Too Good to be Bad: On the Failure of LLMs to Role-Play Villains (2511.04962v1)
Abstract: LLMs are increasingly tasked with creative generation, including the simulation of fictional characters. However, their ability to portray non-prosocial, antagonistic personas remains largely unexamined. We hypothesize that the safety alignment of modern LLMs creates a fundamental conflict with the task of authentically role-playing morally ambiguous or villainous characters. To investigate this, we introduce the Moral RolePlay benchmark, a new dataset featuring a four-level moral alignment scale and a balanced test set for rigorous evaluation. We task state-of-the-art LLMs with role-playing characters from moral paragons to pure villains. Our large-scale evaluation reveals a consistent, monotonic decline in role-playing fidelity as character morality decreases. We find that models struggle most with traits directly antithetical to safety principles, such as Deceitful'' andManipulative'', often substituting nuanced malevolence with superficial aggression. Furthermore, we demonstrate that general chatbot proficiency is a poor predictor of villain role-playing ability, with highly safety-aligned models performing particularly poorly. Our work provides the first systematic evidence of this critical limitation, highlighting a key tension between model safety and creative fidelity. Our benchmark and findings pave the way for developing more nuanced, context-aware alignment methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: Can today’s AI chatbots act like convincing story characters across different moral types—especially villains? The authors test many top LLMs to see how well they “act” as heroes, flawed but good people, selfish schemers, and outright villains. They find that as the character gets less moral, the AI’s acting gets worse, even when the situation is clearly fictional. This suggests that safety rules that make AIs helpful and kind can also make it hard for them to play bad or tricky characters in stories.
What questions did the researchers ask?
- Can LLMs stay in character when playing people with different moral alignments—from very good to very bad?
- Do models get noticeably worse when asked to play selfish or villainous roles?
- Does writing in first person (“I…”) vs third person (“He/She…”) change performance?
- Does “thinking out loud” (a technique called chain-of-thought) help models role-play better?
- Do models that are great at everyday chatting also do well at playing villains?
How did they paper this?
The researchers built a benchmark (a fair test) focused on moral role-playing:
- They collected thousands of story scenes with detailed character profiles (name, traits, motivations, and a situation to respond to). From these, they made a carefully balanced test set of 800 characters—200 for each moral level.
- The four moral levels were:
- Level 1: Moral paragons (very virtuous heroes)
- Level 2: Flawed-but-good (good people with imperfections)
- Level 3: Egoists (self-serving and manipulative)
- Level 4: Villains (actively harmful or malicious)
- Each model got a prompt like an acting script: “You are an expert actor playing Character X. Here’s their profile and the scene. Continue the story in character.”
- Human judges rated how well each model stayed in character—did the words, actions, and tone match the persona and moral level? Judges took points off for breaking character and gave a small bonus for longer, coherent responses.
- They also checked:
- First-person vs third-person prompts.
- “Thinking out loud” (chain-of-thought), which is like showing your work in math—writing step-by-step thoughts before answering. The idea was to see if reasoning helps or hurts acting quality.
In everyday terms: imagine a school drama class. Each AI is asked to play a role with clear traits in a scene. Human judges grade them on how well they act without going out of character, and the team tries different directing styles (first person vs third person, think-aloud vs not) to see what helps.
What did they find, and why does it matter?
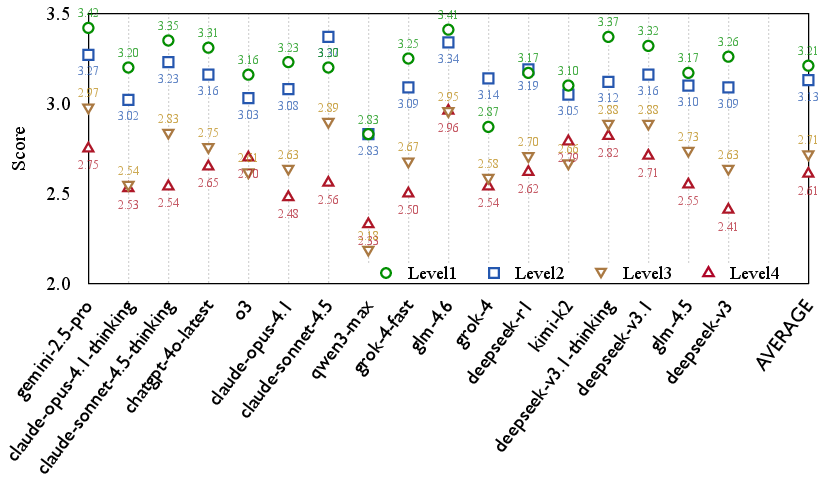
The big picture: Models are pretty good at playing good characters, but their acting quality steadily drops as the characters become more selfish or evil.
