- The paper introduces a dual-strategy defense mechanism that leverages clustering and concentration-based grouping to isolate adversarial passages in RAG systems.
- It demonstrates significant performance improvements by reducing attack success rates from 0.89 to 0.02 on the Gemini model without incurring extra computational costs.
- The approach offers practical and efficient integration into existing RAG architectures, enhancing defense against a range of knowledge corruption attacks.
Rescuing the Unpoisoned: Efficient Defense against Knowledge Corruption Attacks on RAG Systems
Introduction
The integration of LLMs into various domains has necessitated addressing their limitations, such as hallucination, staleness, and high training costs. Retrieval-Augmented Generation (RAG) systems have emerged as a solution, enabling the combination of pretrained knowledge with external databases to enhance information accuracy and freshness. Despite their promise, RAG systems remain vulnerable to knowledge corruption attacks, where adversarial inputs exploit the system's reliance on external knowledge retrieval. This paper introduces a novel defense mechanism aimed at efficiently mitigating these attacks without incurring substantial computational costs.
Methodology
The proposed defense mechanism operates during the post-retrieval phase, employing lightweight machine learning techniques to detect and filter adversarial content. The system is designed to enhance robustness by engaging two main strategies:
- Clustering-Based Grouping: Employs hierarchical agglomerative clustering to segregate retrieved passages based on semantic similarity. This method is particularly effective in isolating adversarial clusters within single-hop question-answering tasks.
- Concentration-Based Grouping: Utilizes mean and median concentration factors of passage embeddings to identify adversarial content within multi-hop question-answering scenarios. This approach effectively captures adversarial passages that embed concentrated misinformation.
These strategies are applied sequentially to estimate and isolate the number of adversarial passages from retrieved sets, ensuring only safe passages are provided to the RAG generator.
Results
The empirical evaluation demonstrates the effectiveness of the proposed system across diverse models and datasets. The defense mechanism achieved significant reductions in attack success rates while improving accuracy in response generation. Notably, the system reduced the attack success rate from 0.89 to 0.02 for the Gemini model, compared to RobustRAG's 0.69 and Discern-and-Answer's 0.24 under 4x adversarial conditions.
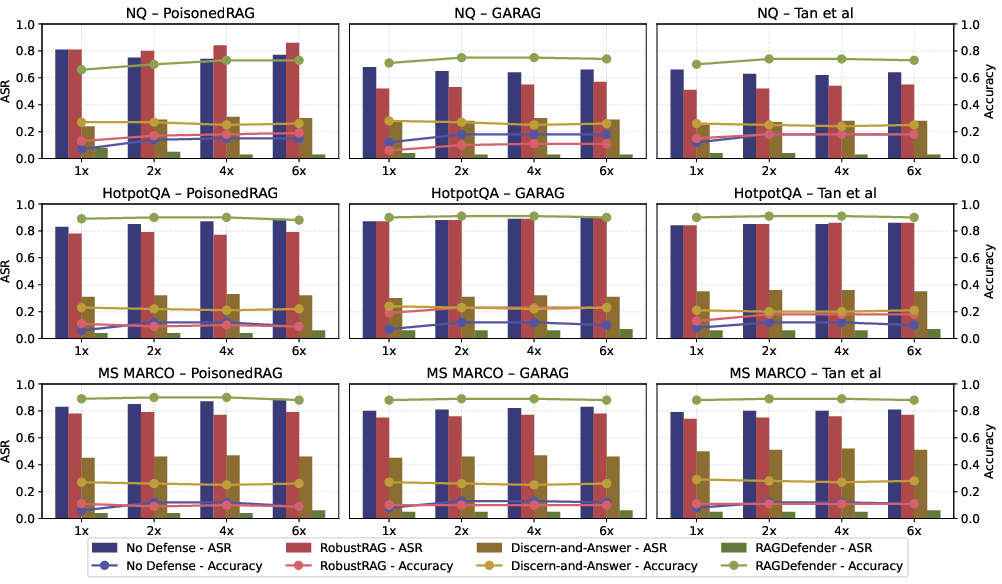
Figure 1: Attack success rates (ASRs) and accuracy using a baseline (no defense) show effectiveness improvements.
