Thinker: Training LLMs in Hierarchical Thinking for Deep Search via Multi-Turn Interaction
Abstract: Efficient retrieval of external knowledge bases and web pages is crucial for enhancing the reasoning abilities of LLMs. Previous works on training LLMs to leverage external retrievers for solving complex problems have predominantly employed end-to-end reinforcement learning. However, these approaches neglect supervision over the reasoning process, making it difficult to guarantee logical coherence and rigor. To address these limitations, we propose Thinker, a hierarchical thinking model for deep search through multi-turn interaction, making the reasoning process supervisable and verifiable. It decomposes complex problems into independently solvable sub-problems, each dually represented in both natural language and an equivalent logical function to support knowledge base and web searches. Concurrently, dependencies between sub-problems are passed as parameters via these logical functions, enhancing the logical coherence of the problem-solving process. To avoid unnecessary external searches, we perform knowledge boundary determination to check if a sub-problem is within the LLM's intrinsic knowledge, allowing it to answer directly. Experimental results indicate that with as few as several hundred training samples, the performance of Thinker is competitive with established baselines. Furthermore, when scaled to the full training set, Thinker significantly outperforms these methods across various datasets and model sizes. The source code is available at https://github.com/OpenSPG/KAG-Thinker.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Thinker, a new way to train LLMs to think more like careful problem-solvers. The goal is to help LLMs find and use information from the web or databases more effectively, avoid making things up, and explain their reasoning step by step. Thinker breaks big, tricky questions into smaller parts, searches deeply only when needed, and keeps the logic consistent and checkable.
What questions does the paper try to answer?
The paper looks at a few simple but important questions:
- How can we make LLMs solve complex, multi-step problems in a clear and logical way?
- Can we reduce unnecessary web searches by first checking if the model already knows the answer?
- Can we represent each step both in plain language and in a structured “logical” format so the model can work with both web pages and databases?
- Will this approach actually improve accuracy compared to popular methods, especially those trained with reinforcement learning (RL)?
How does Thinker work? (Methods explained simply)
Thinker’s approach is like how a good student tackles a tough research question: plan, break it down, check what you already know, then search only when needed, and keep track of every step.
Here are the main ideas, explained with everyday analogies:
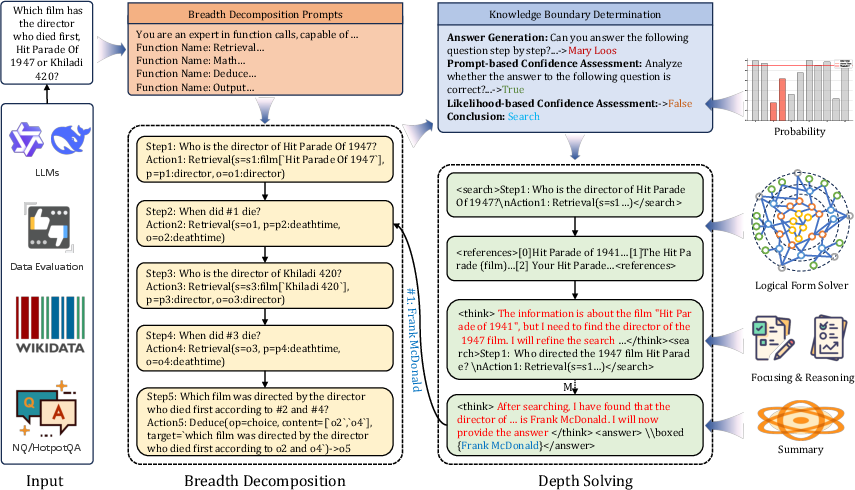
- Breadth decomposition: Imagine a big puzzle. Instead of trying to solve it all at once, you split it into smaller puzzles. For example, for the question “Which film has the director who died first, Hit Parade of 1947 or Khiladi 420?” Thinker breaks it into steps like: 1) Who directed movie A? 2) When did that director die? 3) Who directed movie B? 4) When did that director die? 5) Who died first?
- Depth solving: Some small puzzles still need digging. Thinker can do multiple rounds of search for each sub-problem. It keeps going until it finds enough evidence or hits a maximum limit, so it avoids endless searching.
- Knowledge boundary determination: Before searching, Thinker asks itself, “Do I already know this?” It uses two confidence checks:
- Prompt-based: It self-assesses whether its answer is likely correct.
