Dark Energy Survey Year 3 results: Simulation-based $w$CDM inference from weak lensing and galaxy clustering maps with deep learning. I. Analysis design
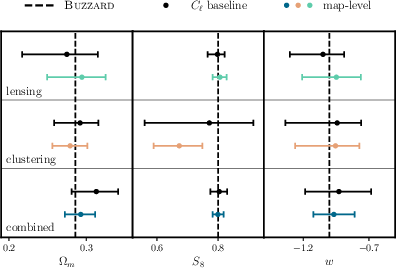
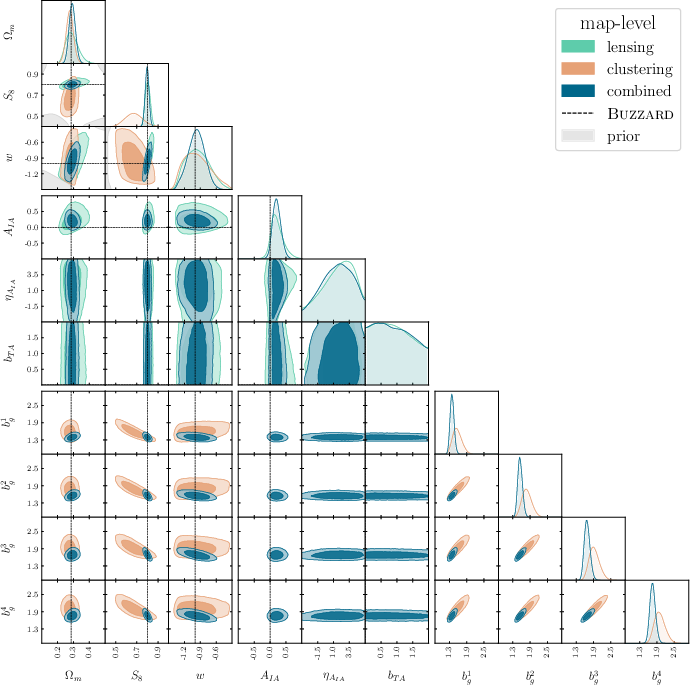
Abstract: Data-driven approaches using deep learning are emerging as powerful techniques to extract non-Gaussian information from cosmological large-scale structure. This work presents the first simulation-based inference (SBI) pipeline that combines weak lensing and galaxy clustering maps in a realistic Dark Energy Survey Year 3 (DES Y3) configuration and serves as preparation for a forthcoming analysis of the survey data. We develop a scalable forward model based on the CosmoGridV1 suite of N-body simulations to generate over one million self-consistent mock realizations of DES Y3 at the map level. Leveraging this large dataset, we train deep graph convolutional neural networks on the full survey footprint in spherical geometry to learn low-dimensional features that approximately maximize mutual information with target parameters. These learned compressions enable neural density estimation of the implicit likelihood via normalizing flows in a ten-dimensional parameter space spanning cosmological $w$CDM, intrinsic alignment, and linear galaxy bias parameters, while marginalizing over baryonic, photometric redshift, and shear bias nuisances. To ensure robustness, we extensively validate our inference pipeline using synthetic observations derived from both systematic contaminations in our forward model and independent Buzzard galaxy catalogs. Our forecasts yield significant improvements in cosmological parameter constraints, achieving $2-3\times$ higher figures of merit in the $\Omega_m - S_8$ plane relative to our implementation of baseline two-point statistics and effectively breaking parameter degeneracies through probe combination. These results demonstrate the potential of SBI analyses powered by deep learning for upcoming Stage-IV wide-field imaging surveys.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper designs and tests a new way to learn about the Universe using maps of the sky. The team uses deep learning (a type of artificial intelligence) and very large computer simulations to study how matter is spread out across the cosmos. They focus on two kinds of sky maps from the Dark Energy Survey (DES), Year 3:
- Weak lensing: tiny distortions in galaxy shapes caused by gravity bending light.
- Galaxy clustering: where galaxies tend to group together, like cities on a map.
Their goal is to better estimate key cosmic numbers—especially the dark energy parameter and how clumpy matter is—by teaching an AI to spot complex patterns in these maps that traditional methods miss.
What questions did the researchers ask?
