- The paper demonstrates that FCCT systematically quantifies causal effects on visual perception by analyzing LVLM components using techniques like activation patching.
- The study reveals that MHSAs and FFNs organize and transfer cross-modal information hierarchically to form effective representations.
- The proposed IRI method reinforces mid-layer representations during inference, leading to improved performance and reduced hallucinations across benchmarks.
Causal Tracing of Object Representations in Large Vision LLMs
Introduction
Causal Tracing of Object Representations in Large Vision LLMs provides an insight into mechanistic interpretability and approaches to mitigate hallucinations. Despite the advancements in Large Vision-LLMs (LVLMs), the interpretability regarding their processing of visual and textual data remains partially understood. This research introduces a novel framework, Fine-grained Cross-modal Causal Tracing (FCCT), to systematically quantify causal effects on visual perception. FCCT's analysis highlights the critical roles of model components like Multi-Head Self-Attention (MHSA) and Feed-Forward Networks (FFNs). In response to these findings, the Intermediate Representation Injection (IRI) technique is proposed to enhance perception and mitigate hallucinations, achieving state-of-the-art performance across various benchmarks.
Fine-Grained Cross-Modal Causal Tracing (FCCT) Framework
The FCCT framework systematically analyzes the causal effects on visual perception by examining visual and textual tokens and their interactions across all layers and components of LVLMs. It employs activation patching, running LVLMs across clean, corrupted, and patched scenarios, to quantify the Recovery Rate (RR) that measures the causal effect of each restored component.
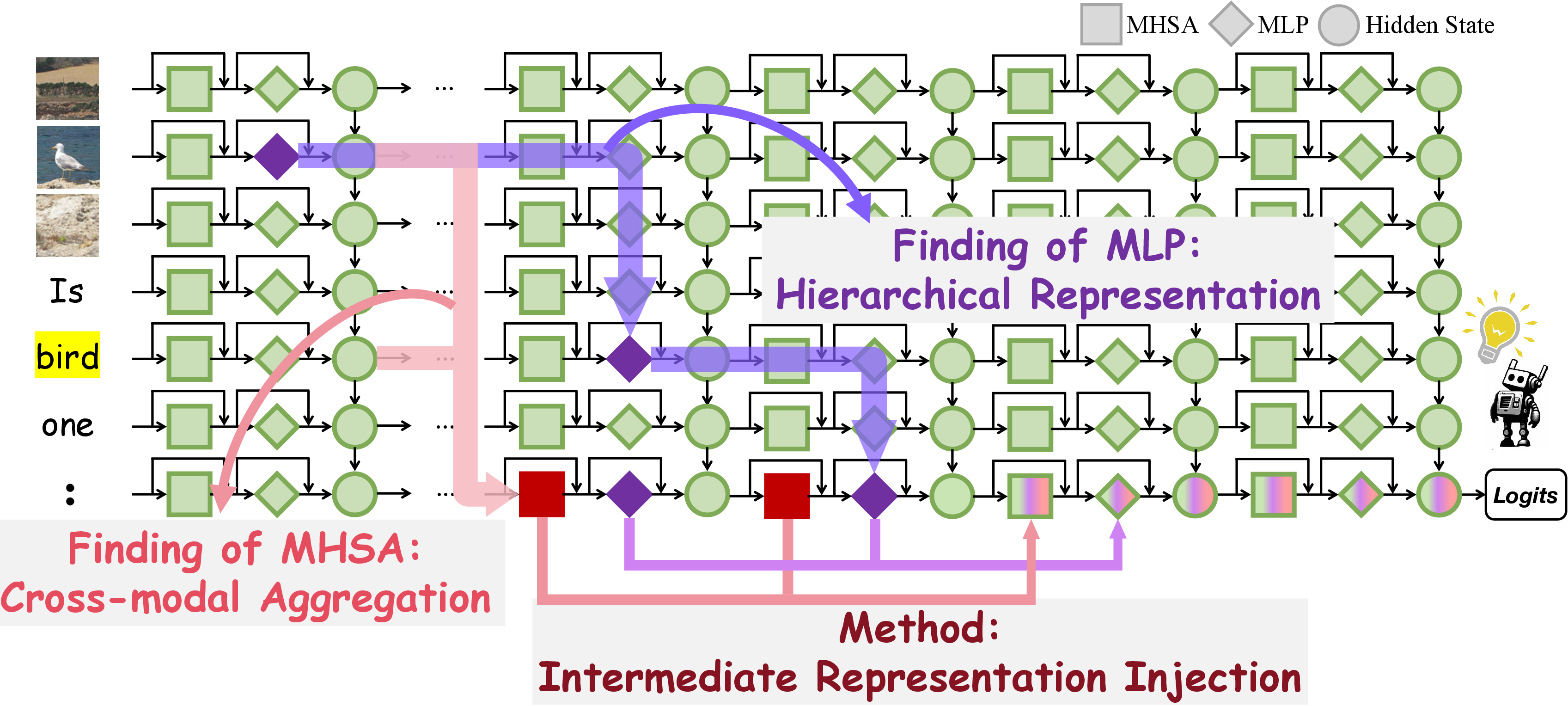
Figure 1: An overview of our proposed Fine-grained Cross-modal Causal Tracing findings and Intermediate Representation Injection method.
