EffiReason-Bench: A Unified Benchmark for Evaluating and Advancing Efficient Reasoning in Large Language Models
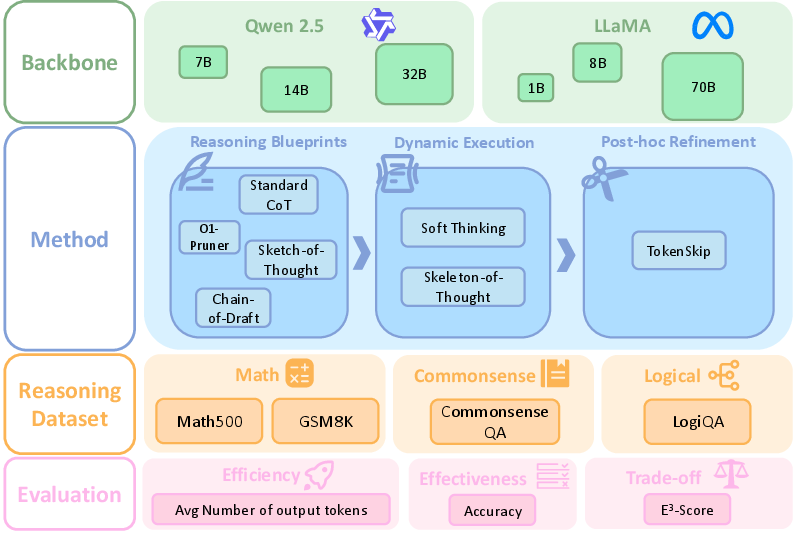
Abstract: LLMs with Chain-of-Thought (CoT) prompting achieve strong reasoning but often produce unnecessarily long explanations, increasing cost and sometimes reducing accuracy. Fair comparison of efficiency-oriented approaches is hindered by fragmented evaluation practices. We introduce EffiReason-Bench, a unified benchmark for rigorous cross-paradigm evaluation of efficient reasoning methods across three categories: Reasoning Blueprints, Dynamic Execution, and Post-hoc Refinement. To enable step-by-step evaluation, we construct verified CoT annotations for CommonsenseQA and LogiQA via a pipeline that enforces standardized reasoning structures, comprehensive option-wise analysis, and human verification. We evaluate 7 methods across 6 open-source LLMs (1B-70B) on 4 datasets spanning mathematics, commonsense, and logic, and propose the E3-Score, a principled metric inspired by economic trade-off modeling that provides smooth, stable evaluation without discontinuities or heavy reliance on heuristics. Experiments show that no single method universally dominates; optimal strategies depend on backbone scale, task complexity, and architecture.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (the big idea)
This paper introduces EffiReason-Bench, a fair “test track” for checking how well AI LLMs can reason without wasting words. Today, many AIs solve problems by “thinking out loud” (writing lots of steps), which often helps—but they sometimes overthink, writing way more than needed. That makes answers slower, more expensive, and sometimes less accurate. EffiReason-Bench compares different tricks to keep reasoning short and smart, and it also adds a new score, E3-Score, to measure the balance between being right and being efficient.
What the researchers wanted to find out
The authors asked simple but important questions:
- Which methods help AIs stay accurate while using fewer words?
- Do these methods work the same on different types of problems (math, everyday commonsense, and logic)?
- Does the size of the AI model (small vs. big) change which method works best?
- Can we measure accuracy and efficiency together in a fair, stable way?
How they did it (in plain language)
First, they set up a unified test bench (EffiReason-Bench) so every method and model is tested the same way. They tried 7 reasoning methods on 6 different LLMs, from small ones to very large ones, across 4 datasets:
- Math: GSM8K (grade-school math), MATH500 (harder competition problems)
- Commonsense: CommonsenseQA (everyday facts and logic)
- Logic: LogiQA (formal logical reasoning)
Because CommonsenseQA and LogiQA don’t include step-by-step solutions, the authors created and checked their own high-quality “show your work” answers. Think of this like writing step-by-step proofs and having two people double-check them to make sure they’re correct and clear.
They grouped the 7 methods into three “when-to-intervene” categories:
- Reasoning Blueprints (before the model starts):
- Train or prompt the model to plan short reasoning from the start.
- Examples: keep explanations brief, teach the model to value shorter steps.
- Dynamic Execution (during the model’s thinking):
- Change how the model generates steps as it goes.
- Examples: first write a short outline, then fill in details; or think in a compressed, softer form instead of full sentences.
- Post-hoc Refinement (after the model finishes):
- Clean up the answer by removing redundant words that don’t matter.
They also created a new metric called E3-Score (Efficiency–Effectiveness Equilibrium Score). In simple terms:
- Accuracy matters more when you’re already doing well (because small gains are hard and important).
- Cutting words is good, but not if it makes you less correct.
- The score smoothly balances both—no weird jumps, no fragile settings—so you can compare methods fairly.
What they found (and why it matters)
The main message: there’s no one “best” method. What works best depends on the model, the task, and how hard the problem is.
