Towards Blind and Low-Vision Accessibility of Lightweight VLMs and Custom LLM-Evals
Abstract: Large Vision-LLMs (VLMs) excel at understanding and generating video descriptions but their high memory, computation, and deployment demands hinder practical use particularly for blind and low-vision (BLV) users who depend on detailed, context-aware descriptions. To study the effect of model size on accessibility-focused description quality, we evaluate SmolVLM2 variants with 500M and 2.2B parameters across two diverse datasets: AVCaps (outdoor), and Charades (indoor). In this work, we introduce two novel evaluation frameworks specifically designed for BLV accessibility assessment: the Multi-Context BLV Framework evaluating spatial orientation, social interaction, action events, and ambience contexts; and the Navigational Assistance Framework focusing on mobility-critical information. Additionally, we conduct a systematic evaluation of four different prompt design strategies and deploy both models on a smartphone, evaluating FP32 and INT8 precision variants to assess real-world performance constraints on resource-limited mobile devices.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explores how small, efficient AI models that can “see” and “talk” (called vision-LLMs, or VLMs) can help blind and low-vision (BLV) people by describing what’s happening in videos. The goal is to make these descriptions good enough for everyday use and to run them directly on a smartphone—no internet or cloud needed—so they’re fast, private, and practical.
What questions did the researchers ask?
The researchers focused on three simple questions:
- Can small models (which fit on a phone) make video descriptions that are good enough for BLV users when they follow professional audio-description rules?
- What trade-offs happen when you run these models on a regular smartphone (speed, memory, battery)?
- Are new evaluation methods (made for BLV needs) better than standard text comparison metrics for judging description quality?
How did they do the study?
They tested two versions of a lightweight video-understanding model called SmolVLM2:
- A smaller one with about 500 million “parameters” (think of parameters like tiny settings in the model’s “brain”).
- A larger one with about 2.2 billion parameters.
They used two video sets:
- Charades (indoor scenes like cooking or cleaning).
- AVCaps (outdoor scenes like streets, parks, and natural areas).
To keep things efficient, they didn’t process every single frame. Instead, they picked “keyframes,” like highlight snapshots that capture the biggest changes—similar to choosing the most important photos from a long slideshow.
They tried four ways of “prompting” (which means how you instruct the model):
- A standard prompt alone.
- A prompt plus extra context (human notes from the dataset).
- A prompt plus context plus professional audio-description (AD) guidelines (rules used by organizations like Netflix to make descriptions helpful and consistent).
- A prompt plus AD guidelines (without the dataset notes).
They evaluated the descriptions in two ways:
- Standard text metrics (like BLEU, ROUGE, METEOR, CIDEr), which compare the AI’s text to a reference, but don’t always match BLV preferences.
- Two new BLV-focused frameworks that judge what actually matters to BLV users:
- Multi-Context BLV Framework: focuses on four kinds of information BLV users need:
- Spatial orientation (where things are, directions, layout).
- Social interaction (who’s there, emotions, relationships).
- Action and events (what happens and in what order).
- Ambience (mood, lighting, setting).
- Navigational Assistance Framework: focuses on safety and movement:
- Descriptiveness (details about obstacles, paths, and layout).
- Objectivity (facts, not guesses).
- Accuracy (precise locations and distances).
- Clarity (easy to follow step by step).
They also checked real-world use by running both models on a mid-range Android phone. They compared two versions:
- FP32 (full detail numbers—like high-quality photos).
- INT8 (compressed numbers—like smaller, lower-resolution photos). This “quantization” makes the model smaller and faster but may slightly change outputs.
What did they find?
Big picture:
- Following professional AD guidelines helped a lot. The models produced better, more useful descriptions when they had clear rules to follow.
- Small doesn’t mean weak. The 500M model often did as well as—or better than—the 2.2B model in areas BLV users care about, especially outdoors.
Key results explained simply:
- Indoor vs. outdoor: The larger model usually benefited more from extra context indoors (where scenes are more predictable). Outdoors, the smaller model held its own and sometimes did better in clarity and objectivity, which matter for safe navigation.
- Action sequences are hard: Both models struggled most with “what happened when” (temporal reasoning), which is important for understanding fast-changing scenes.
- Ambience and social cues: The smaller model often captured environmental mood and social details well, helping users build a mental picture of the scene.
- Navigation safety: The smaller model tended to be more objective (sticking to the facts), which is safer for mobility. The larger model had slightly better accuracy outdoors (precise positions) and clearer descriptions indoors.
- On the phone: The 500M model could run locally in about a minute to a minute and a half per description on a consumer Android phone. The INT8 (compressed) versions were generally faster and smaller, making on-device use realistic. Sometimes the compressed model generated longer outputs, which could increase total time, but per-token speed improved a lot.
