- The paper proposes GRWM, integrating temporal contextualization and geometric regularization to structure latent spaces and reduce prediction drift.
- By enforcing temporal slowness and latent uniformity losses, GRWM delivers near-oracle performance over extended rollouts, outperforming standard VAE-based models.
- Empirical tests in Maze and Minecraft environments show GRWM’s robustness and improved spatial coherence, maintaining high-fidelity predictions over thousands of steps.
Geometrically-Regularized World Models for High-Fidelity Cloning of Deterministic 3D Environments
The paper addresses the challenge of constructing world models capable of high-fidelity, long-horizon prediction in deterministic 3D environments. Unlike open-world generative models that prioritize diversity and plausibility, the focus here is on precise, reproducible simulation—critical for applications such as robot navigation, digital twins, and planning in static environments. The authors identify the primary bottleneck as the quality of the learned latent representation: standard autoencoders, particularly VAEs, produce entangled and lossy latent spaces that hinder the ability of downstream dynamics models to maintain accurate rollouts over extended horizons.
A key empirical observation is that when a dynamics model is provided with ground-truth physical states (e.g., agent coordinates), it achieves near-perfect long-horizon prediction. In contrast, when operating on VAE-learned latents, error accumulates rapidly, leading to divergence from the true trajectory. This motivates the central thesis: the structure and alignment of the latent space with the environment's true state manifold are the dominant factors in world model fidelity.
Geometrically-Regularized World Models (GRWM): Architecture and Training
The proposed GRWM framework augments a standard VAE-based world model with two core innovations:
- Temporal Contextualization: The encoder is designed to process a window of recent observations, leveraging a causal Transformer to aggregate temporal context. This mitigates perceptual aliasing, where distinct states yield similar observations, by allowing the latent to summarize the agent's state over time.
- Geometric Regularization: Two unsupervised loss terms are introduced to structure the latent space:
- Temporal Slowness Loss: Encourages all pairs of latent embeddings within a trajectory window to be close on the unit hypersphere, enforcing smooth, continuous evolution in latent space.
- Latent Uniformity Loss: Prevents feature collapse by encouraging embeddings from different trajectories to be uniformly distributed on the hypersphere.
The total training objective combines the standard VAE reconstruction and KL losses with these geometric regularizers, balanced by tunable hyperparameters. A lightweight projection head is used to decouple the space where regularization is applied from the space used for reconstruction, improving both representation quality and reconstruction fidelity.
Empirical Evaluation
Datasets and Baselines
Experiments are conducted on three deterministic, first-person 3D environments: Maze 3x3-DET, Maze 9x9-DET, and Minecraft-DET. Each provides fixed map layouts and deterministic transitions, enabling rigorous evaluation of rollout fidelity. The GRWM framework is benchmarked against standard VAE-based world models (VAE-WM) and several state-of-the-art dynamics models, including Standard Diffusion, Video Diffusion, and Diffusion Forcing, with and without geometric regularization.
Quantitative Results
Across all environments and dynamics models, GRWM consistently achieves lower frame-wise MSE over long rollouts, substantially closing the gap to the oracle model that operates on ground-truth states. The performance advantage of GRWM increases with rollout length, indicating improved temporal consistency and resistance to error accumulation.



Figure 1: M3x3-DET.
