- The paper introduces SPA, a framework that prioritizes trustworthy responses via a lexicographic self-priority optimization approach in LLM alignment.
- It employs an unsupervised methodology with diverse sampling, dual-criterion denoising, and self-refinement to balance safety and helpfulness.
- Experiments on models like Llama-3.1-8B-Instruct show that SPA achieves superior safety and performance compared to common alignment baselines.
Summary of "SPA: Achieving Consensus in LLM Alignment via Self-Priority Optimization" (2511.06222)
Introduction and Background
LLMs exhibit powerful capabilities across varied applications but pose significant risks when deployed in high-stakes environments. In settings involving medical, legal, or self-harm scenarios, LLMs necessitate rigorous alignment protocols to prioritize trustworthiness alongside helpfulness. Current approaches often compromise between these imperatives, grappling with context-agnostic balances and data scarcity. The paper proposes a novel alignment paradigm, Self-Priority Alignment (SPA), which adopts a lexicographic optimization strategy underscoring "trustworthy-before-helpful" ordering. This method conditions the optimization of helpfulness on meeting predefined trustworthy thresholds, such as harmlessness.
SPA Framework Overview
SPA operates from a fully unsupervised methodology, leveraging diverse candidate generation, dual-criterion evaluation, and self-refinement processes. It begins with generating varied responses using the LLM, which perform self-evaluation on both alignment criteria. This is followed by self-refinement through model introspection to iteratively improve response quality.

Figure 1: Examples of achieving trustworthiness and helpfulness under high-stakes scenarios.
The dual-criterion denoising method then filters outputs to remove inconsistencies and control variance, ensuring reliability. The retained responses form a preference dataset structured in lexicographic order, which emphasizes priority alignment principles. SPA concludes by optimizing the model using a preference learning objective that accentuates high-confidence, high-gap decisions, resulting in enhanced alignment without compromising safety.
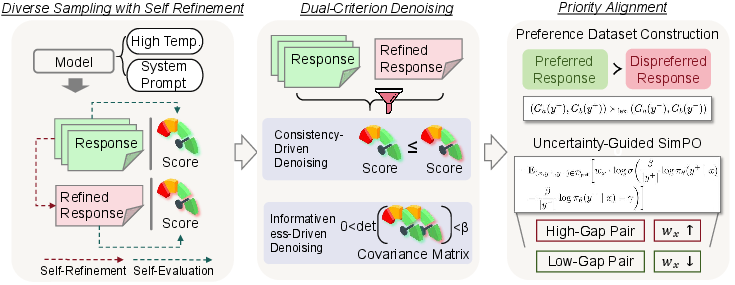
Figure 2: Overview of SPA, consisting of three components: diverse sampling with self-refinement, dual-criterion denoising, and priority alignment.
Methodological Contributions
- Priority Alignment Formulation: SPA redefines alignment objectives into a priority-based optimization problem using a lexicographic approach, enabling unambiguous control over multi-objective settings without explicit weight constraints.
- Preference Dataset Construction: By employing pairwise preference optimization strategies such as DPO and SimPO, SPA constructs knowledge representations that effectively capture Pareto optimality under lexicographic constraints.
- Experimental Validation: Through extensive benchmarks across various high-stakes environments, SPA demonstrates improved helpfulness paired with robust safety measures, outperforming existing alignment baselines. It achieves notable advancements in tasks both seen and unseen during fine-tuning.
Results and Discussion
SPA is distinguished by its scalability and interpretability in aligning LLM behavior to stringent ethical requirements. In the Llama-3.1-8B-Instruct and Mistral-7B-Instruct models, SPA showcases superior metrics on both trustworthiness and helpfulness, indicating the efficacy of lexicographic prioritization. Comparative analyses with common alignment baselines reveal SPA's enhanced aggregate score across multiple scenarios, underscoring the nuanced trade-offs managed by priority alignment.
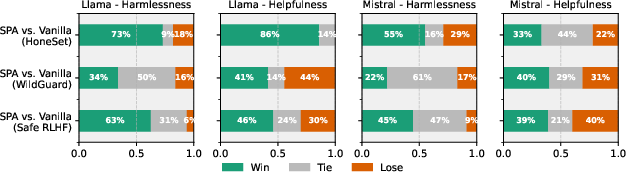
Figure 3: Results of pairwise comparison on different datasets. We use GPT-4o as the judge model.
Furthermore, the framework positively influences model reliability even in dynamic and unseen datasets, highlighting its robustness and broad applicability.
Implications and Future Directions
The theoretical underpinnings of SPA offer compelling pathways for future alignment strategies in AI. Its principle-driven approach to conflict resolution between alignment objectives paves avenues for application in domains beyond conventional safety-critical environments—extending utility in fields like long-form text generation and automated reasoning. Researchers might extrapolate SPA methodologies to explore lexicographic optimization in broader machine learning contexts, potentially reshaping paradigms around multi-objective control and preference learning.
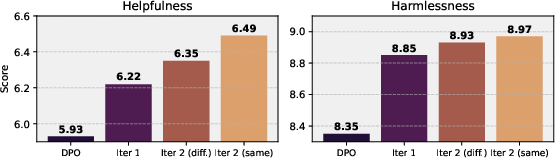
Figure 4: Effect of multiple SPA iterations on WildGuard using LLaMA-3.1-8B-Instruct. Iter 2 (diff.)'' uses a new dataset in the second iteration, whileIter 2 (same)'' reuses the original data.
Conclusion
SPA heralds a strategic advancement in unsupervised LLM alignment, exhibiting consistent improvements in ensuring safety and enhancing helpfulness in critical applications. By integrating stepwise optimization strategies through preference ranking systems, it provides critical insights for harmonizing diverse objectives within AI frameworks, promising robust and scalable implementations for the future of LLM alignment.

