- The paper presents a design-to-vector paradigm that converts raw chip design data into structured, multi-level representations for ML tasks.
- It introduces a modular library architecture integrating flow engines, data APIs, and management workspaces to ensure high-fidelity, scalable vectorization.
- It demonstrates robust AI performance in EDA, with significant improvements in wirelength, delay, and congestion predictions across diverse chip designs.
AiEDA: An Open-Source AI-Aided Design Library for Design-to-Vector
Introduction and Motivation
The systematic integration of AI into electronic design automation (EDA), particularly for physical design, is hindered by fragmented infrastructures, heterogeneous toolchains, and a lack of standardized, machine-learning (ML)-ready data pipelines. Existing frameworks (such as OpenROAD, CircuitOps, and OpenLANE) provide only point solutions, primarily addressing tool flow orchestration or metric extraction, and generally lack comprehensive, scalable approaches to create unified, expressive representations of chip designs suitable for state-of-the-art learning methods. This fragmentation impedes high-throughput dataset generation, interoperability, and reproducibility, consequently slowing down progress in AI-aided design (AAD).
To address these pressing deficiencies, the AiEDA library formalizes the "design-to-vector" paradigm: a robust, hierarchical methodology for transforming all relevant chip design data—logical, physical, and timing—into universal, structured vector/matrix/tensor representations, spanning from system-level graphs to patch-based geometric primitives. This is complemented by iDATA, a multi-hundred-GB-scale dataset comprising 50 real 28nm chip designs, providing Foundation Data at multiple abstraction levels and facilitating benchmarking across prediction, optimization, and generative ML tasks.
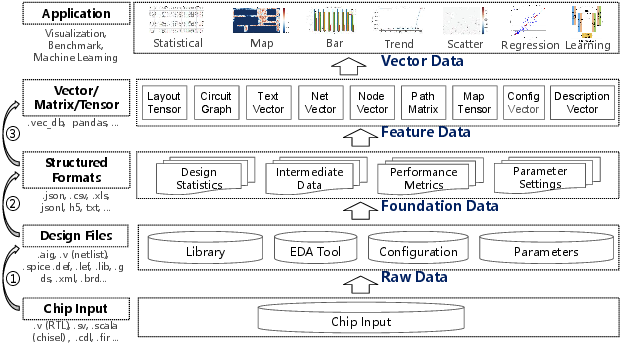
Figure 1: Data transformation pipeline for AI-aided design, illustrating the structured conversion from raw design data to AI-ready vector representations.
Design-to-Vector Paradigm
The design-to-vector process unifies the three key stages of data transformation:
- Raw Data Extraction: Parsing EDA-native outputs such as Verilog, DEF, and GDS into consistent internal representations.
- Foundation Data Construction: Near-lossless, structured representation (JSON, CSV, etc.) at multiple abstraction levels (netlist, layout, path, patch), explicitly engineered for maximal information retention and compatibility with downstream AI tasks.
- Feature/Vector Engineering: Task-specific conversion into tabular, sequential, spatial, or graph data for direct input into ML models.
The paradigm encompasses representations for both topology (graphs/hypergraphs for netlists, timing paths) and geometry (multi-channel tensors for layouts, rasterized maps for physical attributes) as illustrated in the comprehensive design-to-vector hierarchy.
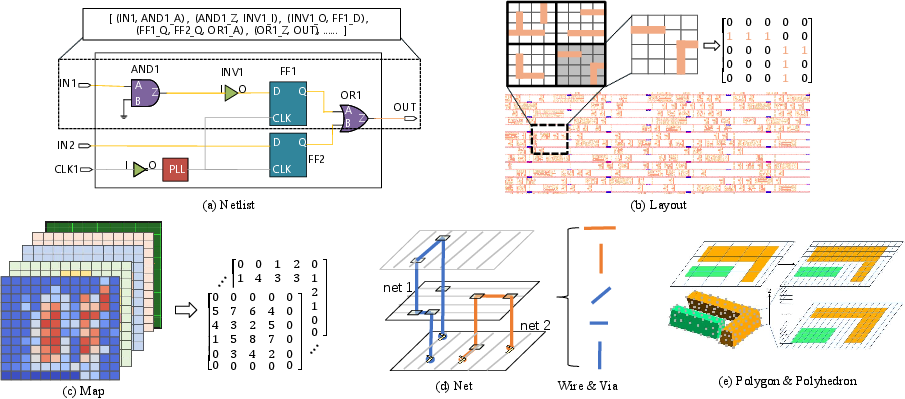
Figure 2: Examples of design-to-vector conversion across netlist, layout, metric maps, routing nets, and geometric shapes, accommodating diverse ML model requirements.
