Why Less is More (Sometimes): A Theory of Data Curation
Abstract: This paper introduces a theoretical framework to resolve a central paradox in modern machine learning: When is it better to use less data? This question has become critical as classical scaling laws suggesting more is more'' (Sun et al., 2025) are challenged by methods like LIMO (less is more'') and s1 (Ye et al., 2025; Muenighoff et al., 2025), which achieve superior performance with small, aggressively curated datasets. Here, we study data curation strategies where an imperfect oracle selects the training examples according to their difficulty and correctness. Our results provide exact scaling law curves for test error under both label-agnostic and label-aware curation rules, revealing when and why keeping only a subset of data can improve generalization. In contrast to classical scaling laws, we show that under certain conditions, small curated datasets can outperform full datasets, and we provide analytical conditions for this by deriving precise phase transition curves tied to data size and quality. We validate these theoretical claims with empirical results on ImageNet, confirming our predictions about when curation improves accuracy and can even mitigate model collapse. Furthermore, our framework provides a principled explanation for the contradictory curation strategies recently observed in LLM mathematical reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but surprising question: Is it always best to train AI models on as much data as possible? The authors show that the answer is “not always.” Sometimes, using less data—carefully chosen—can make a model learn better and more safely. They build a clear theory that explains when “less is more” and when “more is more,” and they test these ideas on real image and language tasks.
Key Questions
The paper looks at three big questions in easy-to-understand terms:
- When does keeping only a small, high-quality part of a dataset help a model perform better than using all the data?
- How should we decide which examples to keep? Should we keep “easy” examples, “hard” examples, or only examples with correct labels?
- Can smart data selection prevent “model collapse,” where a model’s performance gets worse over time when it trains on its own noisy or synthetic data?
Methods and Approach
Think of training an AI like studying for a test.
- The “generator” is like the source that created your practice problems. If it’s very accurate, it gives you good questions and answers. If it’s off, some answers might be wrong.
- The “oracle” (or “pruner”) is like a tutor who decides which practice problems you should keep. The tutor can judge problem difficulty and sometimes whether an answer looks correct.
- The “curation strategy” is the rule for picking problems, such as:
- Keep hard problems (to stretch skills).
- Keep easy problems (to learn basics first).
- Keep only problems with correct answers (avoid bad examples).
The authors study a simple, well-understood type of model (a linear classifier) and measure how often it makes mistakes on new, unseen data (the “test error”). They do this in a “high-dimensional” setting—imagine problems with lots of features—so they can use powerful math tools to predict performance very precisely.
To keep things grounded:
- “Label-agnostic curation” means the tutor picks examples based only on features (how a problem looks), not whether the label/answer is correct.
- “Label-aware curation” means the tutor also checks whether the example’s label/answer seems right, and discards those that look wrong.
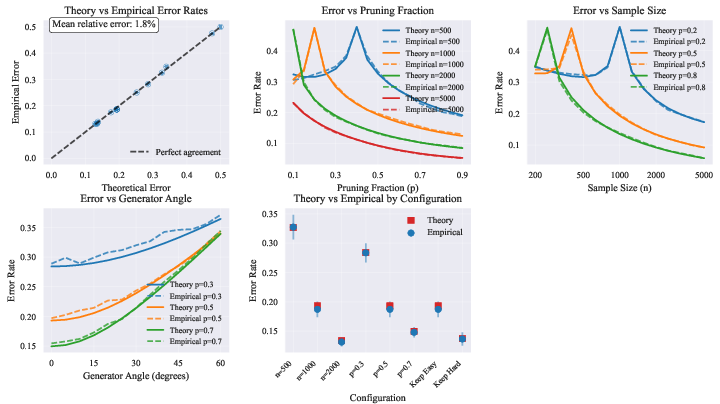
They use advanced math (random matrix theory) to derive exact curves that show test error depending on:
- How good the generator is (how closely its labels match the true labels).
