- The paper presents a novel GRMP attack that exploits graph representations to camouflage malicious model updates in federated IoA environments.
- It leverages a variational graph autoencoder (VGAE) to mimic benign inter-agent correlations, effectively bypassing current DiSim-defense mechanisms.
- Experimental validation on the AG News dataset shows a 62% targeted misclassification rate while overall accuracy remains around 82%, highlighting the attack’s subtlety.
Graph Representation-based Model Poisoning on the Heterogeneous Internet of Agents
Introduction to the IoA Paradigm and FL Vulnerabilities
The imminent evolution towards the Internet of Agents (IoA), where diverse LLM agents operate in tandem across virtual and physical realms, heralds a novel, scalable ecosystem. At the heart of this ecosystem lies federated learning (FL), facilitating distributed model training without necessitating data localization. However, while FL promises data privacy and reduced communication overhead, it remains susceptible to model poisoning attacks which capitalize on the decentralized architecture to degrade model integrity through adversarial updates.
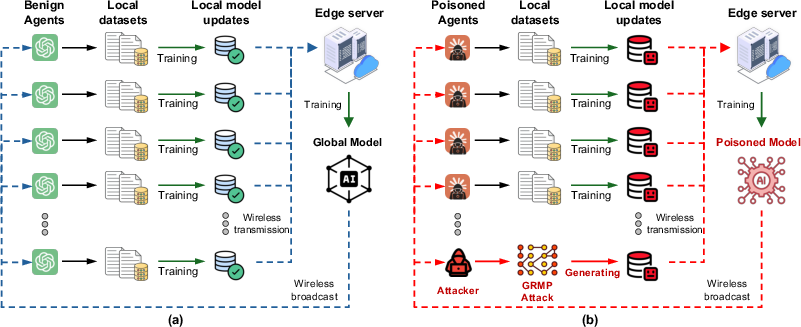
Figure 1: (a) Training process of the FL-enabled IoA system, and (b) impact of the GRMP attack on the IoA training cycle.
Proposed GRMP Attack Framework
The "Graph Representation-based Model Poisoning" (GRMP) attack leverages advanced adversarial graph techniques, crafting malicious updates that camouflage as benign by embedding within higher-order structural correlations of model parameters. This method is particularly adept at eluding the incumbent DiSim-defense mechanisms that detect outliers through statistical deviations in magnitude or direction of model updates. GRMP constructs a parameter correlation graph from benign models, subsequently embedding adversarial gradients via a variational graph autoencoder (VGAE), effectively nullifying existing defenses.
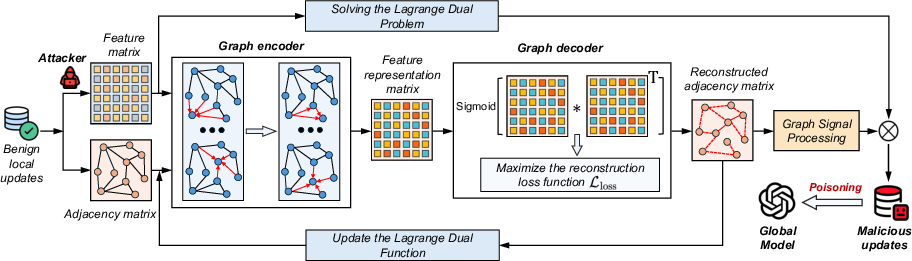
Figure 2: Framework of the proposed GRMP attack.
Attacker Model and Optimization Strategy
In the attacker model, adversarial actors infiltrate the IoA environment by posing as legitimate LLM agents, stealthily integrating malicious updates into the global model. The goal is to optimize a non-convex combinatorial problem — maximizing contamination efficacy while minimizing detection risk. The optimization leverages Lagrangian dual methods to split bandwidth selection from adversarial model crafting. Bridging these transactions is the VGAE, which reconstructs benign correlation structures to mask adversarial intentions, all while maintaining proximity to global model weights to bypass defense filtering.
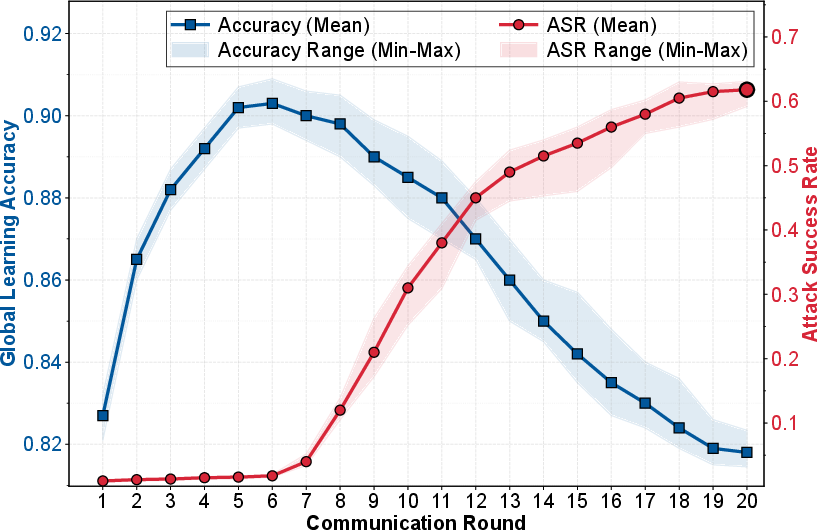
Figure 3: Impact of the GRMP attack on global model learning accuracy and the attack success rate (ASR) over 20 communication rounds (×10 times).