This approach enables reproducible, high-fidelity extraction of metrics and features, while maintaining the provenance and relationships necessary for cross-domain data fusion (e.g., timing-path extraction aligned with layout context).
AiEDA Library Architecture
AiEDA is a modular, extensible library with four primary system components: flow engines, data generation APIs, data management workspaces, and unified AI interfaces:
- Flow Engines: Integration with both open-source and commercial EDA tools, including OpenROAD, iEDA, and Innovus, enabling flexible orchestration of design flows and tool switching via standardized data exchange formats.
- Data Generation: Programmatic APIs for both executing EDA flows and extracting structured Foundation Data, with centralized configuration management and robust Python/C++ interop to enable batch processing.
- Data Management: Hierarchical workspace design that organizes design files, features, logs, and vector data for each chip instance, supporting scalable, multi-threaded operation (demonstrated up to 1.5TB DRAM and 32-thread CPUs).
- Downstream AI Application: Unified interfaces support feature engineering, dataset parsing, model selection, and evaluation. Process engines automate preparation of multi-level and multi-modal data for tabular, sequential, spatial, and graph-based ML models.
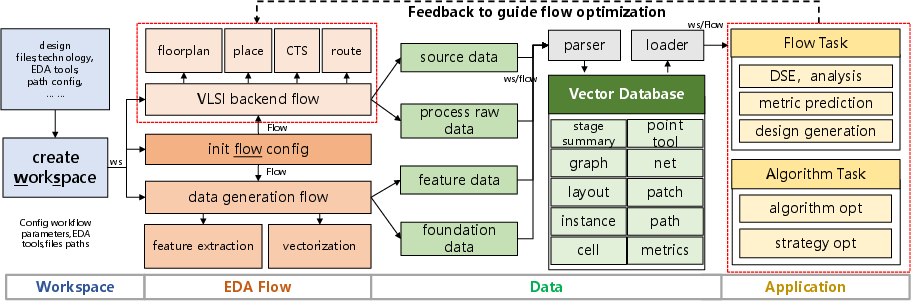
Figure 3: AiEDA library architecture, showing flow engine integration, data extraction, workspace management, and downstream feature/model interfaces.
Visualization and workflow traceability are supported by aieda.report for dynamic reporting and aieda.gui for layout inspection and patch/region interaction.
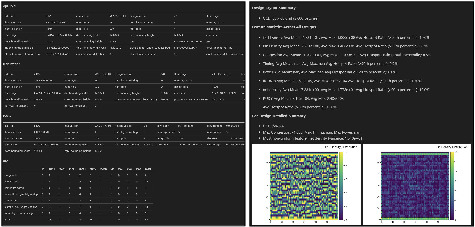
Figure 4: AiEDA.reporter module for automated, data-driven reporting and performance monitoring.
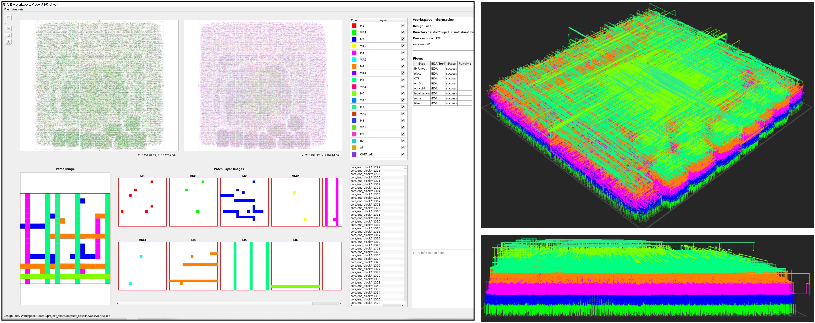
Figure 5: AiEDA.GUI interactive visualizer for hierarchical exploration of layouts, patches, and design versions.
iDATA: A Unified, Hierarchical Dataset
iDATA, generated via AiEDA, comprises Foundation Data at five hierarchical levels: design, net, graph, path, and patch. It covers a diverse array of real-world designs (DSP, interface, SoC, memory, CPU/GPU; 0.14K–4.8M cells), with scalable configuration for resolution and patch size. Each design is comprehensively decomposed, with data size for large chips exceeding tens of GB.
