- The paper introduces Forking Paths Analysis to quantify token-level uncertainty and map diverse outcome distributions using Bayesian change point detection.
- It applies activation steering in Llama-3.2 3B to redirect outputs effectively before tokens become decisively committed.
- Probing hidden states reveals that models encode latent alternate reasoning paths, offering efficient alternatives to exhaustive resampling.
Token-level Uncertainty and Hidden State Dynamics in LLMs
Introduction
This paper investigates whether autoregressive LLMs internally represent "the road not taken"—the latent space of alternate reasoning paths and outcomes at each token generation step. Specifically, the authors probe whether uncertainty and alternative completions are encoded in the model’s sequence of hidden activations during stepwise chain-of-thought (CoT) inference. The work combines Forking Paths Analysis (FPA), model steering via activation interventions, and probing techniques to elucidate the dynamics between token-level uncertainty and hidden state evolution, focusing on the Llama-3.2 3B Instruct model.
Forking Paths Analysis: Quantifying Token-level Uncertainty
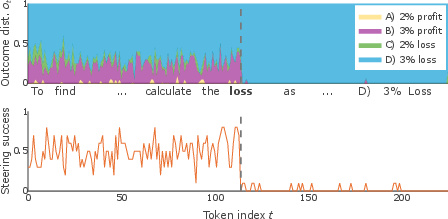
The authors extend FPA methods to estimate the granular progression of uncertainty at each token during text generation. FPA quantifies how the autoregressive sampling of different tokens at position t can induce widely divergent completions, thus mapping a distribution over final outcomes ot conditioned on all branching continuations seeded at t.
The procedure involves:
- Sampling a "base path" CoT completion.
- Iterating over token positions t, and for each, resampling continuations starting from alternative top-N substitutions at t.
- Extracting outcome answers for the completions and empirically building ot as a mixture over possible answers.
Abrupt shifts in ot—indicative of discrete “forking tokens”—are detected via Bayesian change point detection (CPD), revealing positions in the prompt where the model’s outcome uncertainty collapses or decisively commits. The computational overhead of this approach is substantial, as it requires resampling and scoring over a combinatorially expanding tree of possible continuations.
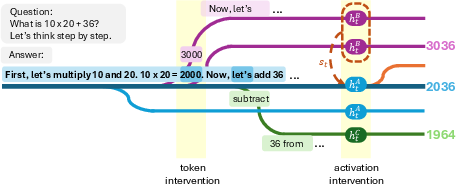
Figure 1: Our experimental set-up. By intervening on the generated tokens, we create branching paths to estimate the model's outcome distribution. By intervening on the model's activations, we steer the base generation towards a desired outcome.
Activation Steering and the Controllability–Uncertainty Link
Building on the interpretable geometry of LM representations, the paper applies a difference-in-means strategy to construct linear steering directions in hidden state space that shift the model's completions toward specific answers. For each outcome A, activations ht(A) (leading to A) and ht(A) (leading to other outcomes) are aggregated at each token position, yielding a mean-difference vector st(A). This vector, added to the residual stream at each token, enables targeted steering of the generation corridor.
Key findings include:
Quantitatively, the correlation between baseline uncertainty (probability mass of the intended answer in ot) and empirical steering success is moderate to strong (R=0.57 for the main example, R=0.64 averaged), indicating that effective controllability is a marker for model indecision.
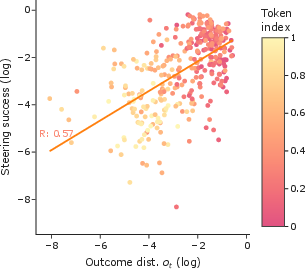
Figure 3: Correlation between steering success (y-axis) and base outcome probability (x-axis) across token positions.
These results imply that model steering by direct activation intervention is maximally potent only before the network has functionally broken degeneracies and settled on a reasoning path. This has implications for guided generation, safety, and interpretability: interventions are viable only during the model's "deliberation" phase and become inoperative once the final answer is encoded and rendered irrevocable in subsequent hidden states.
Predicting Outcome Distributions from Hidden Activations
To further examine whether a model’s hidden states embed information about alternate futures, the paper introduces a probing approach:
- At each token t, a linear probe is trained on the hidden activation ht to predict the empirical outcome distribution ot as constructed by FPA.
- To disentangle semantic from model-specific features, the probe is also applied to embeddings ht′ from a comparable LLM (Gemma-2 2B Instruct) presented with the same CoT prefix.
Both probes outperform random and majority-class baselines, with best performance in mid-to-late layers. However, probes on Llama’s own activations attain consistently lower KL divergence losses (e.g., $0.11$ at layer 8 for Llama versus $0.19$ for Gemma), especially in later layers. This demonstrates that the idiosyncratic hidden state transitions of a specific LLM—not merely the semantic content of the generated text—encode more detailed information about its own prospective branching completions.