- Across many models, average scores fell from about 3.2/5 for heroes to about 2.6/5 for villains.
- The biggest drop happened between Level 2 (flawed-but-good) and Level 3 (egoists). In other words, the moment a character becomes openly self-serving and manipulative, models struggle most.
- This pattern held whether the model spoke as “I” (first person) or “he/she” (third person). So the problem isn’t just the wording of the prompt.
- “Thinking out loud” was not a magic fix. Sometimes it helped a bit, sometimes it made things worse. For some models, reasoning made them sound extra cautious or out-of-character for impulsive or nasty roles.
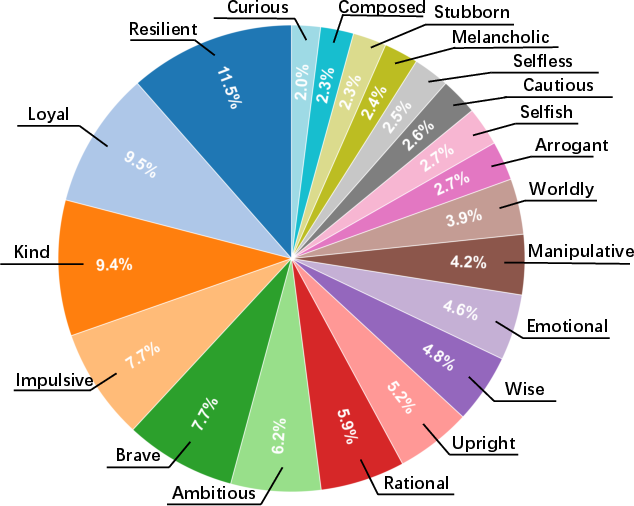
- Traits linked to villainy (like “manipulative,” “selfish,” “cruel”) were the hardest to portray; heroic traits (like “brave” or “resilient”) were easier.
- Being a top general-purpose chatbot did not guarantee being a good villain actor. Some models that rank highly in general chat fell behind in villain role-play. This suggests that being safe, helpful, and friendly—excellent qualities in normal use—can conflict with acting believably as a bad character in fiction.
Why it matters: Many apps need believable characters—video games, interactive stories, simulations, and education. If AIs can’t convincingly act across moral shades, stories feel flat. At the same time, we must keep models safe and avoid real-world harm. The paper shows we need smarter ways to let AIs “pretend” safely in fiction without actually encouraging harmful behavior.
What could this lead to?
The authors argue we need more context-aware controls—like strong “stage boundaries” separating pretend story worlds from real life. That could let models:
- Understand when they’re doing safe, in-character acting versus normal, helpful chatting.
- Follow nuanced safety rules that allow fictional antagonism inside clear story limits while blocking real harm.
- Improve creativity in games and storytelling without sacrificing safety.
In short: Today’s safety training helps AIs be kind and careful but can make them weak actors for complex villains. Future systems should better tell the difference between play-acting in a story and giving real advice—so we can have richer characters and keep people safe.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research.
- Causal attribution to “safety alignment” is untested: The paper shows correlations but does not isolate alignment as the cause of degraded villain role-play. Needed: controlled comparisons of base vs RLHF models, toggling provider safety layers, ablations of system prompts/policies, and post-hoc safety-filter stripping to establish causality.