- Likelihood-based: It looks at how confident it is in the key words it generated (using token probabilities) and applies a threshold. If both checks say “yes,” it skips external search.
- Dual representation (Step and Action): Each sub-problem is written in two ways:
- Step: Plain language (easy to read and useful for text-based search).
- Action: A logical function (like a mini formula) that databases and graph retrievers can use. Variables pass results between steps, like sticky notes labeled “#1” or “o1” to remember what was found earlier.
- Focusing and reasoning: After retrieving documents, Thinker highlights the most relevant bits (“focusing”) and explains how they answer the sub-problem (“reasoning”). If it’s not enough, it plans the next action.
- Multi-turn supervised training: Thinker is trained using example conversations where it plans, searches, and answers over multiple turns. Unlike pure RL, this supervised approach lets humans guide style and logic, making the steps easier to verify and control.
What did the experiments show? Why does it matter?
The paper tests Thinker on popular question-answering benchmarks, including both single-step and multi-step datasets. Key results:
- Strong performance across sizes: With base models like Qwen 3B and 7B, Thinker beats many existing methods, including several RL-based systems.
- On Qwen2.5-7B, Thinker achieves an average exact match (EM) score of 0.452, higher than a leading RL baseline (“ReSearch”) at 0.411.
- On Qwen2.5-3B, Thinker’s average EM is 0.430, above ReSearch’s 0.349.
- Better logical structure: Using metrics like logical hierarchy, granularity consistency, and search efficiency, Thinker’s reasoning process is more organized and coherent than RL-based deep-search baselines.
- Sample efficiency: Even with only a few hundred training samples (about 1% of the full data), Thinker’s performance is already close to the best baseline, reducing training cost.
- Smart searching: The “knowledge boundary” module cuts retrievals by around 16–18% on tested datasets while staying highly accurate (around 97% correctness for no-search decisions).
- Works even better with structured knowledge: When combined with a graph-based retriever (KAG), Thinker improves further by using the logical functions for database-like queries.
- RL on top of Thinker helps: Starting from the supervised Thinker model and then applying reinforcement learning increases average EM from 0.452 to 0.479, without breaking the logical structure.
These results matter because they show you can get both better accuracy and more trustworthy reasoning by organizing the thinking process and supervising it, rather than relying only on “trial-and-error” RL.
What is the potential impact?
Thinker helps LLMs act more like careful researchers:
- Fewer hallucinations: It searches when needed and checks confidence first.
- Clearer logic: Each step is explicit and verifiable, making results more trustworthy.
- Flexible to domains: Because it’s supervised and uses dual representations, it can adapt to fields like medicine, law, and finance where precise, step-by-step reasoning and reliable sources are critical.
- Cost-effective: It works well even with limited training data, and avoids unnecessary searches.
In short, Thinker is a promising approach for building AI systems that think in structured steps, use outside information wisely, and produce answers you can trace and trust.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper. Each point is stated to enable concrete follow-up by future researchers.
- Coverage of logical forms: The system only supports four operations (
Retrieval,Math,Deduce,Output). It is unclear how well this schema generalizes to tasks requiring richer operators (e.g., temporal reasoning, probabilistic inference, planning, code execution, tool use, graph transformation), or how to systematically extend and validate new logical functions. - Decomposition quality and verification: The breadth decomposition relies on an LLM with an instruction template, but there is no quantitative evaluation of sub-problem “atomicity,” decomposition correctness, or mechanisms to detect and repair faulty decompositions. How to automatically verify and refine decompositions remains open.
- Error propagation and recovery: Dependencies (
#n,o_n,s_n) transmit intermediate results, yet the system lacks strategies for backtracking or re-planning when an earlier sub-problem is wrong. What mechanisms (e.g., step-level verification, confidence-aware re-routing) can contain cascading errors? - Knowledge boundary determination calibration: The likelihood-based confidence uses the minimum token probability with a fixed threshold τ, but there is no principled calibration, sensitivity analysis, or adaptive thresholding across tasks, models, or tokenization schemes. How should τ be set or learned to balance accuracy and retrieval reduction?
- Robustness of introspective confidence: Prompt-based True/False introspection is known to be miscalibrated in LLMs. The paper does not evaluate robustness under adversarial prompts or systematically compare against external calibration methods (e.g., conformal prediction, temperature scaling, ensemble agreement).
