- The paper introduces the ACT pipeline, which uses MLLMs for initial annotation and error criticism to minimize human effort.
- It employs strategies like normalization and exponential weighting to optimize annotation quality, measured by AQG and ABS metrics.
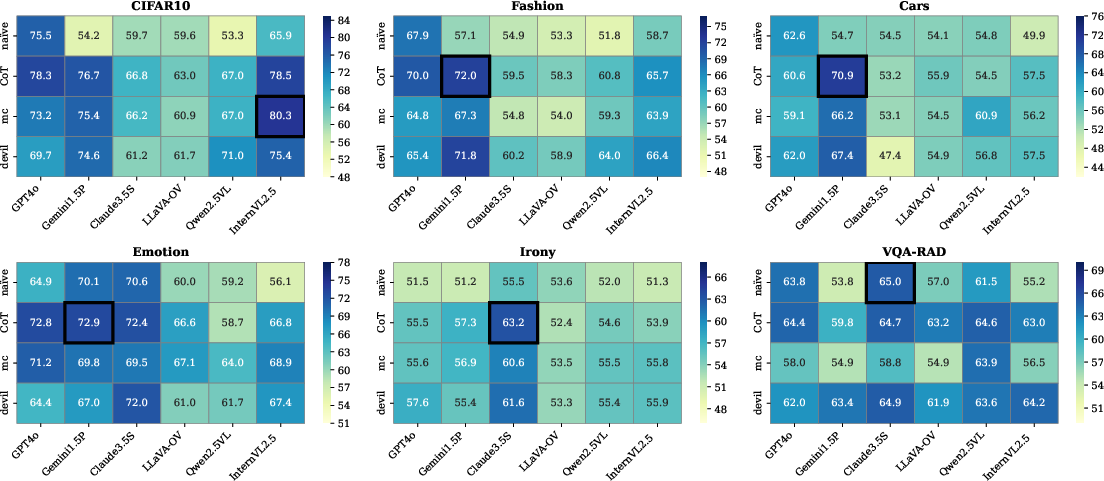
- Experimental results show that black-box strategies and CoT criticism enhance performance, enabling efficient downstream training.
Overview of the Paper "ACT as Human: Multimodal LLM Data Annotation with Critical Thinking"
This paper introduces the Annotation with Critical Thinking (ACT) data pipeline to enhance the efficiency and quality of data annotation using Multimodal LLMs (MLLMs). ACT leverages the capabilities of MLLMs both as annotators and critics, reducing the human effort needed to achieve high-quality annotations by concentrating on suspicious cases. By distributing human tasks effectively, ACT aims to strike a balance between cost efficiency and label accuracy.
Method and Implementation Details
ACT Data Pipeline
The paper outlines three phases in the ACT data pipeline:
- Annotation: MLLMs are used to generate initial annotations across diverse domains such as NLP, CV, and multimodal scenarios. The approach employs MLLMs due to their ability to understand and process various data types simultaneously.
- Error Estimation: To identify potential labeling errors, the pipeline uses another MLLM as a criticizer. This component estimates the likelihood of annotation errors, enabling more targeted human intervention.
- Correction: Based on the error estimations, data samples that exhibit high likelihoods of error are selected for human review, within the constraints of a predefined human budget.
The processing of selecting data samples for human correction utilizes several strategies such as normalization, exponential weighting, and thresholding, each aimed at optimizing the utilization of a limited human budget.
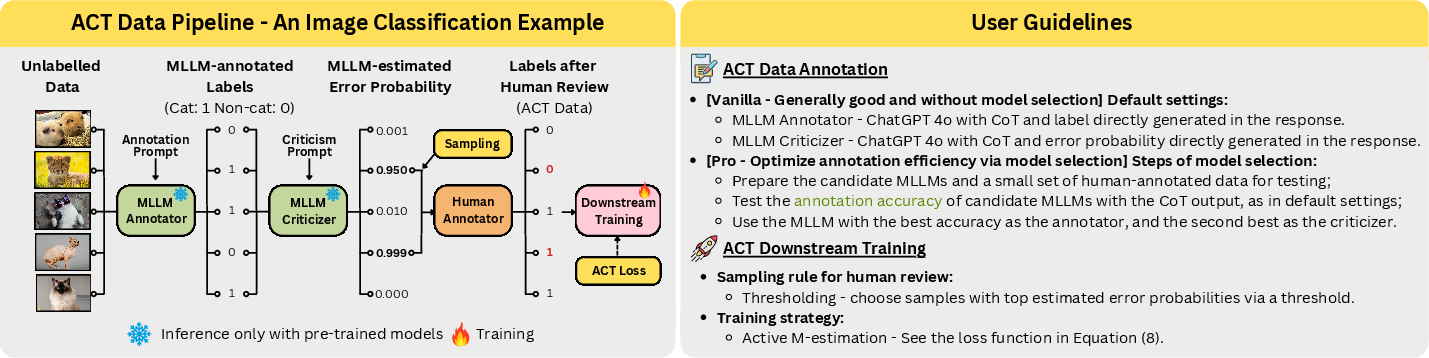
Figure 1: Illustration of the ACT data pipeline (left) and the user guidelines (right).
Evaluation Metrics
To evaluate the effectiveness of ACT, two key metrics are introduced:
- Annotation Quality Gain (AQG): Measures the improvement in annotation quality achieved by ACT compared to machine-only annotations.
- Area under Budget Sensitivity (ABS): Gauges the efficiency of human budget utilization, with higher values indicating better performance and cost-effectiveness.
Experimental Results
The experiments conducted demonstrated that the ACT data pipeline could efficiently reduce the human effort needed while maintaining high annotation quality. Different prompt strategies and model types were tested, revealing insights into optimizing the annotation and criticism processes. Specifically, experimentation showed:
Downstream Training
The paper further analyzes how modified loss functions can enhance downstream training when using ACT data. Notably, active M-estimation methods were applied to adjust the training loss to ensure models trained on ACT data parallel the performance of those trained on fully human-annotated data.
Implications and Future Directions
Theoretical and Practical Implications
The ACT data pipeline offers a promising approach to reducing annotation costs significantly while retaining label quality. By deploying MLLMs both for annotation and in a critical thinking role, ACT allows human resources to be focused on verifying examples most likely to contain errors.
Future Developments
The paper suggests several directions for future research, including the potential application of ACT to more complex tasks beyond classification, such as summarization and open-ended question answering. These would involve extending the criticizer role to evaluate outputs more comprehensively, focusing on coherence and factual accuracy.
Conclusion
The ACT data pipeline is a robust approach toward efficient and high-quality data annotation, leveraging the judgment capabilities of modern MLLMs. By strategically utilizing human resources, it substantially lowers the cost and effort associated with traditional annotation methods, without compromising on accuracy or reliability. As MLLMs continue to evolve, the capabilities and applications of ACT are expected to expand, offering more sophisticated solutions to the challenges of data annotation in diverse domains.