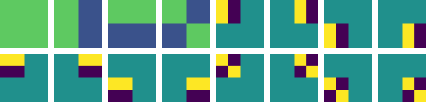STaMP: Sequence Transformation and Mixed Precision for Low-Precision Activation Quantization
Published 30 Oct 2025 in cs.LG and cs.AI | (2510.26771v1)
Abstract: Quantization is the key method for reducing inference latency, power and memory footprint of generative AI models. However, accuracy often degrades sharply when activations are quantized below eight bits. Recent work suggests that invertible linear transformations (e.g. rotations) can aid quantization, by reparameterizing feature channels and weights. In this paper, we propose \textit{Sequence Transformation and Mixed Precision} (STaMP) quantization, a novel strategy that applies linear transformations along the \textit{sequence} dimension to exploit the strong local correlation in language and visual data. By keeping a small number of tokens in each intermediate activation at higher precision, we can maintain model accuracy at lower (average) activations bit-widths. We evaluate STaMP on recent LVM and LLM architectures, demonstrating that it significantly improves low bit width activation quantization and complements established activation and weight quantization methods including recent feature transformations.
The paper introduces a novel methodology that combines sequence transformations with mixed-precision allocation to reduce quantization error in low-bit activations.
It exploits local correlations using DCT, DWT, and related transforms to concentrate activation energy, enabling targeted high-precision quantization and improved SQNR.
The approach is computationally efficient, integrates without retraining, and complements existing feature transforms across both large language and vision-language models.
STaMP: Sequence Transformation and Mixed Precision for Low-Precision Activation Quantization
Introduction and Motivation
The increasing computational and memory demands of large generative models, such as LLMs and LVMs, have made efficient inference a critical research focus. Post-training quantization (PTQ) is a primary method for reducing inference cost, but quantizing activations below 8 bits often leads to significant accuracy degradation, primarily due to outliers and the high dynamic range of activations. Prior work has focused on function-preserving feature transformations (e.g., Hadamard, learned rotations) to redistribute outliers across feature channels, but these approaches ignore the strong local correlations present in the sequence dimension of language and vision data.
