- The paper introduces a plug-and-play training module that aligns each implicit token with a distinct reasoning step.
- It achieves notable gains by mitigating latent instability, with improvements up to 9% over existing implicit CoT methods.
- The framework enhances interpretability by mapping latent tokens to explicit reasoning vocabulary, facilitating detailed diagnostic analysis.
Supervised Implicit Chain-of-Thought: SIM-CoT
Motivation and Latent Instability in Implicit Reasoning
The SIM-CoT framework addresses a critical limitation in implicit chain-of-thought (CoT) reasoning for LLMs: latent instability when scaling the number of implicit tokens. Prior implicit CoT methods, such as Coconut and CODI, encode reasoning steps as continuous latent vectors, offering substantial token efficiency compared to explicit CoT. However, increasing the number of implicit tokens often leads to training collapse, semantic homogenization, and loss of step-level information, especially operator semantics essential for compositional reasoning.
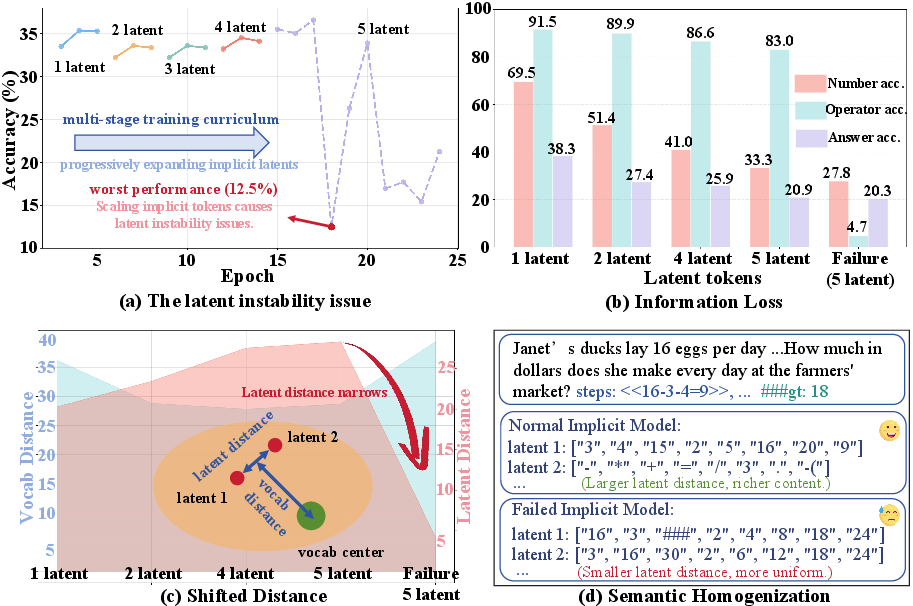
Figure 1: Latent instability in implicit CoT: increasing implicit tokens initially improves accuracy, but training collapses due to information loss, reduced inter-latent distance, and semantic homogenization.
Empirical analysis reveals that failed models with excessive implicit tokens lose operator information, collapse latent distances, and drift away from the vocabulary embedding space. This degeneration results in homogeneous latent states that predominantly encode numbers, undermining the model's ability to perform multi-step reasoning.
SIM-CoT Framework and Step-Level Supervision
SIM-CoT introduces a plug-and-play training module that applies step-level supervision to each implicit latent token. Unlike Coconut (answer-level supervision) and CODI (trajectory-level distillation), SIM-CoT employs an auxiliary decoder during training to align each latent with its corresponding explicit reasoning step. This alignment ensures that each latent captures distinct, semantically meaningful information, stabilizing the latent space and preventing collapse.