Here are the most useful takeaways:
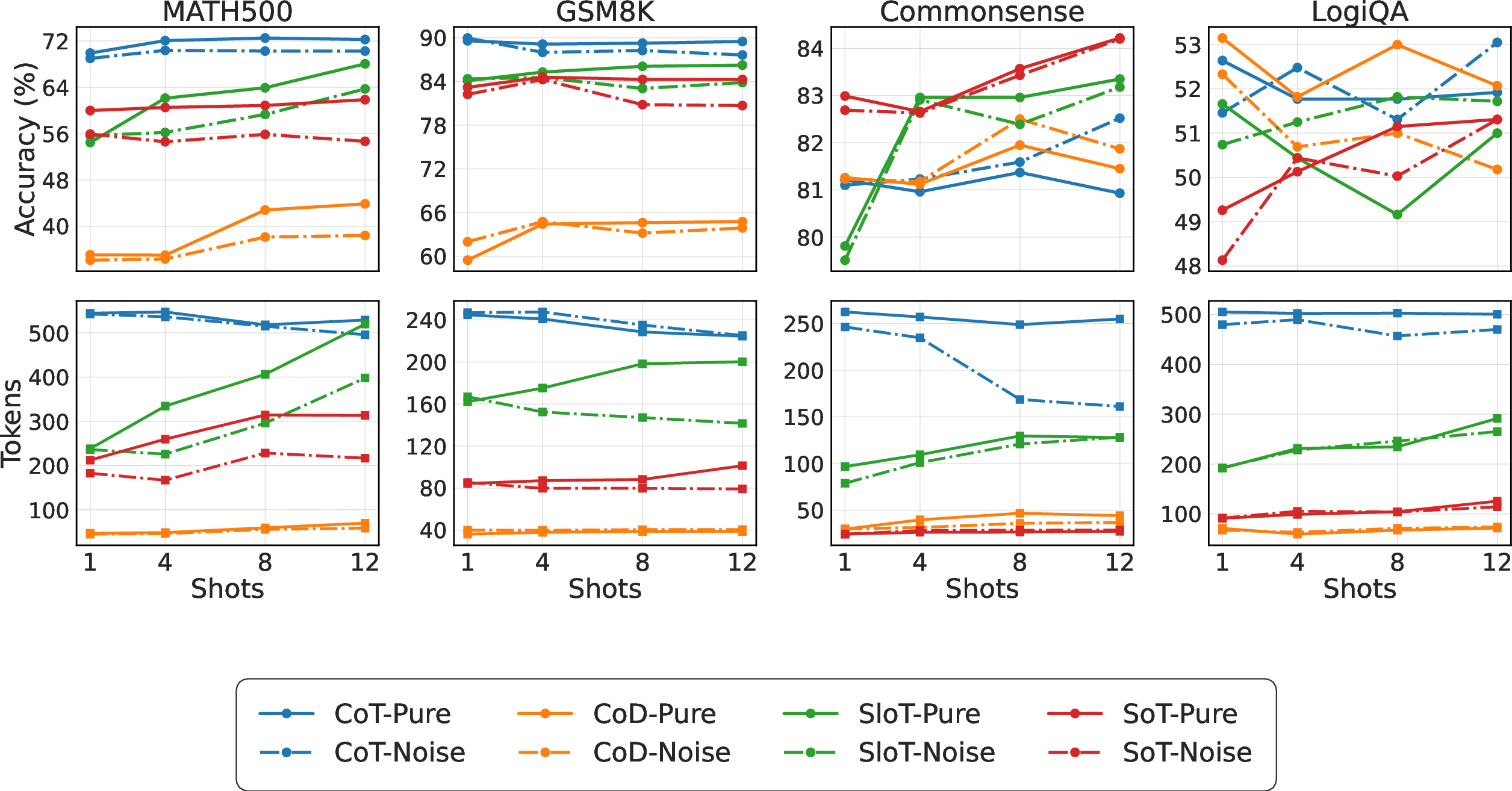
- Different problem types behave differently:
- Commonsense questions are quite tolerant of shorter reasoning. You can cut a lot of text and still keep accuracy.
- Logic and hard math need careful, complete steps. Compress too much, and accuracy can drop a lot.
- Method families have clear patterns:
- Reasoning Blueprints (train-free shortcuts like super-short prompts) can drastically reduce words, but often lose accuracy—especially on tougher tasks.
- A train-based blueprint (O1-Pruner) usually keeps or improves accuracy with modest shortening. It’s safer but needs training time.
- Dynamic Execution:
- “Soft Thinking” (a continuous/softer way of reasoning) is very robust—accuracy stays close to normal and sometimes improves—but it doesn’t always cut many words.
- “Skeleton-first then details” (SloT) can hurt accuracy in zero-shot settings, but with more example problems (few-shot), it learns better structures and scales up nicely.
- Post-hoc Refinement (TokenSkip) is a mixed bag:
- Very effective and safe for commonsense and many logic settings.
- Can be risky on hard math for some model families (it worked well on LLaMA models but caused big accuracy drops on Qwen for MATH500). This shows methods can be architecture-dependent.
- Few-shot learning (giving a few examples before testing):
- SloT improves a lot with more examples; it learns good structures from them.
- Blueprint methods that force “be brief” don’t benefit as much from more examples and can be fragile if examples are noisy.
- CoT (regular “think out loud”) stays stable and reliable across domains.
