability levels, no process for rapid adjustment in response to algorithmic efficiency gains or paradigm shifts.
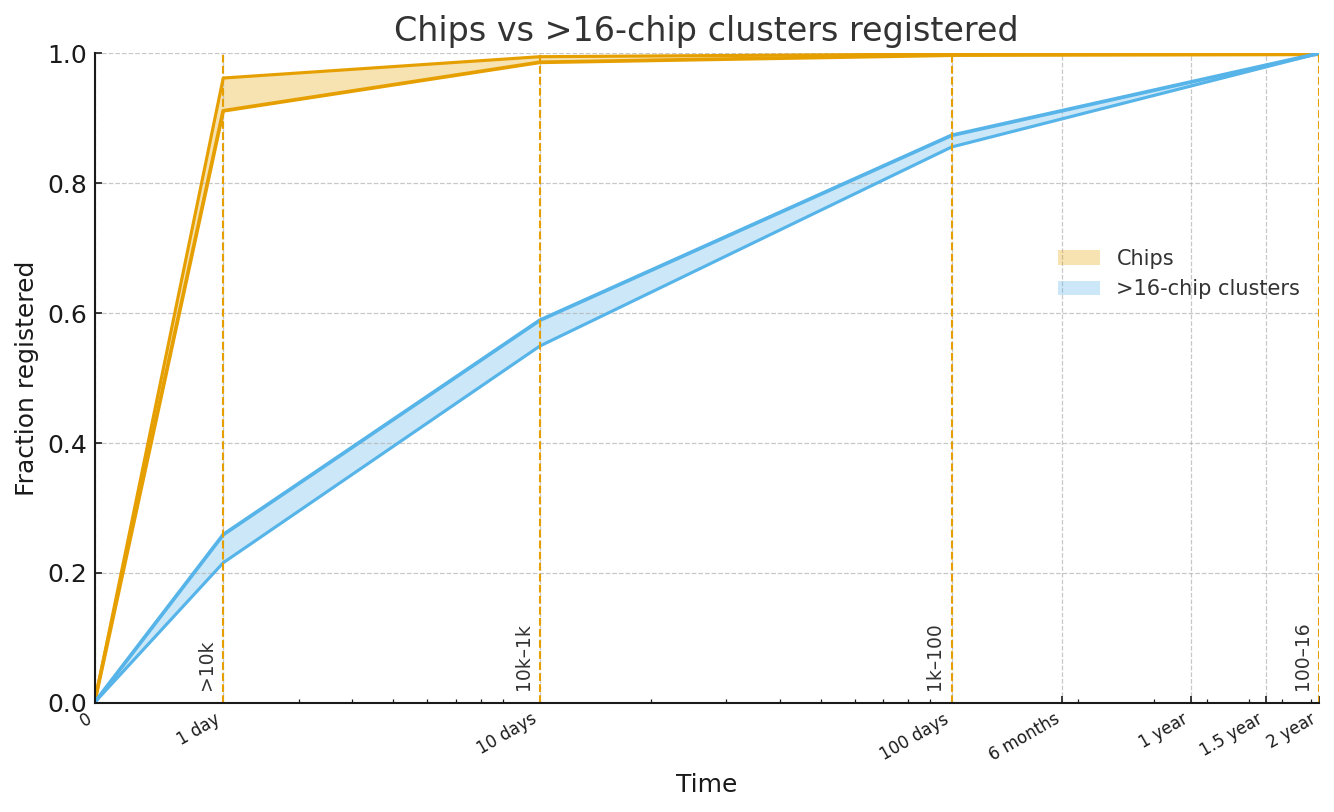
- Unclear technical feasibility and timeline for tamper-resistant on-chip monitoring: no concrete architecture, performance overhead analysis, or vendor commitments for secure attestation, logging, and inference-vs-training discrimination.
