The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents
Abstract: Agents are now used widely in the process of software development, but building production-ready software engineering agents is a complex task. Deploying software agents effectively requires flexibility in implementation and experimentation, reliable and secure execution, and interfaces for users to interact with agents. In this paper, we present the OpenHands Software Agent SDK, a toolkit for implementing software development agents that satisfy these desiderata. This toolkit is a complete architectural redesign of the agent components of the popular OpenHands framework for software development agents, which has 64k+ GitHub stars. To achieve flexibility, we design a simple interface for implementing agents that requires only a few lines of code in the default case, but is easily extensible to more complex, full-featured agents with features such as custom tools, memory management, and more. For security and reliability, it delivers seamless local-to-remote execution portability, integrated REST/WebSocket services. For interaction with human users, it can connect directly to a variety of interfaces, such as visual workspaces (VS Code, VNC, browser), command-line interfaces, and APIs. Compared with existing SDKs from OpenAI, Claude, and Google, OpenHands uniquely integrates native sandboxed execution, lifecycle control, model-agnostic multi-LLM routing, and built-in security analysis. Empirical results on SWE-Bench Verified and GAIA benchmarks demonstrate strong performance. Put together, these elements allow the OpenHands Software Agent SDK to provide a practical foundation for prototyping, unlocking new classes of custom applications, and reliably deploying agents at scale.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “The OpenHands Software Agent SDK” in Simple Terms
What is this paper about?
This paper introduces a new toolkit (called an SDK) that helps people build smart software helpers—“AI agents”—that can write code, run programs, and fix bugs. The goal is to make these agents easy to build, safe to run, and reliable both on your laptop and on big servers.
What questions is the paper trying to answer?
Here are the main things the authors wanted to improve:
- How can we make AI coding agents flexible so they work both locally (on your computer) and remotely (in a secure server) without changing lots of code?
- How can we keep these agents safe and reliable, especially when they run commands or access files?
- How can we give people good ways to interact with the agents (like in VS Code, a browser, or the command line)?
- How can we design the system so it’s modular (built from parts) and easy to extend and test?
- Do these design choices still perform well on real tasks and benchmarks?
How does the system work? (Methods and approach, with simple explanations)
Think of the SDK as a well-organized workshop with clear stations and safety rules, designed to help a smart assistant get work done.
- What’s an SDK? An SDK (Software Development Kit) is a set of tools, code, and guidelines you use to build software. Here, it helps you build AI agents for software development.
- What’s an AI agent? An agent is like a smart assistant that can read instructions, think, use tools, and act in a computer environment (like editing files or running tests).
- What’s a sandbox? A sandbox is a safe, controlled room where the agent can run commands without risking the rest of your computer—like giving it a safe play area.
- What’s event-sourcing? Imagine the agent keeps a diary. Every action it takes (a message, a tool it used, a result it saw) gets written as a new diary entry (an “event”). This makes it easy to replay what happened, recover after crashes, and understand the agent’s history.
- What’s an LLM? LLM stands for LLM, like Claude or GPT. It’s the brain that reads and writes text, decides which tools to use, and plans steps.
- What’s MCP? MCP (Model Context Protocol) is a way to define and use external tools consistently across different models, so the agent can plug into tools like a web browser or file manager easily.
- What’s REST/WebSocket? These are standard ways computers talk over the internet. REST is like sending letters; WebSocket is like a live phone call for streaming updates.
The SDK is built around four big design principles (think of these as the workshop’s rules):
- Optional isolation (sandboxing): Run locally by default for fast testing, and switch to a sandbox only when needed for safety.
- One source of truth for state: The agent’s configuration doesn’t change as it runs; only the conversation diary (event log) changes. That makes replay and recovery predictable.
- Strict separation of concerns: The core agent is separate from apps (like CLI, web UI, or GitHub apps), so you don’t mix the agent’s brain with the user interface.
- Two-layer composability: You can mix and match packages (SDK, Tools, Workspace, Server), and safely add or replace typed parts like tools and agents.