- How good and well-aligned the oracle is (how well the tutor’s sense of difficulty and correctness matches the real task).
- How much data you keep after pruning (the pruning ratio).
- The size of the dataset compared to the number of features.
Finally, they validate these predictions with experiments on ImageNet (a big image dataset) and connect the results to LLM reasoning tasks.
Main Findings
Here are the key takeaways, presented in simple terms:
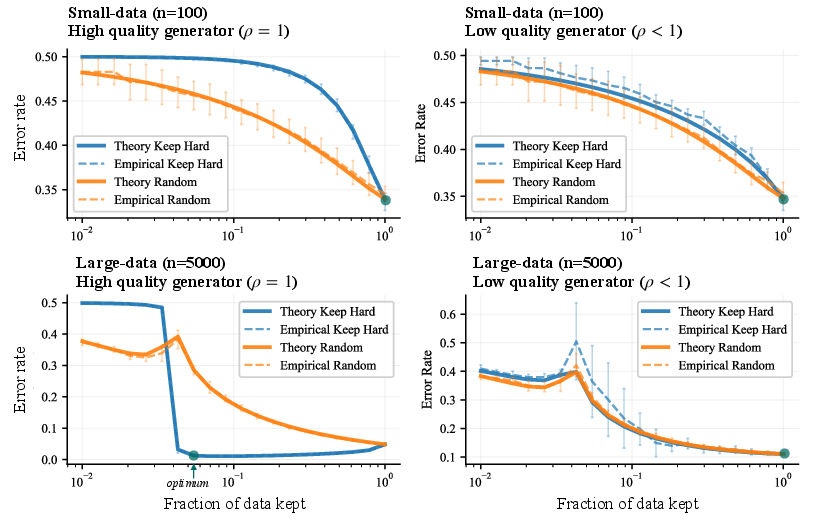
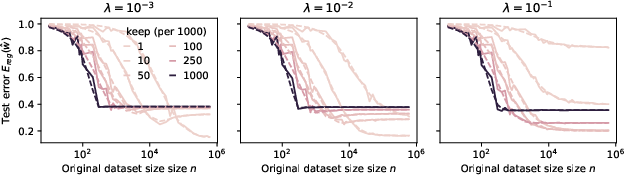
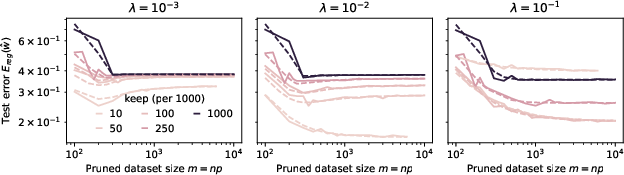
- Less is more—but only sometimes. If your base model (or data generator) is already strong and you have plenty of data, keeping a smaller set of hard, clean examples can beat training on everything. This sharpens skills and avoids wasting time on unhelpful data.
- More is more—when you’re still learning or data is scarce. If your model is weak or you don’t have much data, you should keep more examples (and often keep the easier ones) to build a solid foundation first.
- There’s a “crossover point.” The best strategy flips depending on model strength and dataset size. The authors give exact conditions and curves that show where this flip happens.
- Checking correctness matters. If your pruning oracle can filter out examples with wrong labels, curated small datasets can perform even better.
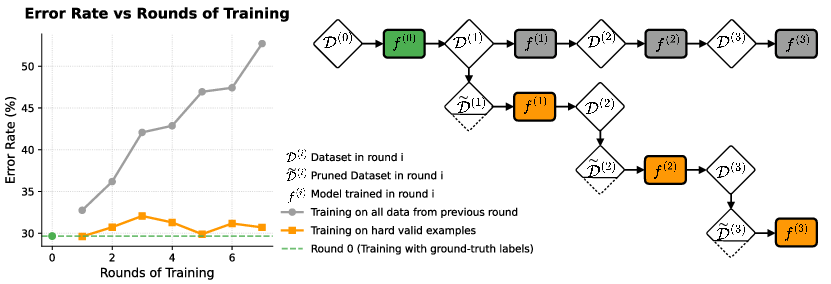
- Smart curation can prevent model collapse. When a model learns from its own synthetic or noisy outputs over and over, it can degrade. Selecting only challenging, correct examples at each step helps keep performance stable.