- No plan for retrofitting the global stock of existing AI accelerators with trustworthy monitoring and attestation, including cost, logistics, and legal authorities needed to modify privately owned or sovereign hardware.
- Insufficient detection strategy for covert facilities and decentralized compute: limited treatment of peer-to-peer clusters, botnets, federated learning, consumer GPUs/NPUs, and edge devices that can collectively exceed monitored thresholds.
- Verification of declared vs undeclared training runs remains underspecified: how to reliably measure actual training FLOPs across mixed precision, sparsity, fine-tuning, RLHF, distillation, and inference-heavy “capability laundering” regimes.
- Ambiguity in “H100-equivalent” thresholds and conversion: no standardized mapping across diverse accelerators (ASICs, FPGAs, TPUs, consumer GPUs, NPUs), memory bandwidth limits, and interconnects that influence attainable training scale.
- No robust early-warning system for algorithmic breakthroughs that reduce compute by large factors (e.g., inference-scaling, new architectures), nor criteria for preemptive policy tightening when such breakthroughs are detected.
- Insufficient treatment of alternative AI paradigms (neuromorphic, symbolic, evolutionary, analog, photonic, quantum) that might bypass compute-based controls; missing detection, evaluation, and containment strategies tailored to non-deep-learning approaches.
- Agreement relies primarily on training controls but leaves inference controls underdeveloped: no mechanism to govern use, replication, or fine-tuning of already-trained dangerous models, nor model registry/watermarking protocols to track provenance and risk.
- No defined capability evaluation framework for “advancement toward ASI”: missing standardized benchmarks, red-team methodologies, deception-resilience tests, and risk thresholds to decide when methods or models cross into restricted terrain.
- Research restriction scope is undefined: no operational criteria to distinguish permitted vs prohibited research topics, governance of the whitelist, update cadence, appeals process, and due-process protections for researchers.
- Verification of researcher activity lacks detail: no practical protocol for audits, interviews, code/repo inspections, or incentives/whistleblower protections, and unclear boundaries to minimize invasiveness and protect civil liberties.
- Open-source model and code governance is unaddressed: how to prevent dangerous capability leakage via weights, libraries, training scripts, or datasets shared across borders and jurisdictions; takedown and “model quarantine” procedures absent.
- Non-state actor risk is under-specified: insufficient policies for criminal groups or rogue labs operating across jurisdictions, including cyber operations, undercover monitoring, and international mutual legal assistance frameworks.
- Enforcement triggers and escalation ladders are vague: no clear thresholds for sanctions, interdiction, or other coercive tools; no rules of engagement, proportionality principles, or crisis-management protocols to avoid geopolitical escalation.
- Strategy for chip tracking and smuggling prevention is incomplete: no modeling of black-market dynamics, smuggling routes, customs capacity, satellite/power-signature detection limits, or false-positive/false-negative rates in supply-chain monitoring.
- No quantitative analysis of breakout time: missing adversarial modeling of how fast a rogue actor could acquire compute and train covertly; lack of stochastic risk models to inform required inspection cadence and enforcement readiness.
- Missing cost-benefit and macroeconomic impact assessment: no estimates of GDP, innovation, financial-market, and industry impacts; no compensation/transition policies for affected firms, workers, and countries, nor funding model for the monitoring regime.
- Governance design of the Executive Council is minimal: no membership criteria, expansion pathways, voting rules, dispute resolution, transparency requirements, rotation, checks-and-balances, or independent oversight to prevent misuse.
- Civil liberties and human rights safeguards are not specified: unclear limits on surveillance, search and seizure, data retention, due process, and redress; no external review mechanisms to prevent authoritarian abuse.
- Compatibility with existing legal frameworks is unresolved: how domestic legislation (export controls, privacy, antitrust, IP) and international instruments (EU AI Act, national RSPs, Wassenaar-like regimes) will be harmonized.
- Data governance gaps: no controls on dataset creation, curation, and synthetic data pipelines that may enable dangerous capabilities; no auditing standards for data provenance and risk.