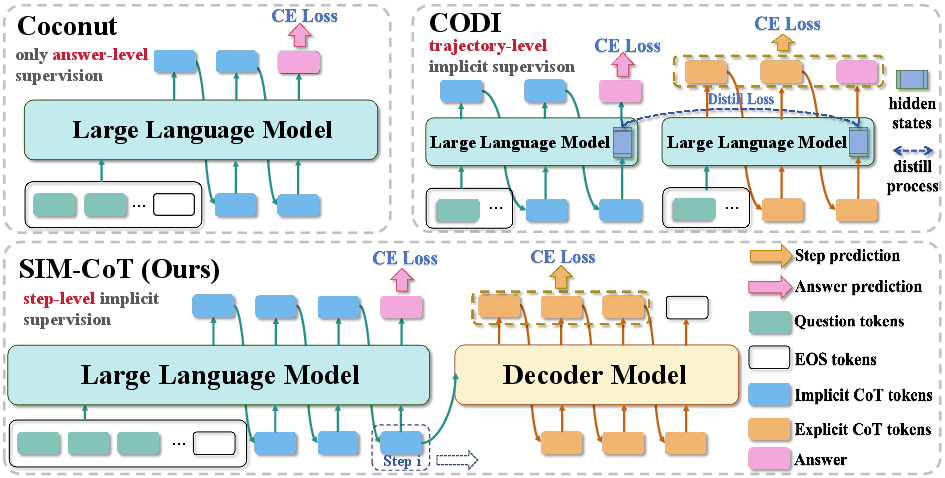
Figure 2: SIM-CoT framework: step-level supervision via a decoder aligns implicit latents with explicit reasoning steps, contrasting with coarse-grained supervision in Coconut and CODI.
During training, the decoder receives each latent zk and autoregressively generates the k-th reasoning step sk. The loss is computed only over the textual step tokens, directly grounding each latent to its semantic role. At inference, the decoder is removed, preserving the efficiency of implicit CoT with no additional computational overhead.
Empirical Results and Scaling Behavior
SIM-CoT demonstrates strong empirical gains across multiple LLM backbones and benchmarks. On GPT-2, SIM-CoT surpasses the explicit CoT baseline by 2.1% and improves Coconut by 8.2% and CODI by 4.3%. On LLaMA-3.2 1B, SIM-CoT yields a 3.4% improvement over CODI and a 9.0% gain over Coconut. The method remains robust and stable when scaling to larger models (LLaMA-3B, LLaMA-8B), consistently outperforming or matching explicit CoT while maintaining inference efficiency.
Ablation studies show that SIM-CoT enables stable training with more implicit latents, whereas Coconut collapses beyond five latents. The step-level supervision in SIM-CoT scales effectively with latent capacity, providing consistent accuracy gains and mitigating representation collapse.

Figure 3: Ablation on the number of implicit latents: SIM-CoT maintains stable accuracy as latent count increases, while Coconut collapses.
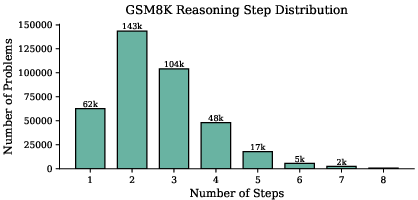
Figure 4: Distribution of reasoning steps in GSM8K-Aug: most problems require 2–4 steps, with a long tail of harder cases.
Interpretability and Latent Space Diagnostics
SIM-CoT enhances interpretability by projecting each latent token onto an explicit reasoning vocabulary using the training decoder. This enables per-step visualization and diagnosis of the reasoning process, bridging the gap between implicit and explicit CoT.
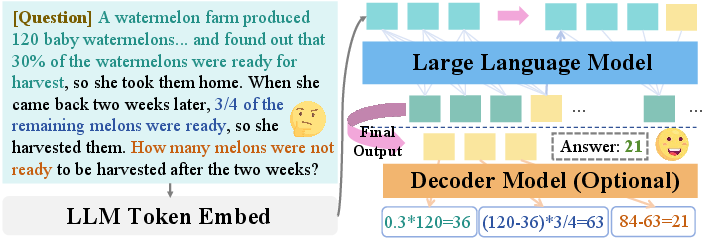
Figure 5: SIM-CoT case study: implicit continuous tokens are decoded into interpretable intermediate steps leading to the final output.
Geometric diagnostics confirm that SIM-CoT restores both separation and stability in the latent space. Normal implicit tokens are well-separated and close to the vocabulary center, failed tokens collapse and drift away, while SIM-CoT latents regain structured separation and semantic grounding.