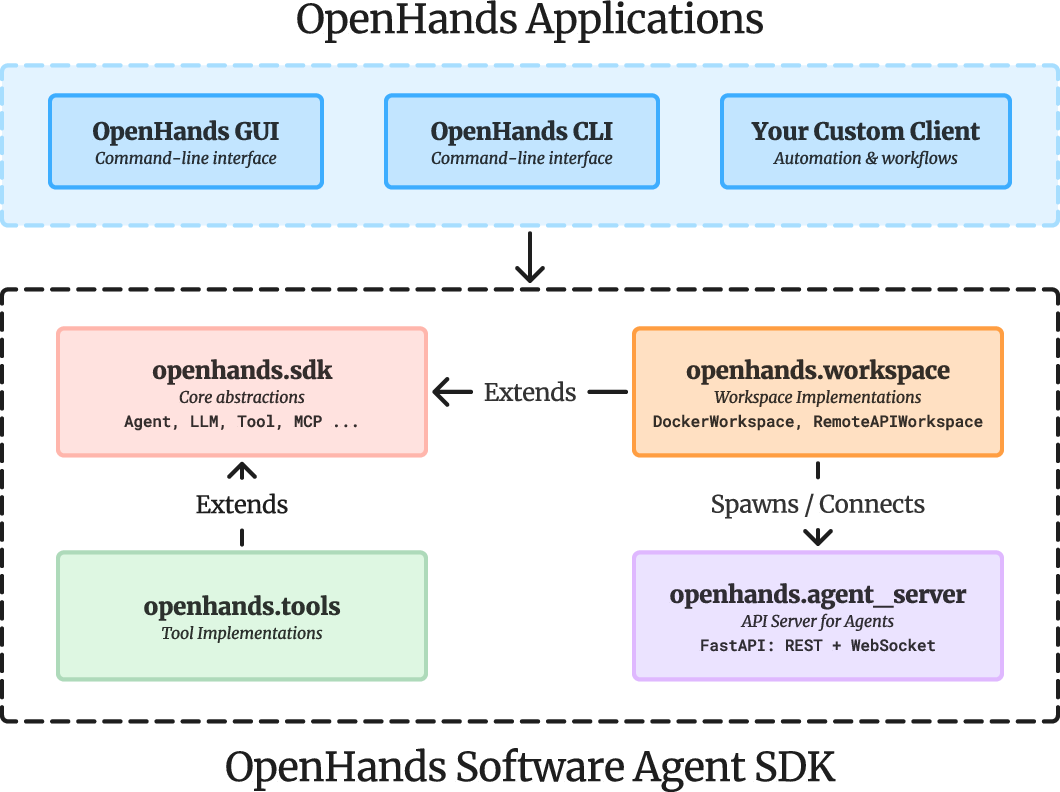
To make this work in real life, the SDK is split into four packages (like different workstations in the workshop):
- sdk: The core brains and rules (Agent, Conversation, LLM, Tool, events).
- tools: Actual tools the agent can use (e.g., run commands, edit files, browse).
- workspace: Where the agent runs (local machine vs. remote container).
- agent_server: A web server so agents can run remotely and stream events live.
Two particularly important ideas:
- Tools follow an “Action → Execution → Observation” pattern. The LLM asks to use a tool (Action), the tool runs (Execution), and the results are captured (Observation). This makes tools safe and predictable.
- Local to remote with minimal changes. You can start with a local workspace while testing. When you’re ready to deploy securely, you swap in a remote workspace (like Docker) with almost the same code.
The SDK also includes:
- Context window management (condensing long histories into summaries to keep model costs low).
- A Secret Registry (for safely handling API keys—masking them so they don’t leak).
- A Security Analyzer and Confirmation Policy (the agent can pause and ask for approval if something looks risky—like deleting files).
What did they find? (Main results and why they matter)
The authors compared their SDK to other major ones (from OpenAI, Claude, and Google) and highlighted features that make OpenHands stand out, including:
- Built-in secure remote execution with a production server.
- Model-agnostic support for 100+ LLM providers, plus smart routing across models (choose cheaper or more capable models depending on the task).
- Native sandboxing and lifecycle controls (pause/resume, restore history, delegate tasks to sub-agents).
- Integrated security checks and secret masking.
- Support for models that don’t have “function calling” by teaching them how to use tools through prompts.
Performance-wise, they tested on two recognized benchmarks:
- SWE-Bench Verified (coding and bug-fixing tasks): Strong resolution rates (up to about 72% with Claude Sonnet 4.5).
- GAIA (general computer tasks): Competitive scores (up to about 68% with Claude Sonnet 4.5).
These results show that the SDK is not just flexible—it also works well on real tasks.
Why is this important? (Implications and impact)
- Faster prototyping and safer deployment: Developers can try ideas locally and then deploy to secure servers without rewriting their code.
- Greater reliability: Event logs and deterministic state make it easier to debug, replay, and recover long-running agent sessions.