Why the new evaluation methods matter:
- Standard text metrics compare the AI’s words to a reference text. That can miss what BLV users actually need (like precise directions or warnings). The new BLV-focused frameworks judge the descriptions by how useful they are for understanding space, people, actions, and safe movement—closer to real user needs.
Why does this matter?
This research shows that helpful, privacy-preserving video descriptions can happen on regular phones without the cloud. That’s huge for BLV users:
- It’s faster and more reliable (no need for internet).
- It’s private (your video stays on your device).
- It’s affordable and widely accessible (no expensive hardware required).
For developers and organizations:
- Use professional AD guidelines in prompts to boost quality.
- Small models are good enough for many BLV tasks and are easier to deploy.
- Evaluate with BLV-focused metrics, not just standard text similarity, to reflect real needs.
Future impact:
- Better on-device assistive apps for navigation and daily life.
- Smarter prompts and training that improve event sequencing (the hardest part).
- More fair evaluations that prioritize BLV user preferences, not just matching a reference sentence.
In short: With smart instructions and BLV-centered evaluation, compact AI models can deliver practical, high-quality video descriptions right on your phone—bringing accessible technology closer to everyone who needs it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future work could address:
- Ground truth validity: The “ground truth” descriptions are generated by Qwen 2.5 VL 7B guided by AD guidelines, not written by professional audio describers nor validated by BLV users; how does this surrogate ground truth differ from human-authored AD, and what is its impact on evaluation outcomes?
- LLM-as-judge reliability: Custom accessibility scores rely on GPT-OSS-20B judgments without human raters; what is the inter-model reliability, test–retest stability, and bias of LLM-based evaluators compared to BLV user evaluations and trained AD professionals?
- Metric calibration and consistency: The paper claims dimension weighting “based on navigation critical scenarios,” but formulas use uniform averaging and include LaTeX/label errors (e.g., “Action {paper_content} Event,” “Special Orientation”); metrics need formal definitions, scale anchoring, weighting rationale, and error-free implementation verified via psychometric analyses (e.g., Cronbach’s alpha, convergent validity).
- Statistical rigor: Results lack statistical significance testing, effect sizes, confidence intervals, and power analysis; future work should quantify whether observed differences across models/prompting strategies are statistically meaningful.
- Dataset representativeness: Only subsets were used (Indoor: 498/1,863; Outdoor: 423/2,061), with limited details on stratification criteria (lighting, motion complexity, occlusions, crowd density, clip length); does performance generalize across the full distributions of these datasets and other BLV-relevant scenarios (e.g., transit hubs, signage-heavy spaces)?
- Temporal coverage limitations: Keyframe extraction reduces videos to 3–4 frames; there is no ablation on keyframe density, no comparison to full-frame or clip-based processing, and no test of alternative sampling (e.g., adaptive segment sampling, SSIM-based, deep feature-based sampling); how do these choices affect temporal reasoning and action event accuracy?
- Action sequence understanding: “Action Events” is the lowest-scoring dimension across conditions; what modeling strategies (e.g., explicit temporal modules, structured planning, event graphs, streaming perception) best address sequential reasoning deficits in lightweight VLMs?
- Modalities not leveraged: The approach is vision-only; BLV navigation often depends on audio cues (environmental sounds, speech) and multimodal fusion; what gains arise from integrating audio tracks or sensor data (e.g., inertial, LiDAR, depth) for spatiotemporal grounding?
- Prompting confounds: The 2.2B model was not evaluated on “Prompt Only” and “Prompt + Context,” making size-based comparisons incomplete; a full factorial evaluation and per-guideline ablation (which of the 42 AD guidelines contribute most?) are needed to disentangle instruction complexity effects from model size.
- Quantization quality impact: INT8 vs FP32 comparisons focus on latency and token statistics, but do not evaluate description quality differences (accuracy, objectivity, hallucination rate); does quantization systematically alter semantic fidelity or increase unsafe omissions?
- On-device viability: Mobile tests were done on a single Android device (Vivo Y27) using CPU-centric inference; there is no analysis of battery drain, thermal throttling, memory fragmentation, or GPU/NPU acceleration; is real-time or near-real-time operation feasible across diverse consumer hardware, including iOS and mid/low-end devices?
- End-to-end accessibility pipeline: The paper omits the full loop (camera capture → inference → TTS → user interaction); how do latency, buffering, and incremental narration affect usability for navigation and social contexts, and what are acceptable delay thresholds for BLV users?
- Safety-critical evaluation: Navigation assistance is scored abstractly; there is no measurement of safety outcomes (e.g., obstacle/hazard false negatives/positives, distance estimation error, directional ambiguity rates); standardized, risk-focused benchmarks are needed.