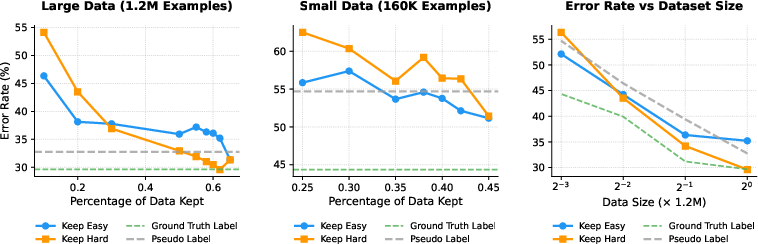
- The theory explains real-world puzzles. In LLM math tasks:
- For average-level questions, aggressive curation of hard, high-quality examples boosts performance (less is more).
- For the hardest questions, using more data helps (more is more), because the model needs broad exposure to learn those tougher skills.
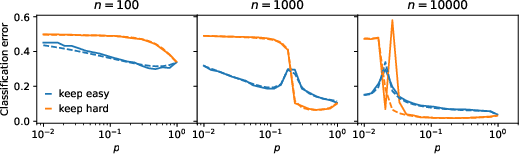
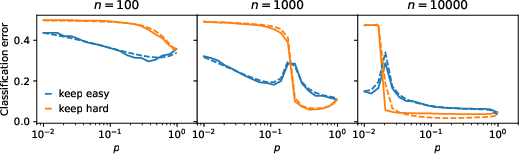
- The predictions match experiments on ImageNet. With a small initial training set, keeping easy examples is best. With a large initial set, keeping hard examples wins.
Why It Matters
This work gives clear guidance for building training datasets:
- It helps you decide when to prune and how much to prune, instead of always believing “more data is always better.”
- It saves compute and money by focusing training on examples that matter most.
- It makes training safer over time by reducing the risk of model collapse.
- It explains why some recent “less is more” successes (like LIMO and s1) work and when to apply them.
Implications and Potential Impact
- Smarter training pipelines: Teams can design data selection rules that adapt as models improve—start broad and easy, then prune to hard and clean.
- Better use of synthetic data: Instead of throwing it out or blindly using it, filter it with a good oracle to keep only helpful examples.
- Clearer evaluation and scaling strategies: The theory tells you how performance should scale with data size and quality, guiding resource choices.
- Future directions: Extend these ideas to non-linear deep networks, make curation adaptive over multiple training rounds, and test across different types of data (text, code, speech). This can also help address fairness, privacy, and energy use by reducing unnecessary training on low-value data.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions that the paper leaves unresolved. Each item highlights what is missing or uncertain and suggests actionable directions for future work.
- Nonlinear models and deep networks: The theory is developed for linear models with squared loss; it remains unknown how the scaling laws and phase transitions change for logistic loss, hinge loss, kernel methods, random features, NTK, or finite-width/deep neural networks.
- Loss-function dependence: Classification is evaluated using sign of a ridge-regression solution trained with L2 loss. The robustness of the conclusions to standard classification losses (logistic/hinge/focal) is not analyzed.
- Multi-class settings: The framework is binary; extensions to multi-class or multilabel classification, and how curation interacts with class imbalance, are unaddressed.
- Non-Gaussian and heavy-tailed features: Results assume Gaussian features; performance under non-Gaussian, heavy-tailed, or sub-exponential distributions typical in language/vision remains theoretically and empirically unexplored.
