- The paper presents 3EED, a novel benchmark that scales outdoor 3D visual grounding with multi-platform, multi-modal data and extensive language annotations.
- It introduces platform-aware normalization and multi-scale fusion techniques that substantially improve in-domain and cross-platform performance.
- The study establishes rigorous protocols for multi-object reasoning and spatial disambiguation, highlighting challenges in diverse outdoor scenes.
Introduction
The 3EED dataset and benchmark address the limitations of prior 3D visual grounding resources, which have been constrained to indoor environments, single-platform data, and limited scale. 3EED introduces a large-scale, multi-platform, multi-modal corpus for 3D grounding in outdoor scenes, integrating synchronized LiDAR and RGB data from vehicle, drone, and quadruped platforms. The benchmark comprises over 128,000 annotated objects and 22,000 human-verified referring expressions, representing a tenfold increase in scale over previous outdoor datasets. The work establishes new protocols for in-domain, cross-platform, and multi-object grounding, and proposes platform-aware normalization and cross-modal alignment techniques to facilitate generalizable 3D grounding.
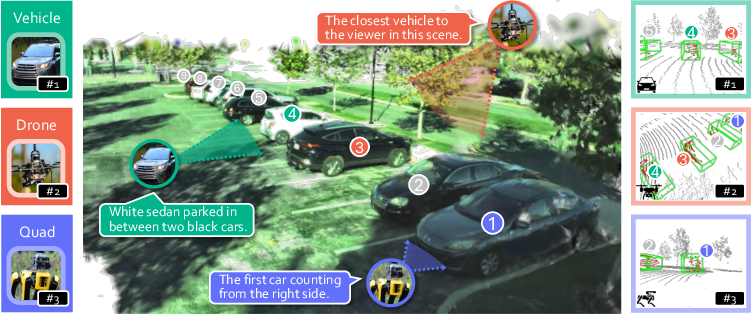
Figure 1: Multi-modal, multi-platform 3D grounding: given a scene and a structured natural language expression, the task is to localize the referred object in 3D space across vehicle, drone, and quadruped platforms.
Dataset Construction and Annotation Pipeline
3EED unifies data from three embodied platforms: vehicles (Waymo Open Dataset), drones, and quadrupeds (M3ED). The annotation pipeline is designed for scalability and quality, combining vision-LLM prompting (Qwen2-VL-72B) with human-in-the-loop verification. The process involves:
- Pseudo-label seeding: Multiple state-of-the-art 3D detectors (PV-RCNN, CenterPoint, etc.) generate initial bounding boxes.
- Automatic consolidation: Kernel density estimation merges detector outputs, multi-object tracking enforces temporal coherence, and the Tokenize Anything model projects boxes onto RGB for semantic validation.
- Human refinement: Annotators verify and correct boxes and referring expressions using a custom UI, ensuring platform-invariant, unambiguous language.
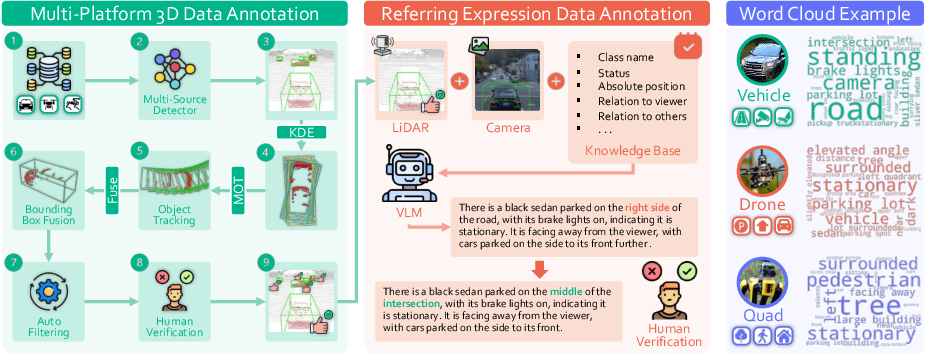
Figure 2: Annotation workflow: multi-detector fusion, tracking, filtering, and manual verification for 3D boxes; VLM prompting and human refinement for referring expressions.