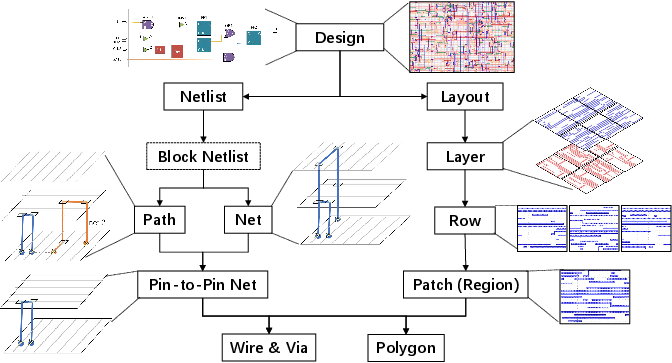
Figure 6: Multi-level design-to-vector framework for netlist, layout, graph, path, and patch representations.
File organization and content are strictly defined to support systematic downstream processing and benchmarking.
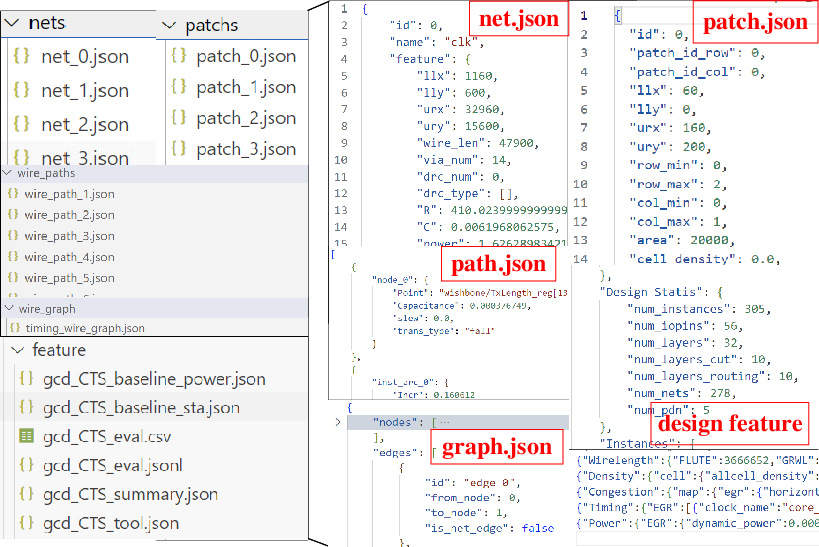
Figure 7: Hierarchical file organization structure for storing vectorized Foundation Data.
Fidelity Analysis: Reconstruction experiments demonstrate a negligible loss of accuracy—WNS and TNS fidelity ratios >0.97, power and DRC violation preservation—validating vectorization suitability for both ML training and EDA sign-off.
