Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising
Abstract: Diffusion-based video generation can create realistic videos, yet existing image- and text-based conditioning fails to offer precise motion control. Prior methods for motion-conditioned synthesis typically require model-specific fine-tuning, which is computationally expensive and restrictive. We introduce Time-to-Move (TTM), a training-free, plug-and-play framework for motion- and appearance-controlled video generation with image-to-video (I2V) diffusion models. Our key insight is to use crude reference animations obtained through user-friendly manipulations such as cut-and-drag or depth-based reprojection. Motivated by SDEdit's use of coarse layout cues for image editing, we treat the crude animations as coarse motion cues and adapt the mechanism to the video domain. We preserve appearance with image conditioning and introduce dual-clock denoising, a region-dependent strategy that enforces strong alignment in motion-specified regions while allowing flexibility elsewhere, balancing fidelity to user intent with natural dynamics. This lightweight modification of the sampling process incurs no additional training or runtime cost and is compatible with any backbone. Extensive experiments on object and camera motion benchmarks show that TTM matches or exceeds existing training-based baselines in realism and motion control. Beyond this, TTM introduces a unique capability: precise appearance control through pixel-level conditioning, exceeding the limits of text-only prompting. Visit our project page for video examples and code: https://time-to-move.github.io/.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Time‑to‑Move: Training‑Free Motion‑Controlled Video Generation via Dual‑Clock Denoising”
Overview
This paper introduces a way to make AI‑generated videos move exactly how you want—without retraining any big models. The method, called Time‑to‑Move (TTM), lets you choose what in a picture should move, where it should go, and even how it should look as it moves. It works with existing image‑to‑video models and needs no extra training or special hardware.
Key Objectives
The researchers wanted to:
- Give users precise control over motion: decide which object moves, and along what path.
- Keep the original look (appearance) from the first image frame, so characters and backgrounds don’t morph or lose identity.
- Work “plug‑and‑play” with many existing video generators (no model fine‑tuning).
- Allow control of appearance too (like changing color or adding an accessory) while the object moves.
How It Works (In Everyday Terms)
First, a quick bit of background:
- A “diffusion model” makes images or videos by starting from noisy pixels (like TV static) and gradually “denoising” them into a clear picture. Think of it like cleaning a very dusty photo until the details appear.
- “Image‑to‑video (I2V)” models take one image and generate a short video that looks like that image moving.
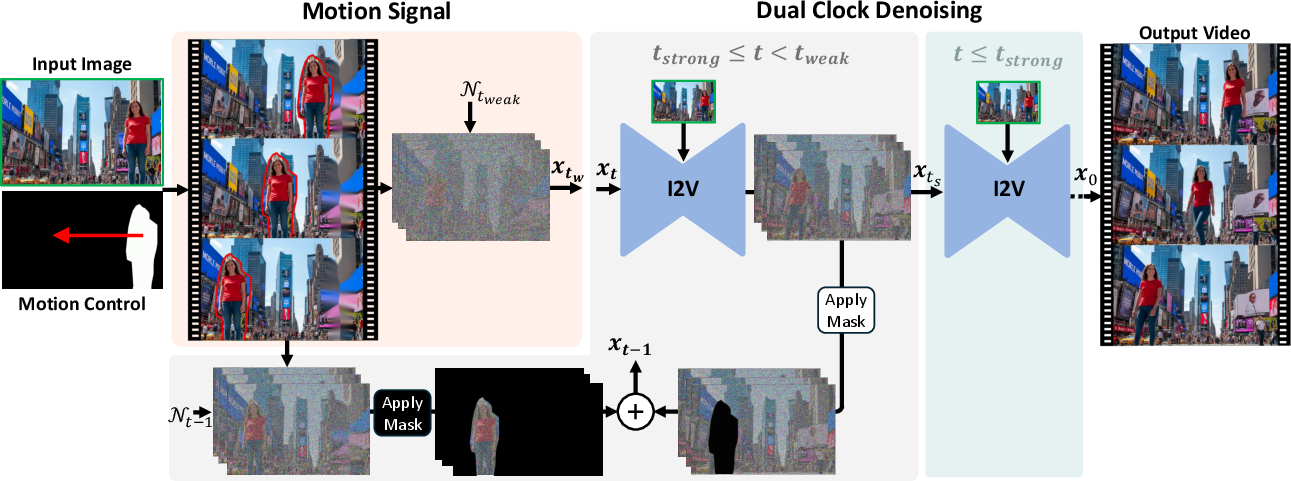
TTM adds three ideas on top of these:
- Make a rough “reference animation”
- You start with one image and create a very simple animation of what you want to happen. For example:
- “Cut‑and‑drag”: draw a mask over an object (like a boat), then drag it along the path you want.
