Benchmark Designers Should "Train on the Test Set" to Expose Exploitable Non-Visual Shortcuts
Abstract: Robust benchmarks are crucial for evaluating Multimodal LLMs (MLLMs). Yet we find that models can ace many multimodal benchmarks without strong visual understanding, instead exploiting biases, linguistic priors, and superficial patterns. This is especially problematic for vision-centric benchmarks that are meant to require visual inputs. We adopt a diagnostic principle for benchmark design: if a benchmark can be gamed, it will be. Designers should therefore try to game'' their own benchmarks first, using diagnostic and debiasing procedures to systematically identify and mitigate non-visual biases. Effective diagnosis requires directlytraining on the test set'' -- probing the released test set for its intrinsic, exploitable patterns. We operationalize this standard with two components. First, we diagnose benchmark susceptibility using a Test-set Stress-Test'' (TsT) methodology. Our primary diagnostic tool involves fine-tuning a powerful LLM via $k$-fold cross-validation on exclusively the non-visual, textual inputs of the test set to reveal shortcut performance and assign each sample a bias score $s(x)$. We complement this with a lightweight Random Forest-based diagnostic operating on hand-crafted features for fast, interpretable auditing. Second, we debias benchmarks by filtering high-bias samples using anIterative Bias Pruning'' (IBP) procedure. Applying this framework to four benchmarks -- VSI-Bench, CV-Bench, MMMU, and VideoMME -- we uncover pervasive non-visual biases. As a case study, we apply our full framework to create VSI-Bench-Debiased, demonstrating reduced non-visual solvability and a wider vision-blind performance gap than the original.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Benchmark Designers Should ‘Train on the Test Set’ to Expose Exploitable Non-Visual Shortcuts”
What is this paper about?
The paper looks at how we test AI systems that understand both pictures/videos and text (often called multimodal models). It shows that many current tests (benchmarks) can be “gamed.” In other words, a model can get high scores without really looking at the image or video—just by guessing from patterns in the words. The authors argue that people who build these tests should try to “break” their own tests first by actively searching for these shortcuts.
Their big idea sounds shocking at first: they say test designers should “train on the test set.” But they don’t mean cheating. They mean carefully and fairly using the test’s text only—without images—and using a safe method called cross-validation to expose hidden patterns that let models guess answers without seeing the picture. This helps fix weak parts of the test before releasing it.
What questions are the authors trying to answer?
The paper focuses on a few simple questions:
- Are some image/video questions actually answerable without the image/video, just by reading the words?
- How can we measure how much a test can be “gamed” using text-only clues?
- Can we score each question to see which ones are especially vulnerable to these shortcuts?
- If we find biased questions, can we systematically remove or repair them so the test truly requires visual understanding?
How did they do the research? (Methods in everyday language)
Think of a school exam. If students can get high scores by memorizing patterns in the questions (like “the answer is usually B”), then the exam isn’t testing real understanding. The authors build two “stress tests” to check if a benchmark can be solved by text patterns alone:
- Test-set Stress-Test (TsT): They split the test into several slices (folds), like cutting a deck of cards. For each round, they: 1) “Train” a text-only model on most slices to learn patterns in the words and answer choices, 2) Then “test” it on the remaining slice it hasn’t seen. They repeat this until every slice has been tested. This way, the model never trains on the exact questions it’s judged on, so it’s not cheating. If the text-only model scores high, the benchmark has non-visual shortcuts.
They build TsT in two ways:
- TsT-LLM: Uses a strong LLM (like the ones behind chatbots) and lightly fine-tunes it on the question text and answer choices only. This finds complex patterns but is harder to interpret.
- TsT-RF: Uses a Random Forest (many simple decision trees “voting”) trained on hand-crafted text features (like word frequencies, question length, or answer choice stats). It’s fast and shows which features cause shortcuts, but requires manual setup.
They also create a “bias score” for each question, written as . If is high, that question can probably be answered without looking at the image/video.
Finally, they try a simple fix method:
- Iterative Bias Pruning (IBP): Remove the most biased questions (the ones with the highest ), then re-check the remaining test (because removing some patterns might reveal new ones). Repeat until the test relies more on actual visual understanding.
