- The paper demonstrates that pre-training on shape-prior synthetic data enables robust few-shot and zero-shot blood vessel segmentation across diverse medical imaging modalities.
- It introduces a novel synthetic dataset generation approach using Bézier curves that decouples shape from texture to reduce CNN texture bias.
- Quantitative analysis shows improved Dice scores (up to 75.7%) and enhanced segmentation continuity, highlighting the lasting benefits of shape-centric pre-training.
VessShape: Few-shot 2D Blood Vessel Segmentation via Shape Priors from Synthetic Images
Motivation and Problem Statement
Semantic segmentation of blood vessels in medical images is constrained by the limited availability of annotated datasets and the poor generalization of models across imaging modalities. Conventional CNN-based approaches exhibit a strong texture bias, which impedes transferability when domain-specific textures differ, as is common between modalities such as retinal fundus photography and cerebral cortex microscopy. The paper hypothesizes that leveraging geometric priors—specifically, the universal tubular and branching nature of vessels—can yield models that are both data-efficient and robust to domain shifts.
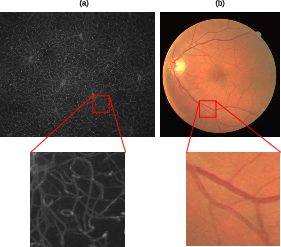
Figure 1: Illustration of the universality of vessel shape across mouse cortex and human retina, despite disparate textures.
VessShape Synthetic Dataset Generation
The VessShape methodology procedurally generates large-scale synthetic datasets with explicit shape bias. Vessel geometries are constructed using nth-order Bézier curves, with randomized control points and perturbations to induce realistic tortuosity. Binary masks are created by discretizing these curves and applying morphological dilation to achieve tubular thickness. Foreground and background textures are sampled from random ImageNet classes and blended via Gaussian-matted alpha masks, ensuring that texture cues are highly variable and non-informative for vessel identification.

Figure 2: Examples of VessShape generation, showing diverse vessel shapes and randomized textures.
This approach enforces a decoupling of shape and texture, compelling models to learn geometric features rather than overfitting to texture statistics. The generator is parameterized to produce a wide range of vessel complexities, thicknesses, and curvatures, and is scalable to millions of samples.
Experimental Setup and Datasets
Validation is performed on two real-world datasets: DRIVE (retinal fundus images) and VessMAP (fluorescence microscopy of mouse cortex). These datasets differ substantially in vessel appearance, global organization, and imaging artifacts, providing a rigorous testbed for cross-domain generalization.
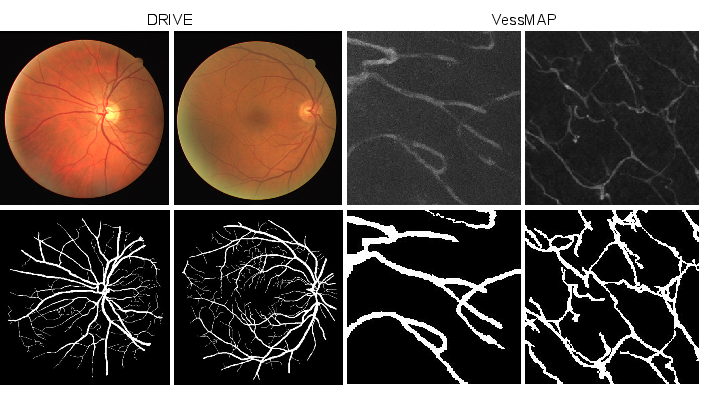
Figure 3: Representative samples and ground-truth masks from DRIVE and VessMAP datasets.
Models are based on U-Net architectures with ResNet18 and ResNet50 encoders. Three training regimes are compared: (1) training from scratch on real data, (2) pre-training on VessShape followed by few-shot fine-tuning, and (3) zero-shot inference using only VessShape pre-training.
Quantitative Results: Few-shot and Zero-shot Segmentation
Pre-training on VessShape yields substantial improvements in few-shot and zero-shot segmentation performance. In the zero-shot regime, VSUNet18 achieves Dice scores of 65.6% (DRIVE) and 75.7% (VessMAP), outperforming models trained from scratch, which require at least one labeled sample to reach comparable performance. In the one-shot regime, VSUNet models maintain a 7–10 percentage point advantage in Dice score over U-Net baselines. The performance gap persists even as the number of fine-tuning samples increases, indicating that the shape prior confers lasting benefits.
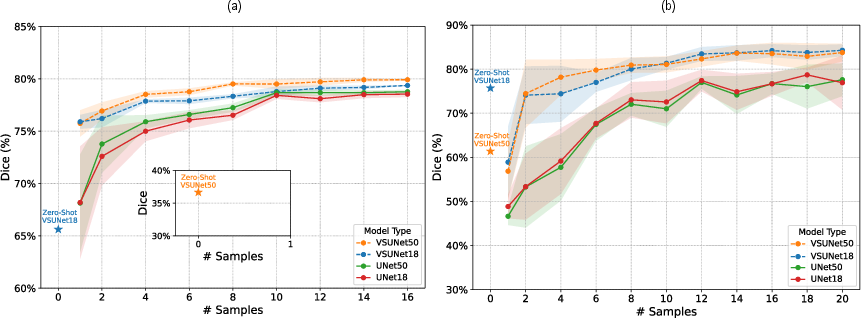
Figure 4: Few-shot and zero-shot Dice performance curves for DRIVE and VessMAP, showing rapid convergence and lower variance for VSUNet models.
A notable phenomenon is observed in VessMAP: zero-shot performance exceeds one-shot, attributed to catastrophic forgetting when fine-tuning on a single sample. This effect is mitigated as more samples are introduced, with the model recovering and surpassing its initial performance. In DRIVE, the shape prior is less well-aligned, but fine-tuning rapidly adapts the model to the domain.