- “Depth reprojection” for camera moves: estimate how far things are in the image (depth), then simulate the camera moving (like panning or rotating) to make a rough sequence.
- This rough animation looks fake—there may be holes or stretched areas—but it captures the big idea: what moves and where.
- You start with one image and create a very simple animation of what you want to happen. For example:
- Adapt SDEdit to videos
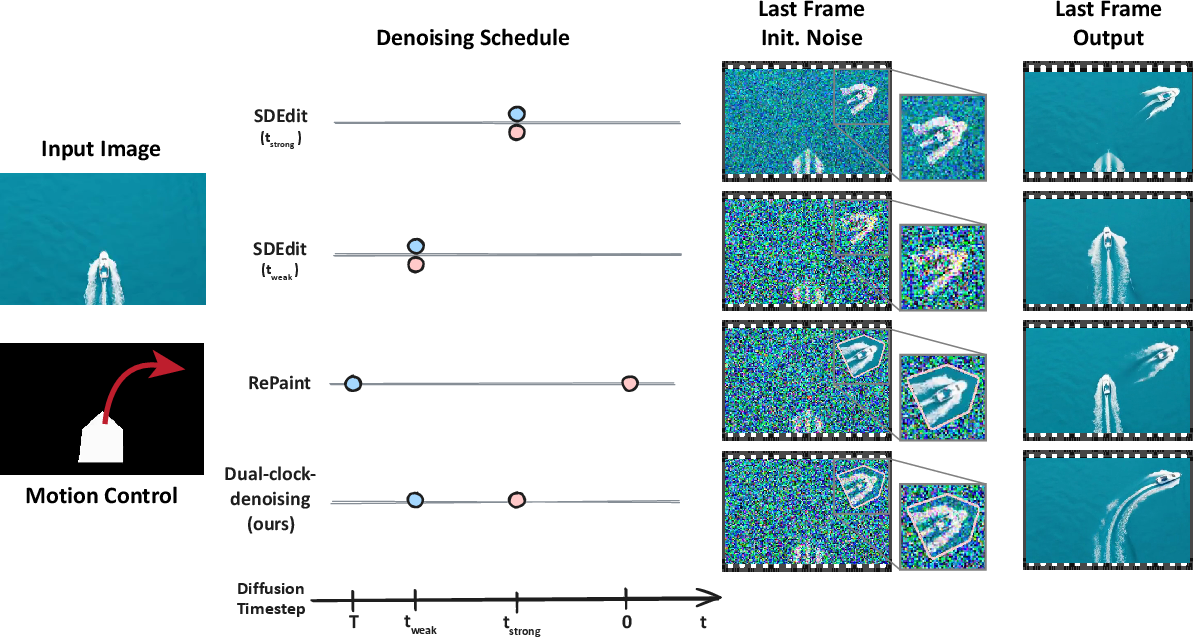
- SDEdit is a trick for images where you add noise to a rough edit and then let the diffusion model clean it up, keeping the big structure while fixing details.
- TTM does this for videos: it adds the “right amount” of noise to the rough animation so the model adopts the intended motion, then denoises it back into a realistic video.
- To keep the original look (so faces, colors, and styles don’t drift), TTM also feeds the clean first image frame into the model. This anchors the appearance across all frames.
- Dual‑clock denoising (the key innovation)
- Problem: different parts of the video need different levels of control. The object you dragged should follow the motion exactly, but the background should be free to adjust naturally (waves behind a moving boat should change, not freeze).
- Solution: use two “noise clocks” (two starting noise levels) at the same time:
- Inside the user’s mask (the controlled object): start with less noise to strongly align with the rough animation.