- Validation of KBD decisions: KBD accuracy on EM=0 cases is judged by two larger LLMs rather than ground truth, introducing circularity and model bias. A human-annotated or programmatically verifiable benchmark for KBD decisions is needed.
- Retrieval strategy generalization: Experiments primarily use Wikipedia (Dec 2018) and dense text retrievers (E5-base-v2, BGE-M3). It is unclear how Thinker performs with web-scale, dynamic, noisy, multi-domain corpora, heterogeneous sources (tables, code, scientific PDFs), or multilingual data.
- Top-k and retriever sensitivity: The choice of top-k (mostly 3; 5 for ReSearch) is fixed. There is no analysis of sensitivity to k, hybrid reranking, query expansion, or learned retrieval policies that optimize cost-accuracy trade-offs per sub-problem.
- Depth solving termination policy: Depth solving stops via max-turn and “answer tokens,” but the optimal stopping policy is not studied. Can dynamic, cost-aware termination (e.g., bandit policies, Bayesian stopping) improve efficiency without harming accuracy?
- Cost, latency, and compute footprint: The paper reports retrieval reductions but does not quantify end-to-end latency, token and retrieval costs, or the computational overhead of multi-turn interactions versus baselines. A detailed efficiency profile is missing.
- Faithfulness and evidence attribution: Improvements are reported via EM/F1, but there is no measurement of evidence use (e.g., citing the exact supporting passage), faithfulness to retrieved content, or hallucination reduction beyond KBD. How faithful are answers to the retrieved evidence?
- Logical coherence evaluation methodology: Logical metrics (Hier, Intrlv, Gran, Eff) are judged by GPT-4 without human verification, inter-annotator agreement, or sensitivity to prompt variations. Reproducibility and reliability of these judgments need validation.
- Focusing and reasoning module impact: Ablation shows a small performance effect, but there is no analysis of when and why it helps or fails. What design changes (e.g., structured evidence selection, entailment checks) can increase its utility?
- Domain transfer beyond QA: Claims of applicability to medical, legal, and finance are not backed by controlled, domain-specific evaluations with domain KBs, compliance constraints, or safety criteria. How well does Thinker adapt to non-QA tasks and domain-specific toolkits?
- Structured KB utilization at scale: Dual representation is tested in KAG with a small, self-built corpus drawn from supporting facts. Generalization to large, real-world KBs (e.g., Wikidata) with complex schemas, constraints, and reasoning (e.g., joins, aggregation) remains untested.
- Multi-lingual and cross-cultural robustness: All experiments appear to be in English. The method’s behavior on multilingual corpora, cross-lingual reasoning, and non-Latin scripts is unknown.
- Training data and exposure bias: Multi-turn SFT optimizes cross-entropy over assistant turns, potentially encouraging verbose trajectories. There is no study of exposure bias, data curriculum, or methods (e.g., DPO/RLAIF variants) to align step-level behavior with outcomes.
- RL reward design and stability: Thinker-RL shows gains, but the reward function, constraints, and stability (e.g., variance, collapse, reward hacking) are not detailed. How do different reward formulations affect logical rigor, efficiency, and generalization?
- Step-level supervision and verifiability: While the approach claims supervisable reasoning, the paper does not provide a step-level correctness dataset, automatic checkers, or proof obligations linking
Actionexecution toStepsemantics. How can one guarantee and audit step-by-step validity? - Handling temporal and freshness constraints: The system uses a static 2018 Wikipedia; real-world tasks often require up-to-date data. How to integrate recency-aware retrieval and detect when parametric knowledge is outdated?
- Safety, bias, and harmful content: The paper does not assess safety risks (e.g., biased retrieval, harmful instructions) in multi-turn deep search. What safeguards and filters are needed at each step (planning, retrieval, reasoning)?
- Adaptive granularity and hierarchy: “Atomic granularity” is assumed, but no mechanism adapts granularity to task complexity or user constraints. How to learn optimal hierarchies (number and size of sub-problems) conditioned on the task and budget?
- Failure mode taxonomy: There is no systematic error analysis (e.g., bad decomposition, poor query formulation, irrelevant retrieval, misreasoning) to prioritize improvements. A taxonomy with measurable rates would make progress more targeted.