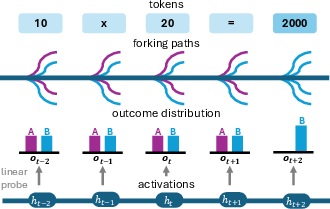
Figure 4: Our experimental set-up for Section \ref{sec:probe}.
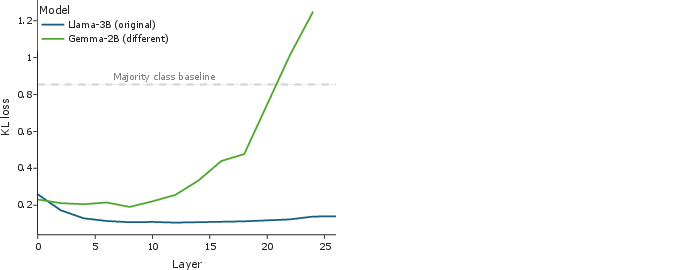
Figure 5: KL loss (lower is better) for linear probes predicting the outcome distribution of Llama from the hidden representations of Llama (blue) and Gemma (green) at the same token mid-generation. Low loss suggests that hidden states over chain-of-thought text are predictive of Llama's outcome distribution.
This provides strong evidence that a model’s internal representation progresses through intermediate states that retain probabilistic information about diverging outcome futures—information that is only partially accessible at the text level. Consequently, probing hidden activations offers an efficient, token-local analytical alternative to computationally expensive FPA tree expansions.
Additional Case Studies and Robustness
Supplementary analyses (Figure 6) demonstrate that the observed dynamics generalize across multiple datasets (GSM8k, AQuA, GPQA) and instances with strong answer uncertainty. The signature pattern—alignment between forking tokens, sharp drops in steering success, and abrupt changes in ot—holds consistently.
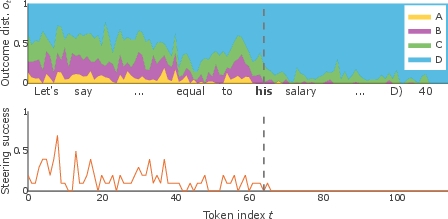
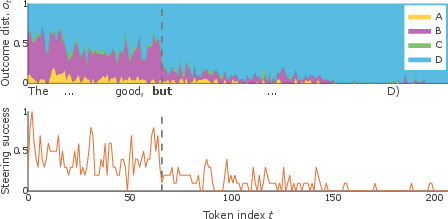
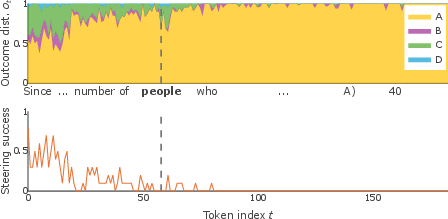
Figure 6: Three additional examples of steering analysis. Each column corresponds to a single example, with outcome distribution and steering success showing similar abrupt transitions at identified change points.
Implications and Future Directions
This work elucidates a direct mechanistic correspondence between token-level uncertainty, path dependency, and representational dynamics within transformer LLMs. Notably:
- Steering and uncertainty estimation can be operationally coupled: Interventions and probes can inform real-time uncertainty diagnostics and model calibration.
- Model-specific representation captures latent possibilities: Hidden activations faithfully encode not only the committed output sequence, but the probabilistic space of alternate completions.
- Activation-based interventions have intrinsic limits: Once the model's trajectory passes a decisional bottleneck (as defined by FPA/CPD), the space of reachable outputs collapses, sharply reducing steering sensitivity.
Practically, this work suggests that efficient estimation of a model’s internal uncertainty—and thus the identification of optimal intervention points—can be achieved via hidden state probing rather than brute-force generation. The theoretical implication is that LLMs realize probability distributions over reasoning paths not just in their outputs, but throughout the computation, with commitment encoded by discrete transitions in representation space.
Future research could extend these methods to larger or more open-ended models, study robustness to prompt variations, or develop real-time uncertainty-aware steering policies. Additionally, the distinction between semantic and model-specific representational components could be further dissected, possibly aiding in model alignment, safety, and interpretability.
Conclusion
By combining FPA, activation steering, and hidden state probing, this paper demonstrates that LLMs internally encode token-level uncertainty and preserve information about alternate reasoning paths during generation. The link between outcome uncertainty and controllability is empirically validated, and probing methods provide an efficient avenue for accessing outcome distributions, bypassing extensive resampling. These results have significant implications for understanding, controlling, and reliably deploying LLMs in settings where uncertainty and interpretability are paramount.