Deep reinforcement learning for optimal trading with partial information
Abstract: Reinforcement Learning (RL) applied to financial problems has been the subject of a lively area of research. The use of RL for optimal trading strategies that exploit latent information in the market is, to the best of our knowledge, not widely tackled. In this paper we study an optimal trading problem, where a trading signal follows an Ornstein-Uhlenbeck process with regime-switching dynamics. We employ a blend of RL and Recurrent Neural Networks (RNN) in order to make the most at extracting underlying information from the trading signal with latent parameters. The latent parameters driving mean reversion, speed, and volatility are filtered from observations of the signal, and trading strategies are derived via RL. To address this problem, we propose three Deep Deterministic Policy Gradient (DDPG)-based algorithms that integrate Gated Recurrent Unit (GRU) networks to capture temporal dependencies in the signal. The first, a one -step approach (hid-DDPG), directly encodes hidden states from the GRU into the RL trader. The second and third are two-step methods: one (prob-DDPG) makes use of posterior regime probability estimates, while the other (reg-DDPG) relies on forecasts of the next signal value. Through extensive simulations with increasingly complex Markovian regime dynamics for the trading signal's parameters, as well as an empirical application to equity pair trading, we find that prob-DDPG achieves superior cumulative rewards and exhibits more interpretable strategies. By contrast, reg-DDPG provides limited benefits, while hid-DDPG offers intermediate performance with less interpretable strategies. Our results show that the quality and structure of the information supplied to the agent are crucial: embedding probabilistic insights into latent regimes substantially improves both profitability and robustness of reinforcement learning-based trading strategies.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper explores how to teach a computer to trade in the stock market using deep reinforcement learning (a kind of AI that learns by trying, getting rewards, and improving). The key idea is to help the AI make good decisions even when some important market information is hidden. The authors design and test different ways to give the AI “clues” about these hidden parts so it can trade better.
Key Objectives
The researchers aim to answer simple questions:
- Can an AI learn profitable trading strategies when the market behaves in different “moods” (regimes) that we can’t see directly?
- What kind of information should we give the AI: raw patterns, probabilities of hidden regimes, or predictions of the next price?
- Which approach leads to higher profits, clearer decisions, and stronger performance both in simulations and real market data?
Methods and Approach
Think of the trading signal (the number the AI uses to decide when to buy or sell) like a rubber band around a “normal” level: it stretches away but tends to snap back. This behavior is called “mean reversion.” The paper models the signal with an Ornstein–Uhlenbeck process, which is a fancy term for a mean-reverting signal with random wiggles. Sometimes the market’s “normal level,” its speed of snapping back, and its volatility change depending on the market’s hidden “mood” (regime). These regimes switch over time like seasons: you don’t always know which season you’re in, but patterns give you hints.
The trading setup:
- The AI chooses how much to hold (inventory) at each step.
- Its reward is the profit from the signal’s movement minus trading costs.
- It’s risk-neutral (it focuses on expected profit) and uses a discount factor (it cares more about money earned sooner than later).
The learning tools:
- Reinforcement Learning (RL): Like a video game player, the AI tries actions, sees rewards, and learns a strategy to maximize profits.
- Deep Deterministic Policy Gradient (DDPG): An RL method with two parts:
- Actor: proposes an action (how much to buy or sell).
- Critic: judges how good that action is.
- Gated Recurrent Unit (GRU): A neural network that remembers past information (like a short-term memory) to understand time patterns in the signal.
They test three approaches to feeding information into the RL agent. Here’s a brief summary, using an everyday analogy:
- hid-DDPG (one-step): The AI uses the GRU’s internal “memory state” directly. Think of it as giving the AI a gut feeling based on recent history.
- prob-DDPG (two-step): First, a GRU estimates the probabilities of the hidden market regimes (like saying, “It’s 70% likely we’re in a high mean-reversion mood”). Then the AI uses these probabilities to make trading decisions.
- reg-DDPG (two-step): First, a GRU predicts the next signal value. Then the AI uses that prediction to trade.
They evaluate these methods in two ways:
- Simulations: Artificial markets with different complexity (different regimes).
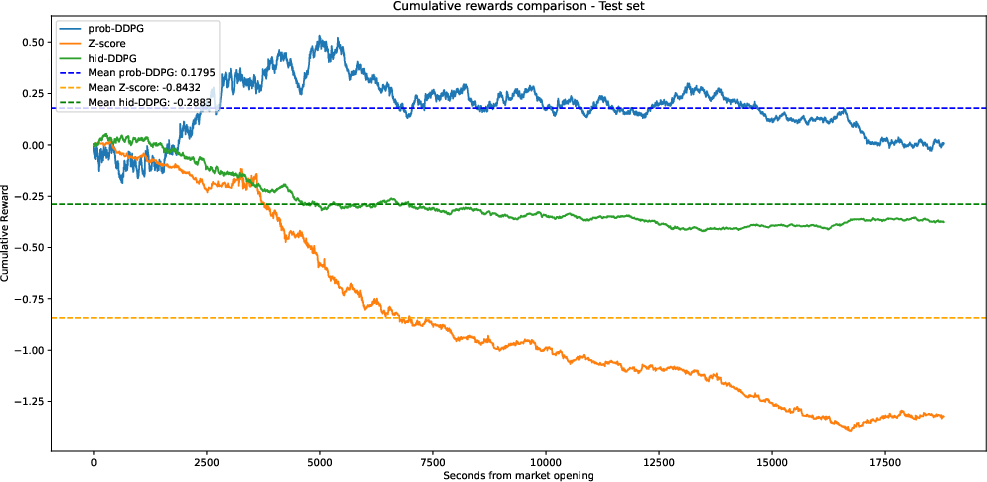
- Real data: Pair trading in equities (trading the relationship between two stocks that tend to move together, betting that their difference will “snap back” to normal).