The dataset covers diverse outdoor scenes, with platform-specific differences in viewpoint geometry, object density, and LiDAR point cloud elevation. Vehicle data is characterized by mid-range, level views; drone data by top-down, sparse, high-density scenes; quadruped data by ground-level, close-range perspectives.
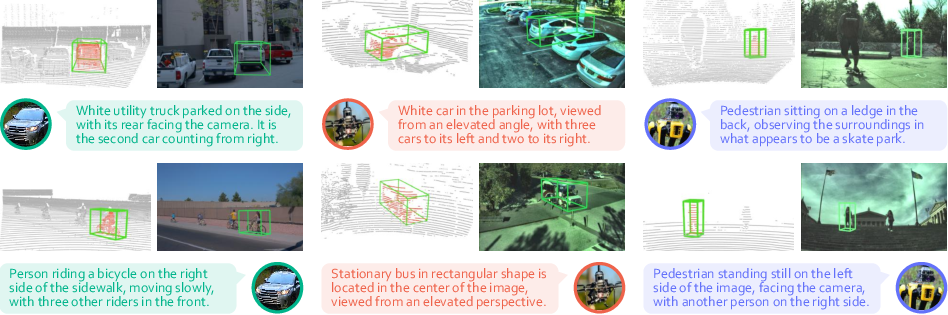
Figure 3: Examples of multi-platform 3D grounding: discrepancies in sensory data and referring expressions across vehicle, drone, and quadruped agents.
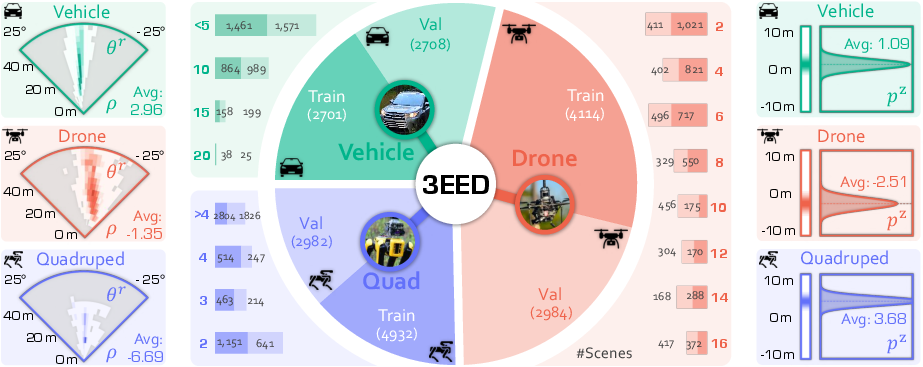
Figure 4: Dataset statistics: polar distribution of target boxes, scene and object count histograms, and elevation biases per platform.
Benchmark Protocols and Model Design
The benchmark suite includes four diagnostic settings:
- Single-platform, single-object grounding: In-domain evaluation per platform.
- Cross-platform transfer: Zero-shot evaluation from vehicle-trained models to drone/quadruped data.
- Multi-object grounding: Localization of all objects described in a multi-object expression.
- Multi-platform grounding: Joint training on all platforms, with per-platform evaluation.
The baseline model adapts PointNet++ for scale-adaptive encoding, incorporates platform-aware normalization (CPA), multi-scale sampling (MSS), and scale-aware fusion (SAF). CPA aligns all scans to a gravity-consistent frame, MSS samples neighborhoods at multiple radii to address LiDAR sparsity and object scale variation, and SAF dynamically fuses multi-scale features per point.
Experimental Results
Single-Object Grounding
The baseline model demonstrates substantial improvements over prior methods (BUTD-DETR, EDA, WildRefer) in both in-domain and cross-platform settings. For example, when trained on vehicle data, the baseline achieves Acc@25 of 78.37% (vs. 52.38% for BUTD-DETR) and narrows the cross-platform gap (drone: 18.16% vs. 1.54%; quadruped: 36.04% vs. 10.18%). Unified multi-platform training yields balanced performance across all platforms.
Multi-Object Grounding
In multi-object scenarios, the baseline outperforms existing methods in both Acc@25 and mIoU, indicating superior joint reasoning and spatial disambiguation. The model's multi-scale and adaptive fusion modules are critical for handling complex scenes with multiple referents and varying object sizes.