- Outside the mask (background): start with more noise to allow natural changes and avoid stiff or frozen areas.
- During denoising, the method keeps injecting the controlled object’s guidance until both regions “meet” and finish denoising together. This makes motion accurate where it’s specified and realistic everywhere else.
In short: you give the model a rough plan (the reference video), tell it which parts to follow strictly (the mask), and TTM uses two noise schedules (the “dual clocks”) to balance control and realism—no training required.
Main Findings and Why They Matter
The team tested TTM on two big tasks:
- Object motion control (moving a specific thing):
- TTM made objects follow their intended paths more accurately than many baselines, including ones that need training.
- It kept the subject’s look consistent and avoided unwanted background motion (like accidental camera panning).
- Visual quality stayed high, with fewer artifacts or weird distortions.
- Camera motion control (moving the viewpoint):
- Using depth to create rough camera moves, TTM produced videos that matched the target camera path better than prior methods, with lower error and more consistent motion over time.
- It removed holes and tearing that often appear in simple depth warps, making the final result smooth and realistic.
- Appearance control (beyond text prompts):
- Because TTM conditions on full frames (not just motion paths), you can control pixel‑level appearance while moving—like changing a chameleon’s color as it slides along a line, or adding a hat to a person so it appears in both the scene and the mirror reflection.
- This is more precise than relying on text prompts alone, which can be vague or inconsistent.
- Works across multiple models:
- TTM plugged into different image‑to‑video backbones (like SVD, CogVideoX, and WAN 2.2) without retraining.
- It runs as fast as normal sampling—no extra compute cost.
Why this is important:
- It gives creators a simple, interactive way to direct motion and appearance, which is useful for animation prototyping, post‑production, education, and social content.
- It avoids costly model fine‑tuning, saving time and energy.
- It brings motion control closer to “what you see is what you get,” rather than hoping a text prompt matches your intention.
Implications, Limitations, and Future Ideas
Implications:
- TTM makes motion‑controlled video generation more practical and accessible. You can quickly try ideas and get clean results without editing complicated model code or running long training jobs.
- It could power user interfaces where you sketch motion or camera paths, nudge objects around, and directly see polished video outputs.
Limitations (honest notes from the paper):
- You may need to tune the two noise levels (the “dual clocks”) for best results, which can take a bit of trial and error.
- TTM preserves identity from the first frame; brand‑new objects appearing later aren’t as strongly anchored.
- It currently works best when you can provide a decent mask for the moving object.
Future ideas:
- More regions and softer masks (not just a single binary mask), smoother schedules, and richer appearance edits (like stylistic changes).
- Better support for complex articulated motion (like walking or dancing) and longer videos.
Overall, Time‑to‑Move is a practical, training‑free toolkit that lets you control both how things move and how they look in AI‑generated videos—accurately, quickly, and across many existing models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete opportunities for future work highlighted or implied by the paper.
- Automatic schedule selection: The dual-clock requires manual tuning of and . Develop principled, data-driven or adaptive methods to automatically set and adjust region-specific timesteps based on motion magnitude, uncertainty, or mask confidence.
- Multi-region and soft-mask control: Extend dual-clock denoising to more than two regions with continuous or soft masks, including spatially and temporally smooth noise schedules that avoid abrupt transitions.
- Boundary artifacts: Analyze and mitigate seams or inconsistencies at mask boundaries introduced by heterogeneous noise levels; explore boundary-aware blending, learned mask feathering, or cross-region consistency losses (at inference or via post-processing).
- Occlusions and disocclusions: The warped reference uses nearest-neighbor hole filling, which is crude. Quantify failure modes and incorporate more advanced, geometry- or diffusion-aware inpainting to better handle newly revealed areas and occlusions.
- Depth and warping sensitivity: Systematically evaluate and model sensitivity to errors in monocular depth and warping, including large parallax, thin structures, specular surfaces, and depth discontinuities; propose robustness strategies (e.g., uncertainty-aware masks, multi-view priors).
- Objects entering later frames: Identity preservation is restricted to content visible in the first frame. Investigate training-free ways to anchor new objects (e.g., on-the-fly appearance injection, reference patches, or iterative conditioning) without fine-tuning.