- Hallucination auditing: Objectivity scores suggest assumption reduction for the 500M model, but hallucinations are not quantified (e.g., entity insertion, mislocalized hazards); robust hallucination taxonomies and audits are required for safety-critical applications.
- Indoor vs outdoor generalization: Context helps outdoors more than indoors in some metrics, but causality is unclear; which environmental factors (lighting dynamics, motion clutter, weather, crowding) drive these differences, and can models adaptively adjust descriptions?
- Guideline personalization: The 42 AD guidelines are applied uniformly; BLV users have heterogeneous preferences (verbosity, technicality, directional specificity); how should guideline selection and description style be personalized and dynamically controlled on device?
- Multilingual accessibility: The work is English-only; how do models perform under multilingual AD guidelines, code-switching, and locale-specific navigation conventions (units, signage, transit norms)?
- Bias and fairness: Person identification and social interaction are evaluated, but potential demographic biases (skin tone, attire, mobility aids), privacy risks, and stigmatizing language are not audited; what safeguards and policies are needed for ethical deployment?
- Benchmark baselines: There is no head-to-head comparison with state-of-the-art large VLMs (e.g., GPT-4V, Gemini) or specialized video models (e.g., Tarsier2, Apollo, BOLT) using the same prompts and evaluation frameworks; how close can lightweight models get to these baselines under identical conditions?
- Reproducibility assets: Prompts, keyframe extraction parameters, evaluation templates, and model configurations are not fully released; reproducibility would benefit from open-source code, prompt libraries, and standardized evaluation scripts/data splits.
- Keyframe algorithm justification: LUV-difference + Hanning smoothing is used without comparison to alternatives (SSIM, LPIPS, CLIP feature dynamics, motion vectors); which method best preserves accessibility-relevant events with minimal compute?
- Scale and scoring inconsistencies: Custom metric ranges vary across tables (e.g., Objectivity ≈2.7–3.3 vs ≈5.0–5.2 elsewhere) despite nominal 1–10 scales; clear normalization procedures, anchor examples, and calibration protocols are required to interpret scores consistently.
- Deployment privacy and security: Claims of privacy benefits are not matched with threat modeling (on-device logging, model leaks, adversarial prompts, offline storage risks); what guarantees can be made and how are they validated?
- Training/fine-tuning gap: Models are used with prompting only; does lightweight fine-tuning on accessibility-annotated corpora (VideoA11y or BLV-specific datasets) materially improve temporal reasoning, hazard coverage, and adherence to AD guidelines?
- Real-world field testing: No user studies or field trials assess usability, satisfaction, trust, and fatigue; controlled studies with BLV participants in indoor/outdoor tasks are needed to validate practical utility and iterate on design.
Practical Applications
Immediate Applications
Based on the paper’s findings, methods, and deployment results, the following applications can be implemented now, with notes on sectors, potential tools/workflows, and feasibility assumptions.
- On-device audio description for blind and low-vision users (Assistive technology, mobile software)
- A smartphone app that runs SmolVLM2-500M (preferably INT8) locally to generate context-aware audio descriptions of live or recorded videos, using the “Prompt + AD Guidelines” strategy and the adaptive keyframe extraction pipeline to keep latency and memory within consumer limits.
- Potential tools/products/workflows: “BLV Navigator” app; Edge Captioning SDK (gguf model packs + prompt library aligned to VideoA11y); integrated FFmpeg keyframe extraction; llama.cpp-based mobile runtime via Termux; offline Ollama-based evaluation.
- Assumptions/dependencies: 6 GB RAM-class devices; willingness to accept 60–83 s inference for multi-sentence outputs; lower accuracy on action/event sequencing; battery draw and thermal limits; INT8 precision trade-offs; human-in-the-loop review for safety-critical use.
- Accessibility QA and benchmarking suite for media teams (Media/Entertainment; academia; software)
- Use the Multi-Context BLV Framework and Navigational Assistance Framework to score captions/AD tracks, running GPT-OSS-20B locally via Ollama for reproducible, offline evaluations.
- Potential tools/products/workflows: “A11yEval CLI” with VideoA11y-compliant templates; batch scoring pipeline integrated into editorial QA; dashboards for spatial/social/action/ambience and navigational dimensions.
- Assumptions/dependencies: Local CPU/GPU enough to run GPT-OSS-20B; adoption of evaluation templates; alignment with studio workflows; reference bias awareness and human validation of outliers.
- Prompt engineering playbook and template library (Software; content production)
- Deploy standardized prompt sets that embed professional AD guidelines, since “Prompt + AD Guidelines” outperforms lighter strategies on most metrics (especially for SmolVLM2-500M).
- Potential tools/products/workflows: “AD Guidelines Prompt Pack” for MLLMs; copy-paste templates for annotation teams; model-specific prompt calibration.