What did they find, and why does it matter?
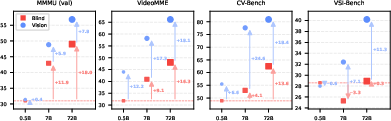
They tested four popular benchmarks: VSI-Bench, CV-Bench, MMMU, and VideoMME. Across all of them, they found that models can gain a lot by using text-only patterns:
- With TsT-LLM (text-only), accuracy jumped by about:
- +33 points on CV-Bench,
- +31 points on VSI-Bench,
- +9 points on MMMU,
- +6 points on VideoMME.
These gains mean many questions can be answered without looking at the image/video—showing the tests contain “non-visual shortcuts.”
They also showed two types of shortcuts:
- Knowledge shortcuts: The model answers from general world knowledge (for example, “most refrigerators are around 150–180 cm tall,” so it guesses without measuring the one in the image).
- Statistical shortcuts: Patterns in the test itself, like certain answers appearing much more often, or typical ranges (for example, many rooms in the dataset are around a standard size, so “average guesses” work well).
Case study: VSI-Bench
- They fine-tuned a multimodal model on a small, matching training set and saw the text-only (blind) accuracy shoot up from about 26% to 45%. The vision-enabled accuracy rose by about the same amount. This shows the model was learning shortcuts that help even when the image is present—because the shortcuts are so strong.
- After applying IBP to remove biased items, they built VSI-Bench-Debiased. On this improved version, text-only accuracy dropped notably, and the gap between “with vision” and “without vision” got bigger. That’s good—it means the test now truly needs visual understanding.
Why does this research matter in the real world?
If we let benchmarks be “gamed,” we risk thinking AI understands images and videos better than it really does. That can mislead science and product decisions. This paper gives a practical plan to build stronger tests:
- Designers should “stress-test” their own benchmarks by training text-only models on the test (with careful cross-validation) to uncover hidden patterns.
- Use the bias score to pinpoint weak questions, then remove or repair them with an iterative process.
- Share these diagnostics so the community trusts that scores reflect true visual understanding, not clever guessing from text.
Takeaway
The message is simple: if a benchmark can be gamed, it will be. So test designers should try to game it first—safely and scientifically—to find and fix non-visual shortcuts. This leads to fairer, more honest evaluations and real progress in building AI that genuinely sees and understands the world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following points unresolved that future research could concretely address:
- Sensitivity of TsT outcomes to diagnostic model choice and scale: quantify how TsT accuracy and sample-level bias scores s(x) vary across different LLMs (sizes, architectures), LoRA ranks, training seeds, and optimization settings; assess cross-model agreement on s(x).
- Definition and calibration of s(x): specify a unified, reproducible method to compute confidence for diverse answer formats (multiple choice, numeric, ordinal, free-form), and evaluate calibration quality (e.g., ECE/Brier) across folds.
- Fold leakage and grouping: establish and evaluate group-wise cross-validation protocols (by template, image/video source, scene, object category, annotator, or generation script) to prevent near-duplicate or structurally similar items from straddling folds.
- Coverage and validity after pruning: quantitatively assess how IBP affects content validity, construct coverage, and distributional representativeness (e.g., per category/task balance, real-world frequencies); provide hard constraints in selection to avoid hollowing out specific subdomains.
- Choice of IBP hyperparameters: provide principled guidelines for setting removal budget B, batch size b, and early-stopping threshold τ; include sensitivity analyses and automatic stopping criteria (e.g., TsT accuracy nearing chance, calibrated max s(x) thresholds).
- Reparative versus removal strategies: systematically compare pruning with rewriting, resampling, counterfactual augmentation, and reweighting; measure their impact on non-visual solvability, ecological validity, and potential introduction of new biases.
- Human-grounded validation: measure human performance (vision-enabled vs blind) and inter-annotator agreement on original versus debiased benchmarks to ensure tasks remain visually grounded and solvable.
- Ranking stability across models: evaluate whether debiasing preserves or changes comparative rankings across a diverse set of MLLMs; analyze if the debiased benchmark better correlates with independent measures of visual reasoning.