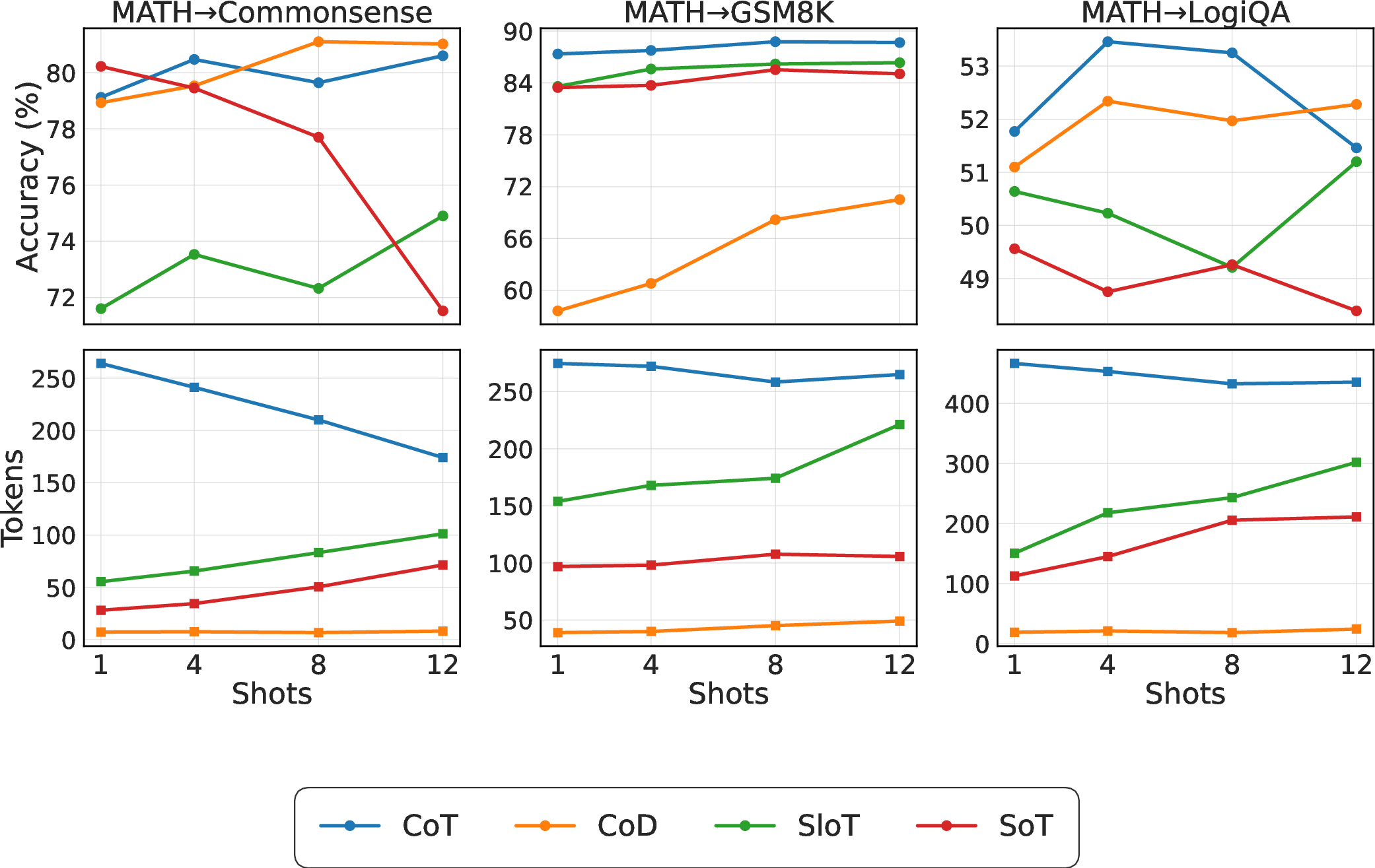
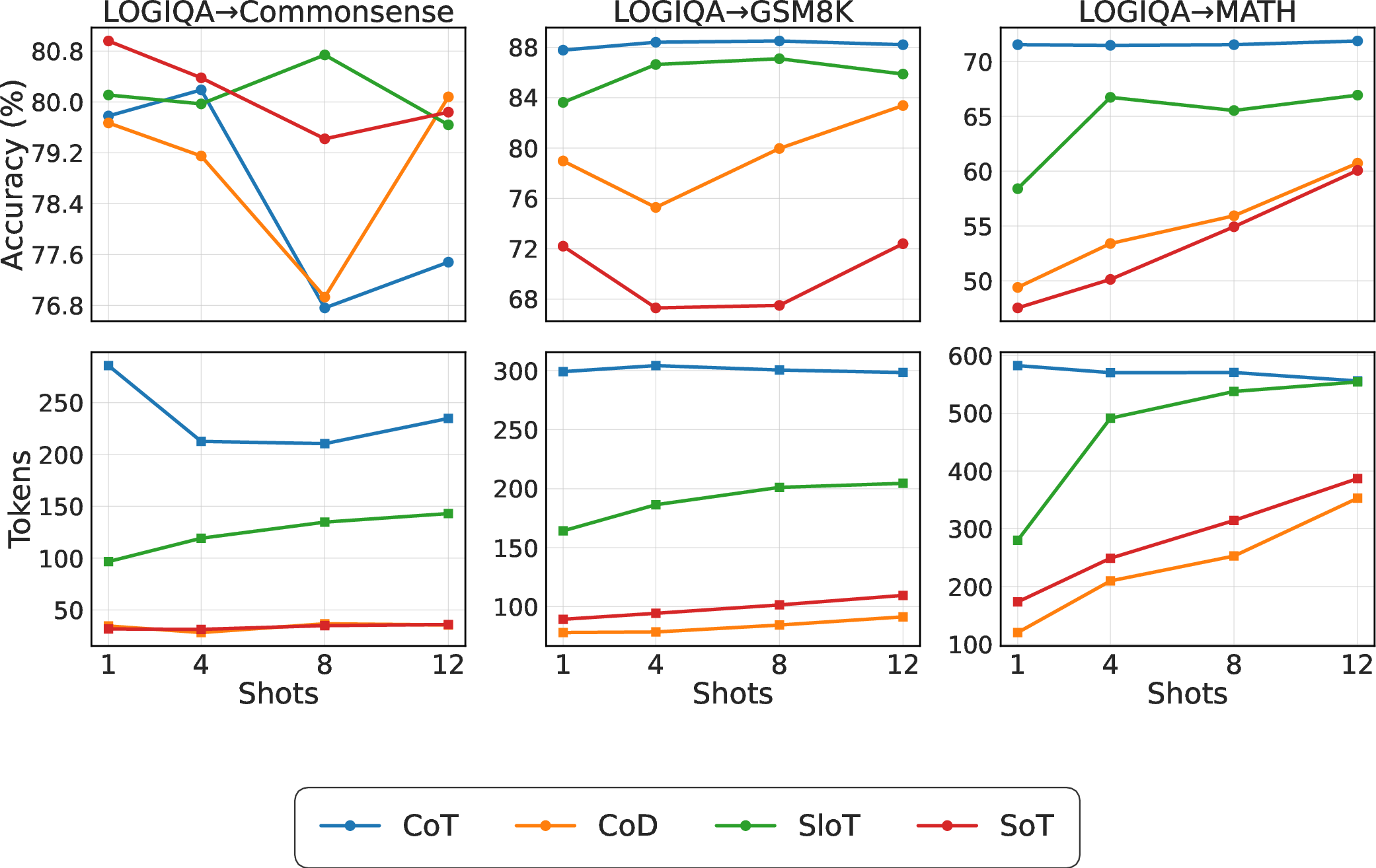
- Cross-domain transfer (examples from one domain, testing on another):
- CoT is the most stable.