They set out to answer simple but big questions:
- Can AI find extra information in sky maps that standard techniques overlook?
- If we combine weak lensing with galaxy clustering, can we break “confusing overlaps” (degeneracies) between parameters and measure them more precisely?
- Can we safely trust these AI-driven results, even when data has realistic errors and complexities?
- How much better are the results than traditional methods that only look at pairs of points (called two-point statistics)?
How did they study it?
They used several steps, explained in everyday terms:
1) Simulating many possible Universes
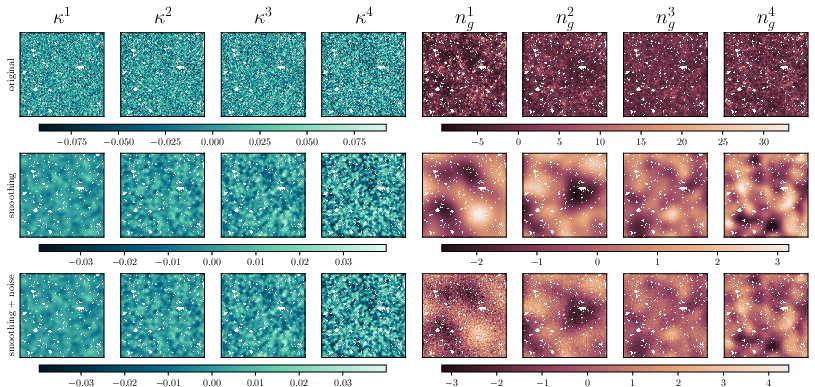
Imagine a super detailed video game sandbox that lets you change the rules of the Universe. The team used a large simulation suite called CosmoGridV1 to create over a million mock sky maps. Each map shows where matter might be and what the galaxies would look like under different cosmic settings (like different amounts of matter, different dark energy , etc.).
- N-body simulations: think of millions of tiny “mass dots” moving under gravity. This builds realistic structures like cosmic “webs” of matter.
- Baryonification: real galaxies and gas can push matter around. The team applied a model that tweaks the simulations to mimic these effects, so the maps look more like the real sky.
2) Making the maps match DES observations
They carefully shaped the simulated maps to match key features of the DES Year 3 data (like the area of the sky covered, how many galaxies are seen, and how their distances are estimated). They also added realistic “noise” (like shape measurement errors and uncertainties in galaxy distances).
- Weak lensing explained: like looking through slightly uneven glass—background galaxies appear a tiny bit stretched or squashed by the gravity of matter in the foreground.
- Galaxy clustering explained: galaxies aren’t spread evenly; they form patterns, similar to how towns cluster along rivers or roads.
3) Teaching AI to read the sky
Instead of picking a few simple measurements, the team used deep graph convolutional neural networks built for sphere-shaped data (like a globe). These networks learn to compress giant sky maps into a few “smart features”—numbers that keep most of the important information.
- Think of it like summarizing a huge book into a short review that still captures the key points.
- These compressed features are designed to keep what’s most informative about the Universe.
4) Estimating the parameters
After compression, they used a method called “normalizing flows” (a flexible statistical model) to learn the likelihood—basically, how likely different settings of the Universe are given the features the AI found. This is called simulation-based inference: instead of writing the math for how data connects to theory (which is very hard here), they let the simulations and AI learn that relationship directly.
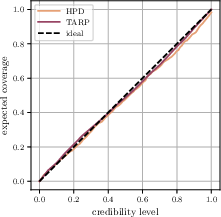
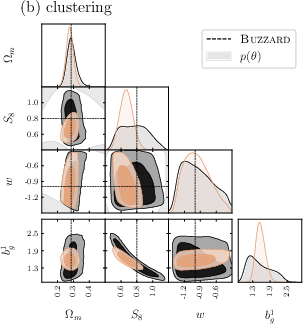
5) Checking reliability
They tested the pipeline with many kinds of “fake observations,” including independent mock catalogs (Buzzard) and maps with known systematics (like errors in galaxy distances or shape measurements). This checks that the method is robust and doesn’t get fooled by tricky details.
What did they find and why is it important?
- Their AI-powered approach pulls out extra, “non-Gaussian” information from the maps—complex patterns beyond simple averages or pairwise relationships.