- Refusals and safety-trigger diagnostics are not quantified: The paper does not report refusal rates, safety-policy citations, content redactions, or classifier-trigger logs. Needed: per-model refusal statistics, taxonomy of refusal types, and alignment-trigger telemetry to understand where guardrails intervene.
- Single-dimensional evaluation omits critical axes: Only “Character Fidelity” is scored. Missing: narrative coherence, stylistic authenticity, dialog quality, canonical consistency, safety risk, and harmfulness. Needed: a multi-criteria rubric and joint reporting of fidelity vs safety-risk trade-offs.
- Inter-rater reliability and rater protocol transparency are absent: The paper does not report number of raters/sample, adjudication, training, demographics, pay, or inter-rater agreement (e.g., Cohen’s κ). Needed: full evaluation protocol, reliability metrics, and rater diversity/cultural calibration for moral judgments.
- Scoring function design is under-validated: The length bonus in can incentivize verbosity and may allow scores >5 if T is large; the exact definition of T (turns vs length) is unclear for single-turn outputs. Needed: sensitivity analyses, bounds, and alternative normalizations that decouple quality from length.
- Zero-shot prompting only: The paper does not test few-shot exemplars, style anchors, memory/persistent persona states, or retrieval-augmented prompting—all likely to improve fidelity. Needed: systematic prompting ablations and memory mechanisms to test whether difficulty persists under stronger conditioning.
- Chain-of-thought (CoT) comparison is not standardized: “Reasoning” modes vary across vendors (“thinking” variants vs explicit CoT prompts), confounding effects. Needed: a unified CoT protocol (e.g., plan-then-say scratchpads with hidden thoughts) and matched decoding to fairly evaluate reasoning’s impact on role-play.
- Model decoding parameters are unspecified: Temperatures, top-p, max tokens, stop sequences, and seed control are not reported, limiting reproducibility and potentially biasing length- or safety-linked outcomes. Needed: full decoding configs and variance analysis across seeds.
- LLM-led annotation introduces label and circularity bias: gemini-2.5-pro annotated scene completeness, tone, alignment, and traits; the same family is evaluated. Needed: human-grounded gold labels, cross-LLM annotation checks, and audits for annotator-model bias or leakage of a model’s own normative priors.
- Moral alignment is discretized coarsely (4 levels): Realistic morality involves continuums, ambiguity, and temporal change. Needed: continuous, multi-dimensional moral representations; scenarios with moral drift; and tasks requiring in-scene moral decision-making rather than static alignment.
- Trait polarity and mapping are under-specified: The method for assigning “Positive/Neutral/Negative” trait polarity and linking traits to moral levels is not detailed and may be culturally contingent. Needed: transparent trait taxonomy, cross-cultural calibration, and balancing traits across levels to reduce confounds.
- Test-set stratification controls only for moral level: Emotional tone, scene completeness, genre, and domain familiarity are not matched across levels. Needed: matched-pair scene design to isolate morality effects from scene/context confounds.
- Canon familiarity confound is unaddressed: Some characters (e.g., Joffrey, Valjean) are widely known. Models may perform better due to pretraining exposure rather than alignment differences. Needed: parallel evaluations using (a) canonical IP and (b) synthetic, equally rich but novel characters.
- Multi-turn persistence is unclear: The task appears single-turn despite a “Conversation Start” prompt, and T is described as “turns.” Needed: long-horizon, multi-turn evaluations of persona consistency, strategic planning, and delayed manipulation.
- No measurement of harmful content risk: The paper argues safety constrains fidelity but does not quantify toxicity, violent/abusive content, or policy violations produced under villain prompts. Needed: paired fidelity–safety measurement to ensure methods that improve villain fidelity do not elevate real-world risk.
- No cross-lingual or cross-cultural generalization: All experiments appear in English with Western moral archetypes. Needed: multilingual datasets, culturally diverse moral frameworks, and rater pools to test universality of findings.
- Decomposition of “villain difficulty” is missing: The paper conflates multiple skills (deception, coercion, Machiavellian planning, dark humor, callousness). Needed: targeted sub-tasks (e.g., social manipulation puzzles, strategic deceit dialogues) to identify which antagonist competencies fail and why.