- SloT can catch up with enough examples.
- Blueprint methods often transfer poorly.
- The E3-Score makes comparisons fairer:
- It rewards saving tokens without letting that hide accuracy loss.
- It values small accuracy gains when you’re already strong.
- It avoids the sudden jumps and hand-tuned settings that hurt older metrics.
What this means going forward
- You should choose efficiency methods based on the task and the model. For everyday reasoning, strong compression can work. For logic and hard math, be more careful—prefer methods that preserve reasoning steps.
- If you can train or fine-tune, O1-Pruner is a safer way to cut length while keeping accuracy.
- If you want stability across tasks, Soft Thinking is a strong default for accuracy, though not always the most concise.
- If you’ll provide examples, SloT can learn good structures and become competitive.
- Token-level cleanup after generation (like TokenSkip) can be great—but test it on your specific model and task.
Overall, EffiReason-Bench and the E3-Score give researchers and developers a fair, consistent way to build AIs that think clearly without overexplaining, saving time and cost while keeping answers reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to enable concrete follow-up by future researchers.
- Benchmark scope is narrow in task diversity: beyond GSM8K, MATH500, CommonsenseQA, and LogiQA, include domains such as code reasoning, scientific QA, multi-hop reading comprehension, theorem proving, planning/agentic tasks, and tool-assisted reasoning to test generality.
- No multilingual evaluation: assess efficient reasoning across languages and scripts (including non-Latin), and test whether compression strategies and E-Score calibrations transfer across linguistic phenomena.
- Efficiency is proxied by average output tokens only: incorporate end-to-end compute metrics (wall-clock latency, FLOPs, energy, memory/KV-cache footprint, throughput at batch size) and account for input/context tokens (instruction header and few-shot exemplars) to reflect real deployment costs.
- Token accounting excludes method overheads: explicitly measure two-stage generation costs (e.g., SloT skeleton + expansion) and any routing/estimation modules, and report whether parallelization claims translate into wall-clock savings on standard hardware.
- E-Score relies on tokens as a cost proxy: validate the metric against platform-specific compute realities (e.g., GPU/TPU utilization profiles) and assess whether E ranking aligns with latency and energy-based rankings.
- E-Score comparability across tasks/backbones is unclear: because it is defined relative to a baseline per setting, analyze how to make scores comparable across datasets and models (e.g., normalized global baselines or task/domain-specific isoquants).
- E hyperparameter choices are under-validated: empirically probe sensitivity to the weight (currently set to ) and (default ) across domains and accuracy regimes; provide guidelines for application-specific preferences (e.g., latency-critical vs accuracy-critical settings).
- Behavior of the transform near extremes is not analyzed: characterize stability when is close to 0 or 1, and extend E to non-binary scoring (partial credit, weighted accuracy, calibration metrics) and multi-answer tasks.
- No statistical rigor on reported results: add confidence intervals, multiple seeds, variance across prompt orders, and significance tests to ascertain the robustness of observed trade-offs and architecture/task effects.
- Process-level evaluation is absent despite new CoT annotations: quantify step-wise correctness, logical consistency, option-wise justification fidelity, and contradiction rates to measure “quality of reasoning” beyond final-answer accuracy.
- CoT annotation pipeline details are incomplete: report dataset sizes per split, inter-annotator agreement statistics, annotation guidelines, provenance of LLM assistance, and release status to assess quality and potential biases or leakage.
- Potential annotation bias/leakage is untested: evaluate whether LLM-assisted rationales bias models toward specific reasoning templates and whether exposure to standardized structures affects model behavior during evaluation.
- Method coverage omits key paradigms: include inference-time search (self-consistency, tree/graph-of-thought), retrieval/tool-use, early-exit/halting, compressive decoding, and model-level compression (quantization/pruning) under the same unified protocol for cross-paradigm completeness.
- Composition of methods is unexplored: test systematic combinations (e.g., Soft Thinking + TokenSkip; O1-Pruner + SloT) to identify synergistic or antagonistic interactions driving accuracy–efficiency outcomes.
- Architecture sensitivity remains a black box: conduct mechanistic and empirical analyses (attention patterns, gradient-based token importance, internal representation diagnostics) to explain why TokenSkip collapses on Qwen but improves LLaMA, and derive architecture-aware optimization strategies.