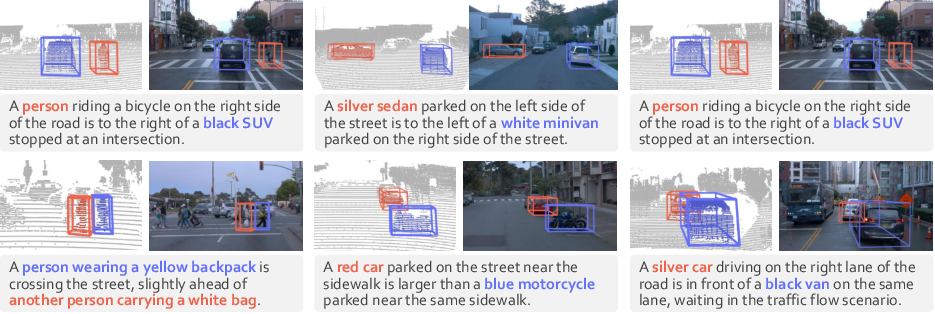
Figure 5: Multi-object 3D grounding: localizing each referred object by reasoning over semantic attributes and inter-object spatial relationships.
Ablation Studies
Component ablations confirm the complementarity of CPA, MSS, and SAF. Removing any module degrades both in-domain and cross-platform performance. Object density analysis reveals that grounding accuracy decreases as the number of objects per scene increases, especially for drone data due to extreme sparsity and clutter.
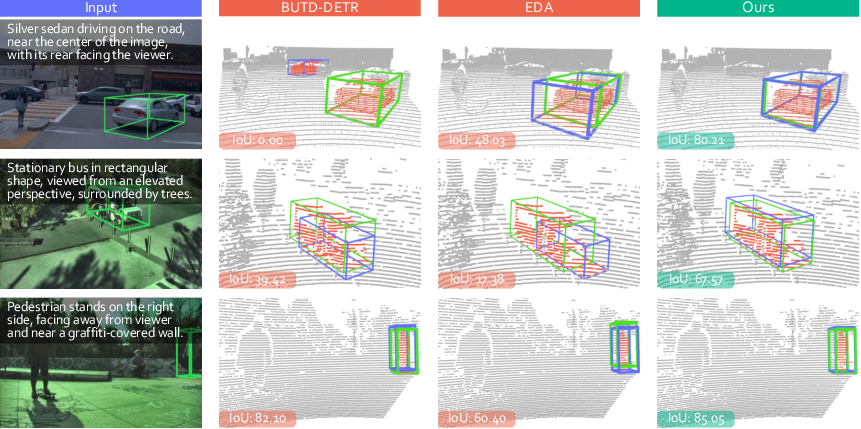
Figure 6: Qualitative comparisons: baseline model yields precise, tightly aligned 3D boxes across platforms; prior methods struggle with viewpoint and density shifts.
Implementation Considerations
- Computational Requirements: Training requires two RTX 4090 GPUs for 100 epochs; inference is efficient due to lightweight fusion modules.
- Data Preprocessing: Uniform downsampling to 16,384 points per scene; gravity-aligned normalization for cross-platform consistency.
- Annotation Quality: Human verification ensures high-fidelity language and spatial alignment; platform-invariant prompts standardize linguistic supervision.
- Deployment: The model is robust to platform shifts and can be integrated into embodied agents for navigation, interaction, and situational awareness in outdoor environments.
Implications and Future Directions
3EED exposes significant performance gaps in cross-platform 3D grounding, underscoring the need for platform-aware, scale-adaptive models. The dataset's diversity and scale enable rigorous evaluation of generalization, multi-object reasoning, and language-vision alignment in real-world conditions. Future research should address temporal dynamics, ambiguous language, and extension to additional sensor modalities. The benchmark provides a foundation for developing robust, context-aware embodied perception systems.
Conclusion
3EED establishes a new standard for outdoor 3D visual grounding, offering a large-scale, multi-platform, multi-modal dataset and comprehensive benchmark protocols. The proposed annotation pipeline and baseline model advance the state of the art in generalizable 3D grounding, revealing key challenges and opportunities for future research in language-driven embodied AI.