- General covariances in practice: Main results are in the isotropic case (Σ = Cg = I). Although generalizations are deferred to the appendix, there is no systematic empirical study of anisotropic or low-rank/structured covariances reflecting real datasets.
- Label noise beyond label shift: The data model uses deterministic labels y = sign(x⊤wg). Effects of stochastic label noise, adversarial label flips, or annotation errors (beyond generator/ground-truth misalignment) are not analyzed.
- Measuring and estimating alignment (ρ, ρg, ρ): The theory relies on cosines between latent directions (wg, wo, w). Practical procedures to estimate these quantities (or proxies) from finite data are not specified, nor is their finite-sample reliability.
- Oracle quality and reliability: Sensitivity of results to imperfect or adversarial pruners (ρ* small or negative) is not characterized; conditions under which curation harms performance with misaligned oracles (ρg ≤ 0) remain open.
- Label-aware curation derivatives: The label-aware constants use distribution-theoretic derivatives for binary q. A rigorous, constructive procedure to compute/approximate these terms for discontinuous q in practice is not provided.
- Soft weighting vs hard pruning: The model only allows p_i ∈ {0,1}. Whether soft instance-weighting (0 ≤ w_i ≤ 1) yields superior or more stable scaling laws, and how to optimally set weights, is not addressed.
- Designing optimal q under constraints: While “keep hard” and “keep easy” emerge as optimal in extremes, there is no constructive recipe to synthesize optimal q for intermediate regimes, resource constraints, or multi-criteria objectives (e.g., hardness + diversity + correctness).
- Multi-dimensional “difficulty”: Difficulty is modeled via a 1D projection x⊤wo. Realistic difficulty is multi-faceted. How to handle multi-directional or learned difficulty scores (e.g., learned scoring networks, ensemble disagreement) is left open.
- Adaptive curation loops: The theory is largely one-shot. There is no formal analysis of iterative re-scoring/retraining loops (self-distillation, RLHF) where both learner and pruner co-evolve (feedback stability, convergence, or limit cycles).
- Model collapse theory beyond toy settings: While experiments suggest curation mitigates collapse, a rigorous dynamical analysis over multiple pseudo-labeling rounds (with explicit noise accumulation, distribution drift, and compounding selection bias) is missing.
- Selection-induced covariate shift: Pruning changes the training distribution. Formal characterization of the induced covariate shift and its impact on out-of-distribution generalization and fairness is not provided.
- Fairness and representation bias: Aggressive pruning may systematically under-represent subgroups or rare modes. There is no theoretical or empirical assessment of disparate impact, and no constraints ensuring equitable curation.
- Privacy and security: The effect of curation on privacy risks (e.g., membership inference) and robustness to data poisoning or malicious oracle guidance is unexamined.
- Compute–data trade-offs: The framework does not quantify how pruning interacts with compute budgets, optimization speed, gradient noise, and wall-clock efficiency in modern training pipelines.
- Hyperparameter sensitivity: Dependence on regularization λ, pruning fraction p, and dataset size n in finite samples (beyond asymptotics) is not quantified; guidelines for selecting λ and p under compute, accuracy, and stability constraints are missing.
- Finite-sample deviations: Rates of convergence to the asymptotic predictions and finite-sample confidence bands for test error under curation are not established.
- Generalization of phase boundaries: The “precise phase boundaries” are claimed but not distilled into user-facing, closed-form conditions in the main text; actionable criteria for practitioners to decide when “less is more” using observable quantities are not provided.
- Interplay with deduplication and diversity: q is said to capture “diverse or interesting” examples, but diversity is not formalized; the effect of diversity-aware curation on scaling and collapse is not analyzed.
- Active learning connections: The relationship between the proposed curation and active learning (querying, uncertainty sampling, disagreement-based selection) is not explored theoretically or empirically.
- Transfer and multi-task settings: It is unclear how curation tuned for one task/domain transfers to others, and whether task-conditional curation strategies are required.