- Training/inference configuration is under-specified: document and ablate decoding hyperparameters (temperature, top-p, max tokens), stop criteria, and instruction styles to ensure fairness and reproducibility across methods and backbones.
- Soft Thinking “train-free” assumption needs clarification: specify whether any fine-tuning or adapter training was performed; if not, reconcile differences with original method variants that require training, and measure fairness versus train-based baselines.
- TokenSkip training details are unclear: describe the token-importance estimator (architecture, training data, loss), its compute cost, and how pruning thresholds are chosen; evaluate generalization across architectures and tasks.
- O1-Pruner scalability is limited by OOM: investigate memory-efficient training (LoRA/QLoRA, gradient checkpointing, optimizer state sharding, pipeline parallelism) to enable fine-tuning at 32B/70B scales and compare accuracy–efficiency at parity with other methods.
- Wall-clock parallelism claims for SloT are not substantiated: measure actual latency gains from skeleton-parallel generation across hardware stacks and report throughput impacts versus CoT and Soft Thinking.
- Few-shot exemplar effects are under-explored: quantify sensitivity to exemplar order, length, style, domain similarity, and position; measure adversarial/noisy exemplars beyond mild perturbations and evaluate mitigation strategies (robust routing, exemplar sanitization).
- Cross-domain transfer coverage is limited: extend transfer paths (e.g., code→math, scientific QA→logic), explore shot scaling laws per path, and characterize which structural features reliably transfer across distant domains.
- Overthinking detection and halting are not addressed: design and evaluate dynamic stop criteria that prevent unnecessary reasoning steps while safeguarding accuracy, including confidence-based halting and token-budget allocation.
- User-centric metrics are missing: assess rationale readability, faithfulness, and plausibility, and test whether TokenSkip or blueprint methods degrade explanation quality despite maintaining accuracy.
- Reproducibility and release details need concreteness: provide exact code, seeds, prompts, trained artifacts (including O1-Pruner/TokenSkip components), and instructions to reproduce E calculations and all reported tables on commonly available hardware.
- Pretraining contamination is unexamined: audit datasets for overlap with model pretraining and quantify potential contamination effects on measured accuracy and the perceived efficiency–effectiveness trade-offs.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, drawing on the benchmark, datasets, metric, and empirical findings reported in the paper.
- Application: Task-aware, cost-optimized LLM reasoning selection
- Sectors: Software/ML Ops, Cloud Platforms, Finance, E-commerce, Education
- What to do: Use the E3-Score and the benchmark’s findings to choose per-task reasoning strategies (e.g., prefer Soft Thinking for robust math/logic accuracy; apply TokenSkip for commonsense and LLaMA-based logic tasks; use concise blueprint prompts like CoD/SoT for robust commonsense tasks where extreme compression is acceptable).
- Tools/workflows:
- Integrate an evaluation harness that logs accuracy and average output tokens per model/method; compute E3-Score to select a default method per route.
- Implement a “Reasoning Controller” in serving stacks (e.g., vLLM, TGI) that routes to CoT/Soft Thinking/SloT/TokenSkip/CoD/SoT per task type.
- Assumptions/dependencies: Requires a baseline (e.g., standard CoT) to calibrate E3; token and accuracy logging; availability of method implementations for the chosen backbone.
- Application: LLM cost/carbon reduction with accuracy guardrails
- Sectors: Cloud, Green AI/ESG reporting, Enterprise IT
- What to do: Prioritize methods that maintain accuracy while saving tokens (e.g., TokenSkip on LLaMA for commonsense/logical tasks; Soft Thinking for robust accuracy with modest token change).
- Tools/workflows:
- Add E3-Score to internal KPIs; set budget-aware inference policies (e.g., “if E3 gain > threshold, permit compressed path; else fallback to CoT”).
- Carbon dashboards that convert token savings to energy/CO₂ estimates.
- Assumptions/dependencies: Token-based billing aligns with cost; CO₂ factors based on datacenter energy mix; method stability validated on in-domain data.
- Application: Architecture-aware deployment playbooks
- Sectors: Software/ML Ops
- What to do: Use the paper’s architecture sensitivity results to define safe defaults:
- LLaMA: TokenSkip is generally safe on commonsense/logical tasks; O1-Pruner can boost weaker backbones; SloT improves with more shots.
- Qwen: Avoid TokenSkip on difficult math (MATH500); consider Soft Thinking or standard CoT.
- Tools/workflows: Model-card checklists noting “safe/unsafe” pairings; route selection rules tied to model family and task.
- Assumptions/dependencies: Behavior generalizes to your fine-tuned variants; unit tests monitor accuracy regressions after changes.
- Application: Few-shot curation and serving guidelines
- Sectors: Education, Enterprise Knowledge Assistants, Customer Support
- What to do:
- For noisy or cross-domain exemplars, favor CoT or SloT (with enough shots) over CoD/SoT, which are brittle to exemplar quality and domain shift.
- On well-curated exemplars, use SloT to approach CoT accuracy with fewer tokens.
- Tools/workflows:
- Demo library with curated, human-audited exemplars (1/4/8/12 shots) per domain; auto-switch to CoT when demonstration quality is uncertain.
- Assumptions/dependencies: Access to curated demonstrations; ability to detect or score exemplar quality.
- Application: Reproducible benchmarking and model selection in R&D
- Sectors: Academia, Industry Research Labs
- What to do: Adopt EffiReason-Bench to compare efficient reasoning methods across backbones and tasks; report E3 alongside accuracy.
- Tools/workflows:
- Add the benchmark to CI for research models; standardize E3 as a gating metric in model “go/no-go” decisions.