- Assumptions/dependencies: Staff training; English-first prompts (multilingual support to be extended); consistent instruction-following across model updates.
- Video editing plugin for first-pass AD generation (Media/Entertainment, software)
- A plugin (Premiere/DaVinci/FFmpeg) that generates draft AD tracks using SmolVLM2 variants, then validates them with the custom metrics frameworks to prioritize edits (e.g., highlighting low scores in Accuracy or Action Events).
- Potential tools/products/workflows: “AD Studio Lite” plugin; export to DAISY/Netflix AD formats; automated keyframe selection to reduce compute.
- Assumptions/dependencies: Editorial review required; limited temporal reasoning in current models; licensing of models and datasets; plugin integration effort.
- Edge assistance in museums, retail, and campus settings (Public venues; education; retail)
- Device-mounted cameras process short clips locally to provide BLV-friendly descriptions (e.g., exhibit summaries, shelf contents), prioritizing Objectivity and Clarity from the NAF.
- Potential tools/products/workflows: “Museum Guide” kiosks; “Retail Assistant” shelf-scanning stations; per-venue prompt tuning aligned with VideoA11y.
- Assumptions/dependencies: Privacy controls; signage and disclaimers; power and compute provisioning; controlled environments work best (indoor scores higher for clarity).
- Wayfinding aid in public transit and outdoor navigation (Transportation; daily life)
- A phone-mounted helper for mobility-critical information (hazards, layout cues), using the Navigational Assistance Framework to tune outputs for descriptiveness and clarity.
- Potential tools/products/workflows: “Transit Wayfinder” mobile app; hazard-focused prompts; haptic feedback integration via screen-reader APIs.
- Assumptions/dependencies: Accuracy limitations outdoors; liability and safety disclaimers; mounting stability; sunlight/glare variability; bandwidth-free operation is critical.
- Accessibility add-on for learning management systems (Education)
- Automatically generate AD for lecture and lab recordings with smaller VLMs on campus servers or faculty laptops; use Multi-Context scores to prioritize revisions (e.g., Spatial Orientation and Ambience for lab demos).
- Potential tools/products/workflows: “CourseA11y Plugin”; batch captioning with evaluation reports; guided edits based on low-scoring dimensions.
- Assumptions/dependencies: IT deployment of local inference; diverse subject matter demands domain prompts; instructor approval flow.
- Screen-reader-aware media overlay (Software; daily life)
- A browser/OS extension that uses keyframe extraction + small VLM inference to deliver structured AD aligned to professional guidelines for videos encountered in apps.
- Potential tools/products/workflows: “MediaA11y Extension”; integration with Android/iOS accessibility APIs; on-device caching.
- Assumptions/dependencies: Permissions to access frames; energy/latency constraints; model footprint on device storage.
- Mobile developer SDK for quantized multimodal inference (Software; embedded)
- Provide a packaged gguf conversion workflow, quantized model variants, and llama.cpp integration for app developers building on-device AD features.
- Potential tools/products/workflows: “Edge VLM SDK” with conversion scripts, benchmark suites, and prompt libraries.
- Assumptions/dependencies: Model licensing and redistribution; device compatibility (MediaTek/Adreno/Mali GPUs); INT8 output variability.
- Keyframe extraction pipeline for compute-aware video processing (Software)
- Adopt the LUV-difference + Hanning smoothing algorithm to auto-select frames that capture scene changes, reducing compute while preserving salient visual changes for description generation.
- Potential tools/products/workflows: FFmpeg filter modules; edge preprocessing service.
- Assumptions/dependencies: Trade-off: fewer frames can reduce temporal fidelity; tuning per content type (action-heavy vs. static scenes).
Long-Term Applications
These applications require further research, scaling, standardization, or development—particularly to improve temporal reasoning, outdoor robustness, multilingual support, and safety.
- AR glasses for continuous, privacy-preserving audio description (Assistive technology; wearables; robotics)
- Real-time, on-device BLV assistance with haptic cues and spatial audio; better temporal modeling to fix low Action Events scores; dynamic context switching between Multi-Context dimensions.
- Assumptions/dependencies: NPU-enabled wearables; battery life; thermal envelopes; model compression; robust outdoor performance and hazard detection.
- Smart cane or wearable robotics for navigation (Robotics; healthcare)
- Sensor fusion (camera + depth + IMU) with NAF-tuned outputs for safe navigation; explicit hazard identification and distance estimation.
- Assumptions/dependencies: Accuracy thresholds for safety; regulation and liability; standardized evaluation harnesses; user studies with BLV communities.
- Standards and certification for BLV video accessibility (Policy; media)
- Formalize the Multi-Context BLV and Navigational Assistance frameworks into industry standards, compliance tests, and procurement criteria (e.g., streaming platforms, public broadcasters).