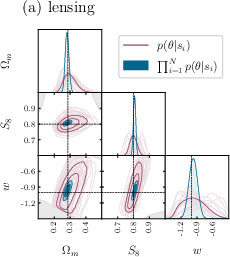
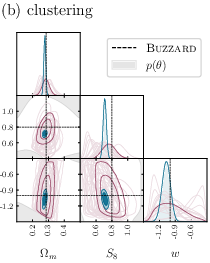
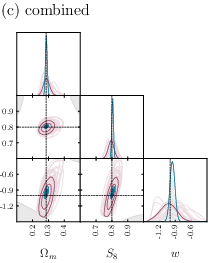
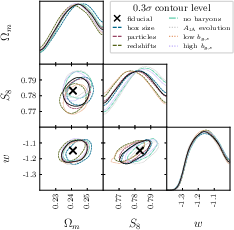
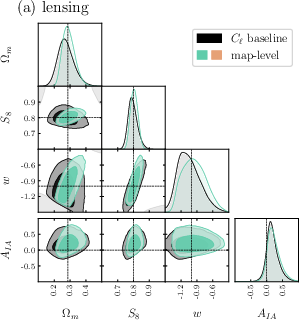
- Compared to traditional two-point statistics, their forecasts show 2 to 3 times better precision for key parameters (especially in the plane, which summarizes how much matter there is and how clumpy it is).
- Combining weak lensing and galaxy clustering helps break degeneracies—cases where different parameter combinations look too similar—leading to more confident measurements.
- The pipeline appears robust: it works well across various simulated conditions and realistic errors.
This is important because better measurements help us understand dark energy (through ), matter content, and the growth of cosmic structure. It’s a step toward solving how and why the Universe is expanding the way it is.
What does this mean for the future?
This work shows that deep learning plus simulation-based inference can make the most of modern sky surveys. As upcoming “Stage-IV” surveys (like LSST, Euclid, and Roman) gather far more data, methods like this could:
- Sharpen our measurements of dark energy and the matter in the Universe.
- Use more of the information in the data by capturing complex patterns.
- Provide strong, combined analyses from multiple probes (lensing, clustering, and more).
In short: the paper lays the groundwork for smarter, more powerful cosmic measurements, using AI to learn directly from realistic simulations. The team designed and validated an end-to-end approach; using it on the actual DES Year 3 data will come next in a companion paper.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper outlines a simulation-based, deep-learning pipeline for DES Y3 weak lensing and galaxy clustering but leaves several aspects missing, uncertain, or unexplored. Future researchers could address the following concrete gaps:
- Real-data application and calibration are deferred
- The pipeline is validated on synthetic mocks only; performance on the actual DES Y3 observations (including coverage, calibration, and posterior reliability) is not demonstrated.
- Simulation-based calibration (SBC), coverage tests, and posterior predictive checks across the full parameter space are not reported.
- Restricted cosmological model space
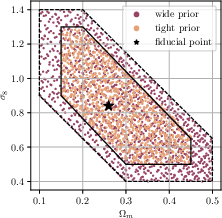
- The analysis is limited to flat, constant- models with fixed neutrino mass ( eV) and no curvature; sensitivity to dynamical dark energy (–), spatial curvature, and varying neutrino masses remains unexplored.
- The pipeline marginalizes over , , and using priors but does not infer them; potential biases from incorrect priors or cosmology misspecification are not quantified.
- Born approximation and higher-order lensing effects
- The forward model assumes the Born approximation and ignores lens–lens coupling, reduced shear, and source clustering; the impact of these approximations on learned summaries and inferred parameters is not assessed.
- A ray-tracing comparison or inclusion of beyond-Born corrections is absent.
- Baryonification model limitations
- Baryonic feedback is modeled by varying only and its redshift exponent ; other influential parameters (e.g., stellar/halo fractions, gas ejection efficiencies) are fixed, and model misspecification risks are not fully tested.
- The CosmoGrid resolution resolves halos down to ≈, potentially missing small-scale baryonic effects; the resulting bias on constraints is not quantified.
- Cross-validation against multiple hydrodynamical suites (e.g., IllustrisTNG, EAGLE, BAHAMAS) across redshift and mass scales is absent.