- Beyond I2V backbones: The approach relies on first-frame image conditioning. Explore extensions to text-to-video or video diffusion models without explicit image conditioning (e.g., via reference-frame tokens, adapter-free feature grafting, or self-attention key/value anchoring).
- Large motion and non-rigid deformations: Provide a systematic stress test for extreme displacements, rotations, scale changes, and articulated/non-rigid motion; characterize breakdown thresholds and propose motion-adaptive schedules or hierarchical control.
- Partial and weak user inputs: The method requires full object masks. Develop training-free mechanisms to operate from scribbles, points, or loose boxes, including automatic mask completion/tracking and confidence-weighted conditioning.
- Camera motion in dynamic scenes: Camera-control experiments use static scenes. Evaluate performance when background contains moving actors or dynamic elements, disentangling camera vs. scene motion and preventing unintended co-motion.
- Appearance control benchmarking: Introduce quantitative metrics and datasets for motion-conditioned appearance edits (color/style changes, insertions, shape deformations) to enable rigorous comparison beyond qualitative demos.
- Theoretical grounding: Provide analysis linking denoising noise levels to motion adherence vs. realism trade-offs in video diffusion; formalize when heterogeneous schedules improve alignment and how they interact with temporal attention.
- Long-horizon generation: Assess stability and identity drift over longer sequences (hundreds of frames), including schedule annealing strategies, periodic re-anchoring to updated references, or memory mechanisms.
- Efficiency at scale: While sampling is claimed to match standard generation, quantify compute/memory overhead across resolutions, frame counts, and backbones, and profile latency in interactive settings.
- Combining controls: Explore synergy with attention-based or trajectory-token controls (e.g., integrating dual-clock with FreeTraj/PEEKABOO-style attention gating) to gain finer control without fine-tuning.
- Geometry-aware conditioning: Investigate 3D-aware variants (e.g., neural radiance fields or Gaussian splats) to produce better camera-motion realism and consistent parallax beyond monocular depth warping.
- Improved hole-filling priors: Replace nearest-neighbor inpainting with diffusion-based or learned priors conditioned on scene semantics, depth, and motion to reduce tearing and fill complex disocclusions.
- Generalization across architectures: Validate robustness on more diverse I2V/T2V backbones (e.g., different latent spaces, tokenization schemes, or discrete variational codecs) and identify architecture-dependent schedule tuning guidelines.
- Interactive editing loops: Study stability under iterative user edits (drag, recolor, re-mask) and propose mechanisms for incremental updates (e.g., latent caching or localized resampling) with consistent temporal propagation.
- Domain coverage: Broaden evaluation beyond MC-Bench and DL3DV to include human motion, transparent or reflective materials, crowded scenes, and stylized content; report domain-wise failure cases.
- Parameterization guidance: Provide practical default schedules per backbone/resolution and rules-of-thumb tied to motion magnitude or mask area; expose schedule search strategies that remain training-free.
- Human studies: Complement automated metrics with perceptual user studies on motion fidelity, temporal coherence, and appearance faithfulness under varied control tasks.
- Text–reference interplay: Analyze how text prompts interact with pixel-level conditioning (e.g., conflicts between textual style cues and reference appearance); propose resolution strategies or weighting schemes.
- Zoom and intrinsics: Camera-control experiments focus on extrinsics; evaluate changes in camera intrinsics (zoom/focal length) and lens effects, and adapt depth-based warping and masks accordingly.
- Flow metric reliability: RAFT-based optical flow is used for motion evaluation; assess robustness in low-texture or high-motion regimes and consider alternative motion-grounding metrics or 3D reprojection errors.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented now using TTM’s training-free, plug-and-play motion and appearance control for image-to-video (I2V) diffusion models.
- Media & Entertainment — Fine-grained motion tweaks in post-production
- Use case: Precisely reposition and animate on-screen objects (e.g., move a prop, adjust a character’s hand, animate a logo) while preserving the first-frame appearance.
- Tools/products/workflows: After Effects/Nuke/Premiere plugin that adds a “motion brush” (mask selection + trajectory drawing), backed by TTM; supports dual-clock region control for artifact-free foreground motion and natural background dynamics.