By adding controlled Gaussian noise to images and measuring output probabilities, FCCT pinpoints crucial components and layers involved in visual perception. The study reveals that the MHSAs of the last token in middle layers aggregate cross-modal information, while FFNs show a hierarchical progression in storing and transferring visual object representations.
Based on FCCT findings, IRI is developed as a training-free inference-time method to reinforce visual object information flow. This technique involves injecting crucial mid-layer representations into subsequent layers, identified through FCCT as having strong causal effects, to enhance visual perception and mitigate hallucinations.
Implementation Details
IRI operates by selecting top-layer components based on recovery rates. It captures MHSA and MLP outputs from source layers and injects them into target layers, scaling them by RRs to enhance their causal influence. Consistently improved benchmarks across several LVLMs demonstrate IRI's efficacy in enhancing perceptual accuracy while preserving inference speed.
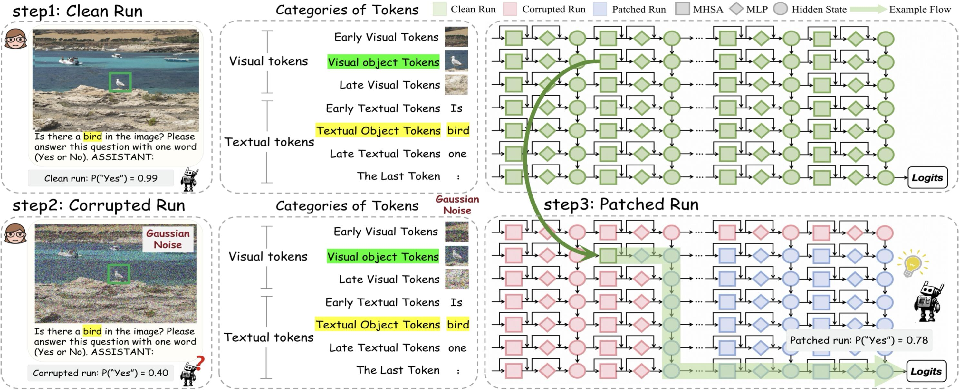
Figure 2: Overview of our proposed Fine-grained Cross-modal Causal Tracing method.
Key Findings
- Cross-modal Aggregation: MHSAs of the last token in middle layers play a pivotal role in aggregating visual-textual information, facilitating the transition to high-level cross-modal representations.