- Better security: Built-in risk checks and secret handling help prevent unsafe actions and leaks.
- More flexibility: You can use many different LLMs, add custom tools, and build complex behaviors without touching the core system.
- Community-friendly: It’s open-source (MIT License), so teams, researchers, and companies can adopt, extend, and collaborate.
In short, this SDK gives people a solid foundation to build powerful, safe, and scalable AI software agents—making it easier to move from cool demos to real, production-ready systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and missing evidence that future work could address.
- Sandbox vs. local execution trade-offs are not quantified: no measurements of latency, throughput, crash isolation, resource contention, or failure rate differences between LocalWorkspace and containerized RemoteWorkspace across representative workloads.
- Absence of a formal security threat model and end-to-end security evaluation: the paper does not detail attack surfaces (privilege escalation, filesystem exfiltration, tool supply-chain compromise, MCP server trust boundaries, API server attacks) or demonstrate effective mitigations via penetration testing or red-team exercises.
- Default “local-first” execution implies elevated risk on user machines: the safety implications of opting out of sandboxing by default are not analyzed, and policy guidance for when to enforce isolation is missing.
- LLMSecurityAnalyzer reliability and calibration are unproven: there is no empirical assessment of false negative/positive rates in risk ratings, susceptibility to prompt injection/adversarial examples, or alignment with a standardized risk taxonomy.
- ConfirmationPolicy UX and efficacy are not evaluated: no data on user burden, time-to-approval, rates of unnecessary blocks, or overall impact on task success; UI/UX design for confirmations is not studied.
- SecretRegistry lacks concrete operational guarantees: the paper omits cipher choices, key storage/rotation strategy, HSM/KMS integration, secure lifecycle of secrets in memory, and evidence that masking prevents leakage via side channels (logs, file writes, screenshots).
- Event-sourcing semantics need rigor: exactly-once processing, idempotency of tool actions, event ordering under concurrency, schema versioning/migration strategies, and cross-version replay guarantees are not specified or validated.
- “Deterministic replay” is underspecified given LLM nondeterminism: how replay interacts with variable LLM outputs (temperature, provider changes), and whether seeds or cached responses are used to ensure reproducibility, is unclear.
- RemoteConversation reliability under network faults is not discussed: retry policies, backoff strategies, idempotent REST endpoints, WebSocket reconnection behavior, and consistency after partial failures are not described or measured.
- MCP integration robustness is untested: handling of MCP server version drift, schema evolution, timeouts, authentication/authorization, and the security model for executing untrusted MCP tools are not evaluated.
- Non-native function calling via prompt+regex lacks reliability analysis: no error-rate quantification (mis-parsing, tool-call hallucinations), injection-safety assessment, or fallback mechanisms are provided.
- Multi-LLM routing strategies are minimal: no learning-based or feedback-driven routing, cost–quality optimization, or empirical evidence that routing improves performance/cost; selection criteria beyond a toy multimodal example are unspecified.
- Context condensation risks and tuning are underexplored: the impact of summarization errors on task outcomes, parameter sensitivity (condense thresholds, summary granularity), and comparisons of condenser algorithms are not empirically characterized.
- Sub-agent delegation is limited to blocking execution: no support for asynchronous coordination, dynamic scheduling, inter-agent communication, failure recovery of sub-agents, or resource management across delegated tasks.
- Long-term memory across sessions is not supported: the table indicates this feature is missing; design, safety implications (privacy), and empirical benefits or risks are unresolved.
- Benchmark scope is narrow and lacks ablations: results are limited to SWE-Bench Verified and GAIA with no ablation isolating architectural contributions (e.g., event-sourcing, condensation, routing), no sensitivity to workspace types, and no cost/latency benchmarks.
- Reproducibility is uncertain: reliance on frontier proprietary models (e.g., Claude Sonnet, GPT-5) lacks details on exact versions, temperatures, prompts, provider configurations, and mitigations for provider-side nondeterminism.
- Production scaling characteristics are not reported: throughput per agent/server, resource footprints, multi-tenant isolation and fairness, autoscaling policies, and queueing under load are not measured.
- Observability and governance are incomplete: logging/tracing/metrics design, PII handling in event logs, retention policies, auditability, and compliance (e.g., GDPR/CCPA) are not specified.
- API server security controls are not detailed: authentication/authorization (RBAC), per-tenant isolation boundaries, secure transport, rate limiting/DoS protections, and secret-handling over the wire are not described.
- Tool registry and dynamic executor resolution pose trust risks: the security model for binding tool definitions at runtime, code injection mitigation, and provenance validation of tool executors are not addressed.