- Assumptions/dependencies: Availability of released code and data; compute to run standardized evaluations.
- Application: Vendor evaluation and procurement with efficiency–effectiveness parity
- Sectors: Public Sector, Regulated Industries (Finance, Healthcare), Enterprise IT Procurement
- What to do: Require E3-Score reporting for proposed models/methods on representative tasks; reject proposals that trade excessive accuracy for token savings.
- Tools/workflows: RFP templates including E3 thresholds and task panels (math, commonsense, logic); third-party validation using EffiReason-Bench.
- Assumptions/dependencies: Agreement on baseline definitions; ability to test in the buyer’s environment.
- Application: Transparent reasoning datasets for evaluation and instruction tuning
- Sectors: Academia, EdTech, Model Training
- What to do: Use the paper’s verified CoT annotations for CommonsenseQA and LogiQA to evaluate intermediate reasoning or to perform instruction-tuning/RL with length-aware rewards.
- Tools/workflows:
- Train/evaluate with standardized four-stage structures (premise → formalization → condition evaluation → option mapping) to enforce reasoning integrity.
- Assumptions/dependencies: Dataset license compatibility; careful use to avoid overfitting to reasoning templates.
- Application: Product feature — “Conciseness mode” with accuracy budget
- Sectors: Productivity Apps, Knowledge Workflows, Consumer Assistants
- What to do: Offer a toggle that prefers concise reasoning when E3 is favorable on current task (e.g., commonsense Q&A), and auto-fallback to full CoT for complex math/logic or uncertain tasks.
- Tools/workflows: On-device or cloud LLM settings controlling method selection; per-task detectors (commonsense vs math vs logic) using simple classifiers.
- Assumptions/dependencies: Lightweight task classification; user-acceptable trade-offs; privacy constraints if routing externally.
- Application: LLMOps observability — “Reasoning Profiler”
- Sectors: Software/ML Ops
- What to do: Build dashboards showing accuracy, tokens, and E3 over time by task, method, backbone; alert on regressions (e.g., accuracy drops after enabling a pruning method).
- Tools/workflows: Instrumentation in inference services; A/B testing harness with E3 as primary metric.
- Assumptions/dependencies: Reliable ground-truth or high-quality proxy labels for accuracy; cohorting by task type.
- Application: Education/tutoring systems with adjustable explanation depth
- Sectors: Education, EdTech
- What to do: Dynamically adapt reasoning verbosity by student level — concise explanations for review, expanded CoT for instruction; use E3 to select the shortest explanation that preserves correctness.
- Tools/workflows: Tutor UI with explanation-depth slider mapped to method selection; logging of learning outcomes vs verbosity.
- Assumptions/dependencies: Alignment with curricula; safety and content quality review.
- Application: Accuracy-first workflows for safety-critical domains
- Sectors: Healthcare (non-diagnostic information), Finance (research assistance), Legal Drafting Aids
- What to do: Default to CoT or Soft Thinking for complex reasoning; only apply compression post-hoc if validated on the task (e.g., TokenSkip on LLaMA for logic) and with human oversight.
- Tools/workflows: Two-pass generate-and-check pipelines, where compressed rationales are verified against the original output.
- Assumptions/dependencies: Domain governance; audit logs of reasoning chains; human-in-the-loop sign-off.
- Application: Inference-time budget schedulers
- Sectors: Cloud Platforms, Contact Centers, RAG/Agent Systems
- What to do: Allocate token budgets per query based on difficulty signals; permit blueprint methods for simple commonsense queries, but use CoT/Soft Thinking for harder math/logic questions.
- Tools/workflows: Difficulty predictors (confidence, perplexity, or selective prediction); method selection policy maximizing E3 subject to budget constraints.
- Assumptions/dependencies: Reliable difficulty signals; controllable method switching without user-visible artifacts.
Long-Term Applications
The following require further research, scaling, or development (e.g., robustness, automation, standardization, or integration with larger systems).
- Application: Auto-selection meta-controller for efficient reasoning
- Sectors: Software/ML Ops, Agent Frameworks, Edge AI
- Vision: A learned router that detects task type, backbone, domain shift, and exemplar quality, then selects or blends methods (CoT, Soft Thinking, SloT, TokenSkip, CoD/SoT) to maximize E3 while meeting accuracy SLAs.
- Potential products: “EffiReason Router” SDK; policy-as-code for reasoning selection.
- Assumptions/dependencies: Labeled telemetry; robust task/difficulty detectors; lightweight switching overhead.
- Application: Architecture-aware pruning and compression suites
- Sectors: Model Training, Cloud, Edge Devices
- Vision: Pruning/compression tools that adapt pruning criteria to model family (e.g., LLaMA vs Qwen) and domain (math vs commonsense vs logic) to avoid failures like TokenSkip on Qwen math.
- Potential products: “Adaptive TokenSkip++” with model-specific calibration; RL-based O1-Pruner variants that avoid OOM and scale to larger backbones.
- Assumptions/dependencies: Access to model internals and training compute; automated safety checks against catastrophic accuracy loss.
- Application: Standardization of E3-Score as an industry KPI
- Sectors: Standards Bodies, Public Sector Procurement, Cloud Providers
- Vision: E3 becomes a procurement and reporting standard for balancing accuracy and efficiency across tasks, avoiding metric discontinuities and heuristic hyperparameters.
- Potential outcomes: Regulatory guidance and RFP templates referencing E3; public model cards including E3 across task suites.
- Assumptions/dependencies: Community consensus on baselines, and defaults, and task panels.
