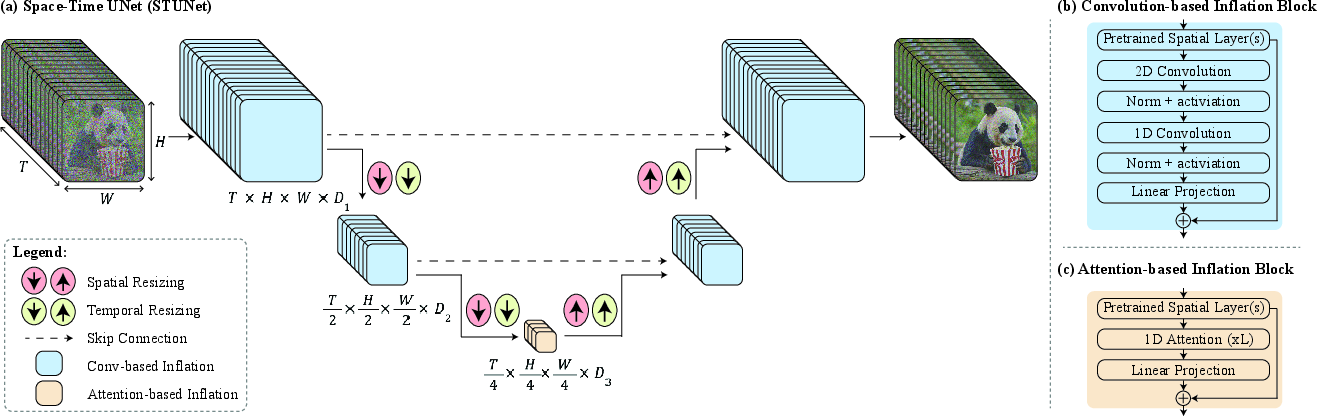
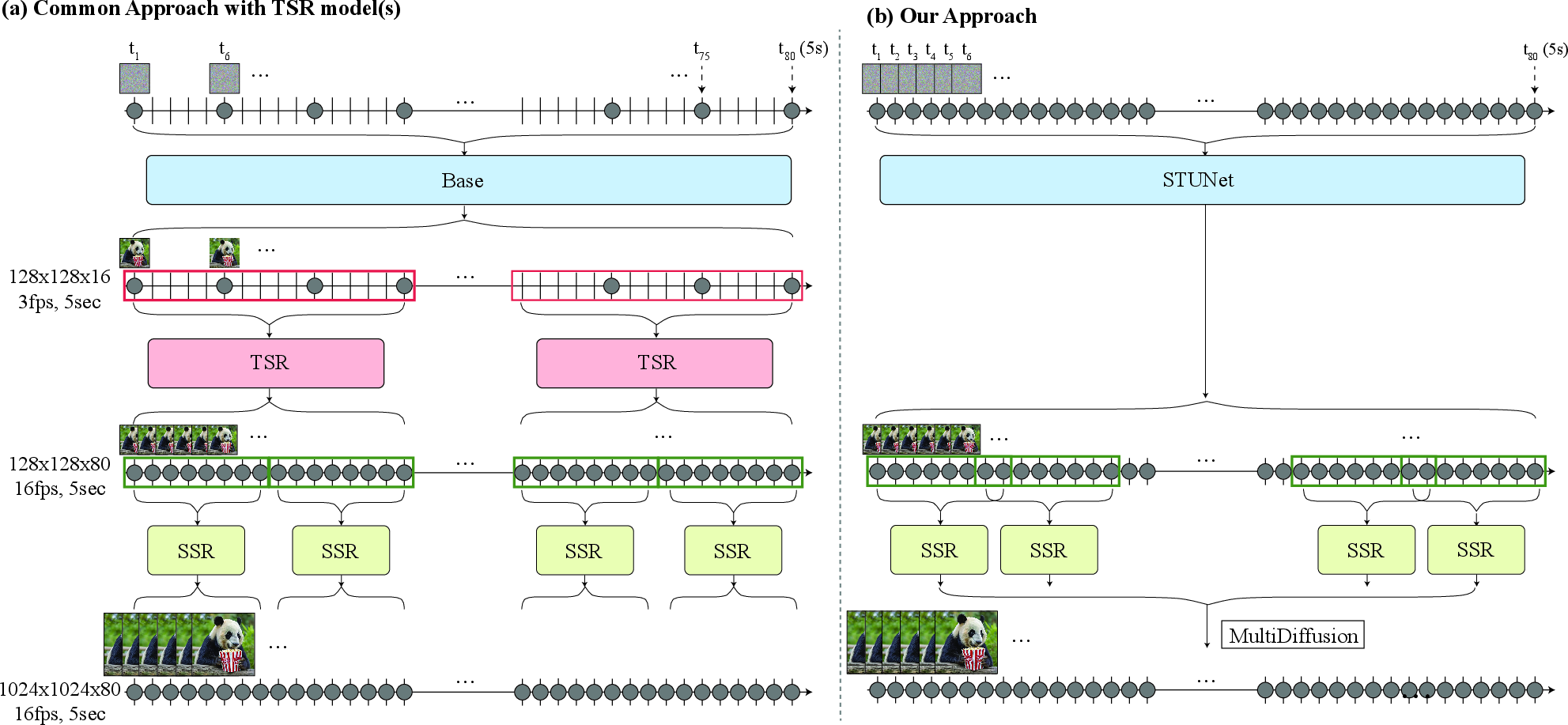
Lumiere: A Space-Time Diffusion Model for Video Generation
Abstract: We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
- MultiDiffusion: Fusing diffusion paths for controlled image generation. In ICML, 2023.
- Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023a.
- Align your latents: High-resolution video synthesis with latent diffusion models. In CVPR, 2023b.
- Quo vadis, action recognition? A new model and the kinetics dataset. In CVPR, pp. 6299–6308, 2017.
- Chen, T. On the importance of noise scheduling for diffusion models. arXiv preprint arXiv:2301.10972, 2023.
- Effectively unbiased FID and Inception Score and where to find them. In CVPR, pp. 6070–6079, 2020.
- 3d u-net: learning dense volumetric segmentation from sparse annotation. In MICCAI, pp. 424–432. Springer, 2016.
- Diffusion models in vision: A survey. IEEE T. Pattern Anal. Mach. Intell., 2023a.
- Diffusion models in vision: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023b.
- Shot durations, shot classes, and the increased pace of popular movies, 2015.
- Diffusion models beat gans on image synthesis. NeurIPS, 2021.
- Breathing life into sketches using text-to-video priors. arXiv preprint arXiv:2311.13608, 2023.
- Preserve your own correlation: A noise prior for video diffusion models. In ICCV, pp. 22930–22941, 2023.
- Emu Video: Factorizing text-to-video generation by explicit image conditioning. arXiv preprint arXiv:2311.10709, 2023.
- Matryoshka diffusion models. arXiv preprint arXiv:2310.15111, 2023.
- AnimateDiff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725, 2023.
- Denoising diffusion probabilistic models. NeurIPS, 33:6840–6851, 2020.
- Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022a.
- Video diffusion models, 2022b.
- CogVideo: Large-scale pretraining for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868, 2022.
- Simple diffusion: End-to-end diffusion for high resolution images. In ICML, 2023.
- Style transfer by relaxed optimal transport and self-similarity. In CVPR, pp. 10051–10060, 2019.
- VideoPoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125, 2023.
- SDEdit: Guided image synthesis and editing with stochastic differential equations. In ICLR, 2022.
- Improved denoising diffusion probabilistic models. In ICML, pp. 8162–8171, 2021.
- On aliased resizing and surprising subtleties in gan evaluation. In CVPR, 2022.
- Pika labs. https://www.pika.art/, 2023.
- Resolution dependent GAN interpolation for controllable image synthesis between domains. In Machine Learning for Creativity and Design NeurIPS 2020 Workshop, 2020.
- State of the art on diffusion models for visual computing. arXiv preprint arXiv:2310.07204, 2023.
- DreamFusion: Text-to-3D using 2D diffusion. In ICLR, 2023.
- Hierarchical text-conditional image generation with CLIP latents. arXiv preprint arXiv:2204.06125, 2022.
- High-resolution image synthesis with latent diffusion models. In CVPR, pp. 10684–10695, 2022.
- U-Net: Convolutional networks for biomedical image segmentation. In MICCAI, pp. 234–241. Springer, 2015.
- RunwayML. Gen-2. https://research.runwayml.com/gen2, 2023.
- Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 Conference Proceedings, pp. 1–10, 2022a.
- Photorealistic text-to-image diffusion models with deep language understanding. NeurIPS, 35:36479–36494, 2022b.
- Train sparsely, generate densely: Memory-efficient unsupervised training of high-resolution temporal GAN. Int. J. Comput. Vision, 128(10-11):2586–2606, 2020.
- Improved techniques for training GANs. NIPS, 29, 2016.
- Make-a-Video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792, 2022.
- Deep unsupervised learning using nonequilibrium thermodynamics. In ICML, pp. 2256–2265, 2015.
- StyleDrop: Text-to-image generation in any style. arXiv preprint arXiv:2306.00983, 2023.
- Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020.
- UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012.
- A closer look at spatiotemporal convolutions for action recognition. In CVPR, pp. 6450–6459, 2018.
- Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018.
- Phenaki: Variable length video generation from open domain textual description. In ICLR, 2023.
- Modelscope text-to-video technical report. arXiv preprint arXiv:2308.06571, 2023a.
- Videocomposer: Compositional video synthesis with motion controllability. arXiv preprint arXiv:2306.02018, 2023b.
- Nüwa: Visual synthesis pre-training for neural visual world creation. In ECCV, pp. 720–736. Springer, 2022.
- Inflation with diffusion: Efficient temporal adaptation for text-to-video super-resolution, 2024.
- Show-1: Marrying pixel and latent diffusion models for text-to-video generation. arXiv preprint arXiv:2309.15818, 2023a.
- Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3836–3847, 2023b.
- The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, pp. 586–595, 2018.
- MagicVideo: Efficient video generation with latent diffusion models. arXiv preprint arXiv:2211.11018, 2022.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