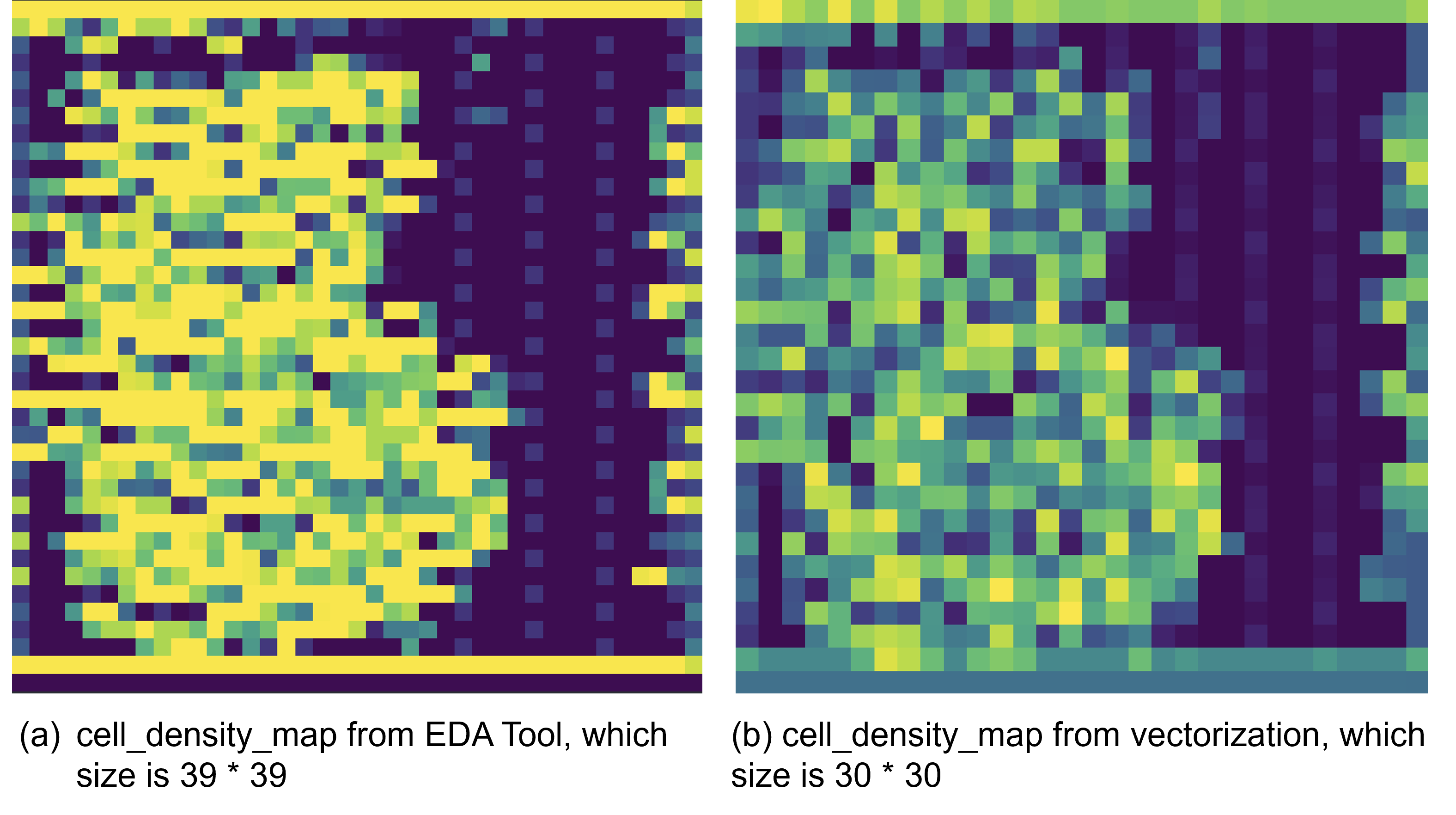
Figure 8: Patch-level fidelity comparison for the s713 design, confirming equivalency of spatial distributions after vectorization.
Statistical and correlation analyses reveal that the dataset preserves fundamental physical and electrical relationships, e.g., the strong linkage between HPWL and RWL across designs, wire density and congestion, and macro- to micro-level metrics.

Figure 9: Design-level core usage, pin, and cell-type statistics across the iDATA multi-design corpus.
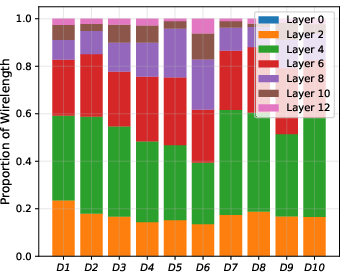
Figure 10: Net-level wirelength and correlation matrix of geometric/electrical parameters (RWL, HPWL, R, C, power, delay, slew).