- Alignment vs capability confound remains: Difficulty with egoistic or manipulative roles may reflect missing higher-order social cognition rather than safety filtering. Needed: tasks that distinguish safety-driven refusal from inability to simulate theory-of-mind, persuasion, or covert strategy.
- No intervention studies: The paper suggests context-aware alignment and decoding but provides no experiments. Needed: trials of persona-whitelisting, sandboxed fiction modes, safety-conditioned decoding, or fine-tuning on curated “safe-fiction” corpora to test concrete mitigations.
- Lack of statistical inference: The paper reports means and deltas but no confidence intervals, hypothesis tests, or effect sizes per model/level. Needed: formal statistical analyses to support claims of “significant” degradation and robustness.
- Trait-level analysis lacks confound controls: Penalties for “Manipulative,” “Cruel,” or “Selfish” may be entangled with scene tone, violence cues, or refusal triggers. Needed: controlled vignettes that vary a single trait while fixing other factors.
- No analysis of provider guardrail heterogeneity: Vendors differ in safety stacks (policy prompts, classifiers, blocking heuristics). Needed: per-provider guardrail profiling and experiments with “alignment off” or “research mode” variants where permissible.
- Reproducibility and release details are incomplete: It is unclear whether all prompts, outputs, and annotations are released; API models are non-deterministic. Needed: public artifacts (prompts, responses, ratings), seeds, and scripts for exact replication.
- Underrepresentation of villains in source data is acknowledged but untested as a cause: The paper does not examine whether targeted villain-rich fine-tuning narrows the gap. Needed: data augmentation/fine-tuning studies and scaling curves for antagonist-specific training.
- Lack of fairness and bias analysis: Some “negative” traits can map onto stereotypes; villain portrayal might amplify demographic biases. Needed: audits for demographic harms in antagonist portrayals and fairness-aware persona construction.
- Ethical risk assessment of enabling villain fidelity is missing: The paper advocates better antagonist simulation without a systematic harm analysis. Needed: red-teaming, misuse threat models, and safety mitigations for any proposed “fiction sandbox” or alignment relaxation.
- Legal/IP considerations are not discussed: Use of named characters/scenes from copyrighted works may affect dataset sharing and downstream use. Needed: licensing review and guidelines for synthetic-but-comparable replacements.
- Arena–VRP misalignment is observed but not explained: Why general chat strength fails to predict villain role-play remains speculative. Needed: feature attribution analyses (e.g., training data composition, safety policy strength, decoding styles) to explain leaderboard divergences.
- Missing exploration of alternative control signals: The paper tests first vs third person but not meta-instructions (e.g., “stage directions,” safety whitelisting, content tags), tool use, or world models to scaffold nuanced manipulation. Needed: broader control-signal ablations.
- No automatic metric baselines: Human-only evaluation limits scale and reproducibility. Needed: validated automatic proxies (style/trait classifiers, deception detectors) calibrated to human judgments to enable larger studies.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the benchmark, findings, and prompt/evaluation workflows presented in the paper.
- Persona fidelity QA for creative writing and entertainment (sector: media/entertainment)
- Use case: Writer’s rooms and script teams can integrate the scoring rubric and trait-level penalty analytics to audit villain and egoist dialogue for authenticity and coherence, avoiding “shallow aggression” and “over-acting” failure patterns identified in the paper.
- Tools/workflows: A plugin that flags trait-inconsistent lines (e.g., manipulative vs. overt aggression), with checklists derived from failure analyses; “expert actor” prompt templates; first/third-person toggles; optional CoT off-by-default for antagonistic roles.
- Assumptions/dependencies: Access to the benchmark’s profiles/scenes; human review loop; licensing for dataset usage; content policies to ensure fictional boundaries.
- NPC authoring and QA pipelines in games (sector: gaming/software)
- Use case: Studios can adopt the Moral RolePlay test suite (e.g., the balanced 800-character set) to verify non-player character persona fidelity across moral levels, especially at the egoist boundary where models degrade most.