- Cloud, HPC, and multi-tenant compliance architecture is unspecified: how providers enforce per-tenant monitoring while preserving privacy, how sovereign clouds and academic HPC centers integrate with attestation and inspection.
- Criteria for lifting the agreement are vague: no measurable milestones for “years-long track record,” “established consensus,” or “strong misuse and proliferation controls”; no testbeds, trials, or formal verification to demonstrate alignment efficacy.
- No plan to detect and respond to AGI capable of automating AI R&D: missing triggers, containment protocols, and “kill-switch” mechanisms when automation of capabilities research begins to accelerate beyond governance control.
- Underspecified approach to “narrow AI” carve-outs: no deterministic criteria to classify and periodically re-validate safe application-specific systems, nor safeguards against capability creep through iterative updates.
- Energy and power-signature monitoring lacks rigor: no validated thresholds or models linking energy consumption to training scale, nor strategies to evade masking (e.g., colocation with other workloads).
- Attribution and provenance of training efforts are weak: no standardized logging requirements, cryptographic commitments, or third-party audit trails that would make covert training detectable or legally actionable.
- International participation and coalition-building strategy is high level: no engagement plans for blocs (EU, India, ASEAN), contingent strategies if a major power defects, or mechanisms to share benefits (security guarantees, infrastructure access) equitably.
- Vendor and supply-chain commitments are unspecified: no binding requirements for chipmakers to implement secure attestation, firmware update controls, serial tracking, and anti-tamper features, nor liability/regulatory levers to enforce compliance.
- Threshold gaming risk remains high: no guardrails against splitting large training into many sub-threshold runs, iterative fine-tuning/distillation that cumulatively yields dangerous capabilities, or cross-entity collusion to evade monitoring.
- Missing performance, reliability, and security evaluation of attestation systems: no plan for penetration testing, threat modeling (insider, nation-state adversaries), resilience to firmware exploits, or rollback protection.
- Funding and capacity building is unaddressed: no global budget estimates, financing mechanisms, and training pipelines for inspectors, OSINT analysts, supply-chain auditors, and technical teams, especially in lower-capacity states.
- Ambiguity around “monitored facilities” threshold (16 H100s): no rationale for chosen value, no sensitivity analysis, and no adaptation plan as hardware evolves (e.g., far more capable next-gen accelerators).
- No structured interaction model with corporate RSPs/preparedness frameworks: how company-level thresholds, evals, and safety commitments integrate with and inform international verification and the whitelist.
- Lack of empirical case studies or pilots: no proposed sandbox jurisdictions or limited-scope trials to test chip tracking, FLOP attestation, research verification, and enforcement mechanics before global rollout.
- Exit and failure modes are not planned: no contingency strategy if verification becomes untenable (e.g., widespread consumer capabilities), if a major state defects, or if breakthrough paradigms nullify compute-based governance.
Glossary
- AGI: Artificial general intelligence; systems performing at human-level across all cognitive domains. "We note that artificial general intelligence (AGI)–systems that perform at human-level across all cognitive domains–would likely emerge before ASI."
- Agentic: Exhibiting goal-directed behavior and the ability to pursue objectives over time. "e.g., in the setting of agentic software engineering"
- Arms-control: International efforts and agreements to limit or regulate weapons and related technologies. "violations of arms-control and nonproliferation agreements."
- Artificial superintelligence (ASI): AI substantially smarter than humans at all cognitive tasks. "premature development of artificial superintelligence (ASI) poses catastrophic risks"
- Challenge inspections: Surprise or on-demand inspections to verify compliance with an agreement. "power consumption monitoring, challenge inspections, whistleblowers, and more."
- Collective action problem: A situation where individual incentives lead to outcomes that are suboptimal for the group. "Those racing toward superintelligence, to the extent they are concerned with catastrophic risks, are stuck in a collective action problem"
- Counterproliferation: Active measures to stop the spread or acquisition of dangerous technologies or capabilities. "strong counterproliferation efforts to ensure these export controls are upheld."