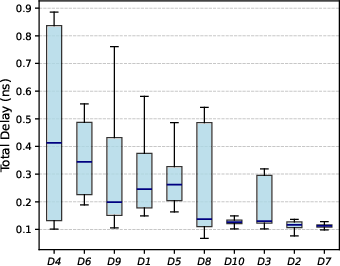
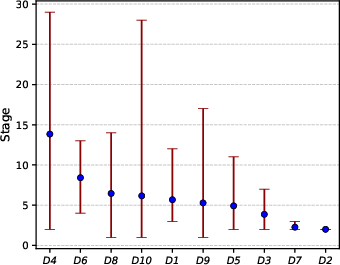
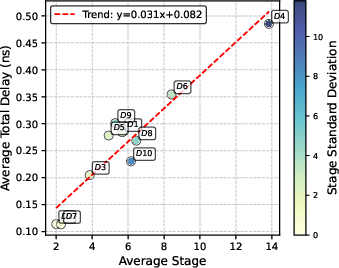
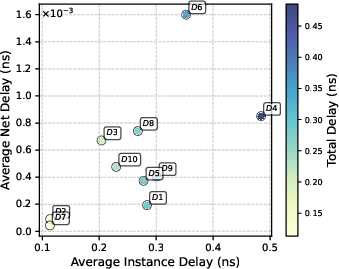
Figure 11: Path-level delay and stage statistics, demonstrating consistency and linear delay–stage correlation.
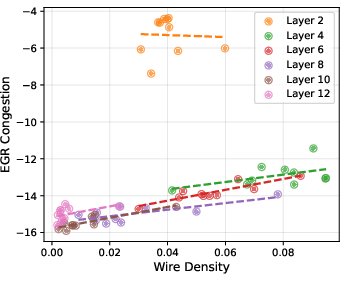
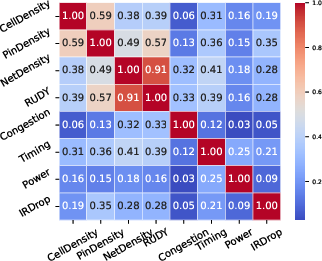
Figure 12: Patch-level analysis: regression and correlation between wire density, congestion, and other localized features.
By formalizing Foundation Data, iDATA enables substantial reductions in feature engineering and development effort for new ML tasks, as compared to prior approaches reliant on ad hoc parsing of raw tool outputs.

Figure 13: Comparative illustration of development effort for deriving AI-ready features from raw, foundation, or engineered data.
End-to-End AI-Aided Design Tasks