- Application: Generalized reasoning-data pipelines with verified CoT
- Sectors: Data Platforms, Research, EdTech
- Vision: Extend the paper’s verified CoT pipeline (premise → formalization → condition evaluation → option mapping + dual human verification) to new domains, languages, and multi-step, multi-hop tasks for transparent training/evaluation.
- Potential products: “Reasoning Dataset Studio” for co-creating verified CoT corpora.
- Assumptions/dependencies: Annotation cost and quality control; domain experts for complex logical tasks.
- Application: Green AI planning tied to E3 and carbon budgets
- Sectors: ESG, Cloud, Sustainability
- Vision: Use E3 in production to enforce carbon/energy budgets while meeting accuracy requirements; automatically shift methods/models to respect real-time carbon constraints.
- Potential products: Carbon-aware inference schedulers; ESG dashboards that trade off tokens vs accuracy in real time.
- Assumptions/dependencies: Access to reliable carbon intensity signals; governance acceptance of dynamic policy changes.
- Application: On-device assistants and robotics with efficient reasoning
- Sectors: Mobile/AR, IoT, Robotics
- Vision: Deploy small or distilled models with method-aware reasoning (e.g., SloT with learned skeletons, or blueprint prompts for routine commonsense decisions) that meet latency and energy constraints on-device.
- Potential products: “Edge Reasoning Packs” optimized per chip; co-designed decoders that exploit skeleton-first decoding efficiently.
- Assumptions/dependencies: Hardware support; compact models with adequate accuracy; robust few-shot structures in the wild.
- Application: Curriculum and safety training for structured reasoning
- Sectors: Education, Safety/Alignment Research
- Vision: Training curricula that teach models to internalize concise but correct reasoning structures (e.g., skeleton-then-expand), with safety checks to prevent overcompression.
- Potential products: Curriculum learning recipes; validation suites that stress-test overthinking vs under-explaining.
- Assumptions/dependencies: High-quality, diverse curricula; reliable safety validators.
- Application: End-to-end agentic systems with reasoning budget markets
- Sectors: Agents, Autonomous Workflows, DevOps
- Vision: Multi-tool agents that “buy” reasoning budget based on task ROI, paying more (CoT/Soft Thinking) for high-impact steps and spending less (blueprints/TokenSkip) for routine sub-tasks, guided by E3.
- Potential products: Budget-aware agent planners; economic controllers using E3 as a utility term.
- Assumptions/dependencies: Accurate task valuation; composable method switching; failure containment.
- Application: Domain-adaptive few-shot augmentation and noise robustness
- Sectors: Enterprise Knowledge Assistants, Support Automation
- Vision: Systems that detect noisy or out-of-domain exemplars and auto-correct (e.g., rewrite or filter demonstrations) to keep methods like SloT stable and prevent blueprint failures across domains.
- Potential products: “DemoGuard” modules; automatic demonstration generation pipelines with verification.
- Assumptions/dependencies: Reliable noise detection; high-quality LLM rewriting; human QA for critical domains.
- Application: Compliance-grade audit trails with concise, validated rationales
- Sectors: Finance, Legal, Healthcare Administration
- Vision: Maintain short, verified reasoning traces that meet auditability requirements without incurring large token overhead, using post-hoc refinement validated against original outputs.
- Potential products: “Rationale Compactor” that retains key steps; dual-pass “generate → compress → verify” pipelines.
- Assumptions/dependencies: Organizational acceptance of compressed rationales; verifiers that catch compression-induced errors.
- Application: AutoML-for-reasoning efficiency
- Sectors: ML Platforms, Research Ops
- Vision: Automated search over methods, backbones, prompts, and shot counts to maximize E3 under constraints, with per-domain deployment bundles.
- Potential products: “AutoEffiReason” service; one-click per-dataset optimization recipes.
- Assumptions/dependencies: Compute for search; representative validation sets; safe stopping rules to avoid overfitting.
Notes on Assumptions and Dependencies Across Applications
- E3-Score requires choosing a baseline (commonly standard CoT); can be set to baseline accuracy and as recommended to emphasize accuracy near strong baselines.
- Some methods are train-free (CoD, SoT, SloT, TokenSkip under post-hoc, Soft Thinking variants) and easier to adopt; others (O1-Pruner) require fine-tuning and can face memory limits at large scales.
- Method performance is sensitive to backbone family and domain (e.g., TokenSkip works well on LLaMA for commonsense/logic but fails on Qwen for hard math).
- Few-shot performance depends on exemplar quality and domain match; blueprint methods (CoD/SoT) are brittle to noise and cross-domain transfer; SloT benefits from more shots and curated demonstrations.
- Verified CoT datasets enable transparent reasoning evaluation but need licensing compliance and careful use to avoid overfitting to templates.
- Safety-critical deployments should prioritize accuracy-preserving methods and include human oversight and verification passes.
Glossary
- Accuracy per Computation Unit (ACU): A metric that normalizes accuracy by computational cost to compare methods’ efficiency. "ACU linearly scales accuracy by computation, undervaluing small but crucial improvements in high-accuracy regimes."
- Accuracy–Efficiency Score (AES): A combined metric for accuracy and efficiency that uses a piecewise formulation with heuristics. "AES considers relative gains in accuracy and tokens, but it is piecewise and relies on heuristic hyperparameters, leading to instability."
- Agentic tasks: Settings where models act autonomously to pursue goals, often exhibiting different reasoning behavior. "the tendency to overthink in agentic tasks"
- Chain-of-Draft (CoD): A prompting strategy that constrains intermediate steps to short drafts to limit verbosity. "Chain-of-Draft employs prompt instructions that restrict intermediate steps to very short drafts, explicitly constraining verbosity."