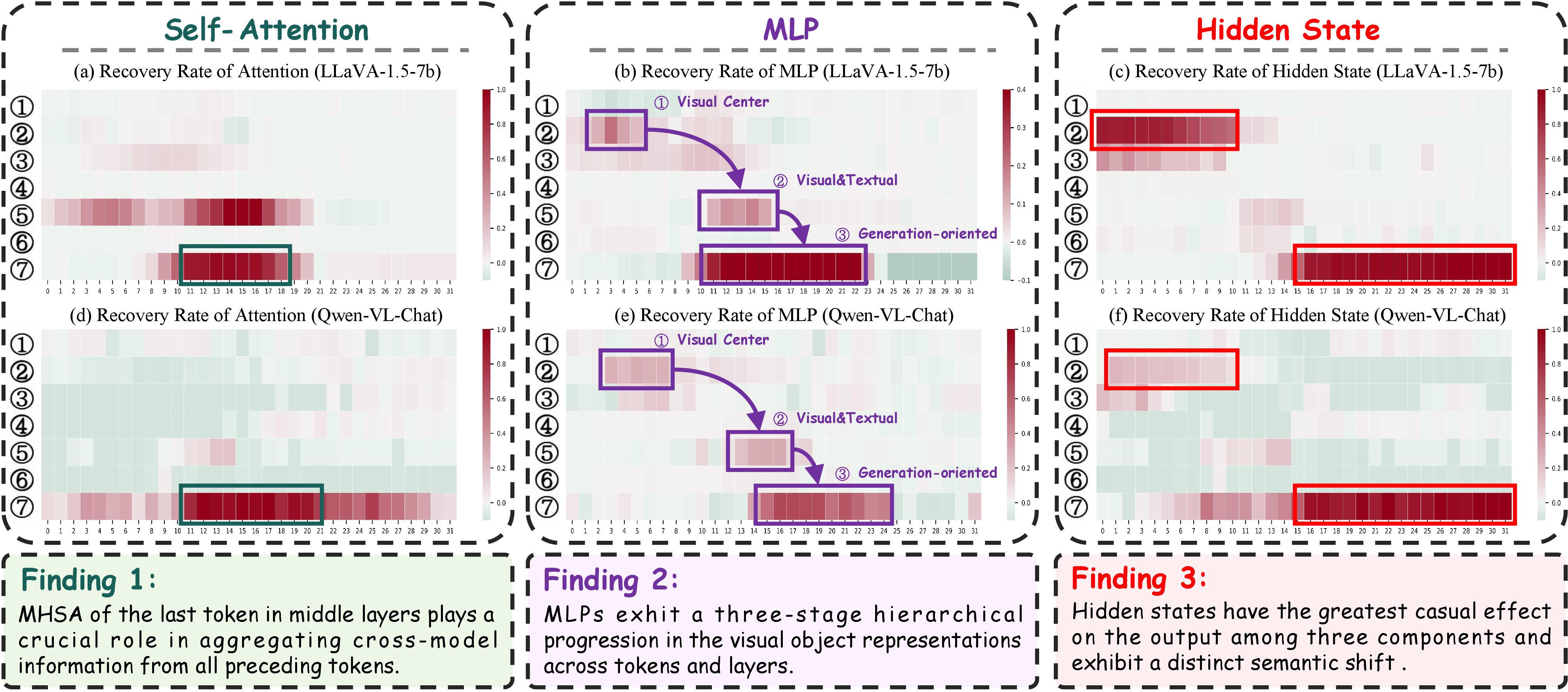
Figure 3: Results and key findings of FCCT framework on LLaVA-1.5-7b and Qwen-VL-Chat.
- Three-stage Hierarchy in MLPs: FFNs exhibit a three-stage progression: initial encoding in visual object tokens, interaction forming cross-modal semantics, and final aggregation into task-relevant representations.
- Hierarchical Semantic Shift: Hidden states reflect a shift from low-level visual patterns to cross-modal task-related information, underscoring a hierarchical organization within LVLMs.