- Intrinsic alignment (IA) modeling is simplified
- The IA kernel resembles NLA-like modeling; more complete TATT (tidal alignment + tidal torquing), luminosity/morphology dependence, and redshift evolution are not fully incorporated or validated.
- Potential biases from IA model misspecification and IA–baryon degeneracies in map-level summaries are not characterized.
- Galaxy bias modeling is too simplistic
- Only linear galaxy bias ( per tomographic bin) is used; scale-dependent, non-linear, and stochastic bias (including assembly bias) are not modeled.
- No halo occupation distribution (HOD) or hybrid galaxy assignment is included in the forward model; mismatch with realistic galaxy formation (as in Buzzard) is only partially addressed.
- Photometric redshift uncertainty treatment is coarse
- Photo- uncertainties are modeled via Gaussian shifts/stretch per bin; non-Gaussian tails, catastrophic outliers, and spatially varying systematics are not included.
- Integration of the full SOMPZ redshift posterior or hierarchical photo- modeling is absent.
- Shear calibration systematics are incomplete
- Only multiplicative shear biases ( per bin) are modeled; additive shear biases, PSF residuals, spatially varying calibration, and selection effects beyond simple are not simulated.
- The impact of B-mode leakage, mask-induced E/B mixing, and the inverse/forward Kaiser–Squires steps on the summaries and inference is not quantified.
- Survey systematics in clustering maps are under-modeled
- Depth/seeing variations, stellar contamination, spatial selection functions, and magnification bias are not explicitly modeled or stress-tested.
- RSD-like effects are ignored in projected maps; their indirect impact on angular clustering is not investigated.
- Noise and weighting realism
- Shape noise maps from scrambled catalogs may miss spatially varying weights, blending-induced correlations, and depth-driven anisotropies present in real data.
- The effect of anisotropic noise on the learned compressions and inferred posteriors is not quantified.
- Training-set design and density across parameter space
- The Sobol grid may be sparse near high-curvature regions of the likelihood; the impact of grid density and boundary effects on normalizing flow learning is not assessed.
- Adaptive sampling (e.g., sequential neural likelihood, active learning) to target high-posterior regions is not explored.
- Neural likelihood modeling and uncertainty quantification
- Calibration of normalizing flows (e.g., tails, multi-modality) and sensitivity to architecture/hyperparameters is not documented.
- Epistemic uncertainty in learned summaries and likelihoods (e.g., via ensembles or Bayesian NNs) and out-of-distribution (OOD) detection for real data are not implemented.
- Robustness to domain shift and model misspecification
- Validation relies mainly on Buzzard catalogs; broader stress tests using diverse mocks with different baryonic physics, galaxy assignment, and IA prescriptions are missing.
- Sensitivity of constraints to mismatches between CosmoGrid+baryonification and independent hydrodynamic/empirical models needs systematic quantification.
- Interpretability and physics-motivated diagnostics
- Learned features from graph CNNs are opaque; saliency analyses, response to filtered maps, and comparisons to known non-Gaussian statistics (peaks, Minkowski functionals, higher moments) are not provided.
- Diagnostics linking scale ranges or morphological features to the observed gains in the – plane are lacking.
- Scale cuts and information localization
- The specific angular/multipole scales driving 2–3× improvements are not identified; robustness of gains to conservative vs aggressive scale cuts is not analyzed.
- Interaction between small-scale information and baryon/IA uncertainties in the deep-learning summaries is not mapped.
- Integration with standard 3×2pt pipelines
- A rigorous comparison against the full DES Y3 3×2pt baseline (including cross-correlations) and consistency tests (parameter shifts, goodness-of-fit) are deferred.
- Strategies for joint or hierarchical combination of SBI map-level summaries with traditional 2pt analyses are not specified.
- Mask complexity and geometric generalization
- The handling of complex masks, holes, and varying survey footprints by spherical graph networks is not stress-tested; invariance/equivariance properties under masking are not established.
- Generalization to different footprints (e.g., LSST, Euclid) and variable observing conditions is untested.
- Extension to additional probes
- CMB lensing, shear–position cross-correlations beyond the implemented maps, and multi-probe synergies (clusters, voids, magnification) are not included; their potential for further breaking degeneracies remains open.