- Chain-of-Thought (CoT): A prompting paradigm where models generate explicit step-by-step reasoning. "LLMs with Chain-of-Thought (CoT) prompting achieve strong reasoning"
- CommonsenseQA: A multiple-choice benchmark for everyday commonsense reasoning. "CommonsenseQA~\cite{talmor2018commonsenseqa}, a multiple-choice dataset evaluating everyday commonsense reasoning;"
- Constant Elasticity of Substitution (CES): An economic model used to aggregate trade-offs with a controllable degree of substitutability. "inspired by the Constant Elasticity of Substitution (CES) formulation~\cite{mcfadden1963constant}"
- Cross-backbone: Evaluation or comparison across different underlying model architectures. "cross-paradigm, cross-backbone, and cross-domain assessment."
- Cross-domain: Transfer or evaluation across different task domains. "cross-paradigm, cross-backbone, and cross-domain assessment."
- Cross-paradigm: Comparison across distinct methodological categories or approaches. "rigorous cross-paradigm evaluation"
- Decoding: The token-generation process during inference, which can be restructured for efficiency. "restructuring decoding with intermediate skeletons"
- Deductive reasoning: Logical reasoning that derives conclusions from given premises. "requiring conditional and deductive reasoning."
- Dynamic Execution: A class of methods that adjust the reasoning process during generation/inference. "Reasoning Blueprints, Dynamic Execution, and Post-hoc Refinement."
- E3-Score (Efficiency–Effectiveness Equilibrium Score): A smooth metric combining accuracy and efficiency inspired by CES trade-off modeling. "we further propose the E-Score (EfficiencyâEffectiveness Equilibrium Score), a smooth and stable metric inspired by economic trade-off modeling."
- Efficiency–Effectiveness trade-off: The balance between achieving high accuracy and using fewer computational resources/tokens. "existing metrics measuring the efficiencyâeffectiveness trade-off, suffer from discontinuities and heuristic dependencies"
- Few-shot: A setting where models are given a small number of examples to guide reasoning. "Few-shot analysis is reported only when explicitly stated."
- GSM8K: A math word problem dataset focused on multi-step arithmetic at grade-school level. "GSM8K~\cite{cobbe2021training}, a collection of grade school math word problems requiring multi-step arithmetic;"
- Harmonic mean: A mean used to conservatively aggregate accuracy and efficiency in the E3-Score. "We adopt (a weighted harmonic mean) as the default"
- Inference-time search strategies: Techniques that explore alternative reasoning paths during generation to improve outcomes. "Sys2Bench~\cite{parashar2025inference} provides systematic evaluation for inference-time search strategies"
- Latent space: A continuous internal representation space where reasoning can be performed more compactly. "reasoning in latent space"
- LogiQA: A logical reasoning benchmark derived from national logic exams. "LogiQA~\cite{liu2020logiqa}, a benchmark derived from national logic examinations requiring conditional and deductive reasoning."
- Option-wise analysis: A requirement to analyze all multiple-choice options to justify both the correct and incorrect answers. "comprehensive option-wise analysis"
- Out-of-memory (OOM): A failure mode when model training or inference exceeds available memory. "“OOM" is the abbreviation for out-of-memory"
- Post-hoc refinement: Methods that compress or prune reasoning after it has been generated. "A third category, post-hoc refinement, operates after generation, pruning, or compressing verbose outputs"
- Pruning: Removing tokens or steps deemed unnecessary to reduce cost while aiming to preserve correctness. "pruning, or compressing verbose outputs"
- Quantization: Reducing numerical precision of model parameters to compress models or speed up inference. "quantization and pruning~\cite{zhang2025reasoning,liu2025quantization}"
- Reasoning blueprints: Pre-inference guidance mechanisms (prompts or training) that shape how a model reasons. "serving as reasoning blueprints that guide the LLM through reinforcement learning with length-aware rewards"
- Router: A component that directs inputs to appropriate high-level reasoning patterns. "introduces a lightweight router that maps inputs to high-level reasoning patterns (âsketchesâ)"
- Skeleton-of-Thought (SloT): A two-stage decoding approach that first produces an outline, then expands details. "Skeleton-of-Thought (SloT) restructures decoding into a two-stage process: first generating a high-level outline (skeleton) and then expanding details for each component, potentially reducing redundancy through parallel generation."
- Sketch-of-Thought (SoT): A method that guides models using compressed high-level reasoning templates or “sketches.” "Sketch-of-Thought (SoT) introduces a lightweight router that maps inputs to high-level reasoning patterns (âsketchesâ), guiding the model to follow compressed reasoning templates."
- Soft Thinking: A continuous-space reasoning method that uses concept tokens (mixtures of embeddings). "Soft Thinking enables reasoning in a continuous space by generating âconcept tokens,â which represent probability-weighted mixtures of token embeddings."
- Standardized reasoning structures: A predefined multi-stage schema enforced during CoT annotation. "standardized reasoning structures, comprehensive option-wise analysis, and human verification."
- Substitutability: The degree to which accuracy and efficiency can replace each other in a trade-off model. "model trade-offs with controlled substitutability."
- TokenSkip: A post-processing approach that removes low-contribution tokens from reasoning chains. "TokenSkip operates on completed reasoning chains by removing tokens with low semantic contribution to the final answer, producing shorter rationales."
- Train-based setting: An evaluation regime where models are trained on data before inference. "In the Train-based setting, models are first trained on the full training set and then evaluated by inference."
- Train-Free setting: An evaluation regime with direct inference and no parameter updates. "In the Train-Free setting, models perform direct inference without any parameter updates."
Collections
Sign up for free to add this paper to one or more collections.