- Human-in-the-loop interaction is underexamined: conflict resolution when users edit files concurrently with the agent, UX for interactive terminals/IDEs, and the cognitive load and acceptance of intervention workflows are not studied.
- Failure handling and compensating actions are unspecified: policies for partial tool effects (e.g., partially applied edits), transactional semantics across tools, and recovery strategies after mid-step failures are not described.
- Testing strategy may be brittle to model drift: LLM-based CI lacks coverage metrics, flakiness analysis, and controls for provider changes; how tests gate releases or detect subtle regressions is unclear.
- Compatibility and migration guidance is missing: how third-party tools/MCP integrations upgrade across SDK versions, event schema changes, and backward compatibility guarantees are not documented.
- Ethical and compliance considerations are unexplored: safeguards for agents acting on external systems (e.g., web, code repos), guardrails for destructive actions, and organizational policy integration are not discussed.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, supported by the SDK’s modular architecture, event-sourced reliability, opt-in sandboxing, REST/WebSocket server, MCP integration, multi-LLM routing, security/confirmation controls, and strong benchmark performance.
- Automated bug triage and patching in CI/CD
- Sectors: software, DevOps
- Tools/workflows:
Conversationwith local repo,DockerWorkspacefor isolated runs,get_default_agent, built-in test instrumentation; SWE-Bench-like workflows to reproduce, edit, run tests, and open PRs - Assumptions/dependencies: Accessible test suites and CI runners; LLM coding proficiency and API keys; repo permissions; guardrails via
SecurityAnalyzer/ConfirmationPolicy
- Agent-powered remote sandboxes for developers and support teams
- Sectors: software, customer support, IT operations
- Tools/workflows:
agent_server+DockerWorkspacewith VS Code Web/VNC/Chromium for reproducing issues, inspecting environments, and guided fixes - Assumptions/dependencies: Container orchestration (Docker/Kubernetes), network access to agent server, role-based access control (RBAC)
- Secure, policy-gated local automation for enterprise desktops
- Sectors: finance, healthcare, gov/public sector
- Tools/workflows:
SecretRegistrywith auto-masking,SecurityAnalyzer+ConfirmRiskypolicies, opt-in sandboxing; controlled file edits, git operations, browsing - Assumptions/dependencies: Enterprise secrets store integration; policy configuration; audit needs met via event logs and deterministic replay
- Cost-optimized multi-LLM routing for agent tasks
- Sectors: software, cloud ops, platform engineering
- Tools/workflows:
RouterLLMroutes text-only steps to cheaper models and multimodal steps to stronger models; LiteLLM across 100+ providers - Assumptions/dependencies: Model availability via LiteLLM; routing policy tuned to task complexity; cost/latency monitoring
- Unifying internal tools via MCP for a single agent interface
- Sectors: enterprise software, data platforms
- Tools/workflows: MCP tools treated as first-class via
MCPToolDefinitionandMCPToolExecutor; standardize tool schemas and results - Assumptions/dependencies: MCP servers for internal tools; tool schema hygiene; secure transport and credentials
- Reproducible, auditable agent sessions for compliance and debugging
- Sectors: compliance, risk, SRE/ops
- Tools/workflows: Event-sourced
ConversationState, deterministic replay, pause/resume; build “agent observability” dashboards over REST/WS streams - Assumptions/dependencies: Persistent storage for
base_state.jsonand event JSONs; log retention policies; PII/secret redaction configured
- Automated QA and test generation in development workflows
- Sectors: software, QA, platform engineering
- Tools/workflows: Built-in programmatic and LLM-based tests; example/integration test harness (
BaseIntegrationTest); generate unit/integration tests and run them - Assumptions/dependencies: Access to test runners and environments; cost budgets for LLM test passes; CI integration
- Education: agent-assisted programming labs and remote IDEs
- Sectors: education, bootcamps
- Tools/workflows:
LocalConversationfor quick iteration in notebooks;DockerWorkspacefor class assignments in isolated containers; skills loaded from.openhands/skills/ - Assumptions/dependencies: Course infrastructure providing per-student containers; API keys; instructor policies for confirmation/risk
- Research: reproducible agent experiments and benchmarking
- Sectors: academia, industrial research
- Tools/workflows: Same agent spec across local/remote; built-in support for SWE-Bench Verified and GAIA; event logs for rigorous ablation/replay
- Assumptions/dependencies: Benchmark datasets and harnesses; standardized tool suites; model access (e.g., Claude Sonnet 4.5, GPT-5 variants)
- Browser automation for ops tasks and knowledge work
- Sectors: operations, customer support, marketing
- Tools/workflows: Persistent Chromium in remote workspace; structured tools for browsing, scraping, and screenshot capture with secret redaction
- Assumptions/dependencies: Site policies/legal compliance for scraping; resource quotas to prevent container crashes; human-in-the-loop confirmation for risky actions
- Personal project maintenance and local coding assistant
- Sectors: daily life
- Tools/workflows:
LocalConversationto create/edit files, run commands, manage small repos; conditional skills and tool prompts; user confirmation on sensitive actions - Assumptions/dependencies: Local dev environment; API keys; basic policy settings to prevent destructive commands
Long-Term Applications
The following applications require further research, scaling, or development—especially around orchestration, safety, compliance, and organizational adoption.