AiEDA natively supports prediction, generation, optimization, and analysis tasks, facilitating both classical and end-to-end AI-EDA workflows. A multi-stage data flow—from extraction to model training and feedback—is achieved, supporting closed-loop design-optimization integration.

Figure 14: Full AiEDA data flow pipeline, from EDA execution and feature extraction through AI model training to reinforcement in the physical design loop.
Net-Level Wirelength Prediction
Employing TabNet for estimating post-routing wirelength and via count from placement-stage features, a two-stage sequential model achieves robust R2=0.94 for via prediction and a 6% decrease in mean relative error (MRE) for wirelength via staged physical feature injection.
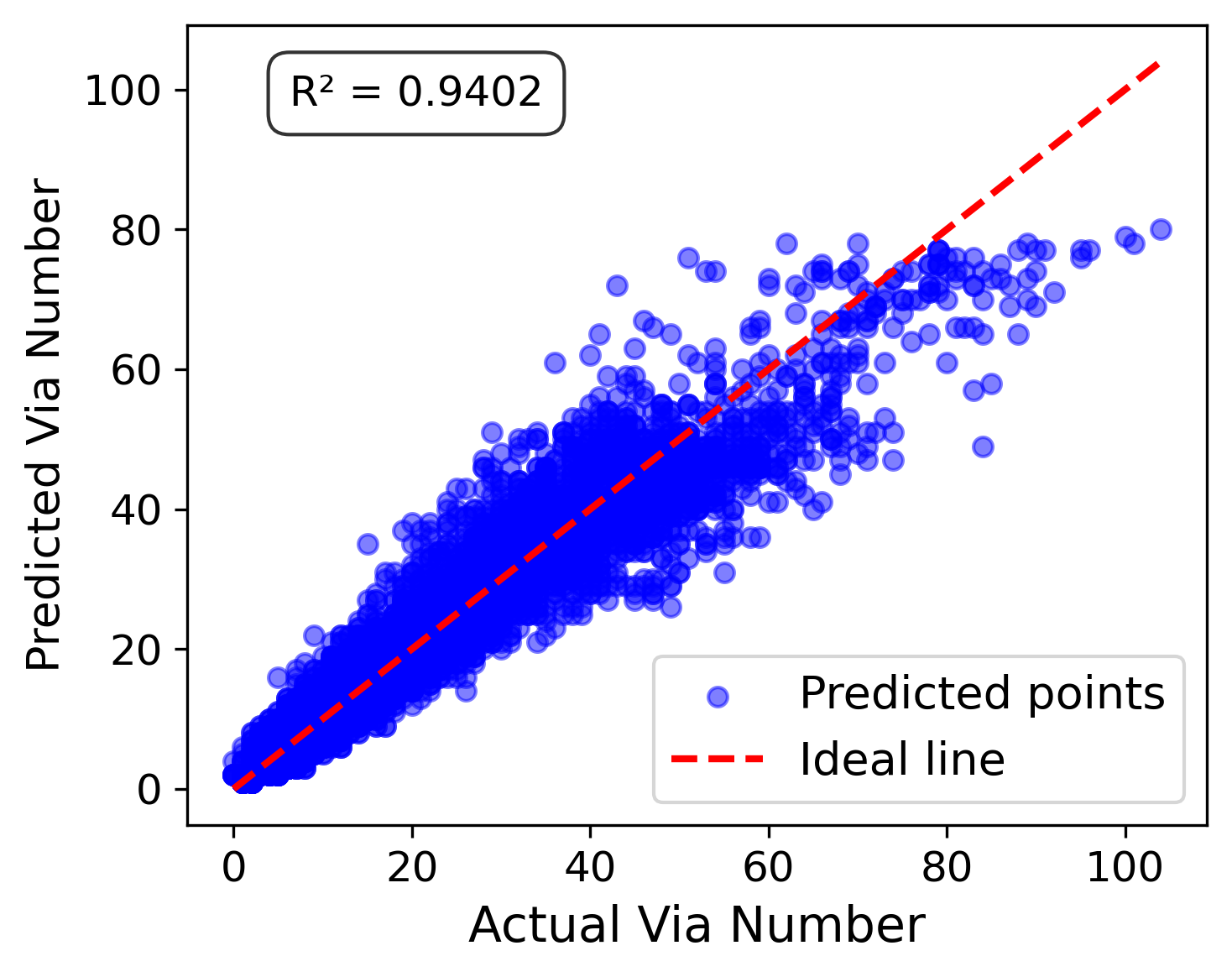
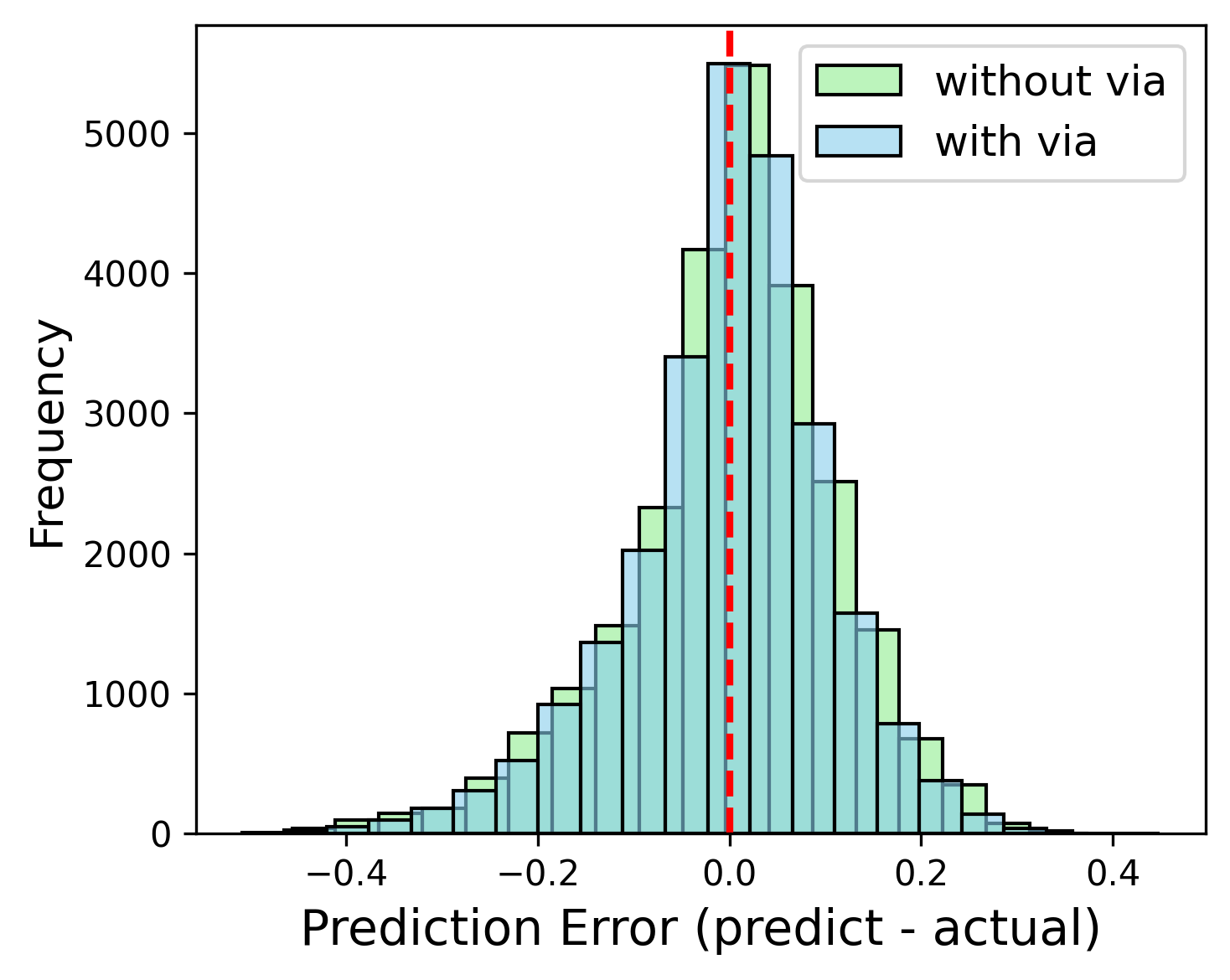
Figure 15: Net-level results: via count prediction (TabNet, R2=0.94) and comparative error distribution for wirelength ratio, with and without via features.