- Interaction with other tools: Integration with calculators, code execution, and external APIs is not explored within the logical forms. What interface and safety mechanisms enable reliable tool use while preserving auditability?
- Parameter passing semantics: Variable binding (
o_n,s_n,#n) is informal. Formal semantics for variable scope, typing, and error handling would help prevent mismatches betweenStepandActionand enable static checks. - Scalability of multi-turn training: The claim of computational efficiency via parallel processing is not quantified. Benchmarking throughput, memory footprint, and scaling to larger models/datasets is needed.
- Evidence selection metrics: The system does not report retrieval quality metrics (e.g., recall@k of supporting facts), making it hard to attribute gains to planning vs. retrieval. Including retrieval diagnostics would clarify bottlenecks.
- Human-in-the-loop verification: The framework is amenable to supervision, yet there is no exploration of minimal human feedback (e.g., correcting decompositions or step-level errors) to accelerate learning and ensure correctness.
- Licensing and data governance: Using web or KB content raises IP and privacy considerations; the paper does not discuss governance for enterprise deployment (logging, compliance, audit trails).
- Extensibility of the logical operator set: There is no recipe for designing, testing, and integrating new logical operators. A principled framework for operator addition, with benchmarks and guarantees, remains an open need.
Practical Applications
Immediate Applications
The following applications can be built and deployed now by combining Thinker’s breadth decomposition + depth solving, dual Step/Action logical forms, knowledge boundary determination (KBD), focusing and reasoning, and multi-turn supervised fine-tuning. Where relevant, we highlight tools/workflows that could be assembled from the paper’s open-source code and assumptions that affect feasibility.
- [Enterprise software, Knowledge management] Hierarchical RAG assistant for internal search and QA
- What it does: Decomposes complex employee questions into atomic sub-questions, retrieves across wikis, docs, and tickets, and assembles auditable answers with explicit Step/Action traces.
- Tools/workflows: Thinker planner + retriever (E5/BGE-M3) + KBD gate to cut 16–18% redundant queries; FlashRAG for indexing; optional KAG-Thinker for graph-aware retrieval over ontologies/CMDB.
- Assumptions/dependencies: Clean document corpora and entity resolution; base LLM fine-tuning for company style; access controls; retrieval quality.
- [Customer support] Case triage and resolution co-pilot
- What it does: Breaks down user issues into sub-problems (configuration, account, policy), retrieves targeted procedures, and provides stepwise resolutions with confidence tags from KBD.
- Tools/workflows: Ticketing integration; depth solving for multi-hop issue resolution; “focusing and reasoning” to weigh conflicting KB articles; retrieval budget optimizer.
- Assumptions/dependencies: Up-to-date support KB; clear workflows to escalate when confidence is low.
- [Compliance, Legal, Policy] Reg-tech query answering with auditable chains
- What it does: Answers “Does policy X apply to scenario Y?” by retrieving statutes, internal policies, and precedents using dual representations (Step for text search, Action for graph/SPARQL).
- Tools/workflows: Thinker traces as audit evidence; “Deduce” and “Output” functions to aggregate multi-source obligations.
- Assumptions/dependencies: Mappings from Action functions to legal KB schemas; human review for high-stakes decisions.
- [Finance] Equity/credit research assistant across filings, news, and KBs
- What it does: Decomposes multi-hop questions (e.g., revenue exposure via subsidiary chains) with variable propagation (s_n, o_n) and returns sourced, reproducible answers.
- Tools/workflows: Filings/news connectors; KBD to avoid needless web hits; “Search depth” set to ≥2 as per sensitivity results.
- Assumptions/dependencies: Entity disambiguation across sources; timeliness and licensing for market data.
- [Healthcare knowledge lookup] Guideline and literature Q&A (non-diagnostic)
- What it does: Retrieves clinical guidelines/systematic reviews with explicit reasoning steps; KBD avoids retrieval for well-known facts and surfaces confidence.
- Tools/workflows: Thinker + medical KB connectors (e.g., PubMed, guideline repositories); trace logging for peer review.
- Assumptions/dependencies: Not a clinical decision-maker; requires domain-tuned prompts and curation; regulatory guardrails.
- [Scientific workflows, Academia] Systematic literature review assistant
- What it does: Breaks a research question into inclusion/exclusion sub-queries; iteratively refines searches and aggregates evidence with “focusing and reasoning.”