- Assumptions/dependencies: Consensus-building across disability advocates, studios, and regulators; longitudinal validation; integration with WCAG and regional guidelines.
- Multilingual and culturally sensitive AD generation (Media; education; global services)
- Extend models and prompts to multiple languages and cultural contexts, including localized idioms and environment norms.
- Assumptions/dependencies: Diverse training data; guideline adaptations; evaluation datasets beyond English; community co-design.
- Domain-specific fine-tuning for safety-critical settings (Healthcare; industrial training; enterprise)
- Specialized AD for operating rooms, lab procedures, factory floors—emphasizing Accuracy and Objectivity; tie-ins to safety SOPs.
- Assumptions/dependencies: Curated, permissioned datasets; strict QA pipelines; human-in-the-loop validation; privacy and compliance (HIPAA, OSHA).
- On-device AD distribution for streaming platforms (Media/Entertainment)
- Store small/quantized models on consumer devices to generate AD dynamically per user preference (e.g., verbosity, ambience emphasis) without cloud dependence.
- Assumptions/dependencies: DRM-compatible deployment; storage budgets; OS-level APIs; standardized prompt packs; performance on entry-level devices.
- Interactive AD co-pilot for editors (Software; media)
- A real-time assistant that suggests edits and re-writes based on custom metrics, highlights weak dimensions (e.g., low accuracy or poor spatial orientation), and simulates BLV user preferences.
- Assumptions/dependencies: UI/UX integration; versioning and audit trails; editor acceptance; model reliability on long-form content.
- Personalized, privacy-preserving continual learning (Software; assistive technology)
- On-device adaptation to user preferences (verbosity, tone, context emphasis), using federated learning or privacy-preserving fine-tuning.
- Assumptions/dependencies: Safe personalization without leakage; compute budgets; robust preference modeling.
- Hardware–software co-design for edge multimodal inference (Semiconductors; OS/platforms)
- NPUs and memory hierarchies optimized for small VLM workloads (keyframe-centric inference, fast TTFB); OS primitives for real-time AD.
- Assumptions/dependencies: Vendor roadmaps; developer tooling; cross-device performance parity; energy efficiency targets.
- City-scale accessible kiosks and transit signage (Smart cities; public policy)
- Embedded, offline AD modules in public infrastructure that deliver contextual descriptions and navigational cues tailored by NAF and Multi-Context frameworks.
- Assumptions/dependencies: Maintenance, security, and privacy; outdoor robustness; policy mandates; accessibility testing at scale.
- Map-integrated navigation with multimodal fusion (Transportation; software)
- Fuse camera-based AD with GNSS and map semantics for route-aware narration (e.g., “crosswalk in 10 m to your right”), improving Accuracy and Clarity.
- Assumptions/dependencies: Reliable sensor fusion; latency constraints; environment variability; alignment with mobility aids.
- Real-time streaming AD for live events (Media; venues)
- Low-latency pipelines that combine improved token throughput, better temporal reasoning, and model distillation to deliver live audio descriptions.
- Assumptions/dependencies: Throughput improvements beyond current TPS; scalable quantization strategies; venue compute; fallback to human describers.
- Safety and emergency detection layers (Public safety; healthcare)
- Proactive detection of hazards (spill, smoke, crowd movement) and alerts integrated with AD; NAF-driven prioritization of clarity and accuracy.
- Assumptions/dependencies: High recall/precision; liability frameworks; integration with alarms and accessibility devices.
- Institutional policies for accessible training media (Policy; corporate/education)
- Requirements that all training videos meet a minimum “A11y-Score” across the custom frameworks; procurement and auditing processes.
- Assumptions/dependencies: Organizational buy-in; standardized scoring rubrics; accessible-by-default content pipelines.