The trained model is exported as ONNX for seamless integration into iEDA's detailed placement optimization, exemplifying in-situ inference and bridging of AI with C++ tool chains.
Path- and Graph-Level Delay Prediction
For sequential timing path delay, a hierarchical Transformer with multi-scale feature fusion and gated residual networks surpasses vanilla attention models with MAE = 0.023 on independent test chips.
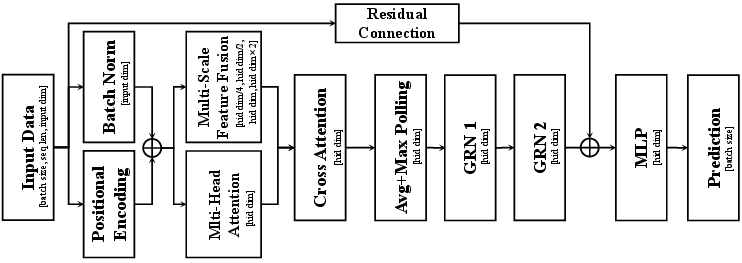
Figure 16: Transformer-based learning system for path delay prediction (R,C,slew input), with contextual attention and refinement.
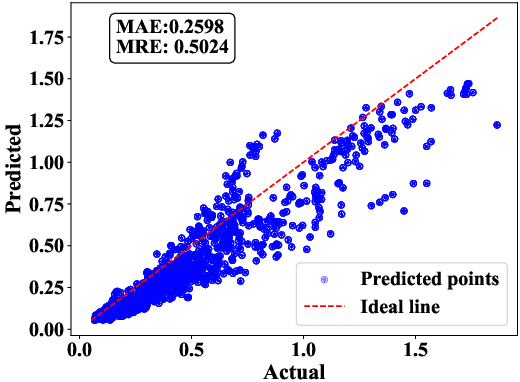
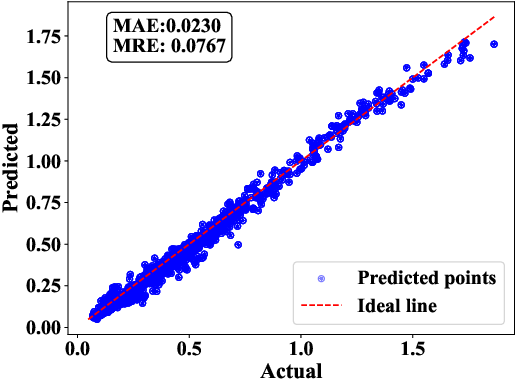
Figure 17: Validation of transformer variants on path delay tasks, showing quantitative improvement with architectural enhancements.
