In Good GRACEs: Principled Teacher Selection for Knowledge Distillation
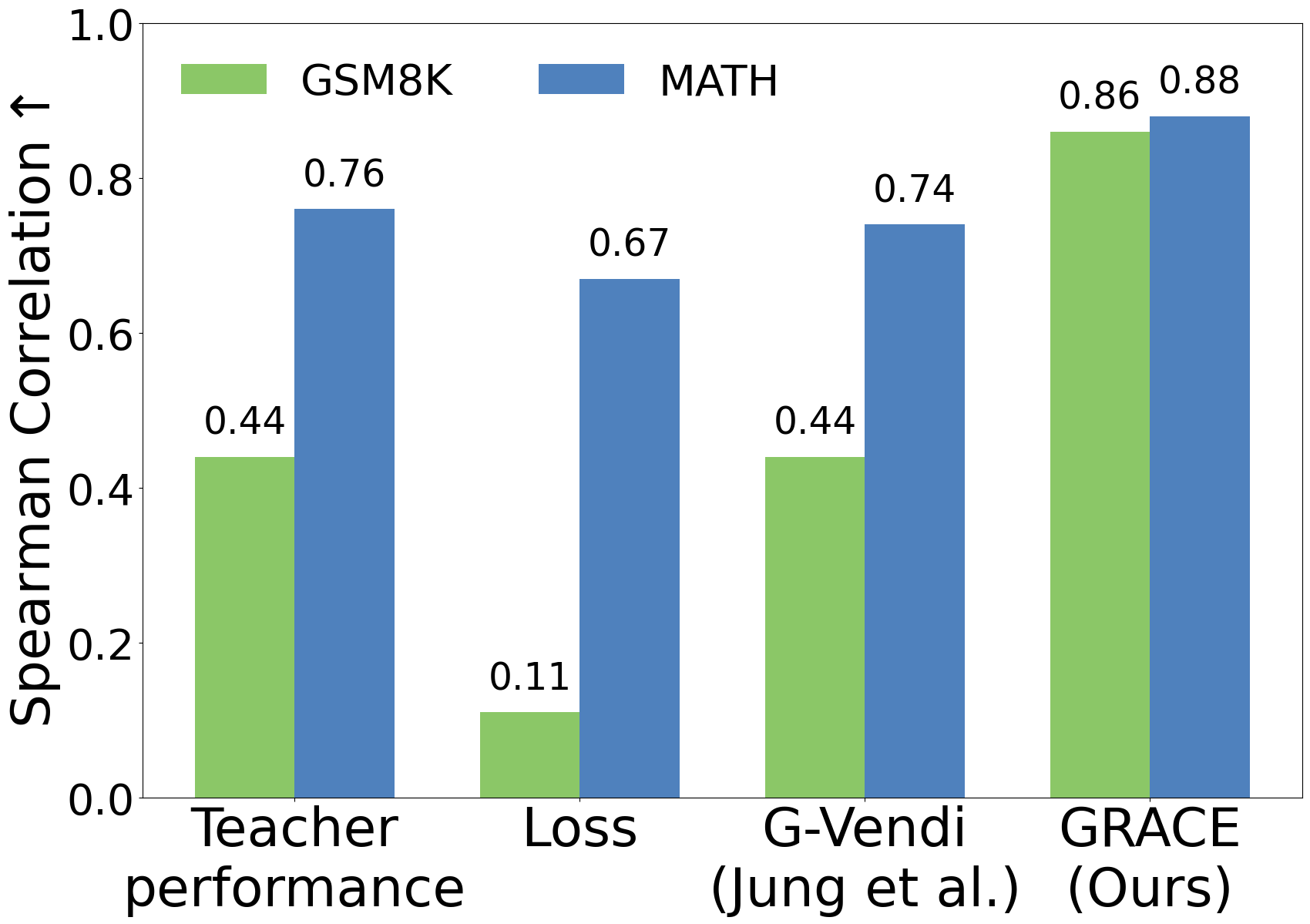
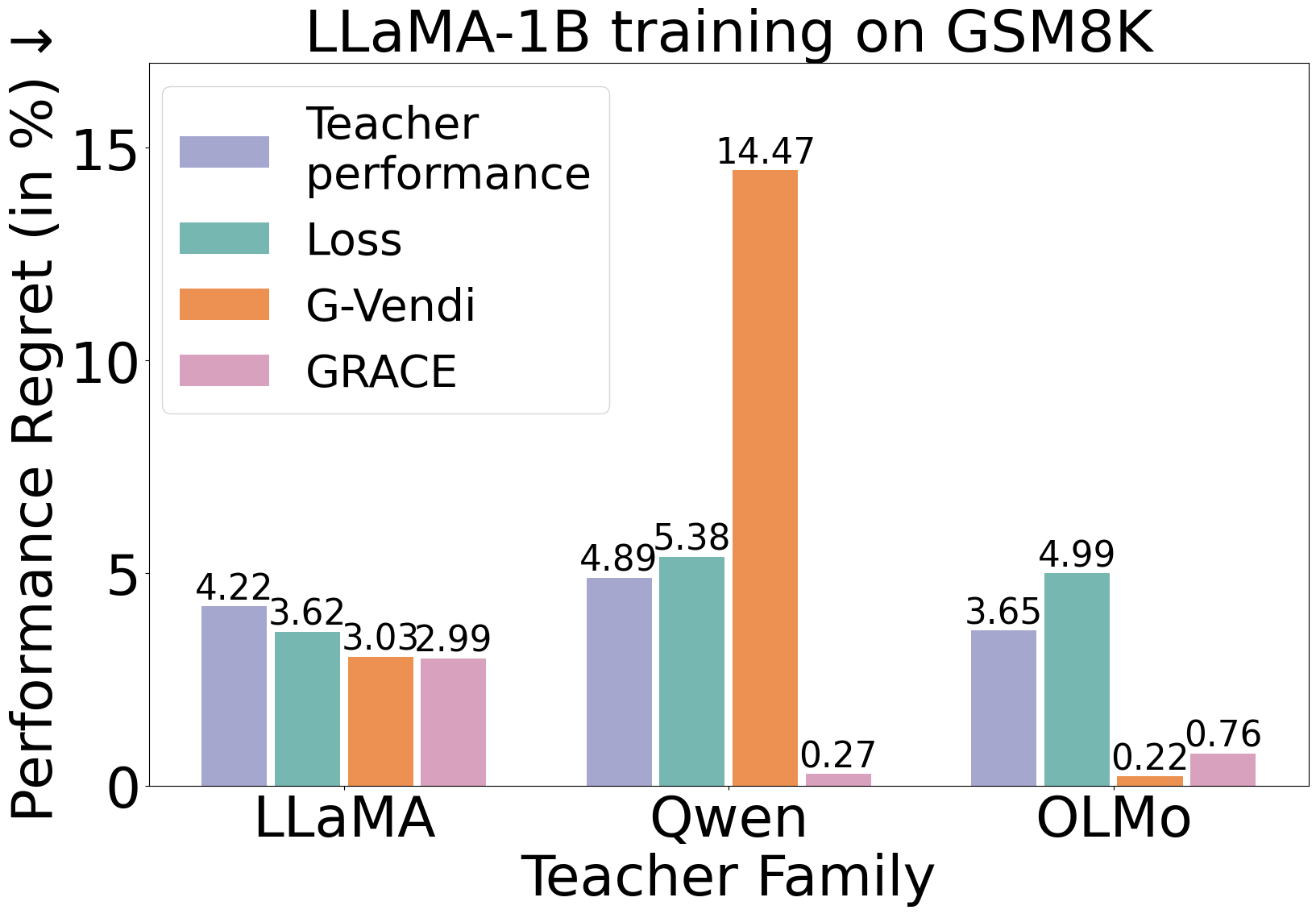
Abstract: Knowledge distillation is an efficient strategy to use data generated by large "teacher" LLMs to train smaller capable "student" models, but selecting the optimal teacher for a specific student-task combination requires expensive trial-and-error. We propose a lightweight score called GRACE to quantify how effective a teacher will be for post-training a student model. GRACE measures distributional properties of the student's gradients without access to a verifier, teacher logits, teacher internals, or test data. From an information-theoretic perspective, GRACE connects to leave-one-out stability of gradient-based algorithms, which controls the generalization performance of the distilled students. On GSM8K and MATH, GRACE correlates strongly (up to 86% Spearman correlation) with the performance of the distilled LLaMA and OLMo students. In particular, training a student using the GRACE-selected teacher can improve the performance by up to 7.4% over naively using the best-performing teacher. Further, GRACE can provide guidance on crucial design choices in distillation, including (1) the best temperature to use when generating from the teacher, (2) the best teacher to use given a size constraint, and (3) the best teacher to use within a specific model family. Altogether, our findings demonstrate that GRACE can efficiently and effectively identify a strongly compatible teacher for a given student and provide fine-grained guidance on how to perform distillation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.