- Computational scalability to Stage IV
- End-to-end cost and memory scaling to LSST/Euclid map resolutions and footprints, and strategies for distributed training/inference, are not evaluated.
- Data management, caching, and I/O bottlenecks for >10 million realizations at higher resolution are not addressed.
- Reproducibility and release plan
- A clear plan for public release of the forward-model code, trained compressions, normalizing flow models, and mock datasets (beyond CosmoGridV1) is not specified.
- Standardized benchmarks for cross-team comparison and ablation studies are missing.
Glossary
- AGN simulation: A hydrodynamical model including active galactic nucleus feedback used to assess baryonic effects on structure formation and cosmological observables. "the AGN simulation~\cite{vandaalenEffectsGalaxyFormation2011} from the hydrodynamic OverWhelmingly Large Simulations (OWLS) suite"
- baryonification: A post-processing technique that displaces dark matter particles to emulate baryonic feedback effects without running full hydrodynamical simulations. "baryonification"
- baryonic feedback: Astrophysical processes (e.g., AGN, supernovae) that redistribute baryons and alter the matter distribution, impacting small-scale cosmological measurements. "it has been shown that baryonic feedback can bias cosmological constraints"
- Born approximation: An approximation in weak lensing that computes deflections along unperturbed light paths, neglecting lens-lens coupling, sufficient for Stage-III surveys. "The code employs the Born approximation"
- Buzzard galaxy catalogs: Synthetic galaxy catalogs used by DES for validation and systematics testing of analysis pipelines. "independent Buzzard galaxy catalogs"
- correlation function: A two-point statistic in real space that measures spatial correlations between pairs of points in a field. "implemented as the correlation function in real space"
- CosmoGridV1: A suite of dark-matter-only N-body simulations sampling wCDM cosmologies, used for forward modeling and SBI. "CosmoGridV1 suite of -body simulations"
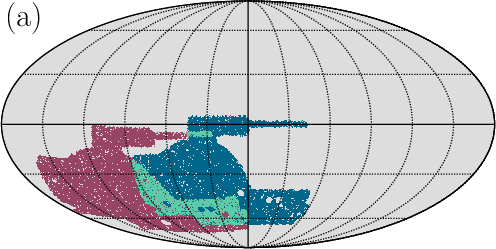
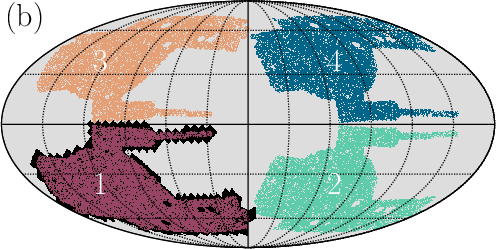
- Dark Energy Survey Year 3 (DES Y3): The third-year dataset of the Dark Energy Survey used for weak lensing and galaxy clustering analyses. "Dark Energy Survey Year 3 (DES Y3)"
- DESI (Dark Energy Spectroscopic Instrument): A spectroscopic survey/instrument providing cosmological constraints, mentioned as context for evolving dark-energy models. "the Dark Energy Spectroscopic Instrument (DESI)"
- DNF (Directional Neighborhood Fitting): A machine-learning photometric redshift estimator used to select the Maglim lens sample. "directional neighborhood fitting (DNF) algorithm"
- Euclid mission: A European Space Agency space telescope for cosmology and galaxy evolution, classified as a Stage-IV survey. "the Euclid mission"
- figures of merit: Quantitative measures of parameter constraint strength (often inverse area in parameter space). "achieving 2--3× higher figures of merit in the --S_8 plane relative to our implementation of baseline two-point statistics"
- galaxy clustering: The spatial distribution of galaxies used as a biased tracer of underlying matter to constrain cosmology. "galaxy clustering"
- Gaussian random field (GRF): A random field whose statistics are fully characterized by its two-point function; a common approximation on large scales. "an isotropic Gaussian random field (GRF)"
- HEALPix: A spherical pixelization scheme (Hierarchical Equal Area isoLatitude Pixelization) used for map-based analyses. "HEALPix maps"
- intrinsic alignment: Correlations in galaxy shapes induced by local tidal fields rather than lensing, acting as a systematic in shear measurements. "intrinsic alignment, and linear galaxy bias parameters"
- Kaiser-Squires: A technique to invert shear maps into convergence maps (and vice versa) under weak-lensing assumptions. "Kaiser-Squires"
- KiDS (Kilo-Degree Survey): A wide-field imaging survey that provides weak lensing and clustering data for cosmology. "the Kilo-Degree Survey (KiDS)"
- lightcone: The simulation output format storing shells along the past lightcone to mimic observational geometry as a function of redshift. "stored in lightcone format"