- Autonomous software maintenance at org scale
- Sectors: software, platform engineering
- Tools/workflows: Hierarchical agents with advanced (async) delegation, dynamic scheduling, fault-tolerant recovery; standardized change management and PR pipelines
- Assumptions/dependencies: Robust sub-agent orchestration beyond current blocking tools; enterprise-grade guardrails; team trust and governance
- Agent-as-a-Service platforms and marketplaces
- Sectors: cloud platforms, developer tools
- Tools/workflows: Multi-tenant
agent_serverwith tool registry; per-tenant isolation; usage metering and billing; curated MCP tool catalogs - Assumptions/dependencies: SaaS ops maturity (quotas, isolation, billing), curated tool quality and security vetting, SLAs
- Enterprise compliance and audit suites for AI agents
- Sectors: finance, healthcare, gov/public sector
- Tools/workflows: Policy engines over event logs, standardized risk taxonomies; audit/forensics dashboards; continuous DLP monitoring
- Assumptions/dependencies: Regulatory acceptance of agent logs as audit artifacts; integration with GRC systems; formalized policies and attestations
- Formal methods and static analysis integrated with the security analyzer
- Sectors: software, safety-critical systems
- Tools/workflows: Combine
SecurityAnalyzerwith program analysis, sandbox escape detection, and formal verification of changes/tests - Assumptions/dependencies: Mature static/dynamic analyzers; mappings from tool outputs to formal guarantees; model + tool reliability
- Cross-application desktop automation with robust UI agents
- Sectors: productivity software, RPA/robotics
- Tools/workflows: General desktop agents coordinating terminal, browser, editors, and enterprise apps with MCP tools; consistent UI state tracking
- Assumptions/dependencies: Reliable computer-use (GAIA-like) capabilities; better multimodal perception; tight OS/app permissions
- Persistent, organization-wide agent memory and knowledge graphs
- Sectors: knowledge management, internal tooling
- Tools/workflows: Long-term memory across sessions (feature listed as not yet supported), knowledge consolidation via condensers and embeddings, cross-project recall
- Assumptions/dependencies: Secure and compliant memory stores; indexing/search over event logs; privacy-preserving recall policies
- Auto-adaptive multi-LLM routing based on real-time performance and cost
- Sectors: platform engineering, cost optimization
- Tools/workflows: Feedback-driven
RouterLLMselecting models by task type, latency, accuracy, and budget; continuous evaluation loops - Assumptions/dependencies: Reliable telemetry on per-step outcomes; automated routing policy training; provider diversity and stability
- Sector-specific agents with regulatory-grade workflows
- Sectors: healthcare (clinical coding, claim validation), energy (config updates for grid software), finance (policy-driven code changes)
- Tools/workflows: Domain-specific tools via MCP, pre-approved change templates, confirmation gates by risk; comprehensive audit trails
- Assumptions/dependencies: Deep domain tooling; regulator-aligned processes; organizational buy-in for agent-mediated changes
- Human-in-the-loop governance dashboards for production agents
- Sectors: platform engineering, security/compliance
- Tools/workflows: Real-time event streaming (WebSocket) to monitor thoughts/actions/observations, pause/resume, approve/reject, rollbacks via deterministic replay
- Assumptions/dependencies: Usability for non-experts; policy-compliant redaction; integration with incident and change management systems
- Standardization efforts for agent interoperability (MCP-first ecosystems)
- Sectors: standards bodies, open-source communities
- Tools/workflows: Shared schemas for tools/events/security annotations; certification processes for tool servers; reference implementations
- Assumptions/dependencies: Broad MCP adoption; community governance; vendor cooperation across model and tool providers
- Large-scale ops automation (data pipelines, infra-as-code changes)
- Sectors: data engineering, cloud ops
- Tools/workflows: Agents coordinating changes across repos/services with confirmation policies; scheduling windows; post-change validation
- Assumptions/dependencies: Robust multi-repo orchestration and rollback; strong safeguards; organizational change control practices
- Public-sector agent governance pilots
- Sectors: public sector, digital services
- Tools/workflows: Limited-scope deployments with opt-in sandboxing, event-sourced accountability, risk gating; independent audits of agent behavior
- Assumptions/dependencies: Policy frameworks for agent operations; procurement and security reviews; public trust and transparency practices
Glossary
- Action–Execution–Observation pattern: A tooling abstraction where inputs (actions) are validated, executed, and returned as structured observations. "The V1 tool system provides a type-safe and extensible framework grounded in an ActionâExecutionâObservation pattern."