- Assumptions/dependencies: Access to a capable I2V backbone (e.g., SVD, CogVideoX, WAN 2.2), GPU/accelerator, reliable object masks; tuning of t_strong/t_weak; identity anchoring limited to content visible in the first frame.
- Animation & Game Previs — Rapid motion blocking from concept art
- Use case: Block out object trajectories and camera moves from a single frame to explore timing, staging, and continuity before full production.
- Tools/products/workflows: Blender/Maya add-on that lets artists cut-and-drag regions and sketch camera paths; TTM samples realistic motion with image anchoring for consistent look.
- Assumptions/dependencies: Monocular depth for camera motion; not physically accurate for final shots; mask quality affects control fidelity.
- Advertising & E-commerce — Product motion and appearance demos from a single photo
- Use case: Animate a product to slide/rotate, change color or finish over time, or create parallax B-roll shots from a catalog image.
- Tools/products/workflows: Web app/SDK for marketers: upload image → select product mask → draw trajectory → optional color ramp → generate short videos.
- Assumptions/dependencies: Legal rights to modify assets; monocular depth quality influences camera-motion parallax; accuracy of appearance edits depends on pixel-level conditioning.
- Social Media & Creator Tools — “Cut-and-drag” photo animations
- Use case: Consumer-friendly interactive animation of personal photos (e.g., move a subject, animate stickers, synchronize motion with music), with appearance tweaks.
- Tools/products/workflows: Mobile app with cloud inference; simple mask-and-trajectory UI; presets for motion strength (dual-clock presets).
- Assumptions/dependencies: Inference speed and cost; model safety guardrails to prevent misuse (e.g., deepfakes).
- Education — Motion visualization with appearance control
- Use case: Demonstrate motion trajectories, transforms, or cause-effect sequences (e.g., physics, geometry) by animating annotated diagrams while safely changing visual attributes.
- Tools/products/workflows: Interactive whiteboard plugin: draw paths on objects; TTM controls appearance and motion jointly to match lesson scripts.
- Assumptions/dependencies: Reliable masking for diagrams; clarity of edits; appropriate content policies in classrooms.
- Camera Motion from a Single Image — Parallax B-roll and smooth pans/tilts
- Use case: Generate camera moves (pan, tilt, dolly, orbit) from a single still using depth-guided reference warps; useful for b-roll, slideshows, and explainer videos.
- Tools/products/workflows: DepthPro-integrated pipeline: estimate depth → back-project → reproject along user path → TTM dual-clock denoising; export stabilized clips.
- Assumptions/dependencies: Depth estimation quality (holes/tearing need simple inpainting); long motions may require careful path planning and t_strong/t_weak tuning.
- Robotics & Drones (Research) — Quick camera-motion sequences for algorithm prototyping
- Use case: Approximate camera trajectories over static scenes for testing visual pipelines (tracking, stabilization, SLAM pre-tests).
- Tools/products/workflows: Scripted augmentation tool: define camera paths over dataset stills to produce controlled motion clips via TTM.
- Assumptions/dependencies: Videos are synthetic approximations, not physically faithful; use only for qualitative prototyping or ablation, not for final performance claims.
- Academic Data Augmentation — Motion-controlled video variants
- Use case: Create controlled motion datasets for benchmarking tracking or appearance consistency; generate paired sequences with varied trajectories and dual-clock masks.
- Tools/products/workflows: Reproducible augmentation scripts; parameter sweeps over motion adherence vs. realism; benchmark creation.
- Assumptions/dependencies: Distribution shift and label fidelity must be audited; ensure that synthetic videos are clearly marked and separated in training/evaluation.
- UI/UX Design — Micro-animations from static screens
- Use case: Animate individual elements (buttons, cards, icons) with trajectory control to preview micro-interactions from static mockups.
- Tools/products/workflows: Figma/Sketch plugin: select element mask → draw motion path → export short loops; pixel-level color or style edits over time.
- Assumptions/dependencies: High-res asset masks; short-duration loops preferred; non-physical motion is acceptable for previews.
- Creative Arts — Joint motion + style edits on illustration frames
- Use case: Move parts of illustrations while shifting color palettes or textures per frame, enabling hybrid motion-design workflows.
- Tools/products/workflows: Procreate/Krita integration; timeline with dual-clock mask regions; appearance ramps synchronized with motion.