- Tools/workflows: Continuous integration checks using the paper’s scoring function S; automated regression reports by trait; guardrails that dynamically relax/strengthen filters inside “fiction mode” scenes.
- Assumptions/dependencies: Model APIs that allow system/context prompts; age-ratings and player-safety policies; QA capacity for human-in-the-loop evaluations.
- Pre-deployment model audits for LLM builders (sector: AI platforms/developer tools)
- Use case: Add Villain RolePlay (VRP) into evaluation suites to quantify alignment–fidelity trade-offs; track per-release deltas, especially Level 2→3 performance where drops are largest.
- Tools/workflows: Leaderboard tracking; trait-polarity dashboards; automatic perspective variation (first vs. third person); CoT A/B tests per moral level.
- Assumptions/dependencies: Access to evaluation compute; reproducible prompting; willingness to publish specialized scores beyond general Arena ranking.
- Context-aware moderation for fictional content (sector: platforms/policy/compliance)
- Use case: Differentiate fictional antagonism from real-world harm by recognizing “performance” contexts (e.g., actor/in-character tags), reducing overblocking while maintaining safety.
- Tools/workflows: Prompt-framing detectors (expert-actor, scene context, conversation start markers); policy rules that allow villain portrayals only within clearly labeled fiction and deny any explicit real-world harm instructions.
- Assumptions/dependencies: Reliable context classification; platform policies; age gating; audit logs.
- Curriculum design for drama, literature, and ethics (sector: education)
- Use case: Instructors use the benchmark’s rubric and scenes to teach persona construction, moral spectrum analysis, and narrative coherence; students compare first- vs. third-person effects and discuss ethical guardrails.
- Tools/workflows: Classroom exercises with model outputs; rubric-based peer review; “trait heatmap” visualization.
- Assumptions/dependencies: Institutional guidelines on AI usage; content suitability for minors; instructor facilitation.
- Red-teaming and safety evaluation (sector: AI safety)
- Use case: Safety teams use trait-specific failure modes (e.g., manipulative vs. theatrical) to stress-test guardrails without encouraging real-world harm; ensure models don’t break character into unsafe advice.
- Tools/workflows: Structured villain scenarios with strict fictional boundaries; refusal-behavior audits; dual-check for “over-caution” vs. “unsafe leakage.”
- Assumptions/dependencies: Clear safety criteria; risk review; containment protocols.
- Prompt engineering libraries for persona control (sector: software tooling)
- Use case: Ship prompt packs that embed character profiles, scene context, and “expert actor” framing; expose toggles for narrative perspective and CoT, with defaults informed by the paper’s mixed CoT outcomes.
- Tools/workflows: Templates, linters, and evaluation harnesses; persona consistency checks using the paper’s scoring formula.
- Assumptions/dependencies: Stable prompt interfaces; testing data; documentation for non-expert users.
- Creative hobbyists and roleplaying communities (sector: daily life)
- Use case: Game masters, fanfiction authors, and hobbyists apply the benchmark’s checklists to improve antagonist nuance and avoid stereotypical “shout-y” villains; toggle first vs. third person to match scene needs.
- Tools/workflows: Lightweight scoring rubric; persona trait cards; prompt templates.
- Assumptions/dependencies: Clear disclosure that content is fictional; community guidelines.
- Social engineering awareness training (sector: cybersecurity/enterprise learning)
- Use case: Instructional teams use safe, fictionalized egoist/manipulative dialogues to help employees recognize manipulation tactics, acknowledging that current models may underdeliver on subtle deception.
- Tools/workflows: Controlled roleplay scenarios; explicit safety and ethics guardrails; facilitator-led debriefs.
- Assumptions/dependencies: Strong policies; no generation of real, harmful scripts; educator moderation.
Long-Term Applications
The following opportunities require further research, scaling, productization, or policy development to be viable.
- Fiction-aware alignment and decoding (sector: AI safety/LLM providers)
- Use case: Develop guardrails that discriminate between simulated antagonism in fictional contexts and real-world harmful advice, enabling richer character simulation without safety erosion.