Experimental Validation
Empirical evaluation on the AG News dataset within a simulated IoA confirms the GRMP attack's potency. DistilBERT models deployed across LLM agents demonstrated significant susceptibility; 62% of targeted misclassifications were achieved, whereas overall learning accuracy inconspicuously hovered at around 82%. Despite contemporary dynamic DiSim mechanisms, GRMP-induced adversarial updates remained indistinguishable from legitimate ones due to their sophisticated mimicry of inter-agent cosine similarity patterns.
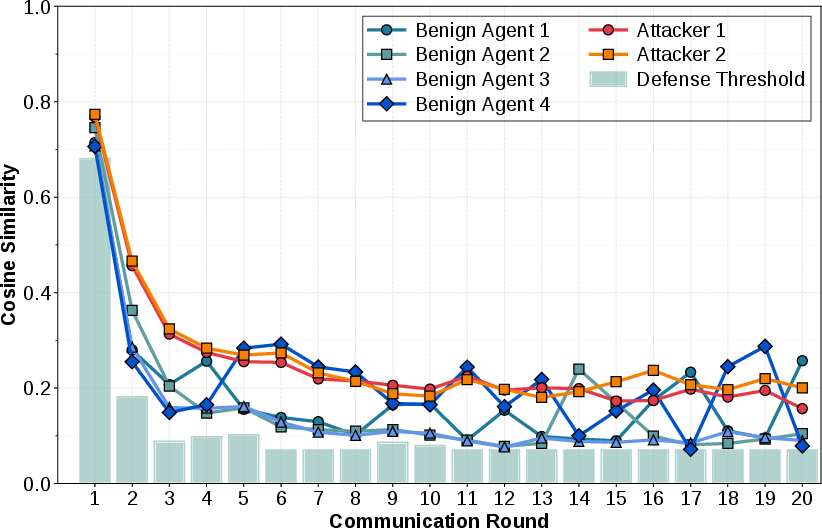
Figure 4: Temporal evolution of cosine similarity for each LLM agent with dynamic detection threshold over 20 communication rounds.
Figure 5 and Figure 6 further depict the learning accuracy of local LLM agents both in attack-free settings and under GRMP assault, revealing a substantial degradation in unmitigated scenarios, and validating the attack’s subversive efficacy.
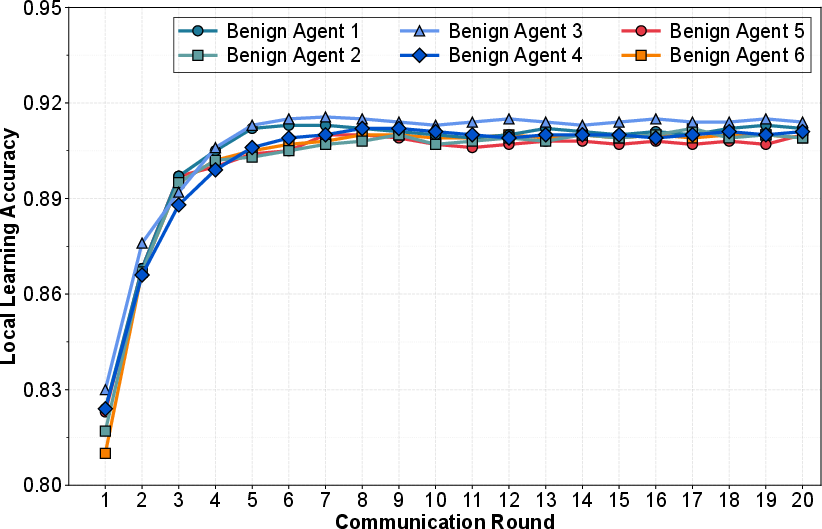
Figure 5: Learning accuracy of local LLM agents with no attack over 20 communication rounds.
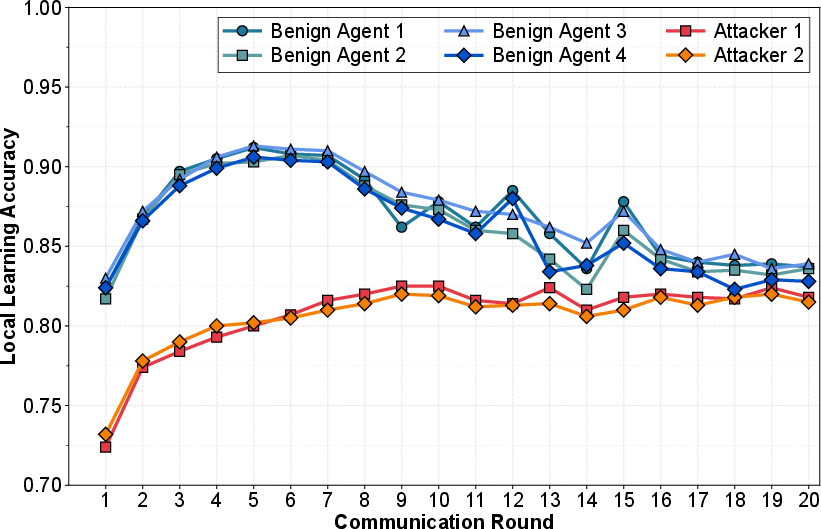
Figure 6: Learning accuracy of local LLM agents under the GRMP attack over 20 communication rounds.
Conclusion and Future Perspectives
The GRMP attack introduces a critical vector for disrupting FL-enabled IoA systems, transcending traditional detection paradigms by exploiting inherent structural limitations. As IoA systems herald broader, more sophisticated agent interactions, defending against such intelligently masked threats necessitates novel countermeasures. Future research must pivot towards diversifying defense models, encapsulating graph theoretic insights, and fostering resilience in federated structures to sustain the integrity and functionality of autonomous IoA ecosystems.