- Executive Council: A governing body of the agreement with decision-making authority. "They are the initial members of an Executive Council which governs the agreement."
- Export controls: Government restrictions on the transfer of sensitive technologies. "export controls on AI chips and chip manufacturing equipment"
- FLOP thresholds: Governance limits defined by the number of floating-point operations permitted in training. "Limits on the scale of AI training are operationalized by FLOP thresholds"
- FP8: An 8-bit floating-point format used to improve performance and efficiency in AI workloads. "assuming 50% utilization in FP8."
- Frontier models: The most advanced, cutting-edge AI models at the leading edge of capability. "Today’s frontier models are not robust to jailbreaks:"
- H100-equivalents: A hardware capacity measure referencing the performance of NVIDIA H100 GPUs. "greater than 16 H100-equivalents; 16 H100s cost approximately \$500,000 USD in 2025"
- Inference-scaling regime: A development approach where capabilities grow primarily through inference-time techniques rather than larger training runs. "the inference-scaling regime started with OpenAI’s o-series of models"
- Jailbreaks: Inputs crafted to bypass a model’s safety or policy constraints. "Today’s frontier models are not robust to jailbreaks:"
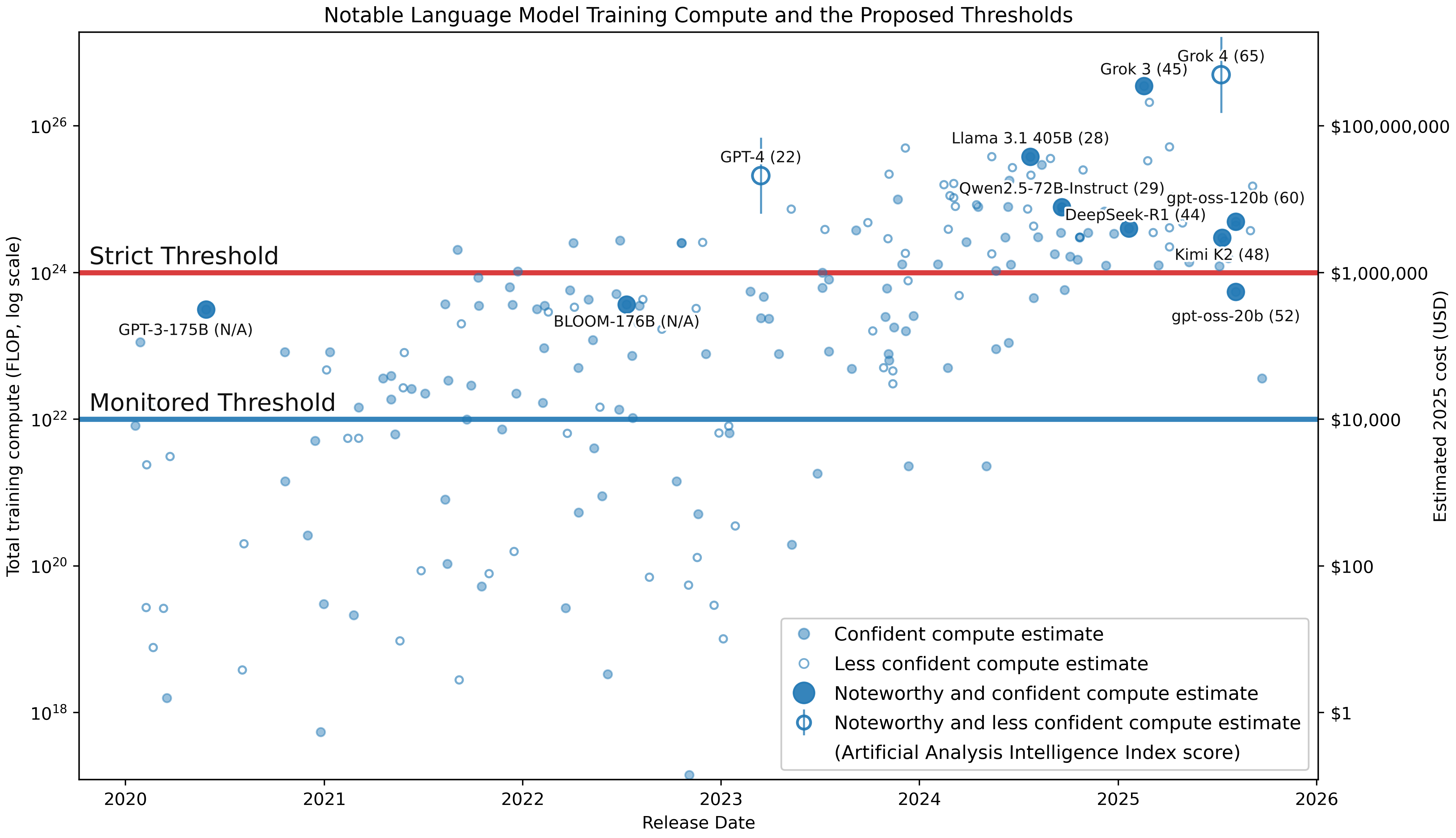
- Monitored Threshold: A compute boundary above which training must be approved and monitored. "Training runs below this threshold but above the Monitored Threshold (i.e., FLOP) must be approved and monitored by coalition authorities."
- Nonproliferation: Policies and actions aimed at preventing the spread of dangerous technologies. "For these, the coalition relies on nonproliferation and enforcement."
- Open-source intelligence: Information gathered from publicly available sources for intelligence analysis. "open-source intelligence"
- Reasoning models: AI models designed or tuned to perform multi-step, structured reasoning tasks. "Current models, especially reasoning models, display a propensity to reward hack and lie to their users"
- Remote attestation: A protocol where hardware/software proves its state to a remote verifier. "Remote attestation and other technical solutions are in early stages"