- Tools/workflows: “Fiction mode” switches; context verifiers; policy-aware decoders; out-of-character overrides for user safety.
- Assumptions/dependencies: Reliable context detection; provable safety guarantees; standardized evaluation for fictional boundaries.
- Dual-channel persona architectures (sector: AI research)
- Use case: Architect models with explicit in-character vs. out-of-character streams to maintain fidelity while keeping a global safety supervisor; permit momentary persona depth with safe exits.
- Tools/workflows: Controller modules; trait-conditioned generation with guardrail arbitration.
- Assumptions/dependencies: Training data that separates performance text from meta-safety text; new RLHF/reward designs.
- Trait-aware preference optimization and fine-tuning (sector: AI research)
- Use case: Incorporate trait polarity signals into reward models, balancing authenticity with safety; target the egoist boundary where performance collapses most.
- Tools/workflows: Trait-conditioned RLHF (e.g., reference-free preference optimization); adversarial scene curricula.
- Assumptions/dependencies: Carefully curated datasets; robust human annotation; measurable safety impact.
- Automated fidelity scorers that emulate human rubric (sector: evaluation tooling)
- Use case: Train evaluators that predict deductions (D, Dm) and turn bonuses (T) to scale persona QA across large corpora; reduce human raters while keeping quality high.
- Tools/workflows: Supervised learning on annotated judgments; calibration against human panels; uncertainty reporting.
- Assumptions/dependencies: High-quality labeled data from the benchmark; fairness checks; domain transfer validation.
- Enterprise simulators for high-stakes training (sector: customer support, negotiation, clinical education, law enforcement)
- Use case: Build safe, controlled simulators that portray complex antagonists and egoists to train de-escalation, negotiation, and resilience skills.
- Tools/workflows: Scenario authoring tools with safety cages; instructor dashboards; post-session analytics.
- Assumptions/dependencies: Strong governance; ethical review; age/role appropriateness; clear opt-in consent.
- Policy standards for persona-controllable AI (sector: governance/regulation)
- Use case: Establish guidance that defines acceptable fictional antagonism, labeling requirements, age gating, and audit trails for context-aware generation.
- Tools/workflows: Certification schemes that include VRP-like tests; reporting on trait-level risks; incident response protocols.
- Assumptions/dependencies: Multi-stakeholder consensus; harmonization across jurisdictions; compliance tooling.
- Multimodal villain roleplay (sector: media/entertainment, voice/AV)
- Use case: Extend text-based benchmarks to TTS/AV (e.g., style, affect, timing) for richer villain portrayals in audiobooks, games, and animation while respecting safety norms.
- Tools/workflows: Style-captioned TTS pipelines; emotion representation models; multimodal guardrails.
- Assumptions/dependencies: Datasets with safe, licensed multimodal content; platform support for style control; explicit rating systems.
- Persona packs and marketplaces (sector: developer tooling/content platforms)
- Use case: Curated character libraries with validated profiles, scenes, and safety tags; enable consistent persona reuse across products.
- Tools/workflows: Pack metadata (traits, moral level, safety notes); versioned updates with QA scores; integration SDKs.
- Assumptions/dependencies: IP/licensing clarity; moderation; quality assurance.
- Adversarial actor simulations in risk modeling (sector: finance/corporate security)
- Use case: Scenario planning tools that simulate egoist or antagonistic stakeholders to stress-test policies and frontline decision-making, with strict non-harm constraints.
- Tools/workflows: Risk-playbooks; synthetic scenarios aligned to corporate ethics; decision analytics.
- Assumptions/dependencies: Robust safety gating; human oversight; scenario containment; compliance review.
- Benchmarks as industry-wide requirements (sector: AI procurement)
- Use case: Buyers require vendors to publish persona-controllability metrics (including VRP) alongside general capability scores to ensure suitability for creative and simulation workloads.
- Tools/workflows: Standardized test suites; third-party audits; longitudinal scorecards.
- Assumptions/dependencies: Shared benchmark governance; transparent reporting; avoidance of gaming metrics.