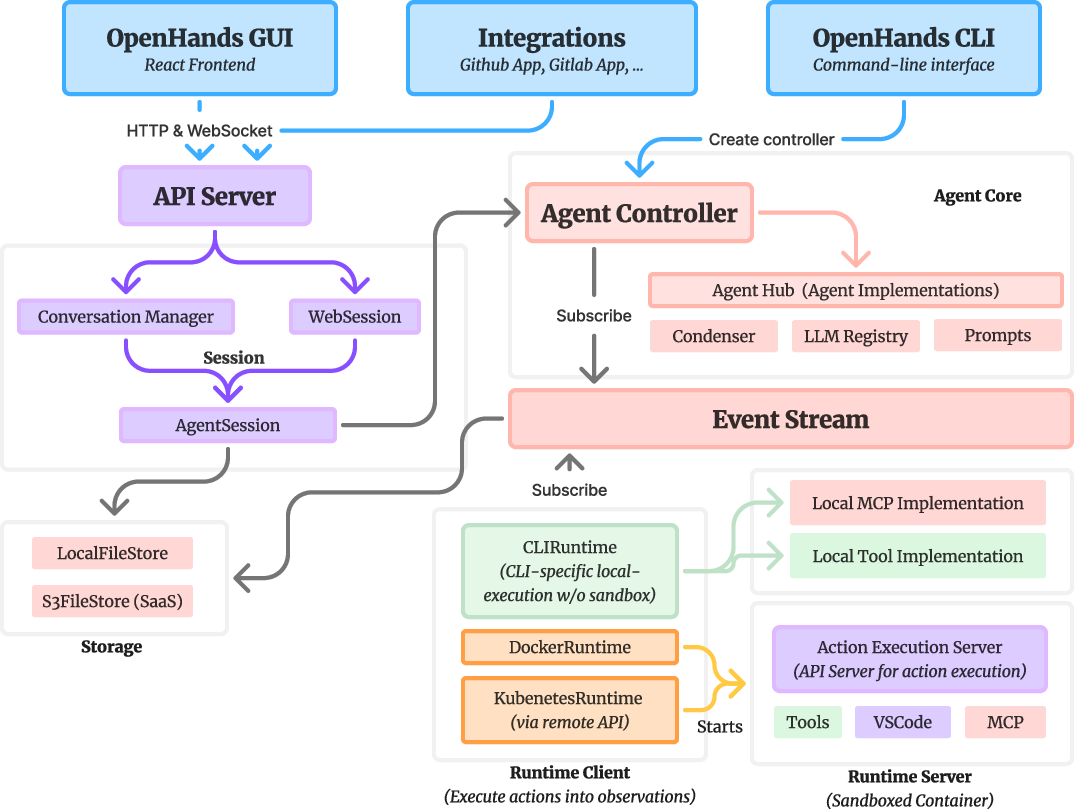
- Agent Server: The server component that executes agents remotely and streams events over APIs. "At the deployment level, its four modular packagesâSDK, Tools, Workspace, and Agent Serverâcombine flexibly to support local, hosted, or containerized execution."
- AgentContext: A configuration object that shapes LLM behavior via prompts, skills, and optional tools. "AgentContext centralizes all inputs that shape LLM behavior, including prefixes/suffixes for system/user messages and user-defined Skill objects."
- API-managed runtime: A remote execution environment managed via an API for running workspaces or agents. "â¦a containerized server (DockerWorkspace) or a API-managed runtime (APIRemoteWorkspace)."