- Strict Threshold: A compute limit beyond which training is prohibited. "AI training runs above the Strict Threshold (i.e., FLOP) are prohibited."
- Strategic deterrence: The use of credible threats to discourage adversaries from taking aggressive actions. "Capabilities that undermine strategic deterrence and incentivize first strikes may trigger wars and conflicts"
- Tamper-resistant on-chip mechanisms: Hardware features designed to resist manipulation and enable reliable monitoring or control. "The coalition works to develop tamper-resistant on-chip mechanisms for such purposes"
- Training compute: The total computational resources used to train a model. "The training compute used to train various notable AI models in the last few years"
- Training FLOP: The total number of floating-point operations consumed during training. "operationalized as total training FLOP"
- Transformer architecture: A neural network design based on self-attention that enabled major efficiency gains. "Ho et al. 2024 estimate that the transformer architecture provided 7.2× reduction in operations"
- Whitelist: A list of approved methods or items permitted under the agreement. "approved methods (e.g., from a Whitelist)"
Practical Applications
Below are practical, real-world applications that flow from the paper’s proposed international agreement, verification architecture, and staged implementation. Each item includes sectors, potential tools/products/workflows, and assumptions or dependencies affecting feasibility.
Immediate Applications
These items can be piloted or deployed now with existing institutions, technologies, and commercial practices, even without a full international treaty.
Industry
- FLOP accounting and pre-training gates in ML pipelines (software)
- Tools/Workflows: Integrate training-compute estimators and “Monitored Threshold” (
~10^22FLOP) pre-registration gates into MLOps (e.g., CI/CD hooks, SDKs for PyTorch/JAX), with audit logs and automatic capability disclosure in model cards. - Assumptions/Dependencies: Agreement on standard FLOP estimation methods; willingness of firms to adopt; compatibility with diverse model architectures.