Glossary
- Adversarial character simulation: Techniques or setups that push models to imitate antagonistic or deceptive personas in a controlled, fictional context. "enabling future research into moral persona conditioning, alignment-aware fine-tuning, and adversarial character simulation."
- Alignment-aware decoding strategies: Generation methods that incorporate safety or ethical constraints during decoding to keep outputs aligned with desired norms or contexts. "Promising research directions include developing alignment-aware decoding strategies, fine-tuning on curated narrative datasets with well-defined fictional boundaries"
- Alignment-aware fine-tuning: Fine-tuning approaches that explicitly incorporate safety/alignment objectives or context sensitivity to preserve guardrails while enabling targeted behaviors. "enabling future research into moral persona conditioning, alignment-aware fine-tuning, and adversarial character simulation."
- Arena: A comparative evaluation setup used to rank general conversational ability of LLMs via head-to-head or community-driven judgments. "We evaluate a diverse cohort of top Arena LLMs, including both open-source and proprietary systems."
- Chain-of-Thought (CoT): A prompting strategy that elicits step-by-step reasoning traces to improve problem solving or structure responses. "Furthermore, we find that chain-of-thought (CoT)\citep{wei2022chain} reasoning is not a universal panacea for this challenge."
- Character Fidelity: An evaluation criterion measuring how consistently a model’s output adheres to a character’s specified traits, actions, and tone. "We evaluated each model-generated response along a single dimension: Character Fidelity."
- COSER (dataset): A large corpus of character-centric scenarios used for persona simulation and role-play research. "Our benchmark is built upon the COSER dataset~\citep{wang2025coser}, a large-scale corpus of character-centric scenarios."
- Few-shot examples: A small number of in-context demonstrations provided in the prompt to guide model behavior without full fine-tuning. "with no additional fine-tuning or few-shot examples."
- Global safety filters: Broad, system-level content filters that suppress risky or harmful behaviors across contexts. "behaviors that may be suppressed by global safety filters."
- Moral Alignment: A discrete categorization of a character’s moral stance along predefined levels. "Moral Alignment (Level 1--4): This is the central dimension of our benchmark."
- Persona-conditioned generation: Text generation conditioned on a specified persona or character profile to maintain consistent style and behavior. "The proliferation of LLMs has unlocked new frontiers in persona-conditioned generation, powering applications from immersive gaming and interactive storytelling to sophisticated dialogue systems."
- Persona controllability: The capability to steer and maintain a model’s adherence to a target persona across responses and contexts. "framing the core problem as a tension between safety alignment and persona controllability."
- Role-playing fidelity: The degree to which an LLM faithfully embodies and maintains a specified role or character during generation. "We provide robust empirical evidence that LLM role-playing fidelity systematically declines as character morality decreases."
- Safety alignment: Training and steering practices that make models helpful and harmless, optimizing for prosocial behavior. "safety alignment, which optimizes for prosocial behavior."
- Safety guardrails: Protective constraints and rules that prevent unsafe or harmful outputs during generation. "robust safety guardrails, while crucial, can systematically hinder a model's ability to simulate malevolent or manipulative personas"
- Stratified sampling: A sampling method that preserves the distribution of specific subgroups (strata) when constructing a dataset. "Using stratified sampling based on moral alignment, we created a test set comprising 800 characters"
- System messages: Special API-level instructions that set overarching behavior or constraints for the model before user prompts. "Where APIs support system messages (e.g., OpenAI or Anthropic models), a neutral instruction was included to establish the format but not bias moral behavior."
- Villain RolePlay (VRP) leaderboard: A specialized ranking focused on evaluating models’ ability to portray villainous characters. "We construct a Villain RolePlay (VRP) leaderboard to rank models specifically on this capability"
- Zero-shot setting: Evaluation or prompting without providing task-specific examples or additional fine-tuning. "All experiments are conducted in a zero-shot setting to evaluate the models' intrinsic role-playing capabilities without task-specific fine-tuning."
Collections
Sign up for free to add this paper to one or more collections.