Qualitative Analysis
Qualitative comparisons reveal that VSUNet models, even in zero-shot mode, accurately segment major vessel structures and maintain continuity, while U-Net baselines struggle with thin vessels and domain-specific artifacts. With increasing fine-tuning samples, all models improve, but VSUNet outputs remain more cohesive and less prone to discontinuities.
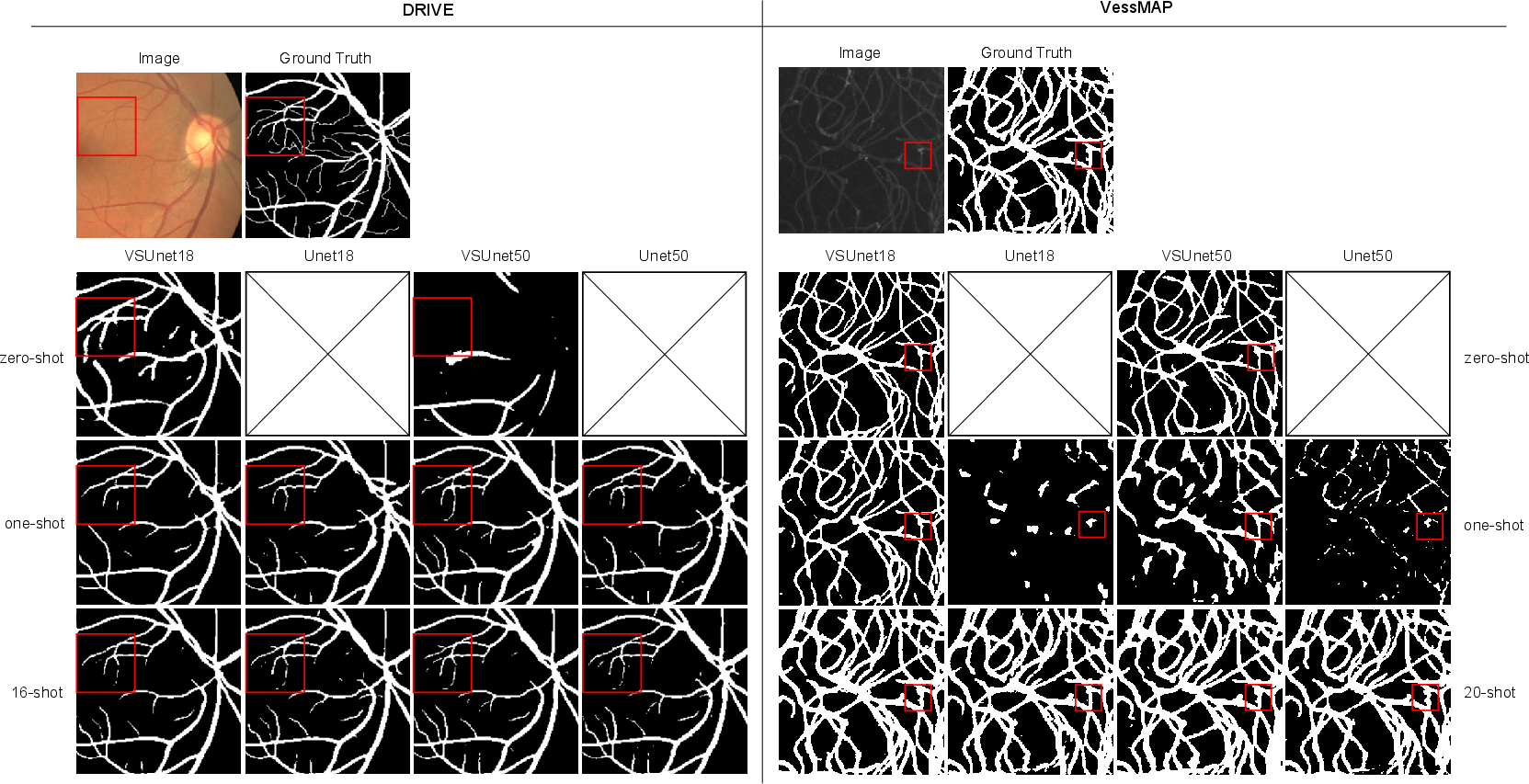
Figure 5: Visual comparison of segmentation outputs across zero-shot, one-shot, and few-shot regimes for DRIVE and VessMAP. Red squares highlight regions with challenging vessel morphology.
VSUNet18, despite its smaller capacity and shorter pre-training, demonstrates superior zero-shot generalization and competitive few-shot performance, suggesting that shape-centric pre-training is highly efficient.
Implications and Future Directions
The results substantiate the claim that pre-training with strong geometric priors enables robust, data-efficient vessel segmentation across modalities. This approach is particularly advantageous in medical imaging domains where annotated data is scarce and domain shifts are prevalent. The VessShape framework is flexible and can be tuned to match specific vascular morphologies, potentially improving alignment with target domains.
Future work may extend VessShape to generate more complex vascular topologies, incorporate true bifurcations, and support 3D volumetric data for modalities such as CT and MRI. The shape-centric paradigm could be generalized to other biological structures with consistent geometry, such as neurons or airways. Additionally, integrating VessShape pre-training with foundation models or self-supervised learning may further enhance transferability and reduce annotation requirements.
Conclusion
VessShape demonstrates that instilling a strong shape bias via synthetic data generation is an effective strategy for few-shot and zero-shot blood vessel segmentation. Models pre-trained on VessShape generalize across disparate imaging modalities and require minimal annotated data for adaptation. This work highlights the utility of geometric priors in medical image analysis and suggests that shape-centric pre-training may be broadly applicable to other segmentation tasks with consistent structural features.