The STaMP framework introduces a novel quantization strategy that leverages sequence transformations and mixed-precision allocation to exploit these correlations, enabling lower average bit-widths for activations while maintaining model accuracy. The method is orthogonal and complementary to existing feature transformation and weight quantization techniques.
Methodology
Sequence Transformations
STaMP applies linear, invertible transformations along the sequence dimension of activations, in contrast to prior work that operates solely along the feature dimension. Given an activation matrix X∈Rs×d (sequence length s, feature size d), a sequence transformation is defined as TX, where T is a left-invertible matrix. This transformation can be efficiently inverted after the subsequent linear layer, ensuring function preservation.
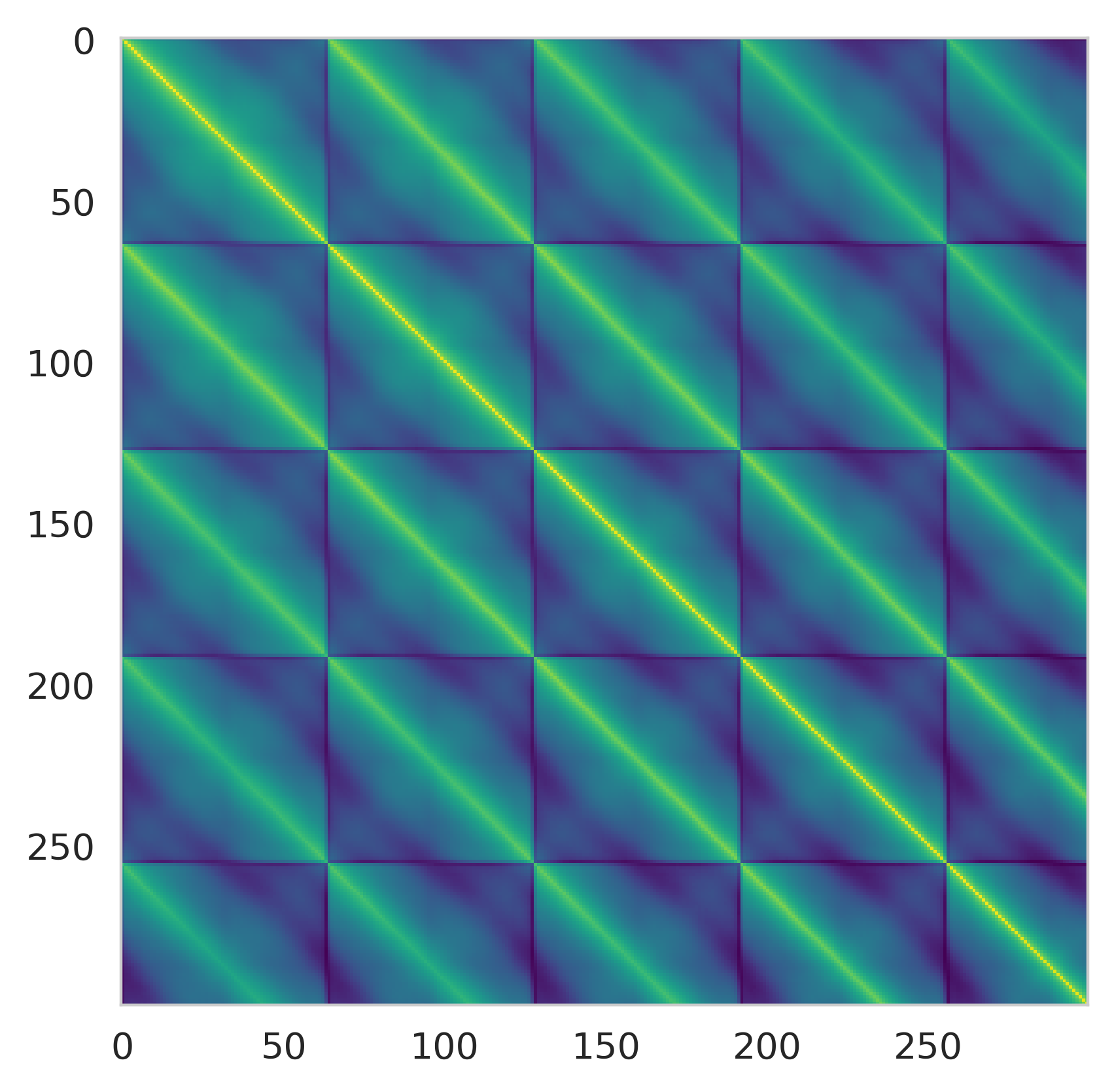
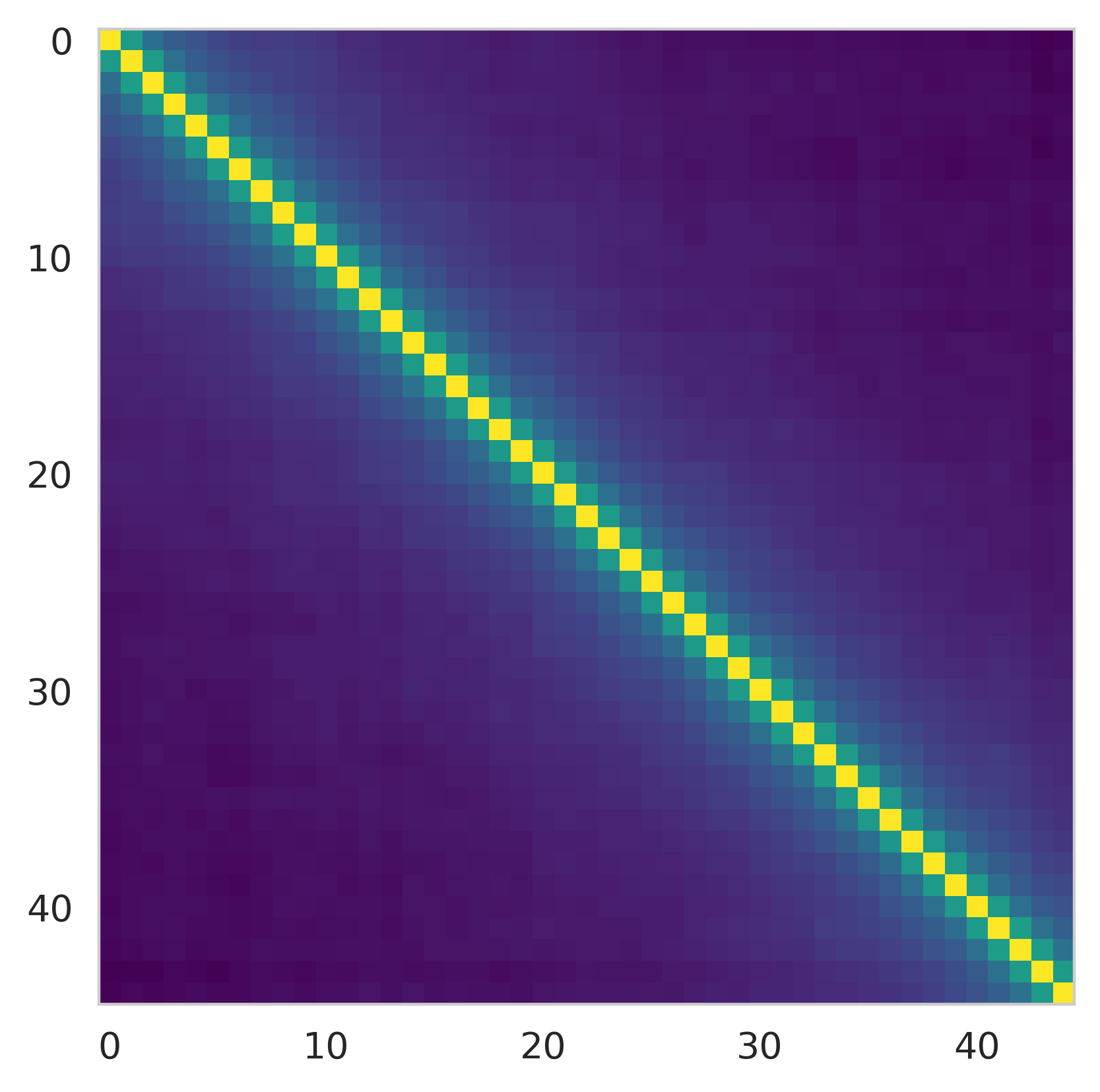
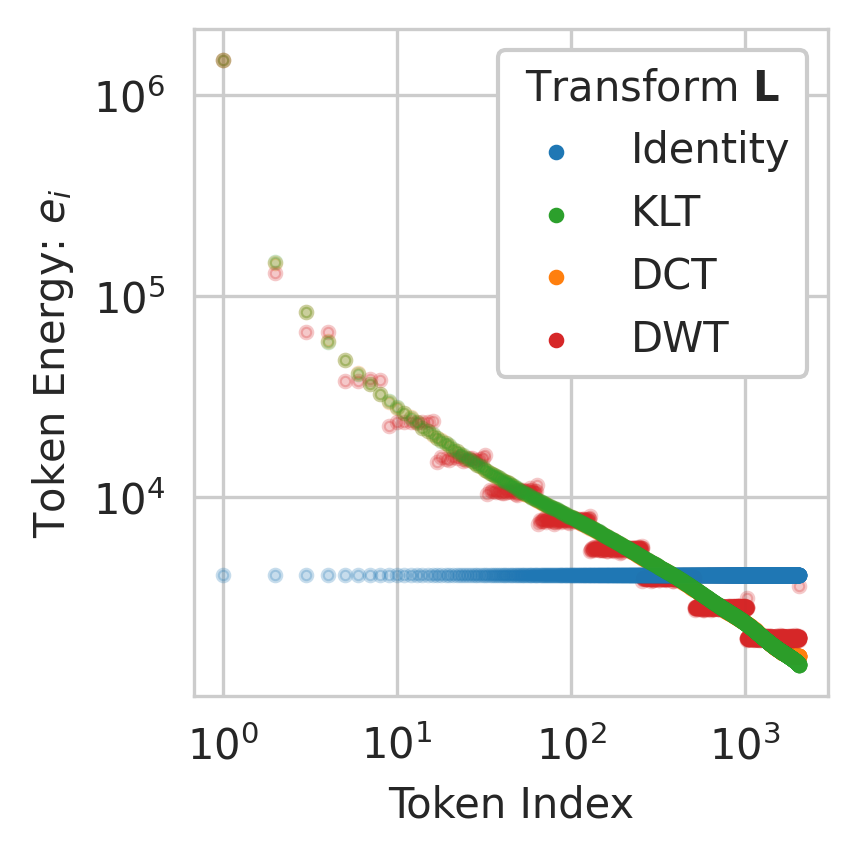
The key insight is that, due to strong local correlations in sequence data, the autocorrelation matrix of activations is approximately (block) Toeplitz, and its eigenbasis can be well-approximated by the Discrete Cosine Transform (DCT) or Discrete Wavelet Transform (DWT). These transforms concentrate the energy of the activations into a small subset of tokens, which can then be quantized at higher precision.