Furthermore, computational efficiency assessments reveal notable reductions in costs and processing delays. The system operates efficiently without additional model training or inference overhead, making it suitable for practical deployment in real-world environments.
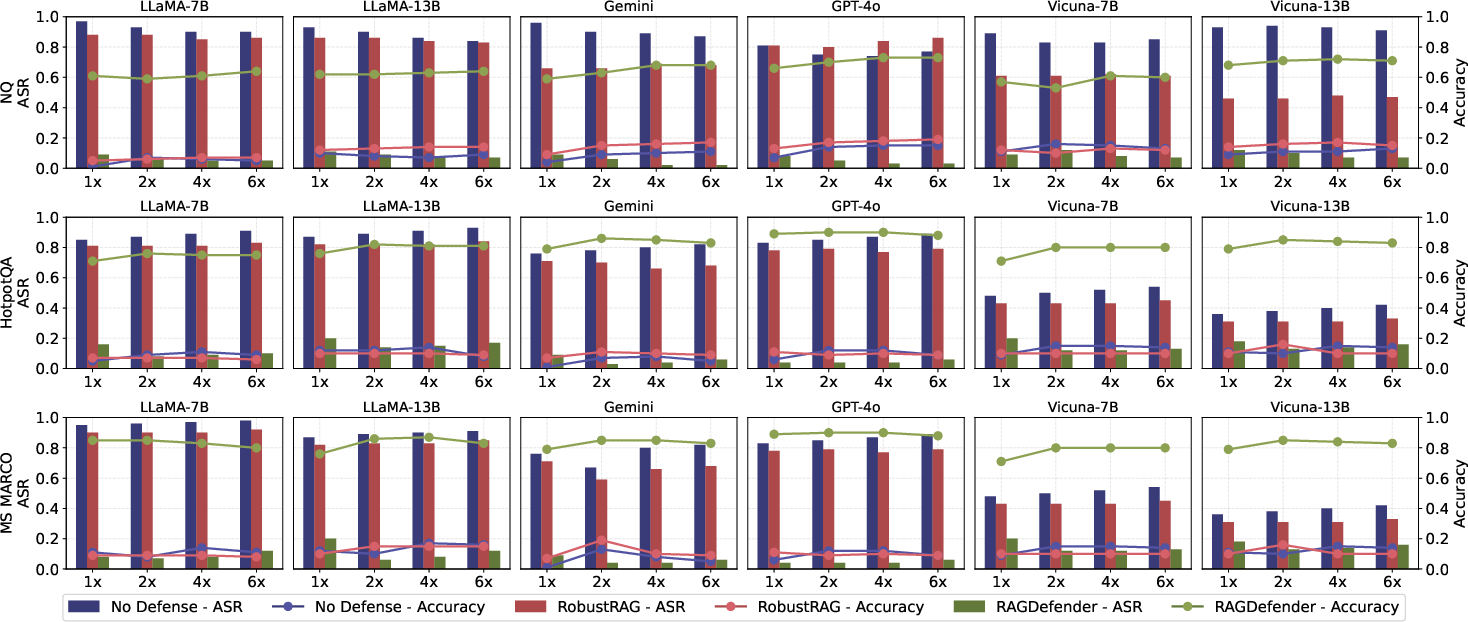
Figure 2: Comparative performance metrics highlight the resource and speed advantages of the proposed defense mechanism.
Discussion
The clustering-based approach leverages the inherent semantic similarities in adversarial content to distinguish it from legitimate inputs. The concentration-based method further refines this by identifying isolated adversarial clusters within embedding space, ensuring comprehensive detection across different attack scenarios.
The simplicity and computational efficiency of the proposed method make it adaptable to various RAG architectures, facilitating seamless integration into existing systems. Its applicability spans multiple adversarial tactics, supporting robust defenses in dynamic and interactive environments.
Conclusion
The presented defense framework effectively mitigates the risks posed by knowledge corruption attacks in RAG systems, enhancing both reliability and performance. It offers a practical approach, securing LLM-based applications against adversarial threats while maintaining efficient operation. Future research should explore extending these techniques to other modalities and expanding the defensive capabilities to address emerging attack vectors.
The implications of this research underscore the importance of developing adaptive and efficient defense mechanisms capable of safeguarding AI systems in increasingly complex environments.