- Tools/workflows: Source managers; reproducible action logs; deduping and quality appraisal prompts.
- Assumptions/dependencies: Access to publisher APIs; domain ontologies to power Action functions.
- [Education] Tutor and grader with explicit decomposition and confidence
- What it does: Shows students the decomposition of problems (Math/Deduce), flags when the model “knows” vs. “needs to look up,” and grades with verifiable steps.
- Tools/workflows: Classroom LMS plugin; KBD-based “metacognition” feedback; rubric-aligned Output aggregation.
- Assumptions/dependencies: Age-appropriate safeguards; curated corpora; alignment to curricula.
- [Business intelligence, Data] Natural-language-to-analytics mediator
- What it does: Converts a business question into sub-queries across data catalogs/semantic layers, retrieves metrics/definitions, and reconciles discrepancies.
- Tools/workflows: Action mapping to SQL/metric stores; focusing module to narrow relevant tables; Output for final aggregation.
- Assumptions/dependencies: Semantic layer availability; governed data access; result validation.
- [Software engineering] Code and design graph search with Step/Action plans
- What it does: Plans code questions (where, why, how) with Step text retrieval; Action maps to code graph (calls, ownership) to trace impacts and fix plans.
- Tools/workflows: Repo indexers; code graph (e.g., SCIP, CodeQL); KBD to avoid repo-wide scans; “search budget” guard.
- Assumptions/dependencies: Accurate code indexing and symbol resolution; model adapted to code domain.
- [Media, Fact-checking] Claim decomposition and verification desk
- What it does: Splits a claim into verifiable atomic statements; retrieves sources; focuses on contradictory evidence; outputs a verdict with linked support.
- Tools/workflows: News and reference connectors; adjudication UI with Thinker traces; calibration using KBD thresholds.
- Assumptions/dependencies: Source credibility filters; adversarial content handling.
- [E-discovery, Due diligence] Targeted discovery with variable propagation
- What it does: Decomposes discovery requests into entity/document sub-queries, binds variables across steps, and preserves provenance for court-ready review.
- Tools/workflows: Action→graph query (custodian/entity graphs); trace export for compliance/audit.
- Assumptions/dependencies: Legal review; chain-of-custody; restricted access.
- [IT Ops, SRE] Runbook retrieval and incident reasoning
- What it does: Decomposes incidents (symptom→service→dependency), retrieves runbooks/telemetry, and proposes remediations with confidence gates.
- Tools/workflows: Observability connectors; “depth solving” for root-cause breadcrumbs; Output to summarize actions.
- Assumptions/dependencies: Accurate service maps; freshness of runbooks.
- [Cost engineering, Platform] Retrieval budget optimizer for AI stacks
- What it does: Wraps existing RAG pipelines with KBD to cut unnecessary searches and API calls while preserving accuracy.
- Tools/workflows: Drop-in middleware with per-domain KBD thresholds; logging and A/B testing harness.
- Assumptions/dependencies: Calibrated thresholds per domain; monitoring for drift.
- [Frameworks, Tooling] Step/Action plugin for LangChain/LlamaIndex-style stacks
- What it does: Adds Thinker’s dual representation, variable binding, and “focusing and reasoning” loop as a reusable chain.
- Tools/workflows: Schema for Retrieval/Math/Deduce/Output; adapters to SPARQL/SQL/Graph APIs.
- Assumptions/dependencies: Engineering integration; domain-specific Action adapters.
- [Evaluation, AI governance] Reasoning-quality dashboards
- What it does: Scores agents on logical hierarchy, interleaving, granularity, and efficiency (the paper’s metrics) to track improvements over time.
- Tools/workflows: Automated trace parsers; benchmark harness based on the paper’s evaluation protocol.
- Assumptions/dependencies: Access to full traces; stable scoring prompts or models.
- [Personal productivity, Daily life] Smarter personal research assistant
- What it does: Breaks down travel/shopping/home-repair queries, searches only when needed (KBD), and provides source-linked summaries.
- Tools/workflows: Browser and note-taking integrations; per-site depth settings; confidence-labeled answers.
- Assumptions/dependencies: API access to sources; privacy controls; user-approved browsing.
Long-Term Applications
These applications are promising but need further research, domain adaptation, scaling, validation, or additional infrastructure (e.g., hybrid graph retrievers, reward design, multimodal integration, or regulatory approval).