- Assumptions/dependencies: Artistic control depends on mask quality; style generalization requires careful conditioning; long sequences may drift.
Long-Term Applications
These use cases require further research, scaling, or development (e.g., longer-horizon stability, better region scheduling, real-time performance, policy frameworks).
- Production-grade Motion Editor — Multi-region soft masks and physics-aware control
- Sector: Media/Entertainment, Software
- Description: A full motion editor where multiple objects have distinct dual-clock schedules, soft masks, and physically informed constraints.
- Dependencies: Research into multi-region scheduling, soft masks, smoother noise schedules; integration with DCC tools; robust UI tooling.
- Real-time Motion-Controlled Generation — Interactive games/VR
- Sector: Gaming, XR
- Description: Stream TTM-like control at interactive frame rates for in-engine cinematics or virtual production.
- Dependencies: Model compression/quantization, GPU acceleration, caching; API/engine integration; latency management.
- Previsualization & Cinematography Planning from Stills
- Sector: Film/TV production
- Description: Director tools to plan complex camera paths, blocking, and composition from concept art or scout photos, with export to shot lists.
- Dependencies: Long-horizon stability, camera path optimization, integration with previsualization pipelines.
- Synthetic Data at Scale for Autonomy
- Sector: Autonomous Driving, Robotics
- Description: Generate controlled camera and object motion from stills at scale to probe model robustness.
- Dependencies: Validation of realism and domain gap; policy and ethical safeguards; metadata/watermarking indicating synthetic origin.
- E-commerce 360° and Try-on from Single Images
- Sector: Retail/E-commerce
- Description: Derive quasi-3D product spins and colorway transitions from one image to reduce photography costs.
- Dependencies: Improved geometry priors and view synthesis; consistency over long trajectories; user trust and disclosure.
- Healthcare & Training Animations
- Sector: Healthcare Education
- Description: Animate surgical diagrams or medical illustrations with motion + appearance control to teach procedures.
- Dependencies: Expert verification; medical accuracy; safeguards against misleading visuals.
- Region-Adaptive Denoising as a General Editing Primitive
- Sector: Software (Imaging), Research
- Description: Extend dual-clock denoising to image/video inpainting, compositing, and restoration (heterogeneous noise schedules per region).
- Dependencies: Broader empirical validation; standard APIs for region schedules; UI metaphors for “adherence vs. freedom.”
- Content Authenticity, Watermarking, and Policy Standards
- Sector: Policy/Compliance
- Description: Establish provenance signals and usage guidelines for motion-conditioned generative videos; detection tools for dual-clock edits.
- Dependencies: Industry adoption of watermark standards; coordination with content platforms; regulatory buy-in.
- Collaborative Cloud Platforms for Non-experts
- Sector: SaaS/Creative Collaboration
- Description: Multi-user, web-based authoring (shared masks, paths, appearance ramps) with versioning and review workflows.
- Dependencies: Scalable inference; cost controls; access control; robust UX for mask/path editing.
- Long-Horizon, High-Resolution Production Pipelines
- Sector: Media/Entertainment
- Description: Stable minutes-long sequences with consistent identity and intricate motion/appearance control at 4K+ resolution.
- Dependencies: Memory and compute scaling; schedule tuning automation; model improvements for temporal coherence and identity retention across long durations.
Glossary
- Any Trajectory Instruction (ATI): A method for controllable video generation that encodes user-specified point tracks into features guiding motion synthesis. "ATI encodes point tracks as Gaussian-weighted latent features"
- Asynchronous denoising: A diffusion strategy where different parts or tokens are denoised at different rates or noise levels. "Asynchronous denoising has been explored in several contexts."
- BG–Obj CTD: A metric variant of CoTracker Distance that measures unintended co-motion between background and object regions. "BGâObj CTD to detect unintended background co-motion."
- CLIP: A vision-language embedding model used here to assess temporal consistency via frame-to-frame similarity. "average CLIP~\citep{radford2021learning} cosine similarity"
- CoTracker Distance (CTD): A trajectory-based metric that quantifies adherence of generated motion to target object tracks. "CoTracker Distance (CTD)"
- ControlNet: An auxiliary conditioning branch for diffusion models that injects structured controls (e.g., trajectories) into generation. "ControlNet-style branch"
- Depth-based reprojection: Creating a synthetic multi-view sequence by reprojecting an image into new views using estimated depth. "cut-and-drag or depth-based reprojection."