- Upper bounds on exploitability: develop methods or theory to approximate upper bounds on non-visual solvability (e.g., ensembles, meta-learning over folds, larger/fine-tuned diagnostics), beyond the paper’s “pragmatic lower bound.”
- Interpretable diagnostics for non-templated datasets: design feature-attribution or representation-level analyses (e.g., SHAP for text features, probing classifiers over LLM embeddings) to make TsT-LLM actionable on human/LLM-authored benchmarks like MMMU and VideoMME.
- Visual-only shortcuts: extend diagnosis to detect and mitigate purely visual spurious cues (e.g., background textures, color priors, watermark/template artifacts) that can also undermine evaluation integrity.
- Temporal biases in video QA: characterize and mitigate non-visual and visual temporal shortcuts (e.g., stereotyped event orders, time-localized cue correlations) specific to video benchmarks.
- Confidence estimation for generative answers: define how TsT-LLM computes s(x) for free-form outputs (e.g., log-likelihoods, constrained decoding, semantic equivalence via LLM judges), and validate robustness to evaluation noise.
- Diversity-aware batch selection in IBP: specify SelectBatch to incorporate diversity constraints (e.g., category/scene/task quotas) so pruning doesn’t disproportionately remove specific content and induce new biases.
- Interaction of statistical and knowledge-based shortcuts: analyze how removing statistical shortcuts shifts reliance toward knowledge-based priors (or vice versa), and devise balanced mitigation that addresses both without degrading realism.
- Ecological validity trade-offs: formalize criteria for preserving natural distributions while reducing exploitability (e.g., adversarial balancing, controlled heterogeneity), and evaluate downstream generalization.
- Post-debiasing adversarial auditing: introduce iterative/continuous auditing pipelines that automatically re-run TsT (and complementary diagnostics) to detect second-order shortcuts that emerge after mitigation.
- Robustness to label noise and ambiguity: develop procedures to detect when high s(x) reflects annotation errors or ill-posed questions, and protocols to repair versus prune such samples.
- Transparent artifact release: standardize the release of per-sample s(x), fold assignments, removed IDs, and rationales to enable reproducibility and community auditing without enabling “cheat models.”
- Safe-use guidance for “train on test set”: propose governance practices that let benchmark designers audit with TsT while preventing public misuse (e.g., private diagnostics, controlled test-set access, dynamic/rotating test sets).
- Scaling and efficiency: study computational costs for very large benchmarks; explore incremental TsT (e.g., streaming folds, warm-started LoRA) and CPU-friendly alternatives that retain detection power.
- Group-aware chance baselines: define and report chance/majority baselines that respect group structure (templates, categories, numeric ranges) so improvements are interpretable across heterogeneous task types.
- Cross-modality generalization: extend TsT and IBP to audio–text, 3D, robotics, and OCR-heavy tasks; evaluate modality-specific shortcuts and propose modality-agnostic diagnostic metrics.
- Effects on training and dataset usage: analyze how debiased benchmarks influence models trained with benchmark-derived supervision (e.g., overfitting to debiased distributions, reduced transfer to real-world tasks).
Practical Applications
Practical Applications of the Paper’s Findings
This paper introduces a concrete, repeatable methodology for auditing and improving multimodal benchmarks: Test-set Stress-Testing (TsT) with LLM-based and Random-Forest diagnostics to quantify non-visual solvability, per-sample bias scoring s(x), and Iterative Bias Pruning (IBP) to produce debiased test sets (e.g., VSI-Bench-Debiased). Below are actionable applications organized by time-to-deploy and linked to relevant sectors, workflows, and feasibility considerations.
Immediate Applications
The following applications can be deployed with today’s tools and typical ML ops infrastructure.
- Bold benchmark auditing and “gating” before release
- Description: Make TsT (LLM or RF) a mandatory pre-release step for any multimodal benchmark. Compute overall non-visual solvability and publish per-sample bias scores s(x); set release gates (e.g., TsT accuracy below a threshold).
- Sectors: Academia, software/AI, platform/leaderboard maintainers.