Figure 1: Autocorrelation structure and energy concentration in LVM and LLM activations, showing that DCT and DWT efficiently concentrate energy in the initial tokens.
Mixed-Precision Quantization
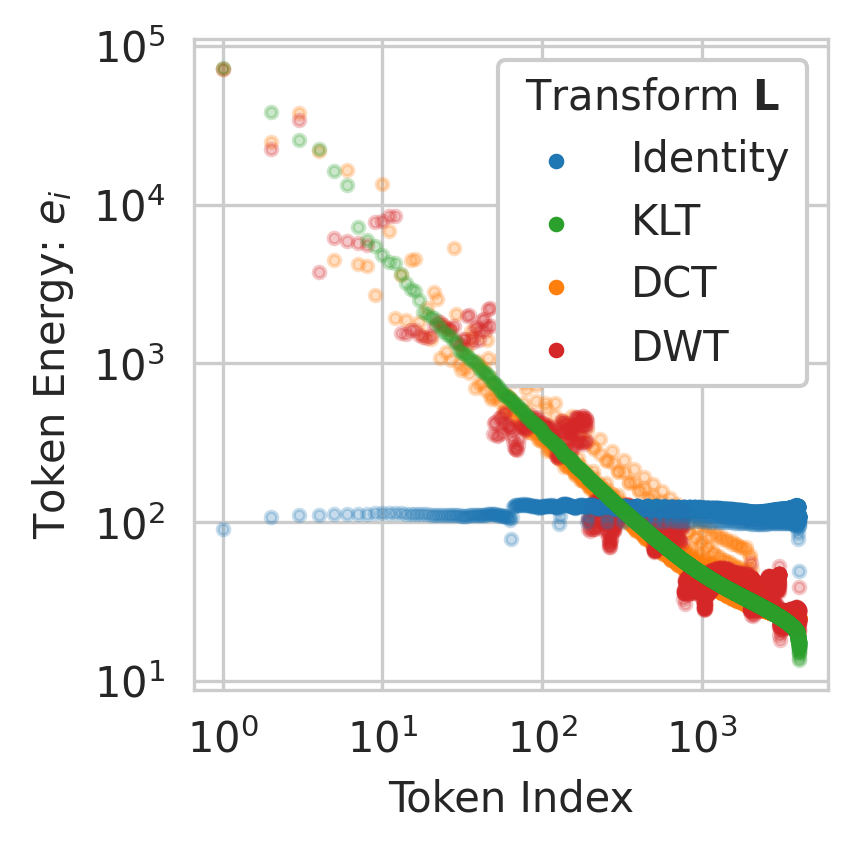
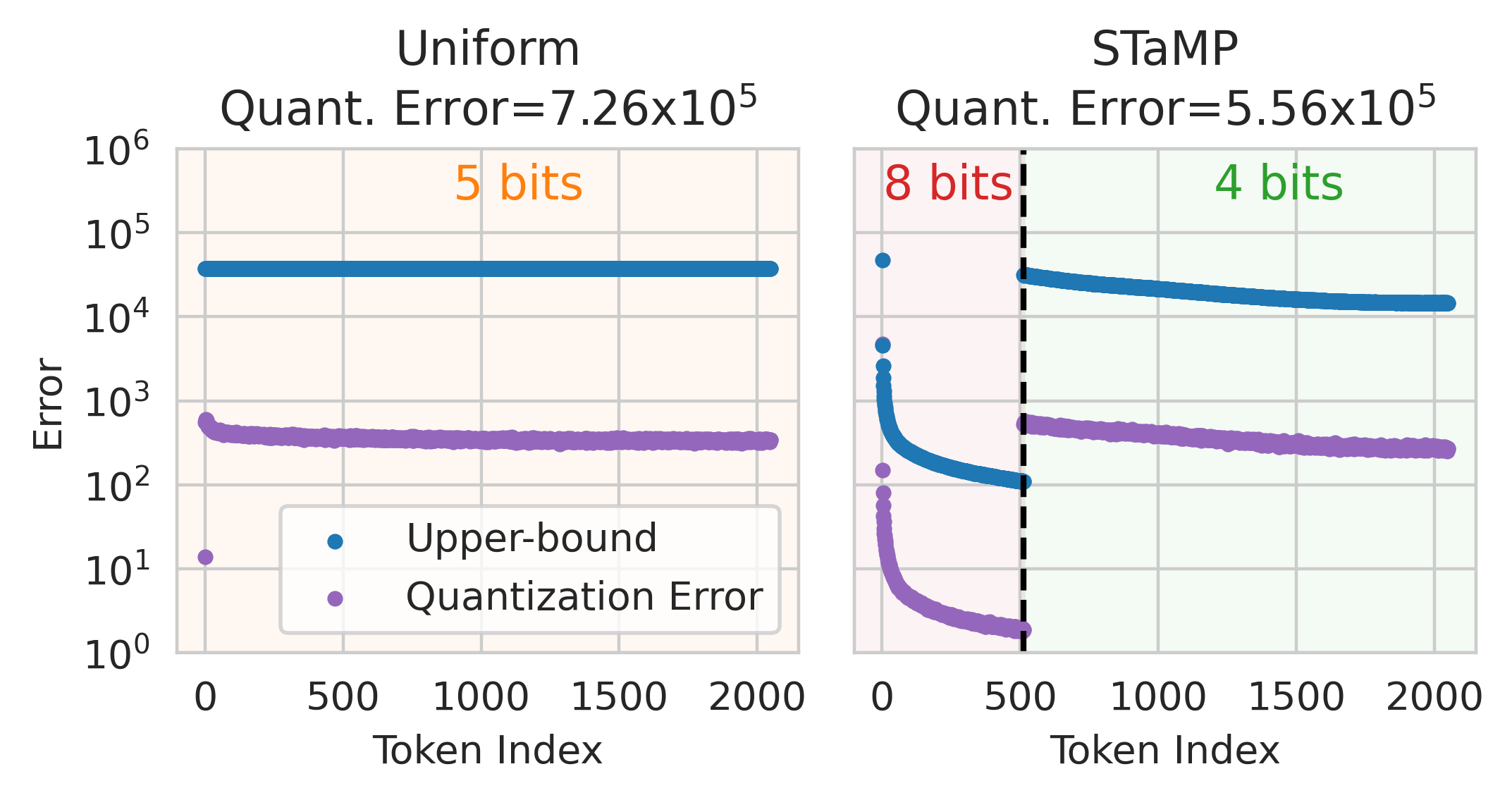
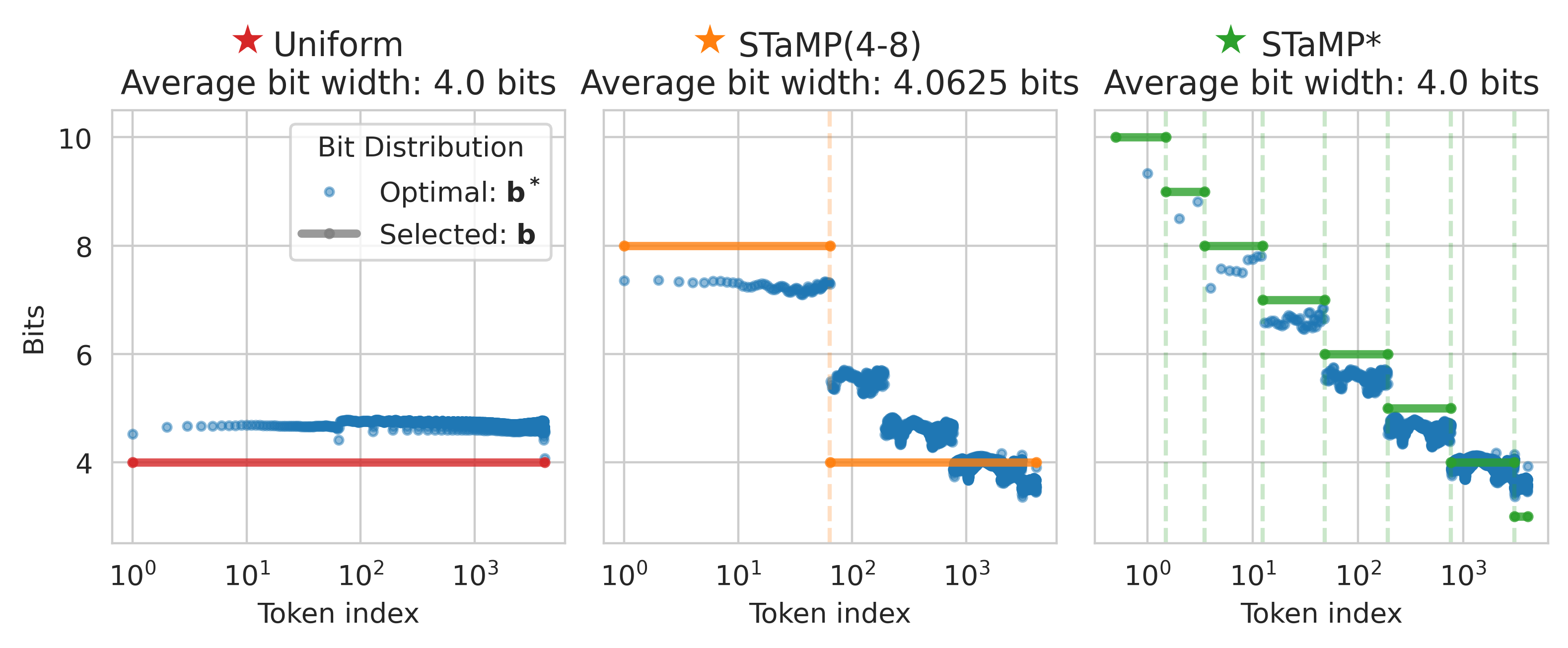
After sequence transformation, STaMP allocates higher bit-widths to the high-energy tokens and lower bit-widths to the rest, under a fixed average bit budget. The optimal bit allocation is derived analytically: for a total bit budget B and token energies ei, the optimal bit-width for token i is bi∗=log2ei−C, where C is a normalization constant. In practice, hardware constraints limit the number of supported bit-widths, so STaMP uses a simple two-level scheme (e.g., 8 bits for the first 64 tokens, 4 bits for the rest).
Figure 2: The STaMP procedure: sequence transformation concentrates energy in initial tokens, which are quantized at higher precision, reducing the quantization error upper bound.