- Robustness to distribution drift: The framework assumes stationary test distribution P*. How curation policies adapt under evolving test distributions or continual-learning scenarios is not studied.
- LLM reasoning specificity: The mapping from the linear-Gaussian theory to chain-of-thought LLM settings (program synthesis, verifiers, partial credit, multi-step failures) is heuristic; a principled abstraction capturing verifier noise, partial correctness, and multi-step difficulty is needed.
- Benchmark breadth: Empirical validation is limited (synthetic and ImageNet). Broader tests across text, code, speech, and reasoning tasks with standardized protocols are needed to substantiate generality.
- Reweighting vs resampling strategies: Comparisons between pruning, importance sampling, and curriculum (or anti-curriculum) schedules are missing; it is unknown which approach optimally bends scaling laws under various constraints.
- Open-source reproducibility: Details on code, hyperparameters, and experimental controls (to rule out confounders in ImageNet experiments) are not provided, limiting independent verification.
Glossary
- Covariate shift: A mismatch between the input feature distributions of training and test data. Example: "corresponding to covariate shift."
- Data curation: The deliberate selection and filtering of training examples based on quality or difficulty to improve learning. Example: "data curation strategies."
- Deterministic equivalents: Analytical approximations in random matrix theory that replace random matrices with deterministic limits for tractable analysis. Example: "deterministic equivalents for the resolvent matrix "
- High-dimensional proportionate scaling limit: An asymptotic regime where both sample size and dimensionality grow with a fixed ratio. Example: "in the high-dimensional proportionate scaling limit:"
- Isotropic setting: A modeling assumption where covariance matrices are identity, making all directions statistically equivalent. Example: "the isotropic setting where the covariance matrices are identity matrices"
- Keep easy: A curation strategy that retains easy, large-margin examples far from the decision boundary. Example: "the "keep easy" (KE) strategy uniquely minimizes the test error F(q) over Q_p."
- Keep hard: A curation strategy that retains hard, small-margin examples near the decision boundary. Example: "the "keep hard" (KH) strategy uniquely minimizes the test error F(q) over Q_p."
- Label-agnostic curation: Pruning decisions that depend only on features, not labels. Example: "Label-Agnostic Curation."
- Label-aware curation: Pruning that keeps examples only if an oracle judges the label correct (and possibly meets a difficulty rule). Example: "Label-aware Curation."
- Label shift: A mismatch between the labeling function used for training and the true labeling function at test time. Example: "our focus here is on label shift"
- Mahalanobis norm: A norm defined by a covariance matrix that scales directions by their variance structure. Example: "is the Mahalanobis norm induced by the covariance matrix ."
- Marchenko–Pastur law: The limiting eigenvalue distribution of sample covariance matrices in high dimensions. Example: "the Stieltjes transform of a Marchenko-Pastur law, "deformed" by pruning."
- Margin: The (signed) distance of an example to the decision boundary; large margins indicate easier examples. Example: "retain large-margin examples (far from the decision boundary)"
- Model collapse: Catastrophic degradation that occurs when models are repeatedly trained on noisy or self-generated data. Example: "can even mitigate model collapse."
- Oracle labels: Labels produced by an external oracle used for filtering or verification. Example: "nor the oracle labels ."
- Oracle pruning vector: The direction used by the oracle to score and filter examples. Example: "an oracle pruning vector "
- Parametrization rate: The limiting ratio of dimensionality to sample size in high-dimensional analysis. Example: "also known as the parametrization rate"
- Phase boundaries: Critical boundaries separating qualitatively different learning regimes (e.g., stability vs. divergence). Example: "establishing phase boundaries where uncurated training diverges while curated training remains stable."
- Phase transitions: Abrupt changes in generalization behavior as data quality/size or oracle reliability crosses thresholds. Example: "revealing sharp phase transitions tied to dataset size, label quality, and oracle reliability."