Glossary
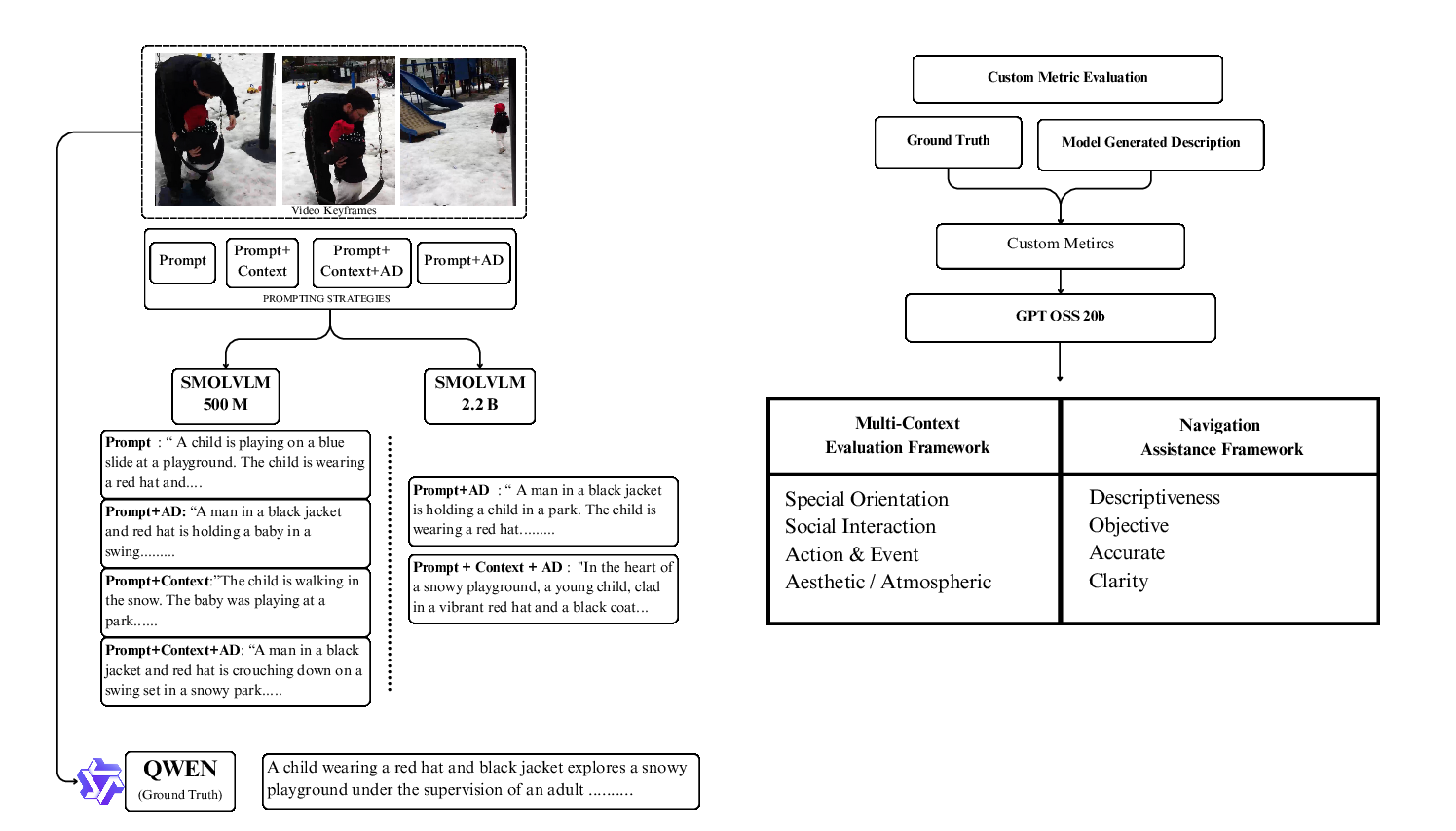
- Action events: Discrete activities and their temporal sequence within a video, important for describing dynamic content for accessibility. "the Multi-Context BLV Framework evaluating spatial orientation, social interaction, action events, and ambience contexts;"
- Adaptive keyframe extraction algorithm: A method that automatically selects informative frames from video by analyzing frame differences to reduce computation while preserving key visual changes. "we implemented an adaptive keyframe extraction algorithm that analyzes inter-frame differences in the LUV color space."
- Ambience: The environmental mood and atmospheric details (e.g., lighting, tone) that enrich understanding of a scene for accessibility. "(iv) {Ambience} (1-10 scale): Captures mood, lighting conditions, environmental atmosphere, and sensory details that enhance immersive comprehension."
- Audio-description (AD) guidelines: Professional standards that structure accessible descriptions (character identification, scene details, narrative flow) for blind and low-vision audiences. "To address these limitations, professional audio-description (AD) guidelines developed by organizations such as Netflix, Ofcom, Media Access Canada, and the Described and Captioned Media Program\cite{li2025videoa11y} provide structured frameworks that ensure consistency in character identification, scene description, and narrative flow comprehension."
- AVCaps: An audio-visual dataset with modality-specific captions used for evaluating video description systems in outdoor scenarios. "evaluate SmolVLM2 variants with 500M and 2.2B parameters across two diverse datasets: AVCaps (outdoor), and Charades (indoor)."