- DepthPro: A monocular metric depth estimator used to construct 3D-aware camera-motion references. "metric depth with DepthPro~\citep{Bochkovskii2024:arxiv}"
- Diffusion blending: Mixing denoised predictions with noised references during sampling to enforce constraints without retraining. "diffusion blending strategy akin to~\citep{avrahami2022blended,lugmayr2022repaint}"
- Diffusion Forcing (DF): A technique that assigns per-token noise levels to introduce temporal heterogeneity in diffusion models. "Diffusion Forcing (DF) introduces temporal heterogeneity"
- Diffusion Transformer: A transformer-based diffusion backbone architecture for video generation. "Diffusion Transformer, 5B parameters"
- Dual-clock denoising: A region-dependent denoising scheme that applies different noise levels to masked and unmasked areas to balance control and realism. "introduce dual-clock denoising, a region-dependent strategy"
- FFT: Fast Fourier Transform; used here to re-inject high-frequency detail in video frames. "via an FFT."
- Forward warping: Mapping pixels from the source frame to target frames using a displacement field to produce a warped video. "The warped video is obtained by forward warping "
- Gated self-attention: A mechanism that modulates attention with gates to control how motion or layout cues influence generation. "using gated self-attention for layout-conditioned control"
- Go-with-the-Flow (GWTF): A motion-control method that aligns diffusion noise to target motion via warping. "Go-with-the-Flow (GWTF) warps diffusion noise to align with the intended motion."
- Heterogeneous denoising: Performing denoising with spatially varying noise levels or schedules across an image or video. "Our method heterogeneously denoises the entire image"
- Image-conditioned video diffusion model: A video diffusion model that conditions on a clean input image to preserve appearance across frames. "we instead opt for an image-conditioned video diffusion model"
- Image-to-video (I2V): Generative models that produce videos conditioned on a single input image. "image-to-video (I2V) diffusion models."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method used to inject new controls or capabilities. "parameter-efficient LoRA modules that decouple camera and object motion"
- Metric depth: Depth values in real-world units, enabling accurate geometric reprojection across views. "estimate metric depth with DepthPro"
- Monocular depth: Depth estimated from a single image, used to synthesize camera motion via reprojection. "estimated monocular depth"
- Noise warping: Transforming diffusion noise fields to encourage a specific motion or alignment during sampling. "relies on noise warping for scene consistency"
- Optical flow: A dense field of pixel-wise motion vectors between frames used as motion supervision or evaluation. "optical flow or point-trajectories"
- Point cloud: A set of 3D points reconstructed from an image and depth, used for view reprojection. "back-project to a 3D point cloud"
- RAFT: A state-of-the-art optical flow estimator employed to evaluate motion consistency. "RAFT-estimated optical flows"
- RePaint: A training-free diffusion inpainting method that alternates re-noising and masked denoising. "RePaint \citep{lugmayr2022repaint} is also training-free"
- Reverse process: The denoising sequence in diffusion models that iteratively removes noise to generate samples. "starting the reverse process directly from the noisy input"
- SDEdit: A guided editing approach that injects coarse structure by noising an edited input and denoising. "SDEdit employs a single noising timestep to corrupt the reference signal before denoising."
- Spatial self-attention: Attention computed within frames to enforce spatial consistency or propagate constraints. "spatial self-attention keys/values"
- Spatio-temporal attention: Joint attention over space and time to control or modulate motion across video frames. "masked spatio-temporal attention"
- Temporal coherence: Consistency of content and motion over time in generated videos. "achieving high visual quality and temporal coherence"
- U-Net: A convolutional encoder–decoder backbone with skip connections commonly used in diffusion models. "trajectory maps in U-Net blocks"
- VBench: A reference-free benchmarking suite for assessing video generation quality across multiple dimensions. "we adopt VBench~\citep{huang2024vbench}, a reference-free suite of automated video metrics."
Collections
Sign up for free to add this paper to one or more collections.