- Tools/Workflows: Integrate training-compute estimators and “Monitored Threshold” (
- Chip inventory and “compute passport” telemetry for data centers (cloud, semiconductors)
- Tools/Workflows: Asset registries linking serials and purchase orders; secure agent software reporting cluster composition, utilization, and physical location; periodic attestation checks aligned with SOC 2/ISO 27001.
- Assumptions/Dependencies: Cooperation from cloud providers and OEMs; supply-chain transparency; acceptance of light-touch audits.
- Inference-only cloud tiers with attested separation from training (cloud, software)
- Tools/Workflows: Offer “inference-only” SKUs with mode-locking, telemetry, and SLAs; customer-facing attestations and logs proving no training workloads; automatic alarms for gradient accumulation or optimizer usage.
- Assumptions/Dependencies: Reliable training-vs-inference fingerprinting; customer demand for compliant services; regulator recognition of attestations.
- Power and utilization anomaly detection for GPU clusters (energy, cybersecurity)
- Tools/Workflows: Pair high-resolution metering with workload telemetry to flag training-like signatures (e.g., sustained high utilization patterns); integrate into SOC dashboards.
- Assumptions/Dependencies: Access to facility-level power data; models of training workload profiles; privacy-preserving aggregation.
- Prototype training/inference mode detection on accelerators (semiconductors, software)
- Tools/Workflows: Firmware modules and driver heuristics that flag optimizer usage, backprop patterns, or distributed training configs; exposure via APIs and logs for auditors.
- Assumptions/Dependencies: Cooperation from GPU vendors; tamper resistance sufficient for audits; manageable false positives/negatives.
- Small-cluster caps in unmonitored sites (industry policy)
- Tools/Workflows: Company policies limiting unmonitored clusters to “< 16 H100-equivalents” with self-attestation; procurement workflows that route larger builds into monitored facilities.
- Assumptions/Dependencies: External recognition of caps as risk-reducing; standardized equivalence metrics across chip generations.
- Compute risk officer and compliance playbooks (finance, corporate governance)
- Tools/Workflows: New roles overseeing compute disclosures, threshold gating, inspector readiness; board-level reporting; incident response for suspected violations.
- Assumptions/Dependencies: Executive buy-in; insurance market recognition; alignment with legal counsel.
Academia
- Research ethics screening and restricted-topic firewalls (education, research)
- Tools/Workflows: Departmental IRB-style review for ML projects; “Whitelist” of permitted algorithms/methods; red-team checks to prevent covert capability escalation.
- Assumptions/Dependencies: Community norms and journal policies; clarity about what counts as “dangerous” capability research.
- Compute disclosure standards in publications (education, software)
- Tools/Workflows: Require training-compute estimates, chip counts, and thresholds in model cards and papers; automated reproducibility checklists embedding FLOP calculations.
- Assumptions/Dependencies: Journal and conference adoption; agreed methodology for multi-stage training and fine-tuning estimates.
- Methods research for verification (software, semiconductors)
- Tools/Workflows: Benchmarks and open-source libraries for FLOP estimation; studies on training-vs-inference fingerprints; privacy-preserving attestation protocols.
- Assumptions/Dependencies: Access to realistic workloads; cooperation from labs for ground-truth data.
Policy and Government
- National pilot registries for medium-scale training (policy)
- Tools/Workflows: Voluntary/mandatory notifications for runs above
~10^22FLOP; lightweight reviewer panels; early transparency measures across labs. - Assumptions/Dependencies: Legal authority; industry participation; simple workflows to avoid stalling benign research.
- Tools/Workflows: Voluntary/mandatory notifications for runs above
- Export-control tightening and end-use verification (policy, semiconductors)
- Tools/Workflows: Expand end-user certifications for AI accelerators; integrate “compute passports” into customs and re-export rules; post-shipment checks.
- Assumptions/Dependencies: Coordination with allies; limited black/grey market leakage.