- LSST (Legacy Survey of Space and Time): A Rubin Observatory Stage-IV imaging survey aimed at precision cosmology with massive datasets. "Legacy Survey of Space and Time (LSST)"
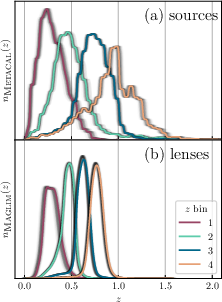
- Maglim: A magnitude-limited lens sample in DES Y3 optimized for w constraints via an i-band cut dependent on photometric redshift. "denoted as Maglim"
- Metacalibration: A self-calibration method for shear measurement that estimates and corrects shear response directly from images. "Metacalibration algorithm"
- mutual information: An information-theoretic measure quantifying dependence between learned features and target parameters. "learn low-dimensional features that approximately maximize mutual information with target parameters"
- N-body simulations: Particle-based gravitational simulations used to evolve dark matter structure formation in cosmology. "-body simulations"
- non-Gaussian: Statistical features beyond Gaussianity present at non-linear scales and not captured by two-point statistics. "non-Gaussian information from cosmological large-scale structure"
- non-linear structure formation: The growth of cosmic structures under gravity leading to departures from linear theory and Gaussian statistics. "due to non-linear structure formation"
- normalizing flows: Invertible neural networks for flexible density estimation of complex probability distributions. "normalizing flows"
- OverWhelmingly Large Simulations (OWLS): A suite of hydrodynamical simulations providing models (e.g., AGN) for baryonic effects used in DES scale cuts. "OverWhelmingly Large Simulations (OWLS) suite"
- photometric redshifts: Redshift estimates derived from multi-band photometry using algorithms and calibration, rather than spectroscopy. "The photometric redshifts of the objects in the catalog are determined by the SOMPZ algorithm"
- photo-z: Shorthand for photometric redshift used for distributions and uncertainty modeling. "photo- distributions"
- PkdGrav3: A high-performance N-body code optimized for hybrid CPU-GPU architectures with linear scaling. "PkdGrav3 code"
- power spectrum: A two-point statistic in harmonic/Fourier space summarizing variance as a function of scale. "the power spectrum in harmonic space"
- probe combination: Jointly analyzing multiple observables (e.g., lensing and clustering) to break degeneracies and improve constraints. "breaking parameter degeneracies through probe combination"
- Roman Space Telescope: A NASA Stage-IV space mission for wide-field imaging relevant to precision cosmology. "the Roman Space Telescope"
- S_8: A parameter combination sensitive to clustering amplitude and matter density, often defined as σ₈√(Ωₘ/0.3). "S_8 plane"
- shape noise: Noise in shear maps arising from the intrinsic ellipticities and finite number of source galaxies. "shape noise generation"
- simulation-based inference (SBI): A framework that learns parameter–data relationships directly from simulations to perform inference without explicit likelihoods. "simulation-based inference (SBI) pipeline"
- Sobol sequence: A low-discrepancy quasi-random sampling strategy used to uniformly fill parameter space. "Sobol sequence"
- SOMPZ: A photometric redshift methodology using self-organizing maps and priors for DES source galaxies. "SOMPZ algorithm"
- Stage-IV wide-field imaging surveys: Next-generation surveys with order-of-magnitude larger datasets and sub-percent precision goals. "Stage-IV wide-field imaging surveys"
- tomographic bins: Redshift slices used to separate galaxy samples and enhance sensitivity to evolution and geometry. "tomographic bins"
- two-point statistics: Summary statistics (correlation function, power spectrum) sufficient for Gaussian fields but insufficient for non-Gaussian information. "two-point statistics"
- UFalcon: A code for fast generation and projection of lightcone maps used in forecasting and inference pipelines. "UFalcon code"
- weak gravitational lensing: Small coherent distortions in galaxy shapes caused by intervening mass, probing the projected matter field. "weak gravitational lensing"
- wCDM: A cosmological model with cold dark matter and a constant dark-energy equation-of-state parameter w. "varying CDM"
Practical Applications
Immediate Applications
The following applications can be deployed with existing tools, data, and methods presented in the paper.