- [Healthcare] Clinical decision support with verified reasoning
- Value: Step/Action traces support clinician review; Deduce/Math integrate labs, risk scores, and guidelines.
- Dependencies: Regulatory validation, medical KG mapping, calibrated KBD for safety, robust hallucination controls.
- [Law] Argument drafting with case law knowledge graphs
- Value: Variable propagation across precedents/statutes; Action→SPARQL over legal ontologies; auditable citations.
- Dependencies: High-coverage legal graphs; liability and privilege protections; human-in-the-loop signoff.
- [Science] Autonomous research agents for hypothesis generation
- Value: Multi-turn deep search across literature/data, with RL fine-tuning to optimize novelty/evidence criteria.
- Dependencies: Reward shaping for scientific value; access to datasets; reproducible computation.
- [Finance, Risk] Graph-native fraud/risk analysis
- Value: Depth solving to trace multi-hop relationships (beneficial ownership, transaction rings) with hybrid graph retrieval.
- Dependencies: Streaming graph infra; entity resolution; alert governance; adversarial robustness.
- [Public policy] Continuous regulatory monitoring and control mapping
- Value: Decomposes new rules into obligations, links to internal controls, and flags gaps with explicit traces.
- Dependencies: Normative frameworks; domain KGs; approval workflows in GRC systems.
- [Safety-critical ops: aviation, energy] Calibrated reasoning with human oversight
- Value: KBD thresholds + focusing module to gate retrieval/actions; rigorous traces for audits.
- Dependencies: Certification pathways; red-team testing; fail-safes and escalation.
- [Robotics, Autonomy] Web-informed procedural planning
- Value: Map Step/Action to task graphs and controllers; retrieve procedures/specs; reason with constraints.
- Dependencies: Multimodal (vision/action) integration; sim-to-real transfer; safety constraints.
- [Education] Personalized metacognitive learning at scale
- Value: Teaches students decomposition and self-assessment using KBD signals and explicit step grading.
- Dependencies: Longitudinal studies; pedagogy alignment; bias and fairness checks.
- [Platforms] Reasoning OS for enterprises
- Value: Centralized orchestration of planners, retrievers, budgets, and policy enforcement with standard logical traces.
- Dependencies: Cross-team governance; trace storage/provenance standards; cost controls.
- [Standards, Governance] Provenance and trace standards for AI reasoning
- Value: A portable “Logical Form Trace” schema to meet audit/regulatory requirements across vendors.
- Dependencies: Industry consortium; regulator engagement; interoperability across tools.
- [Efficiency] Domain-specific KBD calibrators
- Value: Learn per-domain thresholds to minimize cost/latency while preserving accuracy.
- Dependencies: Offline calibration datasets; drift detection; feedback loops.
- [Edge/On-device] Sample-efficient small-model deployments
- Value: Paper shows strong sample efficiency; with distillation, enable private/edge reasoning with deep search.
- Dependencies: Hardware constraints; incremental retrieval; careful compression.
- [Multilingual, Cross-lingual] Global reasoning over heterogeneous corpora
- Value: Step in one language, Action on language-agnostic graphs; cross-lingual retrieval.
- Dependencies: Multilingual LLM/retriever; cross-lingual KG alignment.
- [Trust and security] Adversarially robust deep search
- Value: Use focusing/reasoning to detect manipulative sources; RL to penalize unsafe citation patterns.
- Dependencies: Robustness benchmarks; adversarial data; safety reward design.
Notes on feasibility and deployment
- Integration readiness: The paper provides code and demonstrates performance with widely available retrievers (E5/BGE-M3) and standard corpora (Wikipedia), enabling immediate prototyping.
- Cost and latency: KBD reduced searches by ~16–18% in tests, offering an immediate cost/latency lever. Depth solving requires ≥2 searches for best results in multi-hop cases.
- Adaptation: Dual representations (Step/Action) require adapters to domain systems (SQL, SPARQL, graph DBs). KAG-Thinker shows concrete gains when such adapters exist.
- Governance: Thinker’s explicit logical traces support auditability and controllability compared to RL-only agents; high-stakes domains still require human oversight and validation.
Glossary
- Action: The logical function expression segment paired with a natural-language “Step” in the paper’s dual representation of sub-problems. "Each logical form comprises two components: a natural language segment (Step) and a logical function expression segment (Action)."