- Whistleblower enablement for AI capability violations (policy, legal)
- Tools/Workflows: Secure reporting channels; enhanced protections; rewards for verified disclosures related to restricted research or unregistered clusters.
- Assumptions/Dependencies: Statutory changes; funded investigative capacity; trust in confidentiality.
- Challenge inspection MOUs and inspectorate formation (policy, international)
- Tools/Workflows: Bilateral/multilateral agreements granting facility access with notice; trained technical inspectors; standard inspection playbooks.
- Assumptions/Dependencies: Diplomatic will; manageable scope; clarity on safeguarding trade secrets.
- Dynamic threshold advisory groups (policy, academia)
- Tools/Workflows: National expert panels to periodically review
~10^22/10^24FLOP thresholds; public guidance; alignment with international bodies. - Assumptions/Dependencies: Diverse expertise; access to frontier capability data; transparent mandate.
- Tools/Workflows: National expert panels to periodically review
Daily Life and Professional Practice
- Developer-side compute calculators and compliance checkers (software)
- Tools/Workflows: IDE plugins/CLI tools estimating FLOPs and flagging potential threshold crossings; warnings for use of restricted methods.
- Assumptions/Dependencies: Easy integration; accurate heuristics for varied architectures.
- Organizational training on safe AI use and jailbreak avoidance (education)
- Tools/Workflows: Short courses for product teams and IT; policies limiting risky prompting; capability-aware access controls for powerful models.
- Assumptions/Dependencies: Up-to-date threat models; buy-in from team leads.
Long-Term Applications
These items likely require further research, scaling, international coordination, hardware redesign, or maturation of institutions.
Industry
- Standardized, tamper-resistant on-chip verification (semiconductors, cloud)
- Tools/Products: New accelerator generations with secure enclaves; hardware mode locks; signed telemetry; remote attestation compatible with monitored facilities.
- Assumptions/Dependencies: Vendor adoption; resistance to firmware bypass; global standards harmonization.
- Compliance-first AI cloud and centralized monitored compute (cloud, software)
- Tools/Products: Dedicated “monitored compute providers” licensed to run medium-scale training globally; embedded inspectors; automated reporting to regulators.
- Assumptions/Dependencies: International licensing; predictable audit costs; customer trust in confidentiality.
- Insurance and certification markets for AI compliance (finance)
- Tools/Products: Policies pricing breakout risk; certifications akin to ISO/NIST for compute governance; premiums linked to telemetry strength and inspection history.
- Assumptions/Dependencies: Actuarial data; regulator recognition; coverage clarity in sanctions contexts.
Academia
- Mature alignment science with proven benchmarks and track record (education, research)
- Tools/Products: Longitudinal benchmarks for alignment robustness; standardized eval suites; replication centers demonstrating sustained success.
- Assumptions/Dependencies: Funding continuity; accepted scientific standards for “alignment sufficiency.”
- Global model lineage registry and research licensing (education, policy)
- Tools/Products: Persistent identifiers for models, datasets, and training runs; licensing for potentially dangerous lines of research; public provenance trails.
- Assumptions/Dependencies: Research community buy-in; national adoption of licensing frameworks.
Policy and Government
- Binding international treaty with a US–PRC–led Executive Council (policy, international)
- Tools/Workflows: Formal treaty text; governance charter; membership expansion; modification protocols minimizing veto risks.
- Assumptions/Dependencies: Political will; mutual assurance mechanisms; stable geopolitical climate.
- Global chip-location and monitoring network (policy, semiconductors)
- Tools/Workflows: Integrated supply-chain tracking, customs data fusion, utility metering partnerships, OSINT programs, and challenge inspections to locate and monitor accelerators worldwide.
- Assumptions/Dependencies: Continued chip-supply concentration; cooperation from utilities and cloud operators; legal authorities for inspections.