- BLEU-1: A machine translation/captioning metric measuring n-gram precision (unigrams), used to evaluate overlap with reference descriptions. "Our NLP metric scores align with video captioning benchmarks: BLEU-1 > 0.3 indicates strong performance"
- BLEU-4: A machine translation/captioning metric measuring n-gram precision up to 4-grams, indicating fluency and overlap with references. "Strategy / Dataset & BLEU-1 & BLEU-4 & METEOR & ROUGE-L & SPICE & CIDEr \"
- Blind and low-vision (BLV) users: People who rely on accessible, detailed, and context-aware descriptions to understand visual content. "particularly for blind and low-vision (BLV) users who depend on detailed, context-aware descriptions."
- Charades: A benchmark indoor activity dataset used to evaluate video understanding and captioning models. "evaluate SmolVLM2 variants with 500M and 2.2B parameters across two diverse datasets: AVCaps (outdoor), and Charades (indoor)."
- CIDEr: An image/video captioning metric evaluating consensus with multiple references using TF-IDF weighting of n-grams. "CIDEr > 0.7 is very good, 0.4–0.7 moderate, < 0.4 low (Vedantam et al., 2015)."
- Clarity: A Navigational Assistance Framework dimension assessing how organized, sequential, and unambiguous the information is for navigation. "(iv) {Clarity}: Information organization for sequential navigation decision-making, including logical flow and unambiguous directional references."
- Custom accessibility metrics: Evaluation measures tailored to BLV users’ needs, emphasizing descriptiveness, objectivity, accuracy, and clarity over reference overlap. "both standard NLP metrics and custom accessibility metrics designed for BLV users."
- Described and Captioned Media Program (DCMP): An organization providing guidelines for audio description to ensure accessible media. "professional audio-description (AD) guidelines developed by organizations such as Netflix, Ofcom, Media Access Canada, and the Described and Captioned Media Program\cite{li2025videoa11y}"
- Descriptiveness: A Navigational Assistance Framework dimension evaluating richness of spatial detail, hazards, and environment features. "(i) {Descriptiveness}: Spatial layout detail, hazard identification, and environmental feature descriptions (obstacles, pathways, boundaries)."
- Edge deployment viability: The feasibility of running models on resource-constrained devices (e.g., phones) with acceptable performance and memory footprints. "while maintaining exceptional edge deployment viability with GPU memory requirements of only 1.8 GB and 5.2 GB respectively"
- FP32: 32-bit floating-point precision used for model weights and computations, typically offering higher accuracy at greater resource cost. "evaluating FP32 and INT8 precision variants to assess real-world performance constraints on resource-limited mobile devices."
- GGUF format: A binary model format optimized for efficient inference with llama.cpp and similar runtimes on edge devices. "requiring model conversion to .gguf format for mobile compatibility."
- Hanning window smoothing: A signal processing technique applying a Hanning window to smooth frame difference signals when selecting keyframes. "applies Hanning window smoothing"
- Human annotations (HA): Textual descriptions or labels provided by humans used to guide and enhance model-generated video descriptions. "human annotations (HA) and contextual information are integrated to enhance model understanding"
- INT8 quantization: Reducing model weights/activations to 8-bit integers to improve speed and memory efficiency on constrained hardware. "INT8 quantized versions were generated through Hugging Face's "GGUF My Repo" feature to evaluate precision-performance trade-offs"
- Keyframe density: The number of selected keyframes per video, trading off temporal coverage with computational cost. "while increasing keyframe density can enhance temporal coverage, it also introduces additional computational cost"
- llama.cpp: A lightweight inference framework enabling local execution of LLMs/VLMs on CPUs/edge devices. "Our deployment methodology employed the llama.cpp framework's llama-mtmd-cli tool"
- LLM-Evals: Evaluation procedures or tooling for LLMs tailored to specific criteria, here customized for accessibility. "Towards Blind and Low-Vision Accessibility of Lightweight VLMs and Custom LLM-Evals"
- LUV color space: A perceptually uniform color space used to measure inter-frame differences for keyframe selection. "analyzes inter-frame differences in the LUV color space."
- METEOR: A machine translation/captioning metric emphasizing semantic matching via stemming, synonymy, and alignment. "Prompt + Context + AD Guidelines occasionally excels in semantic-matching metrics like METEOR"
- Multi-Context BLV Framework: An evaluation framework scoring descriptions across spatial orientation, social interaction, action events, and ambience for BLV needs. "the Multi-Context BLV Framework evaluating spatial orientation, social interaction, action events, and ambience contexts;"
- Navigational Assistance Framework: An evaluation framework focusing on mobility-critical information: descriptiveness, objectivity, accuracy, and clarity. "the Navigational Assistance Framework focusing on mobility-critical information."
- NLP metrics: Standard natural language processing evaluation metrics (e.g., BLEU, ROUGE, METEOR, CIDEr, SPICE) used for caption comparison. "We employ dual assessment methodologies: standard NLP metrics for comparison with existing research"
- Objectivity: A Navigational Assistance Framework dimension measuring factuality and avoidance of subjective assumptions in spatial descriptions. "(ii) {Objectivity}: Factual reporting without assumptions, avoiding subjective interpretations of spatial relationships."