Main Findings
The results are clear and consistent:
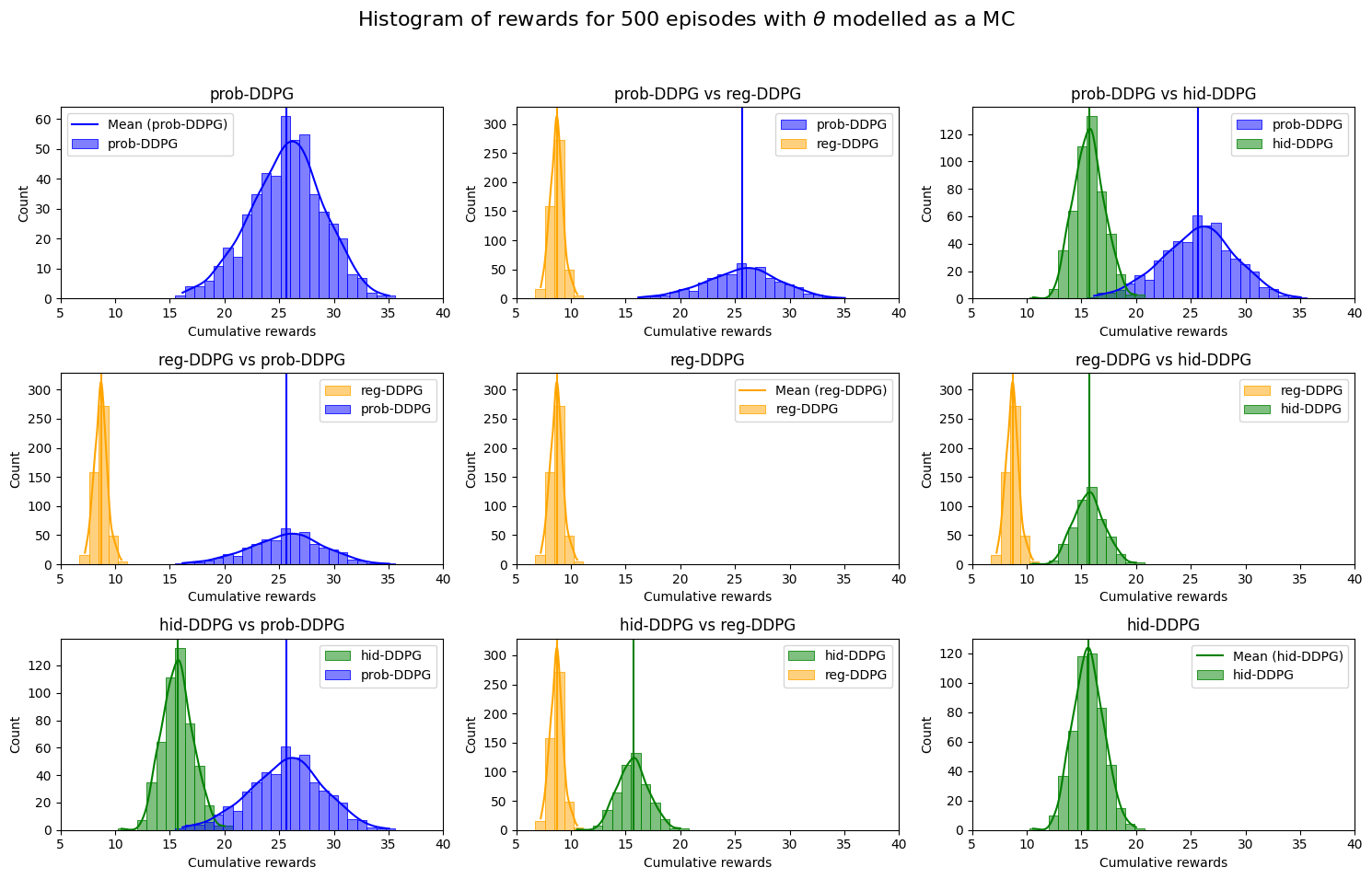
- prob-DDPG (using regime probabilities) performs best. It earns the highest cumulative rewards and makes more understandable decisions (you can see how the AI reacts to being in different regimes).
- hid-DDPG (using GRU hidden states) does okay but not as well. Its strategies are harder to interpret.
- reg-DDPG (using next-step predictions) gives only small benefits and often underperforms compared to prob-DDPG.
The big lesson: what you feed the AI matters. Giving it structured, interpretable information about the hidden regimes (probabilities) helps it trade more profitably and robustly than just giving it raw patterns or simple price forecasts.
Implications and Impact
This research suggests a practical path for building better trading AIs:
- Don’t just predict prices—teach the AI about the market’s hidden “moods” with probabilities. This makes strategies stronger and easier to understand.
- The approach works across both simulated and real markets (like pair trading).
- Beyond finance, the idea applies to any problem where important factors are hidden but can be estimated (for example, energy demand, traffic flow, or health monitoring). Supplying the right kind of information—especially interpretable probabilities—can make learning systems smarter and more reliable.
In short, if you want an AI to make good decisions in a noisy, changing world, it helps to give it the right clues about what’s going on behind the scenes.
Collections
Sign up for free to add this paper to one or more collections.