- Tools/workflows: TsT-LLM via LoRA fine-tuning; TsT-RF for fast CPU audits; CI/CD hooks that fail a release if TsT exceeds a threshold; “Vision-Blind Gap” dashboards.
- Assumptions/dependencies: Access to full test text/metadata; acceptance that cross-validated “train-on-test” is used strictly for diagnostics; modest GPU for TsT-LLM or CPU for TsT-RF.
- Debiasing existing benchmarks with IBP
- Description: Use s(x) to iteratively prune or flag high-bias items and re-diagnose, producing robust subsets (e.g., “-Debiased” tracks) with wider vision–blind gaps.
- Sectors: Academia, open-source consortia, internal eval teams in industry.
- Tools/workflows: IBP loop with small batch removals; optional human-in-the-loop for rewrite vs prune; publish original-to-debiased item maps.
- Assumptions/dependencies: Careful budgeting to avoid over-pruning coverage; agreement on early-stopping thresholds; versioning of benchmark splits.
- Vendor evaluation and model procurement due diligence
- Description: Enterprises use TsT on internal or third-party eval sets to ensure reported gains reflect genuine visual reasoning rather than textual priors.
- Sectors: Finance, healthcare (medical imaging), e-commerce (visual search), automotive (AD/ADAS), manufacturing (inspection).
- Tools/workflows: “Pre-procurement audit pack” with TsT metrics and vision-blind gap; model scorecards with TsT-adjusted performance.
- Assumptions/dependencies: Legal right to audit internal test sets; availability of a “blind” evaluation mode for MLLMs.
- Safety and compliance evidence for regulated domains
- Description: Supply TsT reports showing reduced non-visual solvability and significant vision–blind gaps as part of validation dossiers.
- Sectors: Healthcare, aviation, industrial inspection, public sector.
- Tools/workflows: Audit PDFs with TsT accuracy, s(x) histograms, and post-IBP deltas; traceability to per-item rationale.
- Assumptions/dependencies: Regulator acceptance of diagnostic “train-on-test” with cross-validation; appropriate documentation standards.
- Leaderboard and benchmark governance enhancements
- Description: Publish TsT metrics alongside leaderboard results; introduce “TsT-certified” or “robust subset” tracks and require blind baselines.
- Sectors: Academic benchmarks, competitions, platform operators.
- Tools/workflows: Submission templates collecting blind vs vision scores; TsT-based “robustness score” displayed next to accuracy.
- Assumptions/dependencies: Community buy-in; standardized reporting schema.
- Continuous benchmark QA in MLOps
- Description: Integrate nightly TsT jobs to detect drift in non-visual solvability as datasets grow or templates change.
- Sectors: Software/AI product teams, data platform teams.
- Tools/workflows: GitHub Actions/Airflow pipelines; Slack alerts when TsT accuracy or s(x) tails exceed thresholds.
- Assumptions/dependencies: Stable evaluation harness; compute budget for regular diagnostics.
- Test design for education and assessments
- Description: Use TsT to filter multimodal exam questions that are guessable from text alone, ensuring they require visual reasoning.
- Sectors: Education, ed-tech platforms, certification bodies.
- Tools/workflows: Question banks scored with s(x); IBP pruning or targeted rewrites of high-bias items.
- Assumptions/dependencies: Multiple-choice or scorable short-answer formats; rubric for open-ended grading.
- Robotics and embodied AI perception evaluation
- Description: Build perception/scene-understanding test suites resistant to language priors; audit “vision reliance” before deployment.
- Sectors: Robotics, logistics, smart manufacturing, home assistants.
- Tools/workflows: TsT-RF for templated perception tasks; “sensor-blind” ablations to quantify reliance on real perception.
- Assumptions/dependencies: Access to task metadata; modality-ablation harnesses.
- Product QA for visual features
- Description: Audit test suites for visual captioning, shopping visual search, and OCR Q&A to ensure metrics reflect true perception.
- Sectors: Consumer apps, e-commerce, productivity software.
- Tools/workflows: TsT checks as part of release QA; “blind” ablations in A/B testing.
- Assumptions/dependencies: Ability to run model in blind mode or stub image encoders.