- append-only EventLog: An immutable log of events capturing all agent interactions in order. "â¦all changing variables live in ConversationState, making it the only stateful component. This class maintains two types of state⦠and (2) an append-only EventLog recording all agent interactions."
- Chat Completions API: A standard LLM API interface for chat-based completions used across providers. "Through LiteLLM, it supports 100+ providers with two APIs: the standard Chat Completions API for broad compatibilityâ¦"
- CondensationEvent: An event recording the result of history condensation and what was summarized. "The results of any given condensation are stored in the event log as a CondensationEvent."
- Condenser system: A mechanism to summarize and drop history so it fits within the LLM context window. "To ensure the ever-growing history fits inside the LLM's context, the Condenser system drops events and replaces them with summaries whenever the history grows too large."
- ConfirmRisky: A built-in confirmation policy that blocks execution above a specified risk threshold. "â¦LLMSecurityAnalyzer, which appends a security_risk field to tool calls, and ConfirmRisky policy, which blocks actions exceeding a configurable risk threshold (default: high)."
- ConfirmationPolicy: A policy that determines when user approval is required before executing actions. "â¦the ConfirmationPolicy, which determines whether user approval is required before execution based on the actionâs details and assessed risk."
- ConversationState: The single source of mutable state for an agent’s execution, with metadata and event log. "â¦all changing variables live in ConversationState, making it the only stateful component."
- Discriminated unions: A type system pattern enabling safe serialization/deserialization of variant event types. "â¦with type-safe serialization via discriminated unions \citep{pydantic_discriminated_unions}."
- DockerWorkspace: A workspace implementation that runs agent workloads inside a Docker container. "from openhands.workspace import DockerWorkspace"
- Event-Driven Execution: An execution model where agents advance by emitting and processing structured events. "Event-Driven Execution."
- Event-Sourced State Management: A state model where all changes are captured as immutable events for replay and recovery. "Event-Sourced State Management"
- EventStore: The persistence layer that writes individual event JSON files for incremental durability. "â¦while EventStore persists events as individual JSON files to the corresponding directory."
- FastMCP: An implementation used to connect to MCP servers and manage transport. "MCPToolExecutor delegates execution to FastMCPâs MCPClient, which manages server communication and transport details."
- FIFO lock: A lock ensuring first-in-first-out ordering for thread-safe state updates. "A FIFO lock ensures thread-safe updates through a two-path patternâ¦"
- GAIA: A benchmark suite for evaluating general agentic task-solving capability. "â¦strong results on SWE-Bench Verified and GAIA benchmarksâ¦"
- Kubernetes: A container orchestration system used for production deployments. "â¦local Docker, Kubernetes in productionâ¦"
- LiteLLM: A compatibility layer that routes requests to many LLM providers via unified APIs. "Through LiteLLM, it supports 100+ providersâ¦"
- LLMConvertibleEvent: An event type that can be converted into messages consumable by an LLM. "LLMConvertibleEvent adds to_llm_message() for converting events into LLM format."
- LLMSecurityAnalyzer: An analyzer that uses LLMs to assess the risk of proposed actions. "The SDK includes a built-in pair: LLMSecurityAnalyzer, which appends a security_risk field to tool callsâ¦"
- LLMSummarizingCondenser: The default condenser that uses an LLM to summarize history. "LLMSummarizingCondenser (the default condenser) has been shown to reduce API costs by up to with no degradation in agent performanceâ¦"
- LocalConversation: An in-process execution mode for rapid iteration without network/container overhead. "LocalConversation provides the simplest and most direct execution mode of the SDKâ¦"
- LocalWorkspace: A workspace implementation that runs directly on the host filesystem and shell. "Local Workspace executes in-process against the host filesystem and shellâ¦"
- Model Context Protocol (MCP): A protocol for agents and tools to communicate with shared context and capabilities. "â¦the Model Context Protocol (MCP; \citealt{mcp2025intro})."
- MCPClient: The client used to connect to and invoke MCP tools. "â¦FastMCPâs MCPClient, which manages server communication and transport details."
- MCPToolDefinition: A tool definition that adapts MCP tool schemas into the SDK’s tool model. "MCPToolDefinition extends the standard ToolDefinition interfaceâ¦"
- MCPToolExecutor: An executor that forwards tool calls to an MCP server. "â¦while MCPToolExecutor delegates execution to FastMCPâs MCPClientâ¦"
- Model-agnostic multi-LLM routing: The ability to route requests across many model providers without vendor lock-in. "â¦model-agnostic multi-LLM routing across 100+ providers."