Efficient Transform Implementation
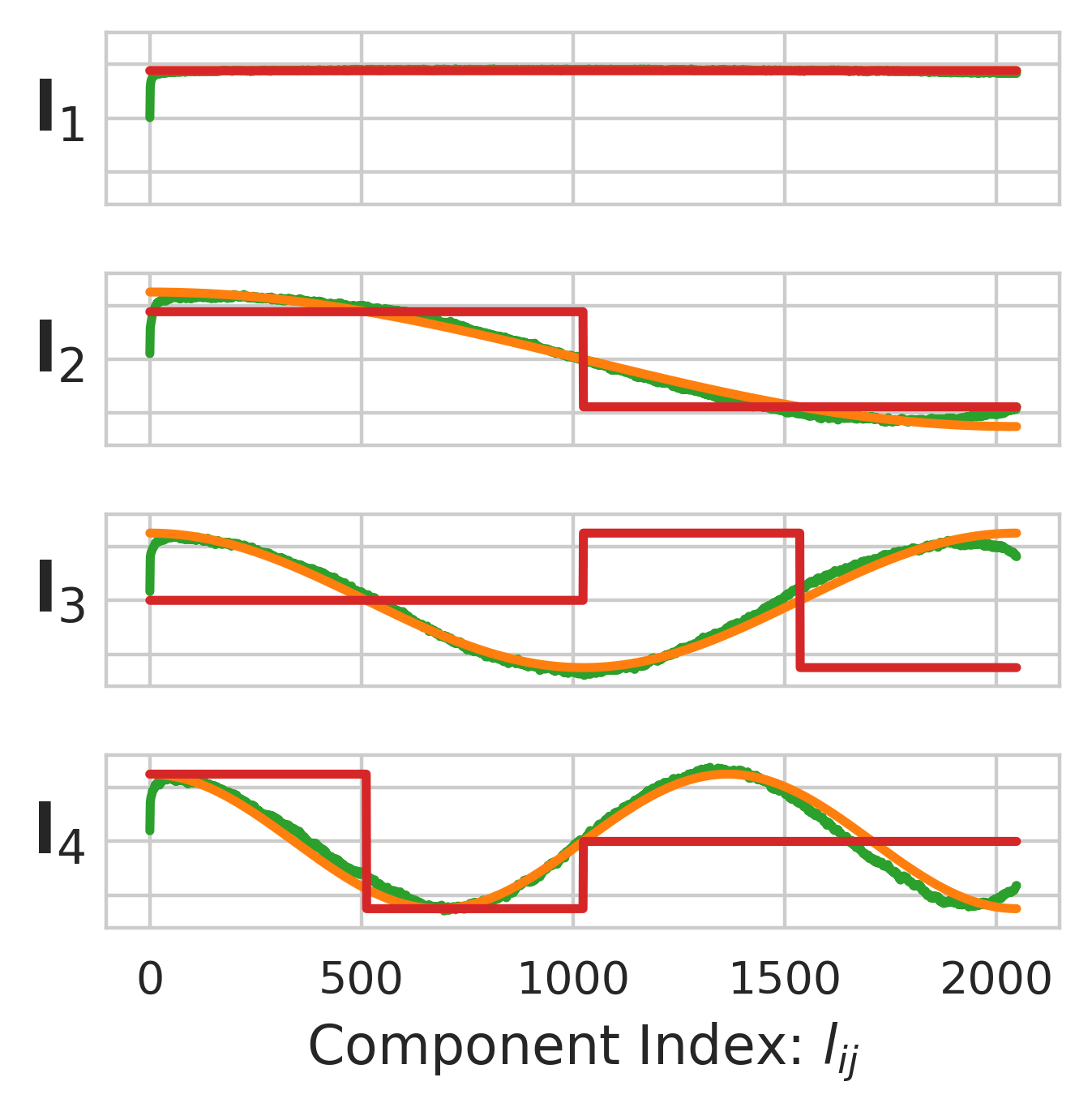
STaMP evaluates several sequence transforms:
Karhunen-Loève Transform (KLT): Optimal but computationally expensive.
DCT: Efficient, O(dslogs), and closely approximates KLT for Toeplitz autocorrelation.
DWT (Haar):O(ds), creates discrete energy levels, ideal for mixed-precision allocation.
DWT is preferred for its computational efficiency and suitability for hardware implementation.
Figure 3: Comparison of energy and bit width allocation strategies, showing that STaMP with DWT and two precision levels achieves superior SQNR/bit-width tradeoff.