- Cosmology survey analysis pipeline for DES Y3 and other Stage-III data (academia, software)
- Use case: Adopt the simulation-based inference (SBI) pipeline that jointly analyzes weak lensing and galaxy clustering maps to infer cosmological parameters (including w), yielding 2–3× higher figures of merit in the S8 plane relative to two-point statistics and breaking parameter degeneracies via probe combination.
- Tools/workflows: CosmoGridV1 simulation suite; UFalcon for map projection; HEALPix map handling; deep graph convolutional networks on spherical geometry for learned compression; normalizing flows for neural likelihood estimation; integrated handling of masks, photo-z, shear bias, and baryonic nuisances.
- Assumptions/dependencies: Constant-w cosmology; Born approximation; fidelity of baryonification model; accurate DES Y3 masks and redshift distributions; sufficient compute to train on large mock ensembles; robustness validated against Buzzard catalogs.
- Emulator-free likelihood estimation for bespoke summary statistics (academia, software)
- Use case: Replace analytical covariance and hand-crafted statistics with flow-based likelihood learned directly from simulations, enabling inference with non-Gaussian map-level compressions and complex survey systematics.
- Tools/workflows: Normalizing flows; neural density estimation; simulation-driven training across 10-D parameter space; end-to-end validation via synthetic observations.
- Assumptions/dependencies: Coverage of parameter space; calibration of nuisance priors; careful model-misspecification tests.
- Map-level diagnostics and anomaly detection for survey quality assurance (academia, software)
- Use case: Use learned low-dimensional compressions to flag systematic contaminants (e.g., masking artifacts, shear calibration issues) in full-footprint spherical maps.
- Tools/workflows: Trained spherical graph CNNs; DES-like mask conditioning; synthetic contaminations for supervised or semi-supervised detection.
- Assumptions/dependencies: Availability of labeled or simulated anomalies; transferability from mocks to real data.
- Rapid testing of scale cuts and baryonic-impact mitigation (academia, policy)
- Use case: Evaluate and tune scale cuts by directly incorporating baryonification in forward modeling rather than relying solely on hydrodynamic templates and conservative cuts.
- Tools/workflows: Effective baryonification model (M_c0, ν) integrated in CosmoGridV1 shells; end-to-end forecasts under systematic variations.
- Assumptions/dependencies: Validity of baryonification parameterization over DES-like scales; sensitivity analyses for posterior shifts.
- Spherical deep-learning feature extraction for global geospatial maps (climate, geospatial software)
- Use case: Transfer spherical graph CNN architectures to Earth-observation tasks (e.g., cloud detection, wildfire risk, aerosol mapping) that use HEALPix-like tiling or global grids.
- Tools/workflows: Spherical GNNs; non-Gaussian feature learning; map-level compression for downstream regression or classification.
- Assumptions/dependencies: Availability of appropriately tiled global data; domain-specific labels; benefits from non-Gaussian features similar to cosmology.
- Synthetic-data training for domains with scarce labels (software/ML)
- Use case: Leverage large simulated ensembles to train inference models where ground-truth labels are limited or likelihoods are intractable (e.g., remote sensing, astrophysical transients).
- Tools/workflows: Scalable forward models; SBI; normalizing flows; domain-gap validation using independent mocks.
- Assumptions/dependencies: Simulator fidelity; robust domain adaptation; compute budgets for generating and storing ensembles.
- Curriculum modules and hands-on labs on SBI and spherical deep learning (education)
- Use case: Integrate CosmoGridV1, UFalcon, HEALPix, and normalizing flows into graduate-level courses and workshops on modern inference for high-dimensional scientific data.
- Tools/workflows: Open datasets; Jupyter notebooks; GPU-enabled training examples; reproducible pipelines.
- Assumptions/dependencies: Access to datasets and compute; simplified subsets for classroom scale.