- Multi-LLM routing: Selecting different LLMs for different requests within the same agent session. "Multi-LLM Routing Support."
- NonNativeToolCallingMixin: A mixin that emulates function-calling by parsing tool calls from text outputs. "â¦the SDK implements a NonNativeToolCallingMixin, which converts tool schemas to text-based prompt instructions and parses tool calls from model outputsâ¦"
- ObservationBaseEvent: The base class for events representing tool execution results. "The action-observation loop uses ActionEvent for tool calls and ObservationBaseEvent subclasses for resultsâ¦"
- OpenAI Responses API: A newer OpenAI API used for advanced reasoning models. "â¦and the newer OpenAI Responses API for latest reasoning models."
- opt-in sandboxing: A security model where sandboxing is optional and applied only when needed. "V1 refactors this into a modular SDK with clear boundaries, opt-in sandboxing, and reusable agent, tool, and workspace packages."
- Pydantic models: Data classes with validation and serialization used to define immutable components. "V1 treats all agents and their componentsâtools, LLMs, etcâas immutable and serializable Pydantic models validated at construction."
- ReasoningItemModel: A schema capturing structured reasoning traces from OpenAI models. "â¦and ReasoningItemModel for OpenAI's reasoning."
- RemoteConversation: A conversation executed via an API server, streaming events over WebSocket. "â¦constructs a RemoteConversation, which serializes the agent configuration and delegates execution to an agent server over HTTP and WebSocket."
- RemoteWorkspace: A workspace implementation delegating operations over HTTP to an Agent Server. "When provided a RemoteWorkspace, the same call transparently constructs a RemoteConversationâ¦"
- REST/WebSocket server: A server exposing HTTP endpoints and WebSocket streams for remote agent execution. "â¦a built-in REST/WebSocket server for remote executionâ¦"
- RouterLLM: An LLM wrapper that dynamically routes requests to selected underlying models. "SDK features RouterLLM, a subclass of LLM that enables the agent to use different models for different LLM requests."
- SaaS-style multi-tenancy: Serving multiple users with isolated containers within a hosted service. "This containerized design simplifies deployment and enables SaaS-style multi-tenancy while preserving workspace isolation."
- SecretRegistry: A per-conversation secret manager with masking and secure retrieval. "SecretRegistry provides secure, late-bound, and remotely manageable credentials for tool execution."
- SecurityAnalyzer: A component that rates the risk of tool actions (e.g., low/medium/high/unknown). "â¦the SecurityAnalyzer, which rates each tool call as low, medium, high, or unknown riskâ¦"
- Stateless by default: A design principle where components are immutable, with all mutable context in a single state object. "Stateless by Default, One Source of Truth for State."
- Sub-Agent Delegation: A mechanism allowing an agent to spawn and coordinate sub-agents as tools. "Sub-Agent Delegation."
- SWE-Bench Verified: A benchmark evaluating software engineering agent capabilities. "Across multiple LLM backends, our SDK achieves strong results on SWE-Bench Verified and GAIA benchmarksâ¦"
- ThinkingBlock: Anthropic-specific structure for extended thinking content. "â¦such as ThinkingBlock for Anthropic's extended thinkingâ¦"
- ToolExecutor: The callable that performs a tool’s logic when given a validated action. "â¦the Toolâs actual logic via the ToolExecutor, which receives a validated Action and performs the underlying execution."
- Tool Registry: A registry used to resolve tool specifications into runnable implementations at runtime. "Tool Registry and Distributed Execution."
- typed component model: A design allowing safe extension by replacing strongly typed components. "â¦the SDK exposes a typed component modelâtools, LLMs, contexts, etcâso developers can extend or reconfigure agents declarativelyâ¦"
- VNC desktop: A browser-accessible remote desktop provided with the agent server. "â¦a browser-based VSCode IDE, VNC desktop, and persistent Chromium browserâfor human inspection and control."
- VSCode IDE: A browser-based IDE integrated for interactive inspection and control. "â¦a browser-based VSCode IDE, VNC desktop, and persistent Chromium browserâfor human inspection and control."
- WAITING_FOR_CONFIRMATION: An agent state indicating execution is paused pending user approval. "When approval is required, the agent pauses in a special WAITING_FOR_CONFIRMATION stateâ¦"
- Workspace factory: A factory that chooses local or remote workspace implementations transparently. "The factory Workspace(\ldots) resolves to local when only working_dir is provided and to remote when host/runtime parameters are presentâ¦"
Collections
Sign up for free to add this paper to one or more collections.