Theoretical Analysis
The paper provides a tight upper bound on the expected quantization error after sequence transformation and mixed-precision allocation:
LT≤2di=1∑s(2bi−1)2ei
where ei is the energy of the i-th transformed token. By concentrating energy and allocating bits accordingly, STaMP achieves a lower quantization error than uniform allocation, as formalized via Jensen's inequality.
Experimental Results
Vision-LLMs (LVMs)
STaMP is evaluated on PixArt-Σ and SANA architectures, using 4-bit activation and weight quantization with block size 64. The method is combined with state-of-the-art feature transforms (SmoothQuant, QuaRot, ViDiT-Q, SVDQuant). Across all baselines and datasets (COCO, MJHQ), STaMP consistently improves SQNR, CLIP Score, and Image Reward, with visually superior generations.
Figure 4: PixArt-Σ sample generations for various quantization methods, with and without STaMP, demonstrating improved visual fidelity.
LLMs
STaMP is applied to Llama 3 8B, Llama 3.2 1B/3B, and Qwen 2.5 3B. Using W4A4KV4 quantization, STaMP is combined with feature transforms (SmoothQuant, QuaRot, FlatQuant). Perplexity on Wikitext-2 is consistently reduced when STaMP is added, especially for smaller, harder-to-quantize models.
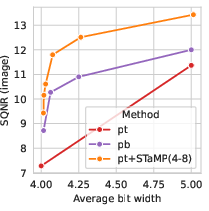
Complementarity with Feature Transforms
STaMP's improvements are largely orthogonal to feature transforms. Combining DWT-based sequence transforms with Hadamard or DCT feature transforms yields additive gains in both LVMs and LLMs.
Figure 5: Images generated with A4 activation quantization and various combinations of feature and sequence transforms for PixArt-Σ.
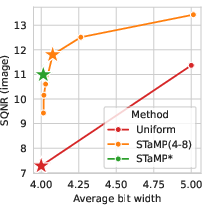
Bit-Width/SQNR Tradeoff
STaMP achieves a superior SQNR/bit-width tradeoff compared to per-token and per-block quantization, with sharp SQNR improvements even when only a small number of tokens are kept at high precision.
Figure 6: SQNR vs. bit width for per-token, per-block, and STaMP quantization on PixArt-Σ.
Overhead and Practicality
The computational overhead of DWT-based STaMP is minimal: less than 5% additional runtime and negligible FLOPS increase compared to Hadamard feature transforms. Efficient CUDA kernels and hardware support further reduce the practical cost.
Implementation Considerations
Integration: STaMP is applied before each linear layer and inverted after, requiring only minor modifications to the model forward pass.
Calibration: DWT and DCT do not require data-dependent calibration, unlike KLT.
Hardware: The two-level mixed-precision scheme (e.g., 8/4 bits) is compatible with existing hardware quantization support.
Compatibility: STaMP is fully compatible with advanced weight quantization (e.g., GPTQ, SVDQuant) and feature transforms.
No Retraining: The method is entirely post-training and does not require fine-tuning or retraining.
Implications and Future Directions
STaMP demonstrates that sequence-aware transformations and mixed-precision allocation can substantially improve low-bit quantization for both LLMs and LVMs, without retraining or complex calibration. The approach is theoretically grounded, computationally efficient, and practically effective across diverse architectures and tasks.
Potential future directions include:
Learned Sequence Transforms: Exploring data-driven or learned sequence transforms for further energy concentration.
Adaptive Precision Allocation: Dynamic bit allocation based on input statistics or task requirements.
Hardware Co-Design: Custom accelerators for DWT/DCT-based quantization pipelines.
Extension to Other Modalities: Application to audio, video, or multi-modal generative models.
Conclusion
STaMP introduces a principled, efficient, and complementary approach to low-precision activation quantization by leveraging sequence transformations and mixed-precision allocation. The method achieves strong empirical gains across LLMs and LVMs, is compatible with existing quantization techniques, and incurs minimal computational overhead. STaMP provides a robust foundation for further advances in efficient generative model deployment, particularly in resource-constrained environments.