- The paper presents a hypernetwork method that eliminates fine-tuning by predicting LoRA-adapted weights for personalized text-to-image generation.
- The approach uses output regularization and Hybrid-Model Classifier-Free Guidance (HM-CFG) to balance subject fidelity and prompt adherence.
- Experimental results demonstrate improved scalability and performance on benchmarks like CelebA-HQ, AFHQ-v2, and DreamBench.
Finetuning-Free Personalization of Text to Image Generation via Hypernetworks
Introduction
This paper introduces a novel approach to personalizing text-to-image (T2I) diffusion models without the need for fine-tuning, using hypernetworks. Traditional methods, such as DreamBooth, require significant computational resources and time for fine-tuning, which limits their scalability and applicability in real-time scenarios. This research addresses these limitations by leveraging hypernetworks to predict LoRA-adapted weights directly from subject images, proposing an end-to-end training objective stabilized by output regularization, and introducing a Hybrid-Model Classifier-Free Guidance (HM-CFG) for enhanced compositional generalization at inference time. The proposed method promises scalability and effectiveness in open-category personalization.
Methodology
The proposed methodology involves using a hypernetwork that predicts the parameters required to adapt a frozen, pre-trained diffusion model to generate personalized images. The training pipeline is designed to negate the need for time-intensive fine-tuning on new subjects by directly predicting these parameters from input images.
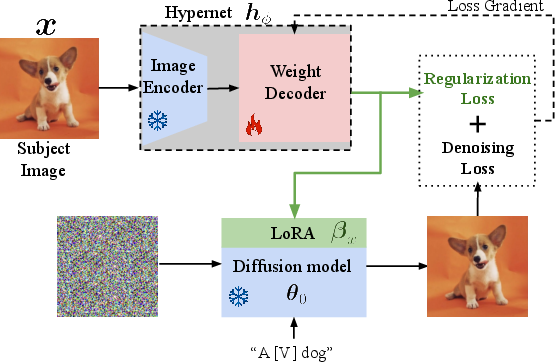
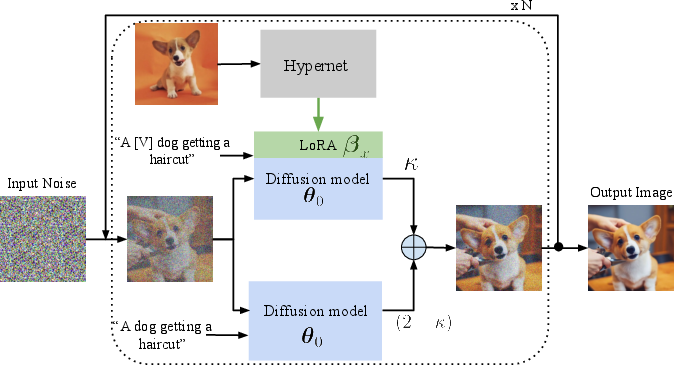
Figure 1: Overview of our approach. a) Training pipeline for hypernetwork-based personalization. b) Inference approach using hybrid model classifier-free guidance.
Key components of the method include:
- Hypernetwork Architecture: A frozen image encoder processes input images, and a trainable weight decoder outputs the LoRA parameters. These parameters adapt a diffusion model to incorporate the subject-specific details.
- Output Regularization: A simple regularization term on the output stabilizes the training and prevents overfitting, effectively replicating early stopping, which is critical in fine-tuning scenarios.
- Hybrid-Model Classifier-Free Guidance (HM-CFG): This inference strategy combines the subject fidelity of personalized models with the compositional strengths of base diffusion models. It allows controlling the trade-off between subject fidelity and prompt adherence through a parameter κ.
The approach negates the need for per-subject optimization at test time, significantly reducing computational overhead while maintaining both subject fidelity and prompt alignment.
Experimental Evaluation
The method was evaluated on several datasets, including CelebA-HQ, AFHQ-v2, and DreamBench. The experiments demonstrated the capabilities of the proposed hypernetwork framework in both closed-category and open-category personalization tasks.
Closed-Category Personalization
Results indicate that the proposed hypernetwork achieves superior subject and prompt fidelity compared to existing methods like DreamBooth, without requiring any test-time fine-tuning.

Figure 2: Qualitative results on CelebA-HQ dataset. Proposed method shows competitive subject and prompt fidelity compared to fine-tuning-based DreamBooth.
Open-Category Personalization
On the open-category benchmark, DreamBench, the method outperformed many state-of-the-art methods without additional fine-tuning, highlighting its robustness and versatility across diverse subjects.

Figure 3: Qualitative results on DreamBench dataset. Improvement in subject fidelity and prompt adherence over baselines is observed.
Hybrid-Model Classifier-Free Guidance
The introduction of HM-CFG significantly enhances prompt adherence while preserving subject fidelity across various datasets.

Figure 4: Qualitative results of applying HM-CFG on CelebA-HQ. Improvement in prompt alignment is evident.
Conclusion
The research offers a pioneering approach to text-to-image personalization that circumvents the computational barriers posed by traditional fine-tuning methods. By utilizing hypernetworks with output regularization and an innovative inference strategy, the method achieves state-of-the-art performance. Future work may explore further tuning of κ to optimize the balance between subject fidelity and prompt adherence, as well as applying these techniques to other generative tasks beyond text-to-image synthesis.