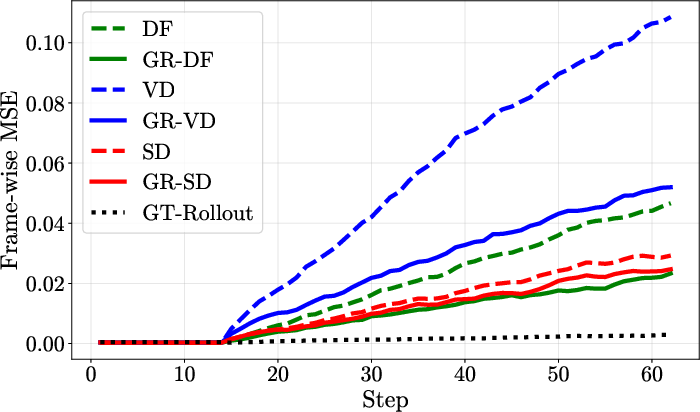
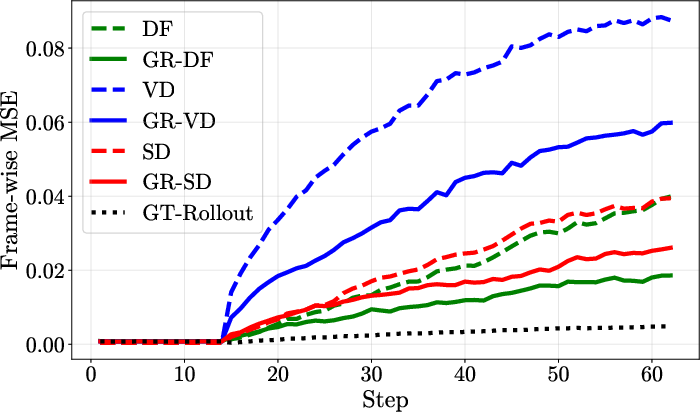
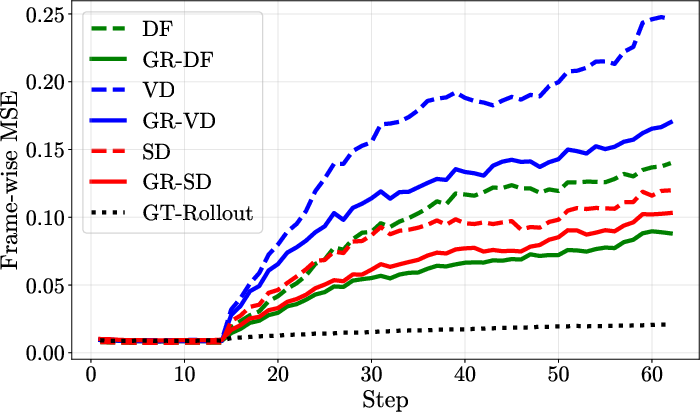
Figure 2: M3x3-DET.
Qualitative Analysis
Qualitative rollouts reveal that VAE-WM models frequently exhibit "teleportation" artifacts, where the agent's predicted trajectory jumps between visually similar but causally disconnected states, or becomes trapped in repetitive loops. In contrast, GRWM maintains coherent, diverse, and physically