- Pruning function: A function that maps a scalar score (e.g., margin) to a binary keep/discard decision. Example: "via a pruning function "
- Pruning oracle: An external mechanism that scores examples for selection based on difficulty/correctness. Example: "under pruning oracles that filter examples based on difficulty and correctness."
- Pruning ratio: The expected fraction of data retained after curation. Example: "The fraction of data retained for learning is the pruning ratio, ."
- Pseudo-labeled dataset: A dataset labeled by a model rather than ground-truth annotators. Example: "to create and select from a pseudo-labeled dataset."
- Random matrix theory (RMT): A mathematical framework for analyzing properties of large random matrices used in learning theory. Example: "random matrix theory (RMT) techniques"
- Resolvent matrix: The inverse of a shifted matrix used to study spectra and learning dynamics (e.g., ). Example: "the resolvent matrix defined in \eqref{eq:estimator}"
- Scaling laws: Regularities relating performance to resources like data, model size, and compute. Example: "classical scaling laws"
- Self-training: Iteratively training a model on data labeled by the model itself. Example: "iterative self-training on noisy or synthetic data"
- Stieltjes transform: An integral transform that characterizes spectral distributions of random matrices. Example: "the Stieltjes transform of a Marchenko-Pastur law"
- Symmetric pruning functions: Pruning rules invariant to sign, i.e., depending on |t| rather than t. Example: "Symmetric Pruning Functions"
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting current data pipelines and verification tools. They leverage the paper’s core findings: when to prune (keep a subset) vs when to scale (keep all), how to choose “keep hard” (KH) vs “keep easy” (KE), and how curation mitigates model collapse.
- LLM fine-tuning with verifier-driven selection (software, education)
- What to do: Use label-aware curation to keep only verifiably correct and difficult examples (KH) when the base model is strong on a slice; use KE when the model is weak on that slice.
- Tools/workflows: Integrate existing verifiers (unit tests for code, solution checkers for math, rule-based validators for Q&A), add a “Curation Controller” that selects KH or KE per task/slice using proxy measures of generator quality (e.g., slice-level validation accuracy, margin/confidence).
- Assumptions/dependencies: Requires reliable verifiers that correlate with true correctness (high ρ*), and slice-level assessment to estimate generator quality (ρ).
- Preventing model collapse in pseudo-labeling loops (vision, NLP, speech)
- What to do: In iterative self-training, retain only correctly pseudo-labeled hard examples (KH + label-aware filter) to stabilize performance; avoid training on all pseudo-labeled data.
- Tools/workflows: “CollapseGuard” plug-in for self-training loops that enforces pruning ratio p, validates labels (agreement thresholds, confidence, ensemble checks), and prioritizes difficult examples by margin.
- Assumptions/dependencies: Needs confidence or agreement metrics as proxies for correctness; computational budget to score examples.
- Data/compute budgeting with principled pruning (cross-sector)
- What to do: Under compute/token constraints, prune aggressively when the model is already strong on a domain (KH) to hit accuracy targets with fewer tokens; avoid pruning when the model is weak (KE or no pruning).
- Tools/workflows: “DataBudget Optimizer” that chooses pruning ratio p and strategy (KH/KE) per dataset slice to meet target accuracy at minimal cost.
- Assumptions/dependencies: Requires per-slice calibration of generator quality; may need periodic re-evaluation as the model improves.
- Dataset auditing and monitoring of “phase boundaries” (MLOps, governance)
- What to do: Track proxies for generator quality (ρ) and oracle/pruner alignment (ρ*, ρg) to determine when the regime favors pruning vs scaling.
- Tools/workflows: “PhaseBoundary Dashboard” reporting per-slice validation accuracy, margin distributions, oracle agreement rates; alerts when to switch from KE→KH.
- Assumptions/dependencies: Estimation of ρ-like proxies needs labeled validation data or strong heuristics.