- Data collection guidance for crowdworkers and LLM generation
- Description: Feed back TsT feature importances (RF) and s(x) hotspots to adjust templates/prompts and reduce predictable artifacts.
- Sectors: Data labeling vendors, synthetic data providers.
- Tools/workflows: Authoring guidelines; automated template linting guided by TsT-RF feature importance.
- Assumptions/dependencies: Access to authoring pipeline; willingness to revise generation logic.
- Research baselines and reproducibility upgrades
- Description: Release benchmarks with bundled TsT scripts, s(x) files, and “debiased” splits to support robust comparisons.
- Sectors: Academia, open-source.
- Tools/workflows: Open-source repo with TsT-LLM notebooks, RF feature extractors, and IBP configs.
- Assumptions/dependencies: Maintenance of scripts as benchmarks evolve.
Long-Term Applications
These applications require further research, scaling, community standards, or policy development.
- Certified benchmark robustness standards
- Description: NIST/ISO-style standards incorporating TsT metrics and minimum vision–blind gap requirements for “certified” multimodal benchmarks.
- Sectors: Standards bodies, policy/regulators, safety-critical industries.
- Tools/workflows: Reference TsT implementations; accreditation programs.
- Assumptions/dependencies: Consensus on acceptable “non-visual solvability” levels; regulatory adoption.
- Co-evolutionary benchmark generation
- Description: Automated pipelines that iteratively generate, diagnose (TsT), and repair items (rewrite/synthesize) rather than just prune, maintaining coverage while minimizing shortcuts.
- Sectors: Benchmarks-as-a-service, AI evaluation platforms.
- Tools/workflows: LLM-based item synthesis with entropy constraints; TsT-in-the-loop generation.
- Assumptions/dependencies: Reliable automatic rewriting that doesn’t introduce new artifacts; scalable scoring for open-ended tasks.
- TsT-adjusted scoring and model cards
- Description: Standardized reporting of TsT-adjusted accuracy and per-domain vision–blind gaps in model cards and evaluation papers.
- Sectors: AI model providers, journals, conferences.
- Tools/workflows: Reporting templates; leaderboard support for adjusted scores.
- Assumptions/dependencies: Community norms; agreement on adjustment formulas.
- Risk assessment for visual AI deployments
- Description: Use TsT metrics as inputs into quantitative risk models (e.g., probability of shortcut-induced error) for insurance, safety cases, and SLAs.
- Sectors: Insurance, legal, safety engineering, procurement.
- Tools/workflows: Risk calculators linking TsT to failure modes; contractual thresholds.
- Assumptions/dependencies: Empirical mapping between TsT metrics and real-world error rates.
- Cross-modality generalization: audio, sensors, and time series
- Description: Extend TsT to ensure reliance on non-text modalities (audio, LiDAR, biosignals), not just language priors.
- Sectors: Autonomous driving, smart cities, digital health.
- Tools/workflows: Modality-ablation harnesses; feature engineering for non-visual modalities; LLM diagnostics for multimodal prompts.
- Assumptions/dependencies: Robust scoring for non-visual tasks; comparable “blind” configurations.
- Curriculum design for robust model training
- Description: Use s(x) to construct training curricula (e.g., hard-negative schedules) or to calibrate loss against language-only baselines.
- Sectors: AI research, product ML teams.
- Tools/workflows: Training-time penalties for blind-solvable items; dynamic data sampling guided by s(x).
- Assumptions/dependencies: Demonstrated generalization gains without overfitting to TsT signals.
- Marketplace of “TsT-certified” debiased datasets
- Description: Commercial repositories offering verified, debiased multimodal eval sets with ongoing TsT monitoring.
- Sectors: Data vendors, AI evaluation platforms.
- Tools/workflows: Continuous IBP maintenance; drift detection; certification badges.
- Assumptions/dependencies: Sustainable business models; transparent governance.
- Educational accreditation and AI-assisted assessment design
- Description: Accrediting bodies adopt TsT-like audits to certify that AI-assisted or AI-graded multimodal exams measure intended competencies.
- Sectors: Education policy, ed-tech.
- Tools/workflows: Auditable item banks, TsT score thresholds, human review workflows for flagged items.