plausible trajectories over thousands of steps, accurately reflecting the environment's topology and structure.

Figure 3: Qualitative comparison of medium-horizon rollouts in M9x9-DET. GRWM maintains high similarity to ground truth, while VAE-WM gets trapped near the pink wall, indicating teleportation between visually similar but distinct locations.

Figure 4: Qualitative comparison in MC-DET. GRWM tracks complex motion and maintains high-fidelity generation, while VAE-WM diverges and renders incorrect objects.

Figure 5: Ultra long-horizon rollouts in Maze 9x9-CE. GRWM explores the environment coherently, while VAE-WM fails to explore and gets stuck in repetitive states.
Latent Space Analysis
Latent probing with MLP regressors demonstrates that GRWM latents are significantly more predictive of the true agent state (position and orientation) than VAE-WM latents. Clustering analysis further shows that GRWM produces spatially coherent clusters aligned with the environment's physical layout, whereas VAE-WM clusters are fragmented and entangled.
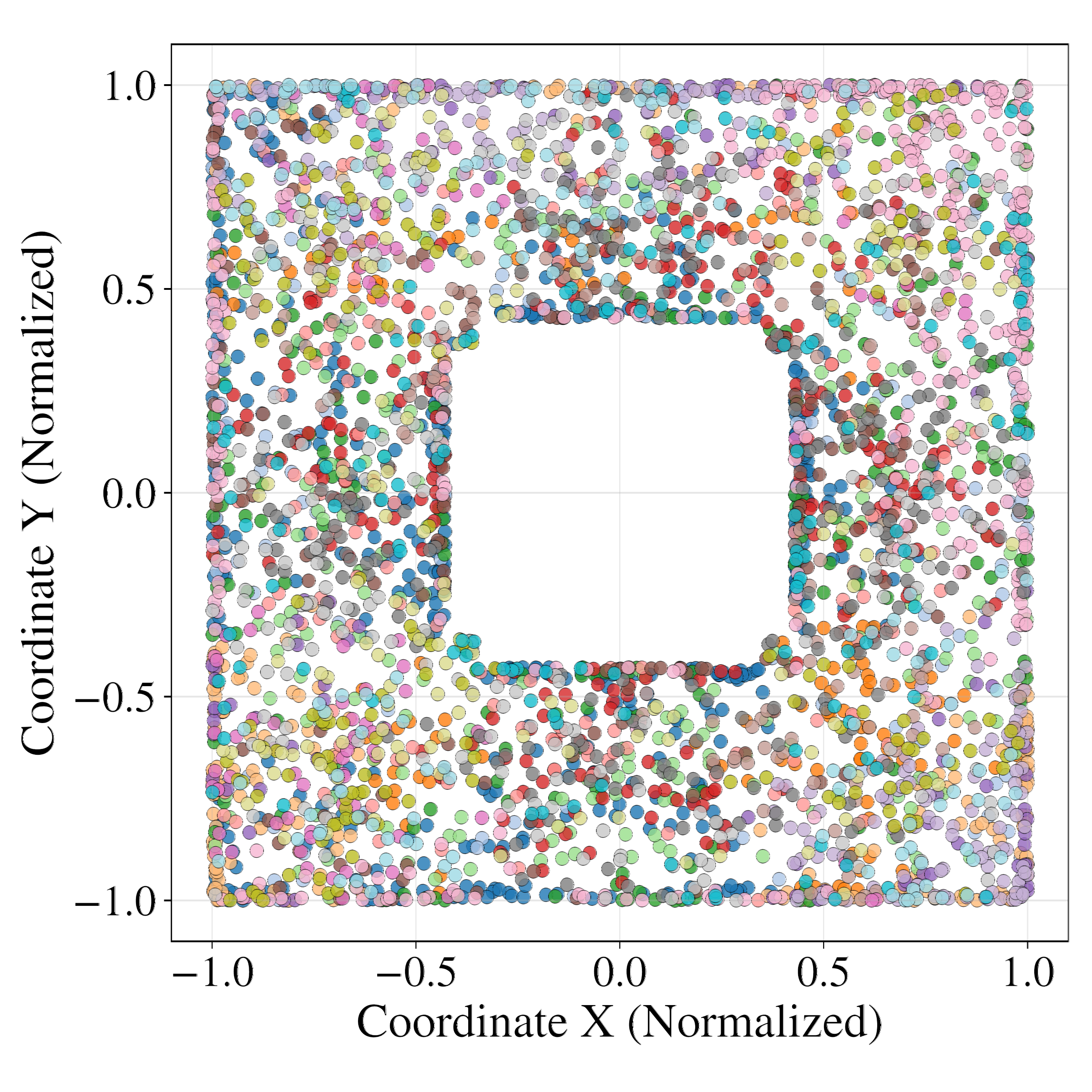
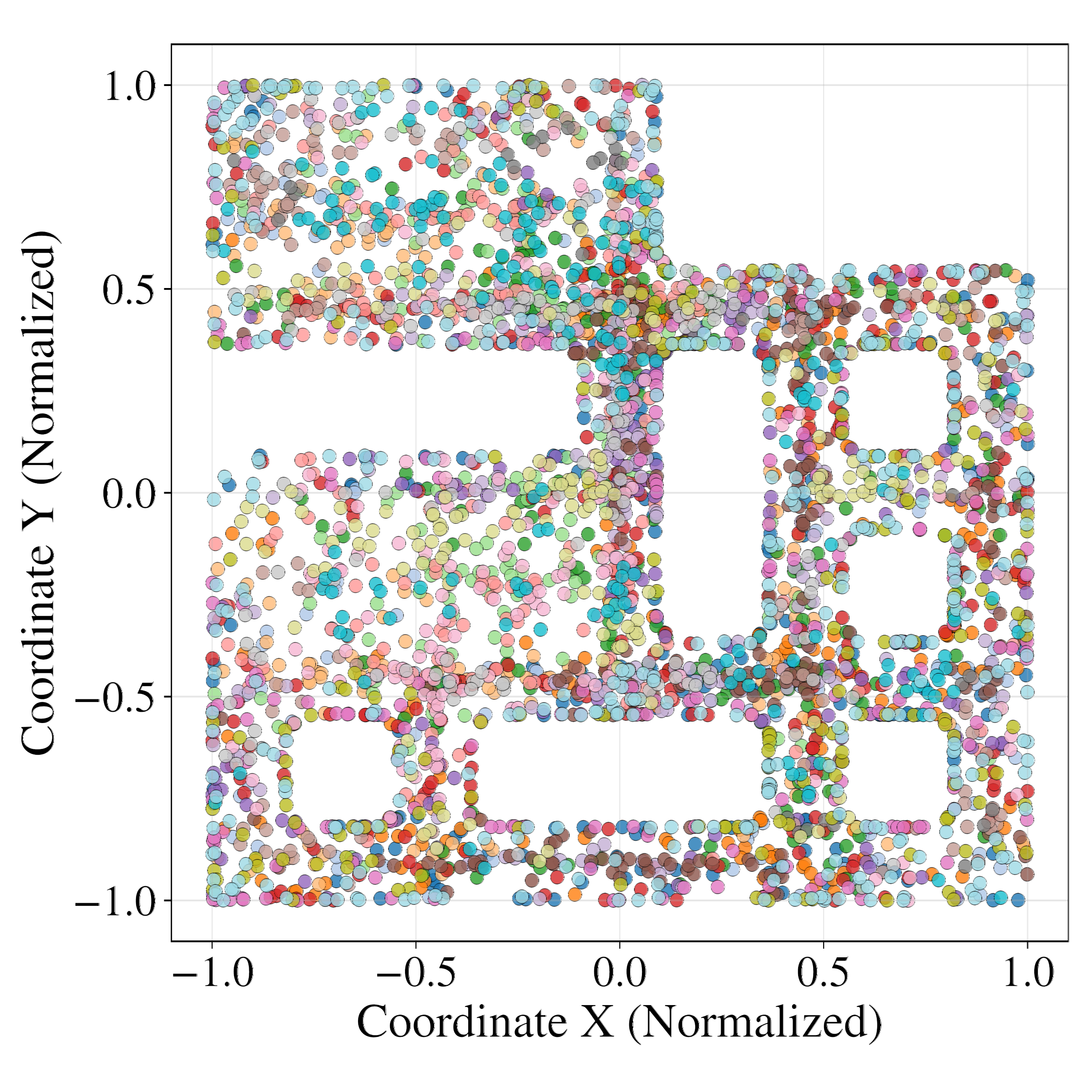
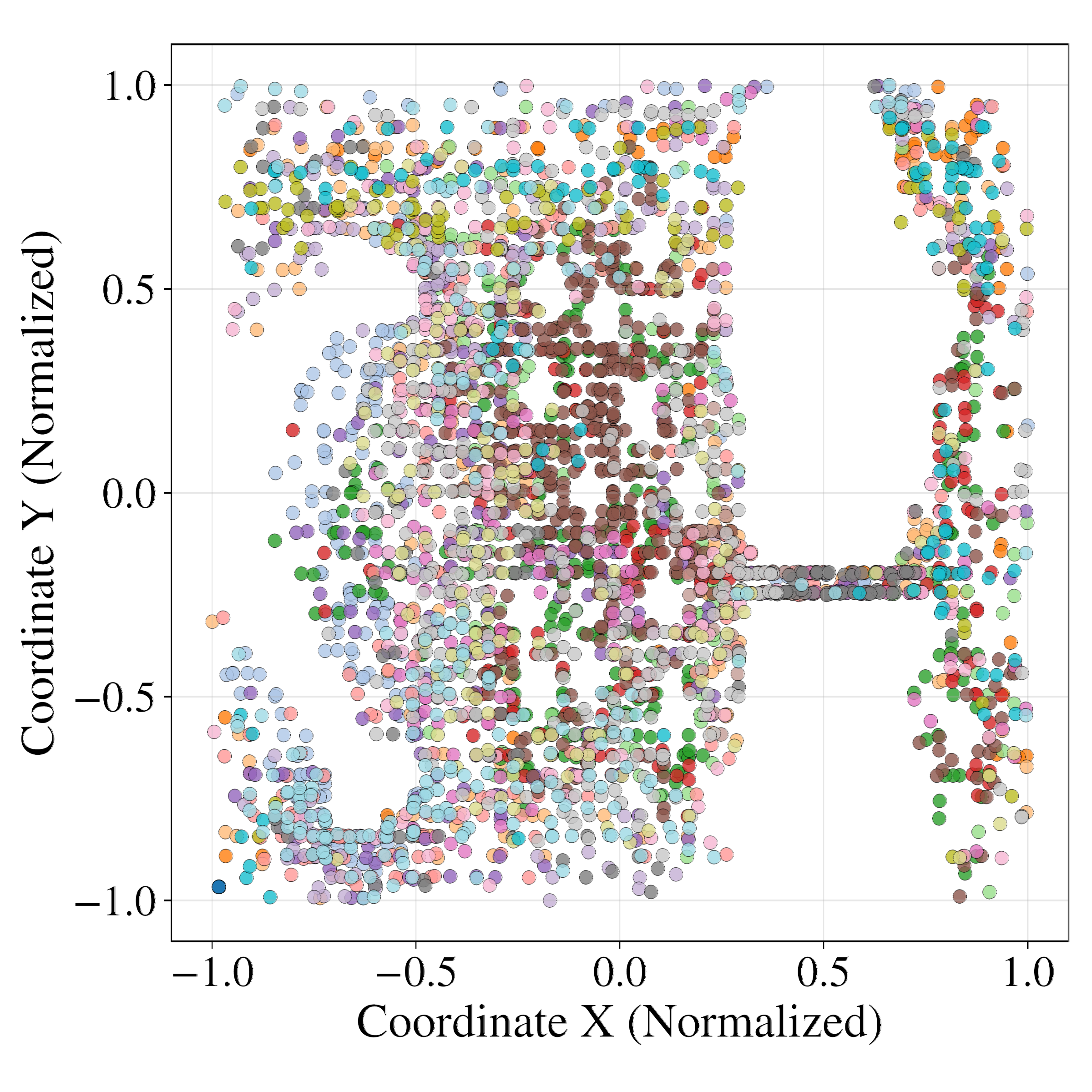
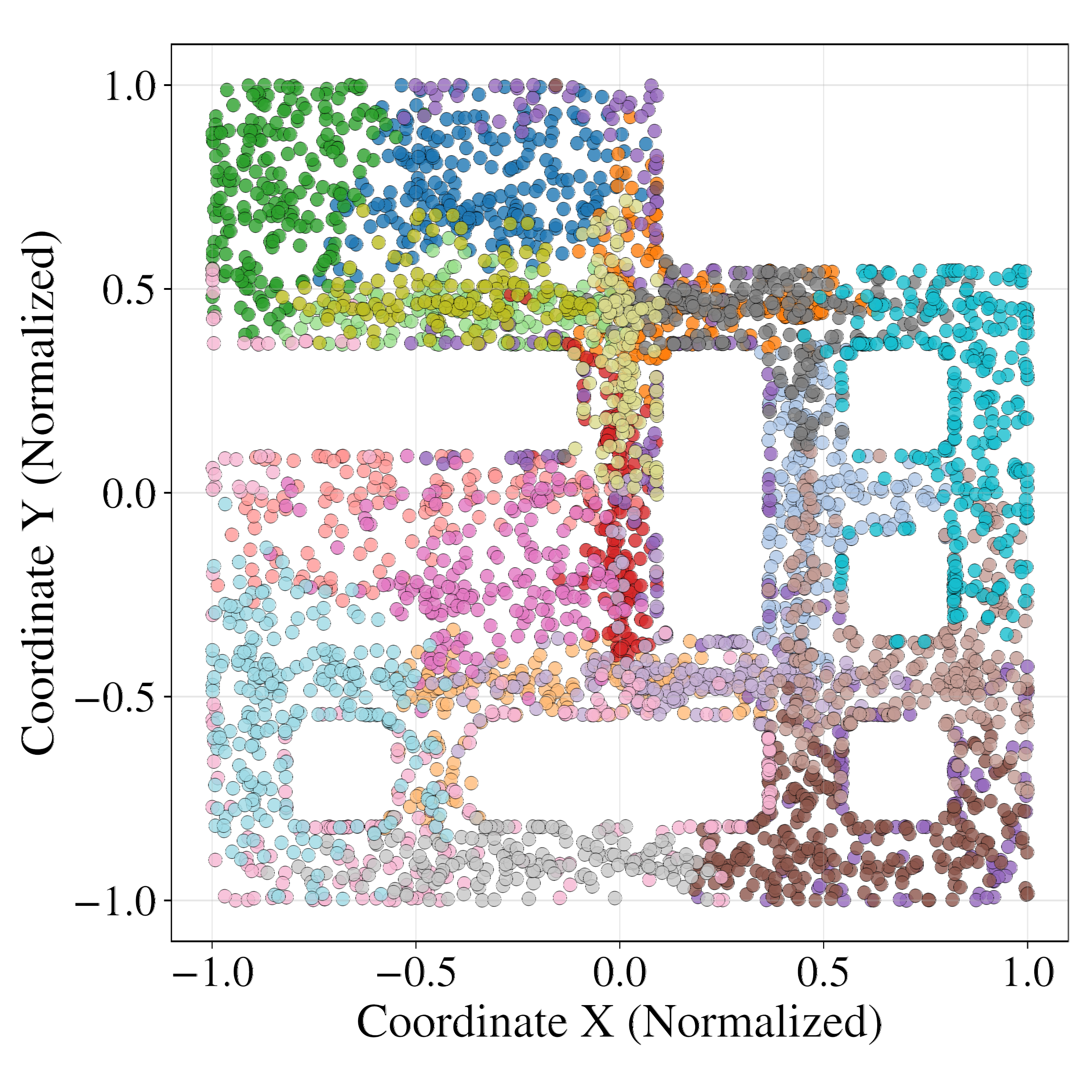
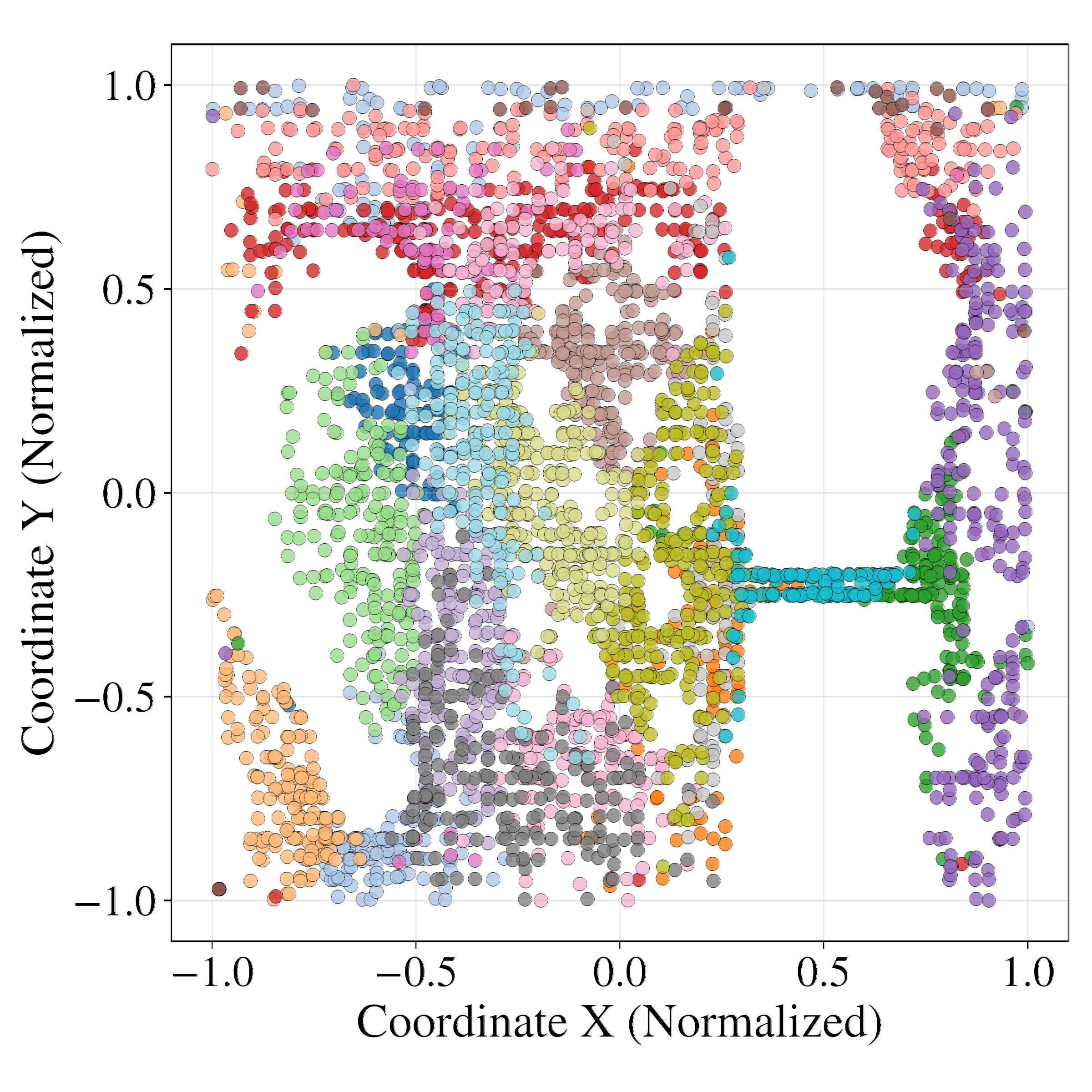
Figure 6: Clustering analysis of latent space. GRWM produces spatially coherent clusters aligned with the environment, while VAE-WM clusters are scattered and noisy.
Ablation Studies
Ablations confirm the necessity and complementarity of the slowness and uniformity losses. Removing either leads to representation collapse or poor rollout performance. The projection head is shown to decouple regularization from reconstruction, improving both. GRWM's performance is robust to latent dimensionality, in contrast to the baseline, which is sensitive and prone to overfitting with larger latent spaces.