- Curriculum and active learning schedules (education-tech, software)
- What to do: Start with KE to bootstrap weak models or for new domains; switch to KH as performance crosses a threshold, mirroring the paper’s phase transitions.
- Tools/workflows: Adaptive scheduler that monitors per-skill accuracy and flips the curation policy when a slice becomes strong.
- Assumptions/dependencies: Requires slice definition and reliable progress signals; risk of over-pruning rare skills unless monitored.
- Synthetic data curation with natural verifiers (code, math, program synthesis)
- What to do: Accept only verified-correct generations; prioritize hard/rare/diverse correct samples in the training pool (KH + label-aware).
- Tools/workflows: Compiler/test-harness pipelines for code; solution checkers for math; symbolic verifiers where available.
- Assumptions/dependencies: Verifier coverage and reliability are essential; hardness scoring must not collapse diversity.
- Vision pipelines using pseudo-labels (healthcare imaging, retail, autonomy)
- What to do: Reproduce ImageNet-style gains by pruning pseudo-labeled images: KE when the teacher/generator is weak (small n), KH when strong (large n).
- Tools/workflows: Margin/confidence-based difficulty scoring; dynamic p selection; periodic recalibration of teacher quality.
- Assumptions/dependencies: Domain shift and class imbalance require careful monitoring; ensure tails are not discarded.
- Risk-sensitive domains: triage curation (healthcare, finance)
- Healthcare: Use double-read or adjudicated labels as oracles; train with KE early, KH later to sharpen decision boundaries on confounders.
- Finance (fraud): Begin with KE on confirmed fraud/legit cases; graduate to KH to reduce borderline false negatives.
- Tools/workflows: Verified-label ingestion pipelines; audit trails for label provenance; slice-specific curation policies.
- Assumptions/dependencies: Label verification quality and availability; regulatory constraints on data handling.
- Policy and procurement guidance on synthetic data use (policy, compliance)
- What to do: Mandate label-aware filtering and report pruning ratios p for any synthetic or self-generated data used in training; discourage “train-on-everything” in self-consuming loops.
- Tools/workflows: Curation policy templates; reporting checklists for dataset releases; audit logs for synthetic data selection criteria.
- Assumptions/dependencies: Organizational readiness for data governance; transparency requirements across partners/vendors.
- Personalized practice and tutoring apps (daily life, edtech)
- What to do: Apply the paper’s principle to human learning: if the learner is strong on a topic, present harder verified problems; if weak, emphasize easier, canonical items first.
- Tools/workflows: Per-skill mastery estimates; content verifiers; “PhaseSwitch” heuristic in adaptive curricula.
- Assumptions/dependencies: Accurate mastery estimation; content difficulty calibration.
Long-Term Applications
The following applications require further research, scaling, or development—often to relax the paper’s assumptions (e.g., linear models, Gaussian features) or to embed curation logic deeply into complex systems.
- Generalizing theory-guided curation to deep networks (software, robotics, multimodal)
- What: Extend scaling-law predictions and phase boundaries from linear/RMT regimes to transformers and RL settings; formally link KH/KE schedules to training dynamics in deep nets.
- Potential tools/products: “Curation SDK” for PyTorch/JAX with pruner-aware dataloaders; theoretical bounds informing scheduler defaults.
- Dependencies: New theory for non-linear models; extensive empirical validation across modalities.
- Automated estimation of ρ, ρ*, ρg and real-time control (MLOps)
- What: Learn proxies for generator/pruner quality and alignment directly from telemetry (loss curves, margins, ensemble agreement), enabling a meta-controller to adjust p and KH/KE online.
- Potential tools/products: “OracleScore” library; “PhaseSwitch Scheduler” that auto-tunes curation.
- Dependencies: Robustness under distribution shift; calibration in streaming/online learning.
- Standardized verifiers and metadata for curated datasets (industry standards, policy)
- What: Dataset formats that carry oracle confidence, difficulty scores, pruning rationale, and phase logs; certification that curation met minimal verifier quality.