- API-driven systems: Systems that orchestrate retrieval and planning via APIs, often with multi-agent setups, to perform deep search. "Existing deep search strategies can be broadly categorized into two paradigms...: (1) API-driven systems that leverage task decomposition and planning, often employing multi-agent architectures to orchestrate retrieval decisions;"
- Auto-regressive generation: A token-by-token generation process where each token is sampled conditioned on the input and previously generated tokens. "During the auto-regressive generation process, each token () is associated with a conditional probability ."
- BGE-M3: A general-purpose dense retriever used to fetch relevant text passages for LLM reasoning. "For generic retrievers like E5 and BGE-M3, we can directly employ the content within the logical form's Step."
- Breadth Decomposition: The process of decomposing a complex problem into atomic, independent sub-problems before depth solving. "We decompose complex problems breadth-wise into atomic granularity sub-problems, with our decomposition instruction template detailed in Appendix~\ref{appendix.breadth_decomposition}."
- Chain-of-Thought (CoT): A prompting technique that elicits explicit, step-by-step reasoning traces from LLMs. "Chain-of-Thought (CoT): Explicit cognitive pathway formalization through sequential reasoning traces~\cite{cotWei2023}."
- Cross-entropy loss: A standard training objective measuring the difference between predicted token distributions and ground truth, computed over assistant outputs. "The cross-entropy loss is computed solely over the assistantâs response tokens (), after which the losses are averaged."
- Deduce: A logical function type in the paper’s formalism used for causal reasoning or inference steps. "We define four logical form functions (Retrieval, Math, Deduce, and Output), each dedicated to handling specific tasks: retrieval-focused problems, mathematical computation and causal reasoning tasks, and results aggregation functions."
- Dual representations: The pairing of natural-language “Step” and formal “Action” expressions for each sub-problem to enable both text and structured retrieval. "each sub-question adopts dual representations, Step and Action, that maintain semantic equivalence."
- E5-base-v2: A dense embedding-based retriever used to index and search the corpus. "We employ E5-base-v2~\cite{wang-etal-2024-improving-text} as the retriever"
- EM score: The Exact Match metric used to evaluate whether a predicted answer exactly matches the ground truth. "increasing the average EM score from 0.452 to 0.479."
- F1 score: A harmonic mean of precision and recall used to evaluate answer quality over token overlap. "Figure~\ref{Fig.Thinker_RL}(c) and (d) show the average EM and F1 scores on seven evaluation datasets."
- FlashRAG: A preprocessing/indexing framework used to build and query the retrieval corpus efficiently. "All corpus indexing and embedding processes are pre-processed using FlashRAG~\cite{flashrag2025}."
- Focusing and Reasoning: Modules that analyze retrieved references to decide next actions or produce final answers during depth solving. "Therefore, we have designed Focusing and Reasoning modules to fulfill this purpose."
- Generate First, Then Assess: A strategy where the model first attempts an internal answer and then evaluates its confidence to decide whether retrieval is needed. "To mitigate these challenges, we introduce the Generate First, Then Assess strategy."
- Hybrid Graph Retriever (HGR): A graph-based retrieval component that leverages structured relations for improved multi-hop reasoning. "KAG-Thinker achieves these enhancements by leveraging two key features from the KAG framework: the hybrid graph retriever (HGR) and native support for Math and Deduce."
- Interleaved Solving: A problematic pattern in RL-trained search where steps are mixed without clear structure, harming logical rigor. "reinforcement learning based deep search methods often suffer from typical problems such as interleaved solving, unclear hierarchy, inconsistent granularity, and inefficient search."
- Introspective verification: A prompt-based self-assessment approach where the model evaluates the confidence of its own answer. "We introduce a prompt-based methodology for confidence assessment that employs introspective verification."
- KAG framework: A knowledge graph-centric framework that supports structured operations (e.g., Math, Deduce) and hybrid graph retrieval. "We create KAG-Thinker by applying the Thinker model within the KAG framework~\cite{DBLP:journals/corr/abs-2409-13731}."
- Knowledge boundary determination: A module that decides whether a sub-problem can be answered from the model’s internal knowledge without external retrieval. "To prevent unnecessary and potentially noisy retrieval, we introduce a knowledge boundary determination module."