- Ollama: A local model serving environment enabling offline inference and reproducible evaluations. "running locally via the Ollama\cite{ollama2024} server"
- Prompt Only: A baseline prompting strategy using zero-shot generation with a standardized prompt without extra context or guidelines. "(1) {Prompt Only} - utilizing zero-shot generation with the standardized compliant prompt to establish baseline performance without additional guidance."
- Prompt with AD Guidelines: A strategy combining the compliant prompt with audio-description guidelines to improve accessibility quality. "(4) {Prompt with AD Guidelines} - integrating the compliant prompt with audio-description guidelines only to test whether structured accessibility guidelines alone can enable compact models to produce descriptions meeting BLV users' requirements."
- Prompt with Context: A strategy augmenting the prompt with original human annotations to leverage existing dataset information. "(2) {Prompt with Context} - incorporating the compliant prompt with original human annotations from the datasets"
- Prompt with Context and AD Guidelines: A comprehensive strategy combining prompt, human annotations, and full AD guidelines. "(3) {Prompt with Context and AD Guidelines} - combining the prompt with human annotations and 42 professional audio-description guidelines to assess comprehensive multimodal instruction following."
- Qwen 2.5 VL 7B Instruct: A vision-LLM variant used to generate ground truth following expert AD guidelines. "We use Qwen 2.5 VL 7B Instruct with expert audio-description guidelines from VideoA11y"
- Reference-based metrics: Evaluation methods that compare generated text to reference descriptions, which may be biased for accessibility tasks. "Our evaluation protocol addresses the critical limitations of reference based metrics for accessibility applications"
- ROUGE-L: A summarization/captioning metric based on longest common subsequence overlap with references. "Strategy / Dataset & BLEU-1 & BLEU-4 & METEOR & ROUGE-L & SPICE & CIDEr \"
- safetensors: A secure, efficient tensor serialization format used for storing and converting model weights. "FP32 variants were converted from their original safetensors format using the official convert_hf_to_gguf.py script"
- SmolVLM2-500M-Video-Instruct: A compact vision-LLM variant fine-tuned for video understanding and edge deployment. "we selected SmolVLM2-500M-Video-Instruct and SmolVLM2-2.2B-Video-Instruct due to their combined advantages for video description tasks"
- SmolVLM2-2.2B-Video-Instruct: A larger compact VLM variant offering enhanced quality for video description with manageable deployment requirements. "we selected SmolVLM2-500M-Video-Instruct and SmolVLM2-2.2B-Video-Instruct due to their combined advantages for video description tasks"
- SPICE: A captioning metric evaluating semantic propositional content alignment with references. "Strategy / Dataset & BLEU-1 & BLEU-4 & METEOR & ROUGE-L & SPICE & CIDEr \"
- Spatial Orientation: A Multi-Context BLV dimension assessing location, directions, relative positions, and layout for mental mapping. "(i) {Spatial Orientation} (1-10 scale): Assesses location descriptions, directional cues, relative positioning, and environmental layout information essential for mental mapping."
- Stratified sample: A sampling approach ensuring coverage across key subgroups or environments for balanced evaluation. "This 20\% sample was stratified across different outdoor scenarios (urban environments, parks, streets, natural settings) to maintain environmental diversity"
- Temporal mechanisms: Model components capturing time-based dependencies in video for coherent sequence descriptions. "Both models are explicitly fine-tuned for video understanding with temporal mechanisms essential for coherent description generation"
- Termux: A terminal emulator and Linux environment on Android used to compile and run inference locally. "The mobile execution environment utilized Termux for Android terminal access"
- Video-MME: A benchmark for video understanding/captioning used to report model performance. "The 500M variant achieves competitive performance on Video-MME (42.2) with maximum computational efficiency"
- VideoA11y: A methodology and dataset providing expert audio-description guidelines and evaluation procedures for accessible video descriptions. "following the VideoA11y evaluation methodology \cite{li2025videoa11y}"
- Vision-LLMs (VLMs): Multimodal models that process both visual and textual inputs to understand and generate descriptions. "Large multimodal vision-LLMs (VLMs), such as GPT and LLaVA series by OpenAI and Microsoft\cite{liu2023llava,openai2023gpt4}, have shown impressive capabilities in understanding and generating detailed descriptions of visual content."
- Zero-shot generation: Producing outputs without task-specific training examples, relying on general instruction-following capabilities. "utilizing zero-shot generation with the standardized compliant prompt to establish baseline performance without additional guidance."
Collections
Sign up for free to add this paper to one or more collections.