- Potential tools/products: “CurationBench” benchmark; dataset cards with curation metrics; synthetic data labeling standards.
- Dependencies: Community consensus; sector-specific verifiers (e.g., clinical, legal).
- Fairness- and diversity-aware curation (policy, responsible AI)
- What: Algorithms that preserve subgroup coverage while applying KH/KE, preventing disproportionate pruning of minority or rare cases; per-group phase boundaries.
- Potential tools/products: Fairness-constrained pruner; diversity-preserving sampler; “Curation Parity” dashboards.
- Dependencies: Access to sensitive attributes or reliable proxies; formal fairness objectives integrated with curation.
- Collapse risk forecasting and intervention playbooks (safety, governance)
- What: Early-warning indicators of collapse in self-consuming loops; automated interventions (increase p, switch to KE, refresh with human-labeled seed data).
- Potential tools/products: “CollapseRisk Index” and response runbooks integrated with training orchestrators.
- Dependencies: Validated risk models; organizational processes to act on alerts.
- Data marketplaces for “verified-hard” packs (economy of data)
- What: Commercial distribution of small, aggressively curated, high-value datasets with verifiers and difficulty metadata, tuned for specific domains or slices.
- Potential tools/products: Sector-specific “hard packs” (e.g., rare defects, hard math skills, edge fraud).
- Dependencies: Trusted verification pipelines; licensing and privacy compliance.
- Energy- and cost-aware training policies (sustainability)
- What: Institutional policies that prefer curated training regimes when the model is in the “less-is-more” phase, quantifying CO2 and cost savings per point of accuracy.
- Potential tools/products: Sustainability dashboards linked to curation settings; procurement guidelines that reward verifiable curation.
- Dependencies: Reliable accounting of energy impacts; acceptance by stakeholders.
- Robotics and embodied learning with curated episodes (robotics, autonomy)
- What: Use physics-based or task verifiers to keep correct trajectories; apply KE in early skill acquisition and KH for fine-grained control refinement.
- Potential tools/products: Episode scorers using constraint residuals; pruner-aware replay buffers.
- Dependencies: High-fidelity simulators or on-policy verifiers; safe exploration guarantees.
- Privacy-preserving oracles and curation (healthcare, finance)
- What: Private verifiers (secure enclaves, federated/DP methods) that enable label-aware selection without exposing sensitive data.
- Potential tools/products: Privacy-first “Oracle API” that returns correctness/difficulty signals; compliant curation logs.
- Dependencies: Mature privacy tech; regulatory acceptance.
- Cross-modal and multimodal curation (vision-language, speech, code+text)
- What: Unified difficulty/correctness signals across modalities and alignment-aware curation for cross-modal tasks (e.g., VQA).
- Potential tools/products: Multimodal verifier toolkits; cross-modal KH/KE schedulers.
- Dependencies: Reliable multimodal verifiers; alignment metrics across modalities.
Key Assumptions and Dependencies Across Applications
- Theory-to-practice gap: Core results are derived for linear models with Gaussian features and high-dimensional asymptotics; qualitative transfer to deep models is strongly suggested but not guaranteed—requires empirical validation.
- Oracle availability and quality: Label-aware benefits depend on strong verifiers (high ρ*). Poor oracles can negate gains; investment in verification is critical.
- Estimating generator quality (ρ): Requires reliable validation signals per slice and ongoing recalibration as models and data evolve.
- Diversity and fairness: Aggressive pruning risks discarding tail or minority examples; must pair curation with diversity/fairness constraints and monitoring.
- Domain shift: Changes between training generator and true test distribution (label/covariate shift) affect phase boundaries; governance must track and adjust.
- Operational costs: Scoring, validating, and auditing introduce overhead; however, savings from reduced training data and improved stability often offset costs.
Collections
Sign up for free to add this paper to one or more collections.