- LLMs: Transformer-based generative models capable of complex reasoning and text generation at scale. "Recently, LLMs like GPT-4 have demonstrated remarkable capabilities dealing with simple tasks~\cite{openai2024gpt4technicalreport,qwen2025qwen25technicalreport}."
- Likelihood-based confidence assessment: A confidence measure based on token probabilities of the generated answer sequence. "Likelihood-based confidence assessment evaluates the reliability of a model's generated response by leveraging the probabilities of its output tokens."
- Logical form: A formal representation for sub-problems with variables and functions that enables structured retrieval and dependency propagation. "Each logical form comprises two components: a natural language segment (Step) and a logical function expression segment (Action)."
- Math: A logical function type used for numerical computation or mathematical reasoning within the formalism. "We define four logical form functions (Retrieval, Math, Deduce, and Output), each dedicated to handling specific tasks: retrieval-focused problems, mathematical computation and causal reasoning tasks, and results aggregation functions."
- Minimum probability criterion: A confidence scoring rule that uses the lowest token probability in the answer to detect uncertainty. "To more effectively capture moments of high uncertainty during generation, we adopt a minimum probability criterion."
- Multi-Hop QA: Question answering tasks that require reasoning across multiple pieces of evidence or hops. "Multi-Hop QA: HotpotQA~\cite{yang-etal-2018-hotpotqa}, 2WikiMultiHopQA~\cite{ho-etal-2020-constructing}, Musique~\cite{trivedi-etal-2022-musique}, and Bamboogle~\cite{press2023measuringnarrowingcompositionalitygap}."
- Multi-turn interaction: A training and inference setup where the model reasons and retrieves across multiple conversational turns. "We propose a deep search method based on hierarchical thinking and multi-turn interaction, as shown in Figure~\ref{Fig.KAGThinker_framework}."
- Output: A logical function type that aggregates results or formats the final answer in the formalism. "We define four logical form functions (Retrieval, Math, Deduce, and Output), each dedicated to handling specific tasks: retrieval-focused problems, mathematical computation and causal reasoning tasks, and results aggregation functions."
- Parametric knowledge: Information encoded in the model’s parameters rather than external documents. "even when the required information is already encoded in the LLM's parametric knowledge."
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm used to train search-capable LLMs in StepSearch. "StepSearch: PPO-based search LLM training with incremental exploration~\cite{wang2025stepsearchignitingllmssearch}."
- Retrieval: A logical function type and operation that fetches relevant documents or facts needed for reasoning. "We define four logical form functions (Retrieval, Math, Deduce, and Output), each dedicated to handling specific tasks: retrieval-focused problems, mathematical computation and causal reasoning tasks, and results aggregation functions."
- Retrieval-Augmented Generation (RAG): A paradigm that integrates retrieved external knowledge into generation for knowledge-intensive tasks. "Several retrieval-augmented generation (RAG) methods have been proposed~\cite{DBLP:conf/naacl/JeongBCHP24,DBLP:conf/emnlp/IslamRHHJP24,DBLP:conf/coling/TangGLDLX25,DBLP:conf/icml/BorgeaudMHCRM0L22,DBLP:conf/cikm/DongLWZXX23,DBLP:conf/acl/LuoETPG0MDSLZL24,Li2025FromS1,DBLP:journals/corr/abs-2502-06772,DBLP:journals/corr/abs-2402-11035}."
- Search efficiency (Eff): A defined metric assessing how efficiently a deep search method conducts retrieval steps. "The logical coherence and rigor of different deep search models are evaluated using four defined metrics: Logical Hierarchy (Hier), Interleaved Solving (Intrlv), Granularity Consistency (Gran), and Search Efficiency (Eff) (see Appendix~\ref{append.logical_metrics} for detailed definitions)."
- Step: The natural-language segment of a logical form that describes a sub-problem for plain-text retrieval. "Step employs for answer propagation of the -th sub-problem"
- Supervised fine-tuning (SFT): Training methodology that optimizes the model with labeled multi-turn interaction data rather than pure RL. "We conduct supervised fine-tuning of the deep search reasoning process through multi-turn interaction data."
- Variable binding: The mechanism of passing dependencies between sub-problems via variables within logical functions. "Action binds variables in logical function (e.g., , ) for variable transmission."
Collections
Sign up for free to add this paper to one or more collections.