For graph-level node-wise propagation delay, a GIN-Transformer hybrid achieves lowest error (test MSE=0.025, R2=0.965) among GCN, GraphSAGE, and GIN, validating the necessity of injective graph aggregation for high-fidelity timing predictions.
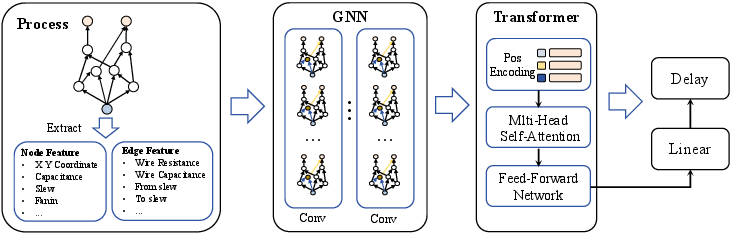
Figure 18: Graph-level learning framework for delay prediction over clock-tree/path subgraphs.
Patch-Level Congestion Prediction
A lightweight UNet (with sliding window and multi-scale attention) is used for spatial congestion prediction based on placement-era features. The model reaches NRMSE as low as 0.12 on large designs, preserving critical hot-spot patterns required for layout optimization.
Multi-modal Net and Map Generation
A U-Net based net routing map predictor fusing source/target point encodings and spatial patch features yields an IoU of 67% and F1-score of 81%, supporting early-stage congestion and routability prediction as well as look-ahead routing flows.
Design-Level Parameter Optimization
Tree-structured Parzen estimator (MOTPE) based design space exploration optimizes up to 11 placement parameters, improving key metrics (HPWL, WNS, TNS) with 8/10 designs showing HPWL improvement and universal timing closure benefits. Upscaling to >250k-cell designs enables HPWL reduction exceeding 50% in large-scale cases when optimized for a single objective (due to plascer runtime constraints).
(Figure 1, repeated)
Figure 1: Data transformation and flow, supporting AI-guided, closed-loop EDA optimization.
Implications and Future Directions
AiEDA, through a systematic design-to-vector abstraction and robust data+model infrastructure, removes major engineering and reproducibility barriers in AI-EDA. The hierarchical, information-rich Foundation Data, combined with a unified workspace and APIs, enables:
- Rapid prototyping and benchmarking of new AI models for diverse EDA tasks,
- Reproducible, fair comparison across toolchains and ML approaches,
- Efficient cross-domain data fusion (timing/physical/layout),
- Direct model deployment into EDA tools for online or offline optimization,
- Scalable processing across device nodes, abstraction levels, and design complexity.
Key numerical results demonstrate minimal fidelity loss in vectorization, high prediction accuracy (R2 > 0.93 for GNN+Transformer approaches), and substantial improvement in placement/routing metrics via learned models and parameter optimization.
Practically, AiEDA and iDATA provide an immediate foundation for community-driven benchmarking, rapid experimentation, and facilitate integration of advanced foundation models and generative AI paradigms into EDA scientific research. The modular design is extensible to additional engines, data types (e.g., analog/RF), and to emergent AI model classes.
Conclusion
AiEDA and the iDATA dataset constitute a critical step forward in bridging advanced AI techniques with real-world EDA workflows, providing an integrated, open-source backbone for research and deployment spanning raw physical design data to in-tool model inference. The design-to-vector pipeline and supporting infrastructure set a new standard for AI/EDA interoperability and scalability, fundamentally lowering the barrier to innovation and reproducible research in AAD. Ongoing and future work includes deeper coupling with placement/routing flows, expansion of the vectorization stack, acceleration of dataset creation pipelines, and broadening of downstream task coverage. The open-source release of AiEDA fosters community extension and paves the way toward a standardized, scalable AI-EDA ecosystem.