- Assumptions/dependencies: Policy adoption; reliable rubrics for open-ended responses.
- Governance for public-sector AI evaluations
- Description: Government AI tenders require TsT disclosures and robust-subset metrics to guard against “inflated” scores from exploitable tests.
- Sectors: Public procurement, defense, civic tech.
- Tools/workflows: RFP templates with TsT requirements; third-party audit programs.
- Assumptions/dependencies: Legal frameworks; data sharing agreements for diagnostics.
- Interpretable bias analytics and authoring assistants
- Description: Authoring tools that suggest changes to prompts/templates based on RF feature importance and s(x) patterns to reduce shortcut cues.
- Sectors: Dataset authoring platforms, LLM content generation.
- Tools/workflows: IDE-like authoring assistants; real-time “bias linting.”
- Assumptions/dependencies: Mature feature extraction for diverse, non-templated tasks; robust UX integration.
Notes on Assumptions and Dependencies
- Data and legal access: TsT requires access to full test text/metadata and a permissible diagnostic “train-on-test” via cross-validation. Proprietary or sensitive datasets may need special handling and approvals.
- Compute: TsT-LLM benefits from GPUs but can be replaced by TsT-RF on templated tasks for speed and interpretability.
- Scoring regimes: Multiple-choice tasks are straightforward; open-ended responses require reliable automatic scoring or human adjudication.
- Diagnostic model choice: TsT outcomes may vary with the diagnostic LLM or feature set; conservative use treats TsT accuracy as a lower bound on exploitability.
- Balance vs coverage: Pruning reduces bias but can narrow domain coverage; IBP should track distributional shifts and stop early when acceptable.
- Avoiding new biases: Rewriting/synthesis must be validated to ensure they do not introduce subtler shortcuts; iterative re-diagnosis is essential.
- Community norms: Widespread impact depends on adoption by benchmark maintainers, conferences, journals, and regulators who endorse TsT reporting and robust-subset tracks.
Glossary
- Adversarial stress-test: An evaluation setup that intentionally probes models by creating adversarial conditions to reveal exploitable patterns. "we conduct an adversarial stress-test on VSI-Bench~\cite{yang2024think}."
- Blind test: A diagnostic where the model is evaluated without visual input to assess reliance on non-visual information. "the ``blind'' test~\cite{tong2024cambrian}---where a multimodal benchmark is evaluated with vision disabled---"
- Counterfactual data augmentation: A training technique that generates modified examples to enforce causal reasoning and reduce shortcut learning. "counterfactual data augmentation~\cite{niu2021counterfactual,abbasnejad2020counterfactual}, synthesizing modified samples to force models to attend to visual evidence"
- Debiasing: Procedures that identify and mitigate biases in datasets or evaluations to prevent shortcut exploitation. "adopting rigorous diagnostic and debiasing procedures to systematically identify, quantify, and mitigate non-visual biases."
- Gini importance: A metric in tree-based models that quantifies the contribution of each feature to reducing impurity, used for interpretability. "feature importance analysis (e.g., Gini importance~\cite{nembrini2018revival}) reveals which specific non-visual cues drive exploitability."
- In-distribution: Data that follows the same statistical distribution as the test set or target domain, used to assess learned patterns. "We first curate a small, in-distribution training set, ``VSI-Train-10k'',"
- Iterative Bias Pruning (IBP): An iterative procedure that removes highly biased samples based on diagnostic scores to improve benchmark robustness. "using an ``Iterative Bias Pruning'' (IBP) procedure."
- k-fold cross-validation: A validation method that partitions data into k folds, training on k−1 and evaluating on the held-out fold to measure generalization. "apply -fold cross-validation~\cite{stone1974cross,hastie2009elements} directly on the test set"
- LLM: A neural network trained on vast text corpora to perform language understanding and generation tasks. "fine-tuning a powerful LLM"
- Log-normal distributions: Probability distributions where the logarithm of the variable is normally distributed, often modeling sizes or durations. "Size estimation tasks follow predictable log-normal distributions."