- Open-source component adoption for map projection and simulation post-processing (academia, software)
- Use case: Reuse UFalcon and HEALPix workflows for fast projection and shell-based processing; adopt baryonification steps for small-scale modeling across cosmological projects.
- Tools/workflows: UFalcon; HEALPix; baryonification code aligned with Schneider et al. models.
- Assumptions/dependencies: License compatibility; minimal modification for other surveys; verification against survey-specific systematics.
Long-Term Applications
These applications require further research, scaling, new simulations, or broader ecosystem development.
- Stage-IV deployment for LSST, Euclid, and Roman (academia, software)
- Use case: Scale SBI pipelines to full-sky, multi-probe analyses with sub-percent precision, incorporating more complex systematics and larger data volumes.
- Tools/workflows: Exascale computing; extended spherical GNN architectures; distributed normalizing-flow training; automated systematics modeling.
- Assumptions/dependencies: New simulation suites with expanded parameter spaces; precise photo-z calibration; robust baryonic and observational systematics models.
- Dynamical dark energy inference (w0–wa) and beyond-ΛCDM (academia)
- Use case: Extend from constant w to time-varying w0–wa, and add parameters for modified gravity or neutrino masses; learn higher-dimensional implicit likelihoods.
- Tools/workflows: New CosmoGrid-like suites spanning extended cosmologies; emulators for speed; hierarchical SBI for scalable training.
- Assumptions/dependencies: Availability of high-fidelity simulations; careful prior design; increased training data and compute budgets.
- Unified multi-probe pipelines integrating WL, GC, galaxy–galaxy lensing, CMB lensing, and spectroscopy (academia)
- Use case: Build end-to-end SBI for combined probes to maximally break degeneracies and tighten constraints.
- Tools/workflows: Joint forward models for all probes; shared masks and calibration nuisance handling; multi-channel spherical networks; joint normalizing flows.
- Assumptions/dependencies: Harmonized data standards; forward models for each probe; robust cross-calibration strategies.
- Likelihood-free calibration of complex simulators in other sectors (energy, infrastructure, climate)
- Use case: Apply SBI and flow-based density estimation to parameter inference in power-grid stability simulators, climate GCMs, transportation systems, or urban microclimate models.
- Tools/workflows: Synthetic ensembles from domain simulators; learned compressions for non-Gaussian spatiotemporal outputs; probabilistic parameter posteriors.
- Assumptions/dependencies: High-fidelity simulators; mapping between simulator outputs and observed data; domain-specific priors and validation datasets.
- Digital twins: parameter inference and monitoring in manufacturing and robotics (industry)
- Use case: Fit digital twin parameters to telemetry where explicit likelihoods are unknown; perform online updates with learned compressions from sensor maps (including 360° cameras).
- Tools/workflows: SBI integrated with streaming data; spherical or panoramic deep networks; normalizing-flow posteriors for decision support.
- Assumptions/dependencies: Reliable sensor-to-map representation; simulator realism; latency and compute constraints.
- Standardized spherical deep-learning libraries and toolchains (software)
- Use case: Productize spherical graph CNNs and training utilities for scientific and industrial map-like data (astronomy, geospatial, panoramic imaging).
- Tools/workflows: Open-source packages with benchmarks; data loaders for HEALPix and global grids; tutorials and model zoos.
- Assumptions/dependencies: Community adoption; maintenance resources; interoperability with mainstream ML frameworks.
- Compute and data governance policies for massive simulation ensembles (policy)
- Use case: Establish guidelines for sustainable HPC usage, dataset sharing, and reproducibility for SBI-based science.
- Tools/workflows: Best-practice documents; shared repositories; standardized validation protocols with independent mocks (e.g., Buzzard-like catalogs).
- Assumptions/dependencies: Institutional coordination; funding and infrastructure; alignment with open-science principles.
- Public engagement and interactive learning tools (education, daily life)
- Use case: Develop interactive apps that visualize how deep learning extracts cosmological information from maps and how simulations inform scientific inference.
- Tools/workflows: Web demos; simplified models; narrative explanations linking maps to parameters and uncertainties.
- Assumptions/dependencies: Simplified datasets that preserve core ideas; accessible UIs; outreach partnerships.
Collections
Sign up for free to add this paper to one or more collections.