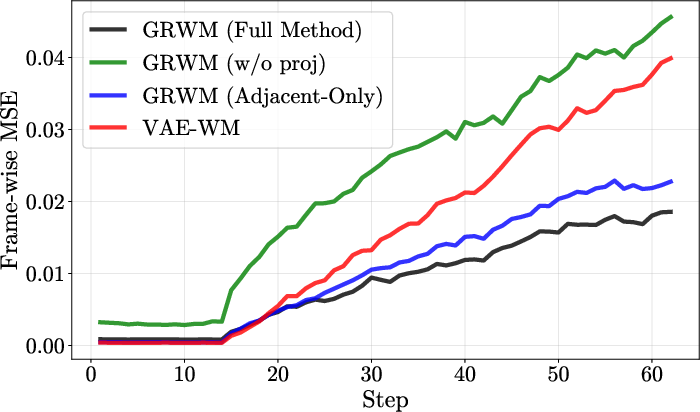
Figure 7: Frame-wise prediction MSE across ablation variants.
Additional Visualizations
Further visualizations reinforce the superior long-horizon consistency of GRWM. Even at 400 steps, GRWM maintains high-fidelity predictions, while VAE-WM predictions degrade rapidly.







Figure 8: Generated frames at multiple time points from a single starting state. GRWM maintains high fidelity at long horizons, while VAE-WM predictions degrade quickly.










Figure 9: Generated frames from the MC-DET sequence.
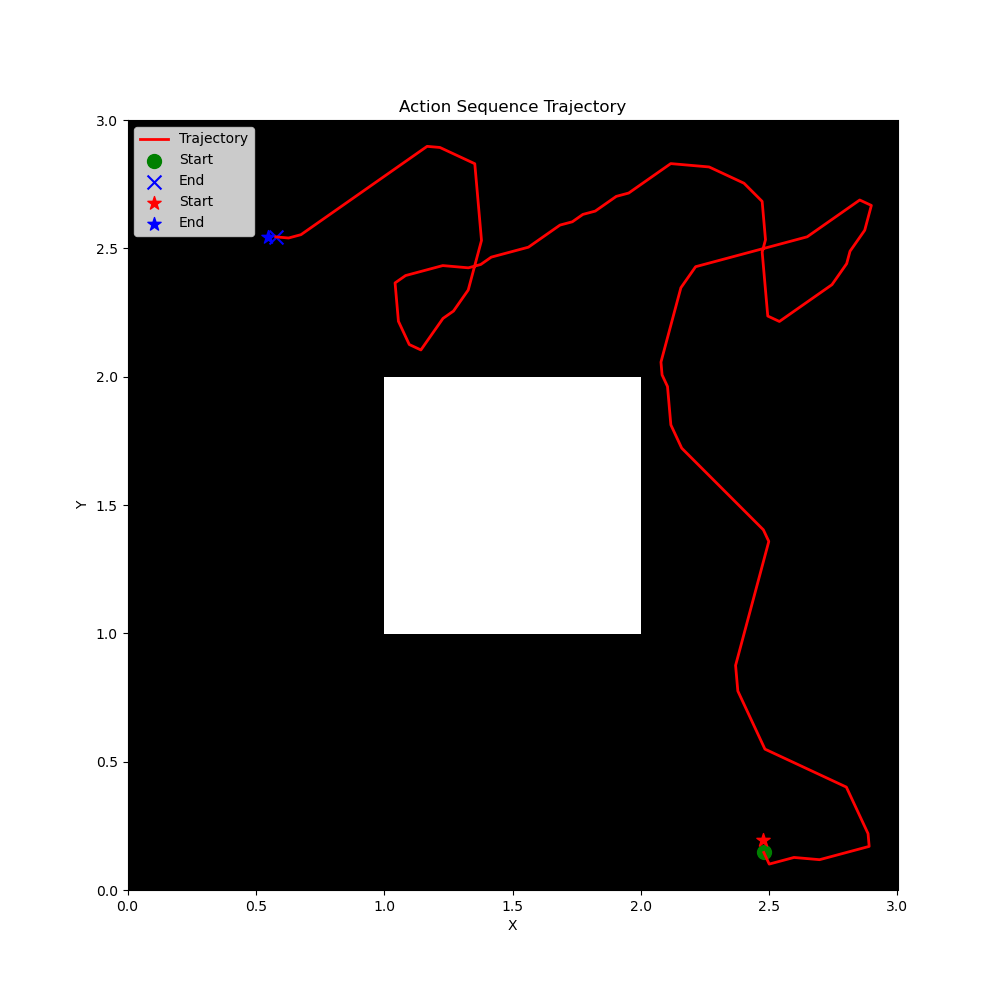
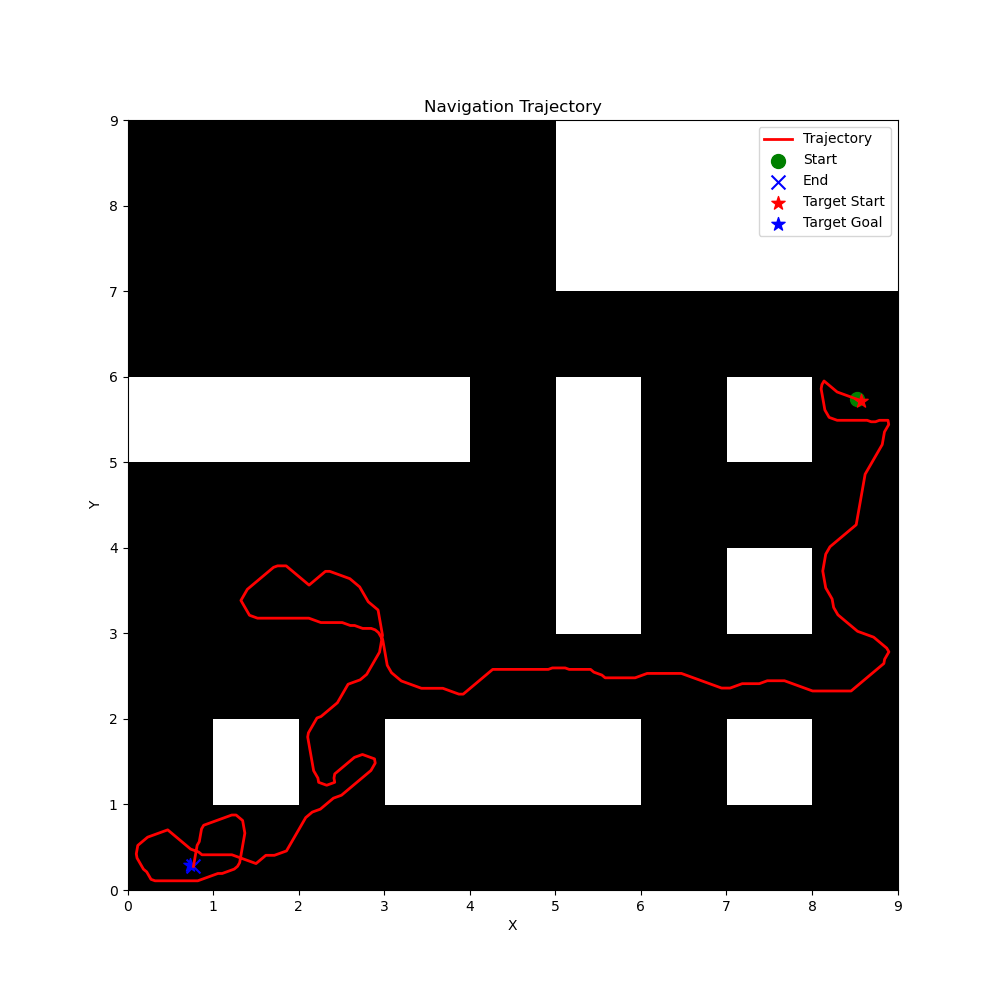

Figure 10: Representative trajectories from the three datasets.
Implications and Future Directions
The results provide strong evidence that representation learning is the primary determinant of world model fidelity in deterministic settings. By enforcing geometric structure in the latent space, GRWM enables standard dynamics models to achieve near-oracle performance without architectural changes or access to privileged information. This plug-and-play approach is computationally efficient and broadly applicable.
However, the method does not guarantee perfect recovery of the true physical state, and residual misalignment may still accumulate over extremely long horizons. The ultimate challenge remains the unsupervised discovery of the true generative factors underlying the environment. Future work should explore integrating geometric regularization with advances in disentanglement, self-supervised learning, and learned compression to approach this goal.
Conclusion
This work reframes high-fidelity world modeling as fundamentally a problem of representation learning. The GRWM framework demonstrates that geometric regularization of latent spaces yields substantial improvements in long-horizon prediction, outperforming prior approaches and approaching the performance of oracle models. These findings suggest that further progress in world modeling will be driven by advances in unsupervised representation learning, with geometric priors playing a central role in bridging the gap to robust, generalizable digital twins of complex environments.