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that adds low-rank matrices to adapt large models without updating all weights. "using Low-Rank Adaptation (LoRA)~\cite{hu2021lora}"
- Majority baseline: A simple baseline that always predicts the most frequent class, used to contextualize model performance. "Chance and majority baselines provided for context."
- Modality Importance Score (MIS): A metric that quantifies the contribution of each modality (e.g., vision, audio, text) to task performance. "Park et al.~\cite{park2024modality} propose the Modality Importance Score (MIS),"
- Multimodal LLMs (MLLMs): LLMs augmented to process multiple input modalities, such as text and images or video. "Robust benchmarks are crucial for accurately evaluating Multimodal LLMs (MLLMs)."
- Non-visual solvability: The extent to which tasks can be solved using only non-visual information, undermining visual evaluation. "provides a global estimate of the benchmark's ``non-visual solvability''."
- Out-of-distribution evaluation: Testing models on data that differs from the training distribution to assess robustness and generalization. "typically assessed through out-of-distribution evaluation (e.g., VQA-CP~\cite{agrawal2018don})."
- Parametric knowledge: Information encoded in model parameters from pretraining, enabling recall without perception. "using parametric knowledge or statistical priors"
- Procedural generation artifacts: Systematic patterns or biases introduced by programmatic data generation processes. "procedural generation artifacts"
- Random Forest classifier: An ensemble learning method using multiple decision trees to improve predictive accuracy and robustness. "uses a Random Forest classifier~\cite{breiman2001random}"
- Region Comprehension Index (RCI): A diagnostic that measures whether benchmarks require local versus global visual reasoning. "Agarwal et al.~\cite{agarwal2024rci} introduce the Region Comprehension Index (RCI),"
- RUBi: A unimodal bias suppression technique that down-weights examples where question-only models are confident. "unimodal bias suppression techniques like RUBi~\cite{cadene2019rubi}"
- Sample-level bias score: A per-example metric estimating how answerable a sample is without visual input. "derive a quantitative, sample-level bias score, ."
- Spurious correlations: Non-causal statistical associations that models exploit to predict answers without genuine reasoning. "exploiting spurious correlations within the benchmark artifact"
- Template-based benchmarks: Evaluations constructed with structured or templated question formats, often prone to predictable patterns. "For template-based benchmarks CV-Bench and VSI-Bench,"
- Test-set Stress-Test (TsT): A diagnostic methodology that “trains on the test set” via cross-validation to quantify non-visual shortcuts. "using a ``Test-set Stress-Test'' (TsT) methodology."
- TF-IDF: Term Frequency–Inverse Document Frequency, a weighting scheme highlighting informative words in text features. "including textual information (TF-IDF vectors, keywords, question length)"
- Unimodal biases: Reliance on a single modality’s information (e.g., text) that allows solving tasks without multimodal reasoning. "develop a causal framework to quantify and mitigate unimodal biases in MLLMs,"
- Visual grounding: The process of aligning language with visual evidence to ensure answers depend on perception. "feedback-based objectives~\cite{liang2021lpf} that encourage visual grounding."
- Visual Question Answering (VQA): A task where models answer questions about images, used to study multimodal reasoning. "has deep roots in the Visual Question Answering (VQA) literature~\cite{antol2015vqa}."
- Vision-blind gap: The performance difference between vision-enabled and vision-disabled (blind) configurations, indicating visual reliance. "vision-blind gap (+1.6 points)."
- Vision-centric benchmarks: Evaluations explicitly designed to require visual inputs for correct solutions. "particularly problematic for vision-centric benchmarks,"
- VQA-CP: A VQA benchmark with changing priors between train and test to expose language bias reliance. "e.g., VQA-CP~\cite{agrawal2018don}"
- Zero-shot evaluation: Assessing models without task-specific training to measure general capability. "in zero-shot (ZS) evaluation"
- Zipf's Law: A linguistic principle where word frequency inversely correlates with rank, reflecting natural distributions. "analogous to Zipf's Law in language~\cite{zipf1932selected}"
- Long-tailed answer distribution: An imbalanced pattern where few answers occur frequently and many occur rarely, enabling shortcut guessing. "Counting tasks often exhibit severe long-tailed answer distributions;"
Collections
Sign up for free to add this paper to one or more collections.