- Research restrictions and whitelists codified in law (policy, education)
- Tools/Workflows: Statutory definitions of restricted capability research; periodic whitelist updates; safe-use carve-outs (e.g., self-driving, industrial controls).
- Assumptions/Dependencies: Narrow scoping to minimize collateral damages; appeal processes; international harmonization.
- Nonproliferation apparatus for AI chips and manufacturing equipment (policy)
- Tools/Workflows: Export regimes, watchlists, sanctions, and counterproliferation operations; joint task forces to disrupt smuggling networks.
- Assumptions/Dependencies: Multilateral alignment; intelligence-sharing; effectiveness against covert state-backed efforts.
- Graduated enforcement mechanisms up to disruption of rogue projects (policy, defense)
- Tools/Workflows: Diplomatic pressure, economic sanctions, cyber operations, facility shutdowns where lawful; rules of engagement comparable to arms-control contexts.
- Assumptions/Dependencies: Legal authorities; proportionality and oversight; accurate attribution.
- Dynamic threshold governance and periodic capability reassessments (policy, academia)
- Tools/Workflows: Scheduled reviews to update FLOP thresholds and monitoring rules; triggers for tightening if algorithmic efficiency improves faster than expected.
- Assumptions/Dependencies: Timely data; consensus methods for uncertainty handling; resilience against politicization.
Sectoral Deployment of Safe Narrow AI (examples)
- Healthcare: Compliance-attested diagnostic support operating in inference-only modes; auditable model updates with compute disclosures.
- Assumptions/Dependencies: Medical device regulation integration; hospital IT telemetry.
- Transportation and robotics: Permitted autonomous systems with hardware attestation and capability caps; monitored updates via licensed providers.
- Assumptions/Dependencies: Safety case frameworks; regulator capacity for audits.
- Energy and utilities: Grid-integrated monitoring for high-density compute clusters; utility-level anomaly detection aiding treaty verification.
- Assumptions/Dependencies: Data-sharing agreements; privacy safeguards; cybersecurity hardening.
- Finance: Model governance with compute risk disclosures and certification; alignment assurance requirements for critical decision systems.
- Assumptions/Dependencies: Prudential regulator mandates; audit standards.
Societal and Professional Infrastructure
- International whistleblower protection standards specific to AI (policy, legal)
- Tools/Products: Cross-border safe reporting channels; standardized evidentiary rules; protection from retaliation.
- Assumptions/Dependencies: Treaty codification; funding; interoperable legal frameworks.
- Privacy-preserving monitoring technologies (software, policy)
- Tools/Products: Secure aggregation, differential privacy, and zero-knowledge proofs enabling verification without revealing sensitive workloads.
- Assumptions/Dependencies: Advancements in applied cryptography; vendor integration.
- Emergency response protocols for suspected treaty violations (policy)
- Tools/Workflows: Joint investigative teams; rapid inspection deployment; escalation ladders and deconfliction guides.
- Assumptions/Dependencies: Real-time intelligence-sharing; pre-negotiated access rights; clear thresholds for action.
- Global AI development project post-mitigation (policy, academia, industry)
- Tools/Workflows: Monitored, cautious development under an internationally supervised program once alignment and misuse controls meet agreed safety bars.
- Assumptions/Dependencies: Established alignment consensus; reliable verifiability; broad political legitimacy.
Notes on cross-cutting assumptions and dependencies:
- FLOP thresholds must remain predictive of dangerous capability; rapid algorithmic efficiency gains could undermine them.
- Ability to locate and monitor existing chips is pivotal; effectiveness declines if accelerators become ubiquitous in consumer devices.
- Hardware attestation must be tamper-resistant; otherwise physical inspections remain necessary.
- Success depends on political will, international trust-building, and enforcement credibility; staged implementation reduces barriers.
- Research restrictions must be narrowly scoped to minimize collateral damage in benign AI subfields; regular reviews are needed to adapt to paradigm shifts.
Collections
Sign up for free to add this paper to one or more collections.