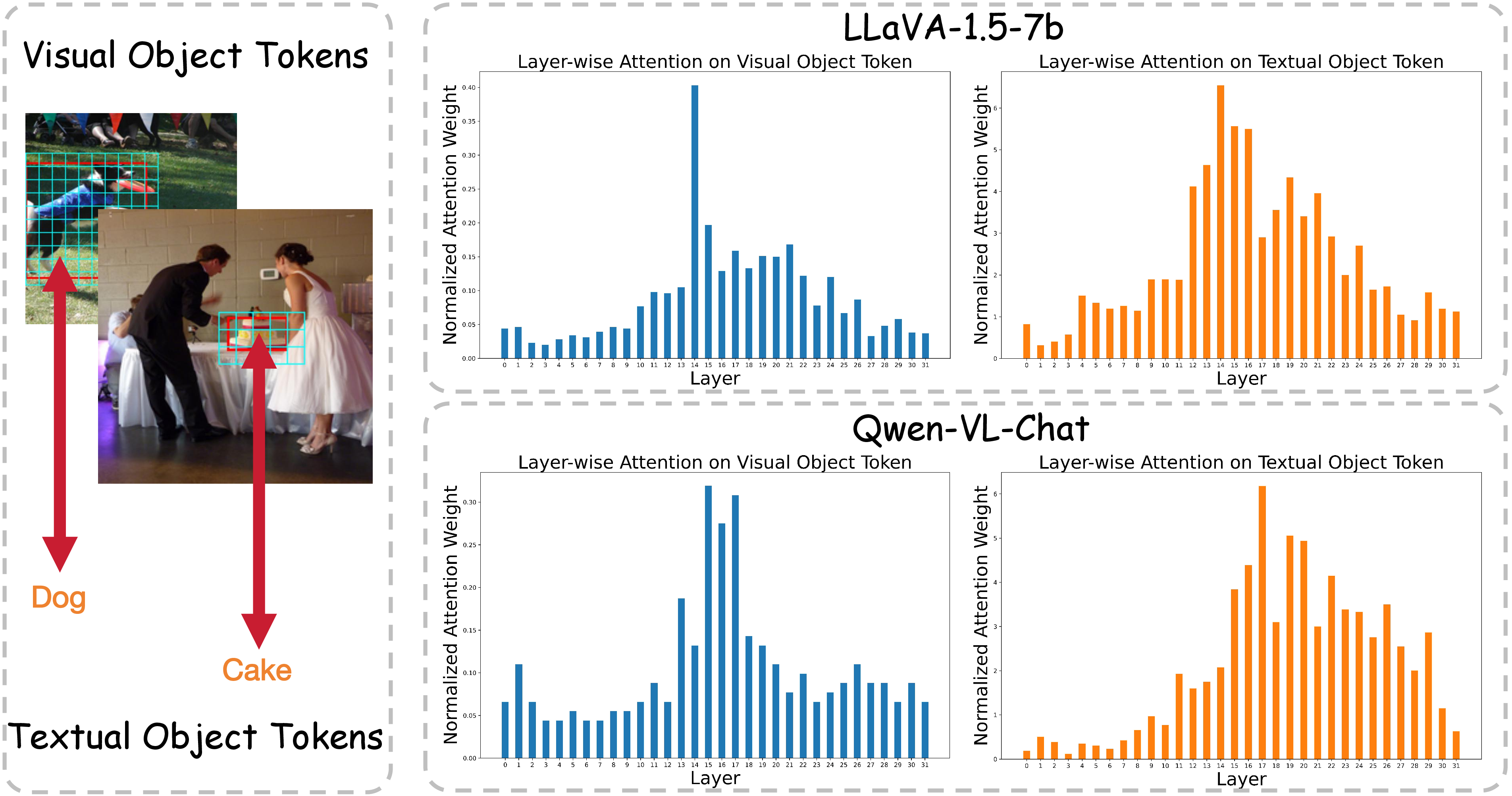
Figure 4: Visualization of normalized attention weights to visual object tokens and corresponding textual object tokens across layers.
Experimental Results
Empirical evaluations demonstrate IRI's outperformance of baselines across benchmarks like POPE, MME, CHAIR, and MMHal-Bench in mitigating hallucination while enhancing perception. IRI shows model-agnostic adaptability, confirmed through successful deployment on advanced LVLMs like Qwen2-VL-7B and InternVL2-8B.
Conclusion
FCCT advances the understanding of object representations in LVLMs, and IRI translates those insights into practical improvements in model reliability and performance. These contributions highlight the potential for theoretical findings to drive tangible advancements in vision-language integration, with IRI offering a scalable, effective means of hallucination mitigation in real-world AI applications.