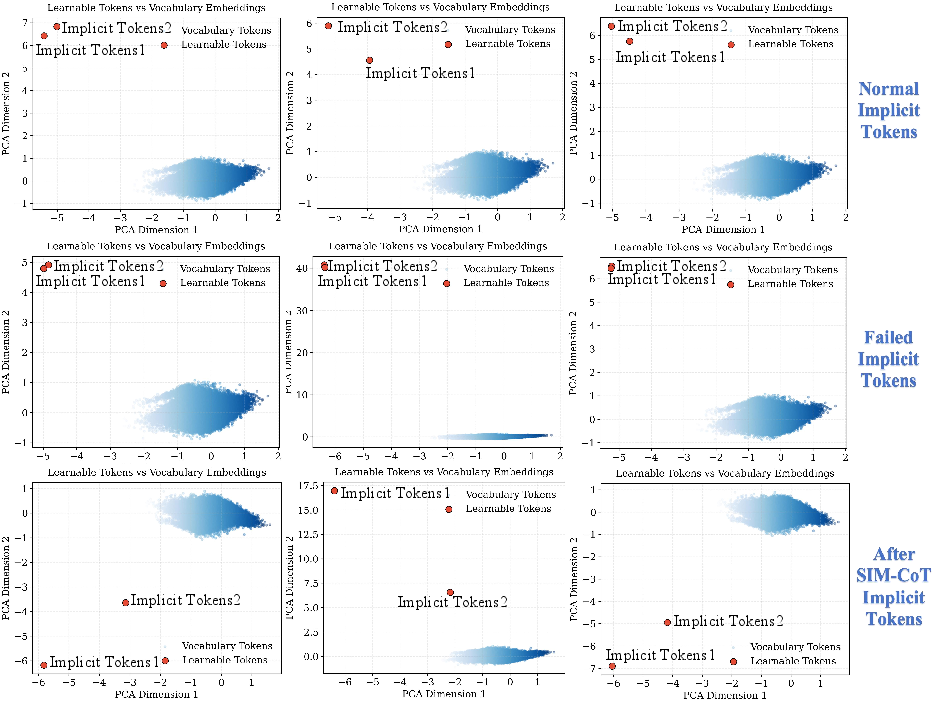
Figure 6: Visualization of distances among implicit tokens: SIM-CoT restores separation and stability compared to failed models.
Additional Case Studies and Reasoning Visualization
SIM-CoT consistently produces interpretable, step-ordered reasoning chains in its latent space. Case studies on GSM8k illustrate how each implicit latent corresponds to a distinct intermediate step, with arrows indicating dependency relations and colored spans highlighting supporting evidence.
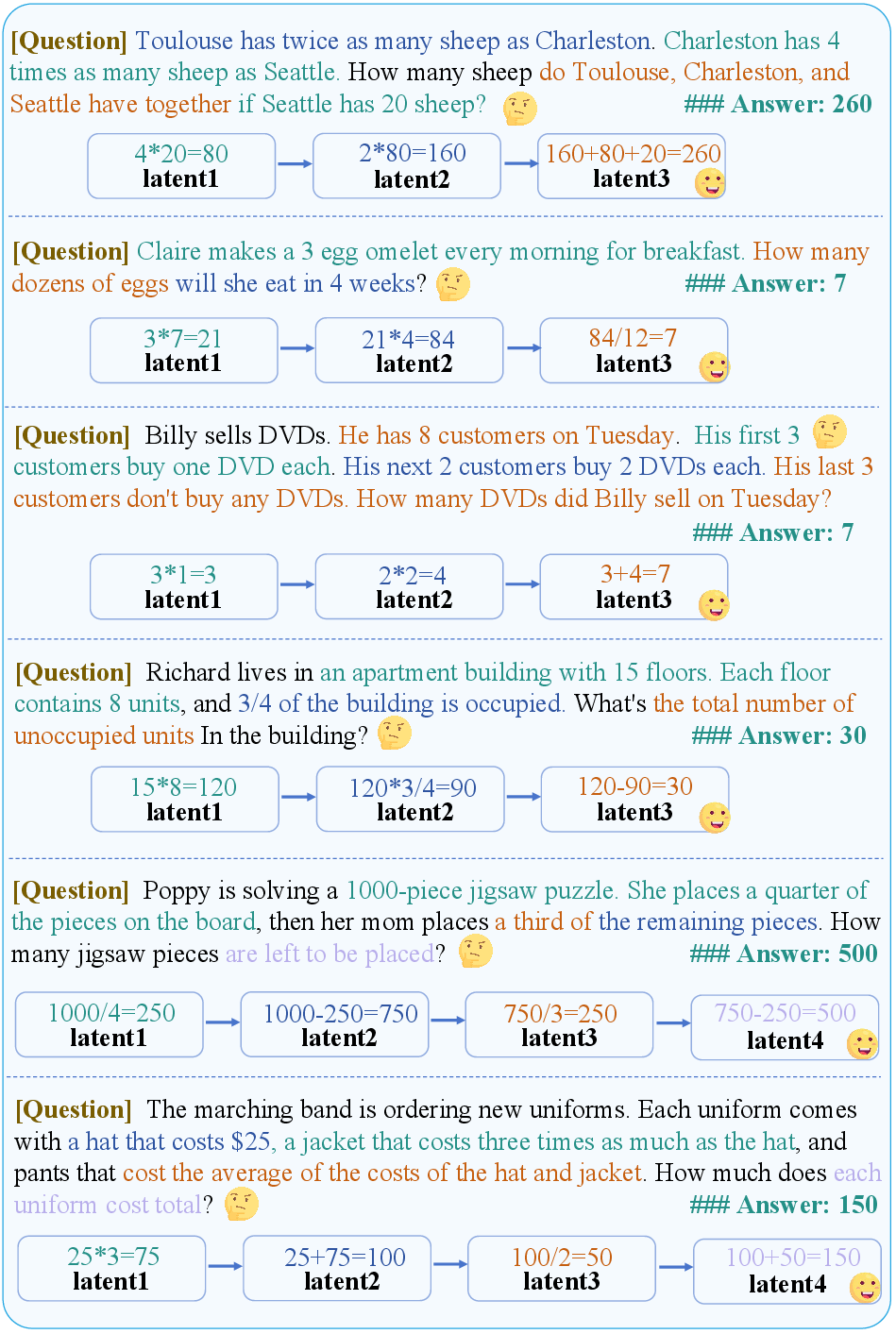
Figure 7: SIM-CoT case studies: implicit latents correspond to intermediate reasoning steps, with dependencies and evidence highlighted.
Practical and Theoretical Implications
SIM-CoT establishes a new paradigm for efficient, stable, and interpretable implicit reasoning in LLMs. The step-level supervision mechanism is modular and can be integrated with existing implicit CoT methods, including training-free approaches such as soft thinking. The framework achieves superior token efficiency, robust generalization to out-of-domain benchmarks, and maintains performance when scaling to larger models.
Theoretically, SIM-CoT demonstrates that fine-grained supervision distributes learning signals across the latent chain, preventing collapse and ensuring semantic fidelity. The geometric analysis of latent space provides a principled diagnostic for stability and diversity, informing future developments in implicit reasoning.
Future Directions
Potential extensions include multimodal step-level supervision for vision-LLMs, multi-path implicit reasoning inspired by Tree-of-Thought methods, integration with RLHF and preference optimization, and further theoretical analysis of latent space dynamics. The modularity of SIM-CoT suggests broad applicability across reasoning tasks and model architectures.
Conclusion
SIM-CoT introduces step-level supervision for implicit chain-of-thought reasoning, resolving latent instability and semantic collapse in prior methods. The approach achieves strong empirical gains, stable scaling, and enhanced interpretability, establishing a robust framework for efficient multi-step reasoning in LLMs. Theoretical and practical insights from SIM-CoT inform future research in implicit reasoning, multimodal learning, and representation stability.